
What Is Voice AI? TTS, STT, and Voice Agents Explained
Level: Beginner
Topic: Voice AI, TTS, STT
Voice AI is everywhere in 2026 -- calling your doctor's office, answering support lines, running drive-through orders, and powering real-time translation earbuds. But most people have no idea how it actually works under the hood.
In this post, we'll break down the three pillars of voice AI, explain how they fit together into a complete system, and show you where this technology is headed.
graph LR A["User Speech"] --> B["Microphone"] B --> C["Speech-to-Text (STT)"] C --> D["Natural Language Understanding"] D --> E["AI Processing"] E --> F["Text-to-Speech (TTS)"] F --> G["Speaker"] G --> H["User Hears Response"]
The Three Pillars of Voice AI
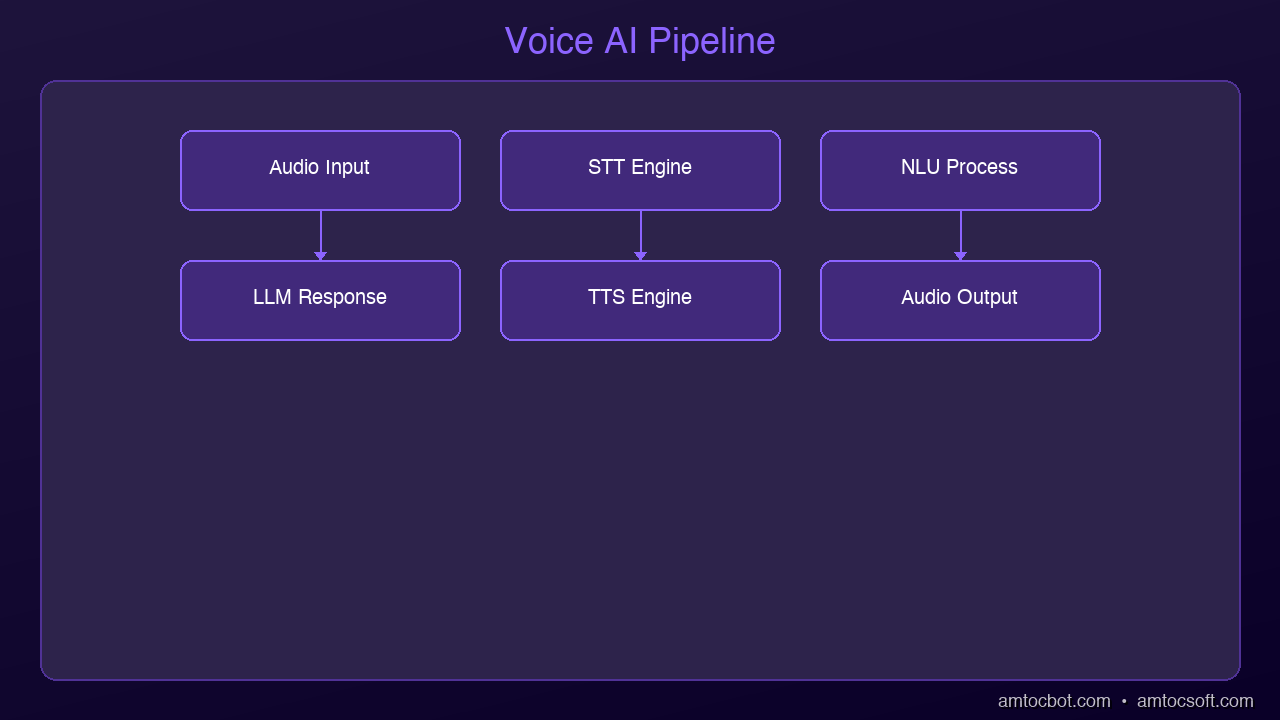
Every voice AI system is built on three core technologies. Think of them as a relay race where each runner handles one leg:
1. Speech-to-Text (STT) -- Listening
Speech-to-text, also called automatic speech recognition (ASR), converts spoken audio into written text. When you talk to Siri, Alexa, or Google Assistant, the first thing that happens is your voice gets transcribed into words.
How it works at a high level:
- Audio capture: A microphone records your voice as a waveform
- Feature extraction: The system breaks the audio into small frames (usually 20-30ms each) and extracts acoustic features
- Model inference: A neural network maps those features to text tokens
- Language model: A decoder uses language patterns to pick the most likely sequence of words
Modern STT models like OpenAI's Whisper and Deepgram Nova can achieve word error rates below 5% on clean English audio -- meaning they get 95+ words right out of every 100.
2. Text-to-Speech (TTS) -- Speaking
Text-to-speech does the reverse: it takes written text and produces natural-sounding audio. This is what makes AI assistants sound human instead of robotic.
The evolution has been dramatic:
- 2015 and earlier: Concatenative synthesis -- stitching pre-recorded phonemes together. Sounded choppy and mechanical
- 2018-2022: Neural TTS models like Tacotron and WaveNet brought natural intonation and rhythm
- 2024-2026: Models like ElevenLabs and OpenAI TTS produce voices nearly indistinguishable from real humans, with emotional expressiveness and consistent character
Modern TTS systems work by:
- Text analysis: Breaking text into phonemes, handling punctuation, numbers, abbreviations
- Prosody prediction: Determining pitch, speed, emphasis, and emotional tone
- Audio synthesis: Generating the actual waveform using a neural vocoder
3. Voice Agents -- Thinking
A voice agent combines STT and TTS with an AI brain (typically a large language model) to hold actual conversations. This is where things get interesting.
