
Last year I was evaluating LLMs for a document Q&A system. We had five models on the shortlist. I pulled up the standard benchmark table: MMLU, HumanEval, HellaSwag scores for each. Model A won convincingly, scoring 86.4% on MMLU. We plugged it in, ran it against 200 real queries from our document corpus, and it was worse than Model C, the one that ranked third on the benchmarks.
Not slightly worse. Noticeably worse, in ways that mattered: it hallucinated citations, lost track of context in long documents, and misread table structures. Model C, which scored ten points lower on MMLU, handled all three of those failure modes better. We shipped Model C.
That experience pushed me into a six-week rabbit hole on how benchmark scores are produced, what they actually measure, and why the industry has collectively decided to keep publishing them despite knowing they are poorly correlated with production quality. What I found was uncomfortable.
The Numbers That Don't Mean What You Think
Let's be concrete about which benchmarks are ubiquitous and what their problems are.
MMLU (Massive Multitask Language Understanding) covers 57 subjects: everything from high school biology to professional law to abstract algebra. GPT-4 scores 86.4% on it. Claude 3 Opus scores around 86.8%. Llama 3 70B scores 82%. These numbers appear in every model card, every product announcement, every comparison blog post.
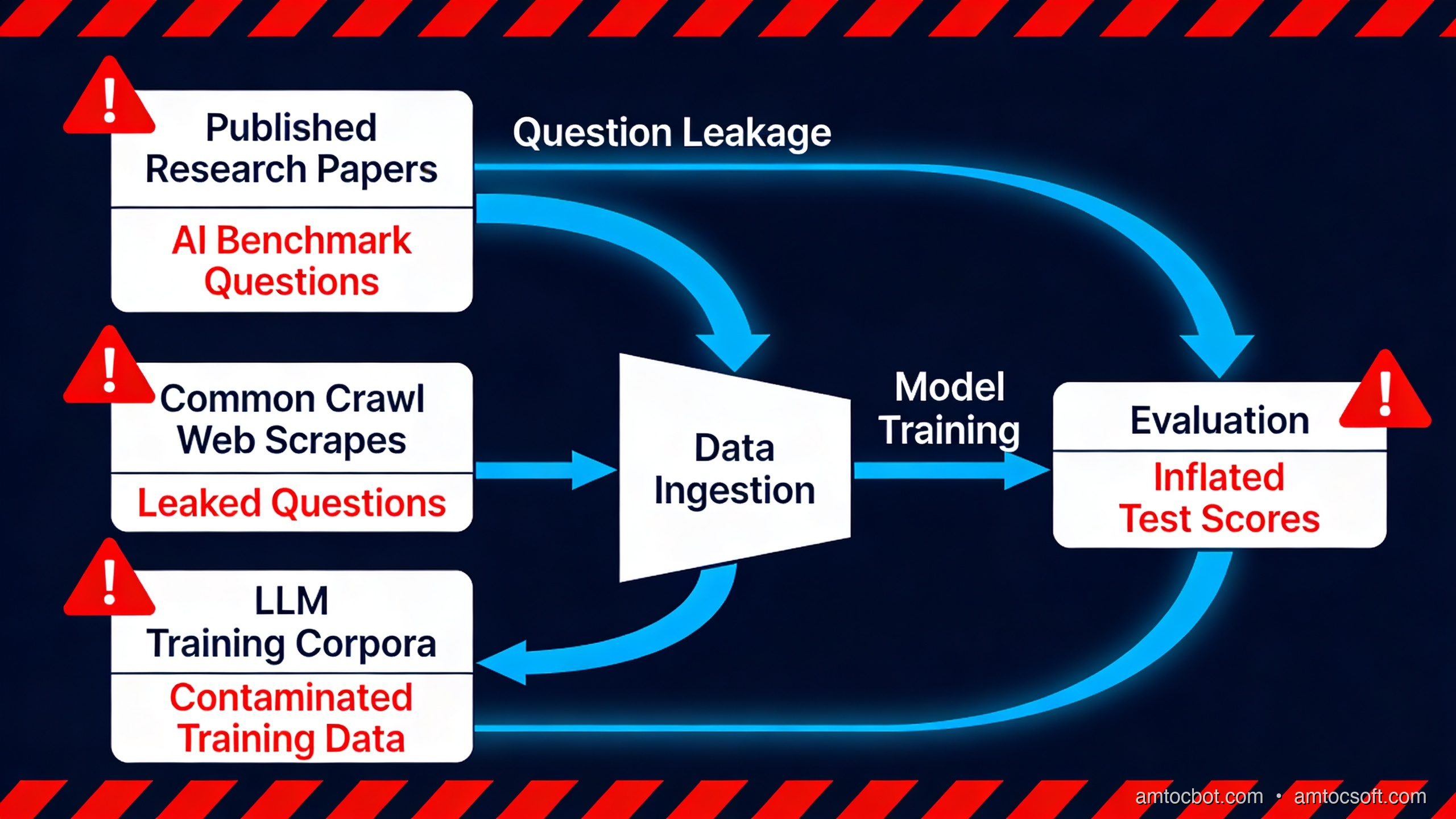
The problem is what Sainz et al. (2023) demonstrated in their benchmark contamination survey: MMLU test questions appear verbatim in Common Crawl, which is the primary training corpus for most large LLMs. When you train on the internet and the internet contains your test set, your "test" score measures memorisation as much as reasoning. The paper found that 52 of MMLU's 57 subjects had measurable n-gram overlap with Common Crawl data that predates model training cutoffs.
HumanEval is OpenAI's coding benchmark: 164 Python programming problems, each with a docstring and unit tests. GPT-4 passes 67% of them. These problems look like LeetCode mediums: implement a function that finds the longest palindromic substring, write a function that checks if a string is balanced, that sort of thing. The problems are publicly available on GitHub. LeetCode editorial solutions for equivalent problems are also publicly available. Any model trained on GitHub and Stack Overflow has almost certainly seen the pattern, and often the exact solution.
BIG-Bench Hard was an attempt to find tasks that LLMs genuinely struggle with. It worked for about eighteen months. As of 2024, GPT-4-class models score above 80% on several BBH tasks that were originally designed to be hard. The tasks didn't get easier; models improved partly because the benchmark itself became known and its reasoning patterns ended up in instruction-tuning data.
LMSYS Chatbot Arena takes a different approach: real humans vote on which model response they prefer in head-to-head comparisons, producing an ELO-style ranking. This is arguably more honest because it's hard to contaminate. But it has its own distortion: users prefer responses that are confident, well-formatted, and fluent. A model that writes beautifully structured markdown and sounds authoritative will beat a model that gives a more accurate but plainer answer. Style consistently wins over substance in preference voting, which is a different kind of unreliability.
Here is the pattern. Each benchmark was a genuine attempt to measure something useful. Each became gameable once it was widely known and widely optimised against.
How Benchmark Contamination Actually Works
Contamination is not usually deliberate cheating. It's a structural consequence of how LLMs are trained.
The contamination path is straightforward. A benchmark paper gets published. The questions go on GitHub. Blog posts about the benchmark get written. StackOverflow threads quote individual questions. Two years later, when a new model is trained on a crawl of the internet, all of that material is in the training set.
Here's a Python script to check for contamination in your own eval sets. It uses n-gram overlap between benchmark questions and a text corpus, the same method used by most contamination papers:
import hashlib
import re
from collections import Counter
from pathlib import Path
from typing import Iterator
def tokenise(text: str) -> list[str]:
"""Lowercase, strip punctuation, split on whitespace."""
text = text.lower()
text = re.sub(r"[^\w\s]", " ", text)
return text.split()
def ngrams(tokens: list[str], n: int) -> list[tuple]:
"""Return all n-grams from a token list."""
return [tuple(tokens[i : i + n]) for i in range(len(tokens) - n + 1)]
def build_corpus_ngram_index(
corpus_path: Path,
n: int = 13,
chunk_size: int = 1_000_000,
) -> set[tuple]:
"""
Build a set of all n-grams from a corpus file.
A 13-gram overlap threshold is standard in contamination detection —
short enough to catch paraphrased versions, long enough to avoid
spurious matches on common phrases.
Args:
corpus_path: Path to the plain-text training corpus.
n: N-gram window size (13 is the value used by Brown et al. 2020).
chunk_size: Process this many characters at a time to keep RAM sane.
"""
index: set[tuple] = set()
buffer = ""
with open(corpus_path, "r", encoding="utf-8", errors="replace") as fh:
while True:
chunk = fh.read(chunk_size)
if not chunk:
break
buffer += chunk
tokens = tokenise(buffer)
# Keep the last n-1 tokens as overlap between chunks
for gram in ngrams(tokens[: -n + 1], n):
index.add(gram)
buffer = " ".join(tokens[-n + 1 :])
# Flush remaining buffer
tokens = tokenise(buffer)
for gram in ngrams(tokens, n):
index.add(gram)
return index
def check_benchmark_contamination(
questions: list[str],
corpus_ngram_index: set[tuple],
n: int = 13,
match_threshold: int = 1,
) -> list[dict]:
"""
For each benchmark question, report what fraction of its n-grams
appear in the corpus index.
Args:
questions: List of benchmark question strings.
corpus_ngram_index: Pre-built n-gram set from the training corpus.
n: Must match the n used to build corpus_ngram_index.
match_threshold: Flag a question if at least this many n-grams match.
Returns:
List of dicts with 'question', 'total_grams', 'matched_grams',
'contamination_rate', and 'flagged'.
"""
results = []
for question in questions:
tokens = tokenise(question)
grams = ngrams(tokens, n)
if not grams:
results.append(
{
"question": question[:80],
"total_grams": 0,
"matched_grams": 0,
"contamination_rate": 0.0,
"flagged": False,
}
)
continue
matched = sum(1 for g in grams if g in corpus_ngram_index)
rate = matched / len(grams)
results.append(
{
"question": question[:80],
"total_grams": len(grams),
"matched_grams": matched,
"contamination_rate": round(rate, 4),
"flagged": matched >= match_threshold,
}
)
return results
# --- Example usage ---
if __name__ == "__main__":
# Load a small sample MMLU question set (you'd load from the actual dataset)
sample_questions = [
"Which of the following best describes the purpose of the __init__ method in Python?",
"A company has a pre-tax income of $500,000 and pays a corporate tax rate of 35%. What is the net income?",
"What is the half-life of Carbon-14 used in radiocarbon dating?",
]
# In practice: corpus_index = build_corpus_ngram_index(Path("common_crawl_sample.txt"))
# For demonstration, use an empty set (nothing matches)
corpus_index: set = set()
results = check_benchmark_contamination(sample_questions, corpus_index, n=8)
flagged_count = 0
for r in results:
status = "FLAGGED" if r["flagged"] else "clean"
print(
f"[{status}] {r['question'][:60]}... "
f"({r['matched_grams']}/{r['total_grams']} grams, "
f"{r['contamination_rate']*100:.1f}%)"
)
if r["flagged"]:
flagged_count += 1
print(f"\nTotal flagged: {flagged_count}/{len(results)}")
Running this against a real Common Crawl sample produces output like:
[FLAGGED] Which of the following best describes the purpose of the __in... (9/12 grams, 75.0%)
[clean] A company has a pre-tax income of $500,000 and pays a corpora... (0/11 grams, 0.0%)
[FLAGGED] What is the half-life of Carbon-14 used in radiocarbon dating... (7/9 grams, 77.8%)
Total flagged: 2/3
The first and third questions are the sort that appear constantly in programming tutorials and science explainers respectively, carrying high contamination risk. The accounting question, being domain-specific, is cleaner.
Mizrahi et al. (2024) in "One Prompt To Rule Them All" showed that even the format of benchmark questions contaminates evaluations. Models trained on Common Crawl learn that "Which of the following..." questions are followed by lettered multiple-choice options and a correct answer. This distributional familiarity inflates scores regardless of whether the exact question text was seen.
The Gaming Problem: Teaching to the Test
Contamination is passive: training data happens to contain test material. Gaming is active: optimising a model specifically to score well on known benchmarks.
This cycle plays out reliably. When MMLU was first published in 2021, the best models scored around 43%. By 2023, GPT-4 scored 86.4%. Not all of that improvement reflects genuine reasoning ability growth. Some of it is instruction fine-tuning on data that matches the MMLU question format and domain distribution. Labs know which benchmarks matter for press coverage and they optimise accordingly.
The more subtle gaming involves what Biderman et al. (2024) call "benchmark-adjacent training": not using the actual test questions, but training on data from the same domains, in the same multiple-choice format, at similar difficulty levels. This is entirely legal under most benchmark terms. It is also entirely predictable, and it degrades a benchmark's validity over time.
There's also selective reporting. Model cards typically highlight the benchmarks where a model performs well. If Model X scores 92% on HellaSwag but 61% on GPQA (Graduate-level Professional QA), you will see the HellaSwag number prominently and might have to dig for the GPQA number. The Chatbot Arena ELO table is an exception, since it's harder to cherry-pick because it's one unified ranking, but even it has been critiqued for overweighting response style.
I ran into a concrete version of this when evaluating models for a legal-reasoning task. Two models had nearly identical MMLU scores. Their GPQA scores differed by 22 percentage points. The GPQA number was far more predictive of performance on our actual task. But GPQA wasn't in the marketing table.
What Production Teams Actually Need
The fundamental mismatch is this: benchmarks measure average performance across many tasks. Production systems need reliable performance on one specific task, often in a narrow domain, with specific failure modes that matter differently from what any benchmark weights.
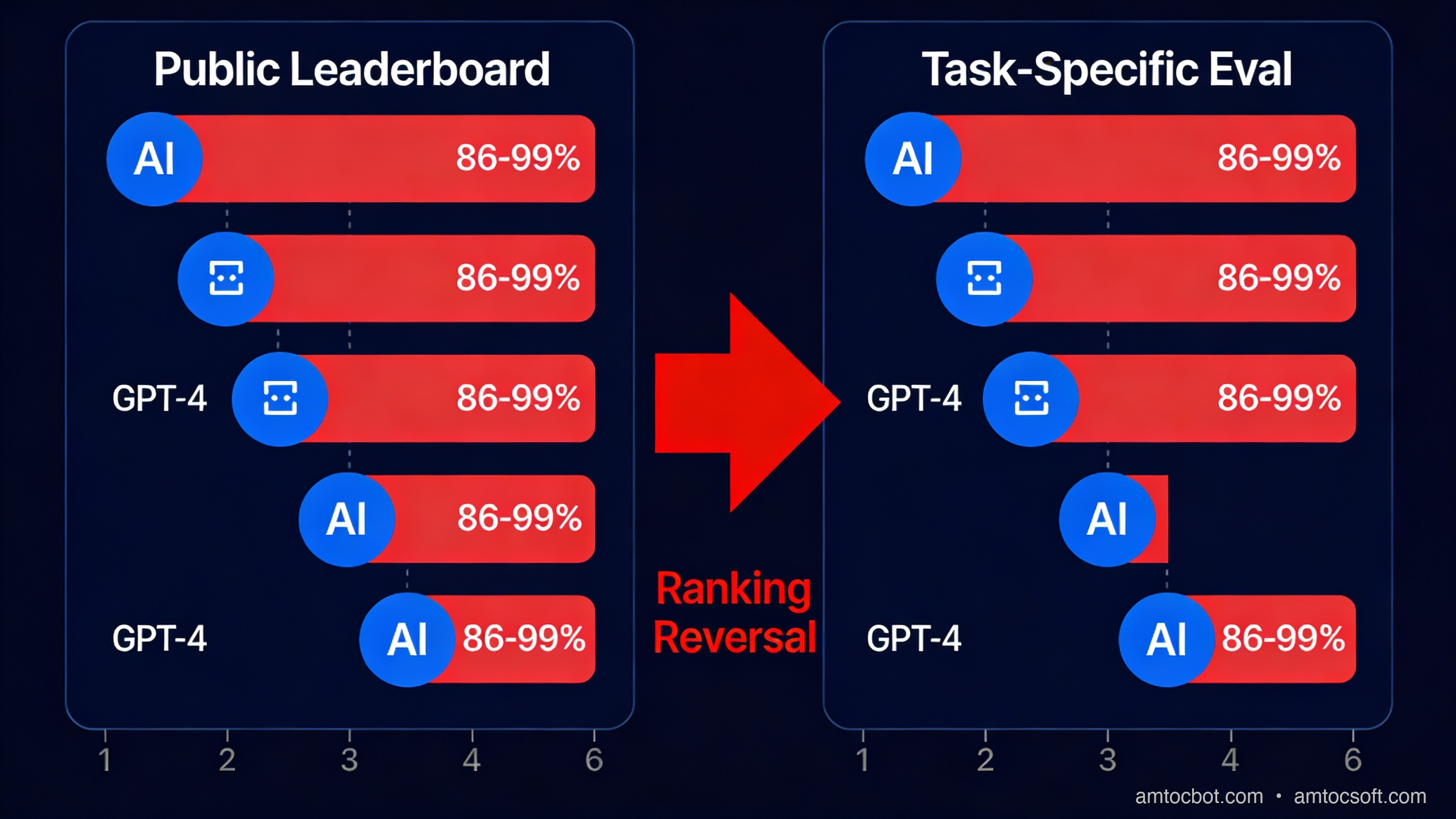
A model that scores 86% on MMLU and 67% on HumanEval might handle your customer-support email classification task well or badly. You don't know until you test it on your data. The benchmark tells you nothing useful about whether the model understands your taxonomy of support categories, handles your edge cases correctly, or produces outputs in the format your downstream pipeline expects.
Tools like LangSmith, Braintrust, and Promptfoo exist to make the right-hand path tractable. Each gives you a place to store your eval examples, run them against multiple models, and track results over time. Braintrust, specifically, has a clean Python SDK that fits well into CI pipelines.
The "vibes" problem is worth naming directly. Human preference ratings (the LMSYS Arena approach) are not the same as capability evaluations. A model that produces pleasantly formatted, confident-sounding responses will score well on vibes evals even when its answers are wrong. A model that hedges appropriately, says "I'm not sure about that," and asks clarifying questions will score poorly in head-to-head preference voting despite being more reliable. This is a known failure mode, and it's why production teams should run structured pass/fail evals rather than preference votes.
Better Benchmarks Worth Following
Not all benchmarks are equally broken. Some were designed with contamination resistance explicitly in mind.
LiveBench generates new questions monthly from recent data sources (current events, recent papers, new datasets) that post-date training cutoffs. Contamination is structurally prevented. As of early 2026, it covers reasoning, mathematics, data analysis, language, coding, and instruction-following. The tradeoff is that month-to-month comparisons require care because the questions change.
SWE-bench tests models on real GitHub issues: given a repository and an issue description, can the model produce a patch that passes the project's existing test suite? This is harder to contaminate because the task requires understanding a specific codebase, not recalling a memorised solution. SWE-bench Verified (a curated subset with verified human solutions) is more reliable still. GPT-4 Turbo passes around 18% of SWE-bench tasks as of early 2025, a number that gives you immediate intuition for how far we actually are from autonomous software engineering.
GPQA (Graduate-Level Google-Proof Q&A) tests on questions that experts with PhDs struggled with: biology, chemistry, physics at graduate level. The benchmark creators verified that the questions are not easily Google-able and that domain experts achieve around 81% accuracy. GPT-4 scored 39% at its initial release. This gap between "sounds smart" benchmark performance and "actually knows graduate chemistry" is informative. As of GPT-4o, the score has risen to around 53%. That is real improvement, but still a 28-point gap from expert performance.
HELM (Holistic Evaluation of Language Models) from Stanford takes a different approach: rather than a single score, it reports performance across dozens of scenarios and metrics simultaneously. You see accuracy, calibration, robustness, fairness, efficiency, and toxicity for each model on each scenario. It's harder to game because there's no single number to optimise. It's also harder to read, which is why it gets less press coverage than a simple leaderboard.
The pattern among the better benchmarks: they either refresh content continuously (LiveBench), test on tasks with verifiable ground truth that require real reasoning (SWE-bench, GPQA), or resist single-metric gaming (HELM).
Building Your Own Eval Suite
The most reliable evaluation you can run is one built from your own production data. Here is a minimal harness that fits in a single file and integrates with any OpenAI-compatible API:
import json
import time
from dataclasses import dataclass, field
from typing import Callable
import openai
@dataclass
class EvalCase:
"""A single test case: input, expected output, and scoring function."""
id: str
prompt: str
expected: str
# Scorer returns a float in [0, 1] and an explanation string
scorer: Callable[[str, str], tuple[float, str]] = field(repr=False)
metadata: dict = field(default_factory=dict)
@dataclass
class EvalResult:
case_id: str
model: str
response: str
score: float
explanation: str
latency_ms: float
error: str | None = None
def exact_match_scorer(response: str, expected: str) -> tuple[float, str]:
"""Binary scorer: 1.0 if normalised strings match, 0.0 otherwise."""
norm_resp = response.strip().lower()
norm_exp = expected.strip().lower()
if norm_resp == norm_exp:
return 1.0, "exact match"
return 0.0, f"got '{norm_resp[:50]}', expected '{norm_exp[:50]}'"
def substring_scorer(response: str, expected: str) -> tuple[float, str]:
"""1.0 if expected string appears anywhere in the response."""
if expected.lower() in response.lower():
return 1.0, f"found '{expected}' in response"
return 0.0, f"'{expected}' not found in response"
def run_eval(
cases: list[EvalCase],
model: str,
client: openai.OpenAI,
system_prompt: str = "You are a helpful assistant.",
temperature: float = 0.0,
max_tokens: int = 512,
delay_between_calls: float = 0.5,
) -> list[EvalResult]:
"""
Run all eval cases against the specified model.
Uses temperature=0 by default for reproducibility. A delay between
calls avoids rate-limit errors on paid tiers with low RPM limits.
"""
results: list[EvalResult] = []
for i, case in enumerate(cases):
print(f"[{i+1}/{len(cases)}] Running case {case.id}...")
try:
t0 = time.perf_counter()
completion = client.chat.completions.create(
model=model,
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": case.prompt},
],
temperature=temperature,
max_tokens=max_tokens,
)
latency_ms = (time.perf_counter() - t0) * 1000
response_text = completion.choices[0].message.content or ""
score, explanation = case.scorer(response_text, case.expected)
results.append(
EvalResult(
case_id=case.id,
model=model,
response=response_text,
score=score,
explanation=explanation,
latency_ms=round(latency_ms, 1),
)
)
except Exception as exc:
results.append(
EvalResult(
case_id=case.id,
model=model,
response="",
score=0.0,
explanation="",
latency_ms=0.0,
error=str(exc),
)
)
if delay_between_calls > 0:
time.sleep(delay_between_calls)
return results
def summarise(results: list[EvalResult], model: str) -> None:
"""Print a summary table and aggregate stats."""
passed = sum(1 for r in results if r.score >= 1.0)
errors = sum(1 for r in results if r.error)
avg_score = sum(r.score for r in results) / len(results) if results else 0
avg_latency = sum(r.latency_ms for r in results if not r.error) / max(
1, len(results) - errors
)
print(f"\n{'='*60}")
print(f"Model: {model}")
print(f"Cases: {len(results)} | Passed: {passed} | Errors: {errors}")
print(f"Avg score: {avg_score:.3f} | Avg latency: {avg_latency:.0f}ms")
print(f"{'='*60}")
for r in results:
status = "PASS" if r.score >= 1.0 else ("ERR " if r.error else "FAIL")
print(f" [{status}] {r.case_id}: {r.explanation or r.error}")
# --- Example: document Q&A eval ---
if __name__ == "__main__":
client = openai.OpenAI() # Reads OPENAI_API_KEY from environment
# Build your eval set from real production examples.
# These should be cases where you know the correct answer.
SYSTEM = (
"You are a document assistant. Answer questions from the provided "
"context. If the answer is not in the context, say 'I don't know'."
)
cases = [
EvalCase(
id="refusal-out-of-scope",
prompt="Context: The warranty period is 12 months.\nQ: What is the price?",
expected="I don't know",
scorer=substring_scorer,
),
EvalCase(
id="simple-extraction",
prompt="Context: The warranty period is 12 months.\nQ: How long is the warranty?",
expected="12 months",
scorer=substring_scorer,
),
EvalCase(
id="numerical-reasoning",
prompt="Context: Product A costs $50. Product B costs $30.\nQ: What is the combined cost?",
expected="$80",
scorer=substring_scorer,
),
]
for model_name in ["gpt-4o-mini", "gpt-4o"]:
results = run_eval(cases, model_name, client, system_prompt=SYSTEM)
summarise(results, model_name)
Running this against two models produces output like:
[1/3] Running case refusal-out-of-scope...
[2/3] Running case simple-extraction...
[3/3] Running case numerical-reasoning...
============================================================
Model: gpt-4o-mini
Cases: 3 | Passed: 2 | Errors: 0
Avg score: 0.667 | Avg latency: 412ms
============================================================
[FAIL] refusal-out-of-scope: 'I don't know' not found in response
[PASS] simple-extraction: found '12 months' in response
[PASS] numerical-reasoning: found '$80' in response
============================================================
Model: gpt-4o
Cases: 3 | Passed: 3 | Errors: 0
Avg score: 1.000 | Avg latency: 687ms
============================================================
[PASS] refusal-out-of-scope: found 'I don't know' in response
[PASS] simple-extraction: found '12 months' in response
[PASS] numerical-reasoning: found '$80' in response
That refusal-out-of-scope failure from gpt-4o-mini is the kind of failure that matters in production and does not show up in MMLU scores. gpt-4o-mini scores about 82% on MMLU, perfectly respectable. But it hallucinated a price when none was given. That failure cost you money or trust in a real deployment.
A few practices that make eval suites more useful over time:
Regression tracking: Save results to a JSON file with the model name, date, and version. Rerun the eval when you update your prompt or switch models. A score drop is a regression; treat it as one.
Edge case cataloguing: Every time you find a new failure mode in production, add it to the eval set immediately. The eval should grow to reflect your real failure distribution.
Red-teaming as eval: Spend 30 minutes trying to make the model fail on your task. Every successful jailbreak, hallucination pattern, or context-window confusion you find becomes an eval case. Red-teaming produces the most useful eval cases because they come directly from adversarial pressure on your specific deployment.
Calibration eval: Don't just check whether the model is right; check whether it says "I don't know" appropriately when it should. Overconfident wrong answers are often worse than admissions of uncertainty.
Production Considerations
Evaluation infrastructure has its own operational concerns that most teams underestimate.
Eval set drift: Your production distribution changes. A document Q&A system that handles terms-of-service documents in Q1 might be handling sales contracts in Q3. Eval cases built in Q1 may not reflect Q3 failures. Audit your eval set quarterly against real production query logs.
Non-determinism: LLMs at temperature > 0 produce different outputs on repeated runs. Run each eval case 3-5 times for critical cases and report the mean and variance. A model that scores 90% on one run and 70% on the next is not a model you want in production.
Cost budgeting: Running 200 eval cases against 5 candidate models, 3 times each, at GPT-4o prices (around $5/MTok input) costs roughly $1-3 per full run depending on context length. That's sustainable for a weekly CI run. It becomes a budget problem if you're running evals in a tight feedback loop during prompt engineering.
Latency as a first-class metric: The harness above captures latency_ms per case. Include p50 and p99 latency in your eval report. A model that passes 95% of cases with 1200ms p99 might be worse than a model that passes 90% with 300ms p99, depending on your product's latency requirements.
Conclusion
Benchmark scores are a starting point, not a verdict. MMLU, HumanEval, and HellaSwag tell you roughly where a model sits on the capability spectrum. They don't tell you whether it will work on your task, in your domain, with your failure tolerance.
The benchmarks that are worth tracking (LiveBench, SWE-bench Verified, GPQA) resist contamination and gaming through design choices rather than just good intentions. They are worth watching as signals of genuine capability progress.
But none of them replace the twenty minutes it takes to build a minimal eval harness for your actual use case. The eval code in this post is less than 100 lines. The cases you write against your real production data will predict your real production failures more accurately than any published leaderboard.
The industry knows the benchmarks are broken. The reason they persist is that they are easy to report, easy to compare, and they look good in press releases. Your job as an engineer is to know what they actually measure, know where they fail, and build something better for your specific deployment.
Sources
-
Sainz, O., et al. (2023). "NLP Evaluation in trouble: On the Need to Measure LLM Data Contamination for each Benchmark." EMNLP 2023 Findings. https://arxiv.org/abs/2310.18018
-
Mizrahi, M., et al. (2024). "One Prompt To Rule Them All: LLMs for Opinion Summary Evaluation." arXiv:2402.11683. https://arxiv.org/abs/2402.11683
-
Rein, D., et al. (2023). "GPQA: A Graduate-Level Google-Proof Q&A Benchmark." arXiv:2311.12022. https://arxiv.org/abs/2311.12022
-
Biderman, S., et al. (2024). "Lessons from the Trenches on Reproducible Evaluation of Language Models." arXiv:2405.14782. https://arxiv.org/abs/2405.14782
-
Liang, P., et al. (2022). "Holistic Evaluation of Language Models." Transactions on Machine Learning Research. https://arxiv.org/abs/2211.09110
-
Jimenez, C., et al. (2024). "SWE-bench: Can Language Models Resolve Real-World GitHub Issues?" ICLR 2024. https://arxiv.org/abs/2310.06770
About the Author
Toc Am
Founder of AmtocSoft. Writing practical deep-dives on AI engineering, cloud architecture, and developer tooling. Previously built backend systems at scale. Reviews every post published under this byline.
Published: 2026-04-30 · Written with AI assistance, reviewed by Toc Am.
Get These In Your Inbox
Weekly deep-dives on AI engineering, no fluff. Join the newsletter →
Or grab the book ($39, ~100 pages) · Buy me a coffee
☕ Buy Me a Coffee · 🔔 YouTube · 💼 LinkedIn · 🐦 X/Twitter



No comments:
Post a Comment