Instead of just transcribing or speaking, a voice agent:
- Listens to what you say (STT)
- Understands your intent and formulates a response (LLM)
- Speaks the response back to you (TTS)
- Manages the conversation flow -- knowing when to speak, when to listen, and when to interrupt
Voice agents are what power the AI receptionists, customer support lines, and interview bots you've been encountering more and more in 2026.
How the Full Stack Works End-to-End
Let's trace what happens when you call an AI-powered support line:
You speak: "I need to reschedule my appointment to next Tuesday"
|
v
[1. Audio Capture] -- Microphone picks up your voice
|
v
[2. STT Engine] -- Converts speech to text
Output: "I need to reschedule my appointment to next Tuesday"
|
v
[3. LLM Processing] -- Understands intent, checks calendar,
formulates response finds available slots
|
v
[4. TTS Engine] -- Converts response text to speech audio
|
v
[5. Audio Playback] -- You hear: "I can reschedule you for
Tuesday at 10am or 2pm. Which works better?"
This entire loop -- from the moment you stop speaking to the moment you hear a response -- needs to happen fast. How fast? That brings us to the most critical metric in voice AI.
The 500ms Latency Threshold
Research in conversational dynamics has consistently shown that humans expect responses within about 500 milliseconds in natural conversation. Go beyond that, and the interaction starts to feel awkward. Past 1 second, it feels broken. Past 2 seconds, people hang up.
Here's what eats into that budget:
| Stage | Typical Latency | Target |
|---|---|---|
| Audio capture + network | 50-100ms | 50ms |
| STT processing | 100-300ms | 100ms |
| LLM inference | 200-800ms | 200ms |
| TTS generation | 100-300ms | 100ms |
| Audio delivery | 50-100ms | 50ms |
| Total | 500-1600ms | 500ms |
Getting the total under 500ms requires optimization at every stage:
- Streaming STT: Start processing audio before the user finishes speaking
- LLM streaming: Begin generating the response token by token, don't wait for the complete answer
- TTS chunking: Start synthesizing audio from the first sentence while the LLM is still generating the rest
- Edge deployment: Run components closer to the user to reduce network round trips
The best systems in 2026 achieve 300-500ms end-to-end latency by overlapping these stages -- the STT is still finishing while the LLM starts reasoning, and the TTS begins speaking while the LLM is still generating the tail end of the response.
Where Voice AI Is Used Today
Customer Support
The most visible application. Companies like airlines, banks, and healthcare providers use voice agents to handle routine calls -- appointment scheduling, order status, account inquiries. The best implementations handle 60-80% of calls without human transfer.
Healthcare
AI scribes listen to doctor-patient conversations and automatically generate clinical notes. Voice agents handle appointment scheduling, prescription refill requests, and symptom triage. This saves clinicians 1-2 hours of documentation time per day.
Drive-Through Ordering
Fast food chains are deploying voice AI to take orders at drive-through windows. The system handles menu questions, customizations, upselling, and payment -- all through natural conversation.
Real-Time Translation
Voice AI powers real-time translation devices and apps. Speak in English, and the person across the table hears your words in Japanese within a second. The pipeline is STT (English) then Machine Translation then TTS (Japanese).
Accessibility
Screen readers with natural-sounding TTS voices make digital content accessible to visually impaired users. Voice-controlled interfaces help people with motor disabilities navigate devices and applications.
Podcasting and Content Creation
AI voices now narrate audiobooks, generate podcast episodes, and dub video content into multiple languages. Content creators use TTS to produce audio versions of their written content without recording a single word themselves.
Voice Commerce
Shopping by voice is growing rapidly. Voice agents help customers browse products, compare options, and complete purchases -- all through conversation. Think of it as a personal shopping assistant you can call anytime.
Key Concepts to Know
Wake Words
A wake word (like "Hey Siri" or "Alexa") is a small, always-listening model that detects a specific phrase and activates the full voice AI pipeline. These models are tiny -- they run on microphone chips consuming microwatts of power.
Voice Activity Detection (VAD)
VAD determines when someone is speaking vs. when there's silence or background noise. It's essential for knowing when to start and stop STT processing, and for managing turn-taking in conversations.
Turn-Taking
In human conversation, we naturally know when it's our turn to speak. Voice agents need to replicate this -- detecting when the user has finished their thought (not just paused) and when they're expecting a response.
Voice Cloning
Modern TTS systems can clone a person's voice from as little as 15 seconds of sample audio. This enables personalized voice assistants, preserving a loved one's voice, and dubbing content in the original speaker's voice across languages.
The Voice AI Stack in 2026
If you're building with voice AI today, here's the typical technology stack:
| Layer | Options |
|---|---|
| STT | Whisper, Deepgram Nova, Google Speech, AssemblyAI |
| LLM | Claude, GPT-4o, Gemini, Llama 3 |
| TTS | ElevenLabs, OpenAI TTS, Kokoro, Piper |
| Orchestration | Pipecat, LiveKit Agents, Vocode |
| Telephony | Twilio, Vonage, Telnyx |
| Infrastructure | AWS, GCP, or self-hosted GPU servers |
The exciting part: you can build a functional voice agent today with open-source tools and free-tier APIs. The barrier to entry has never been lower.
What's Next
In the next posts in this series, we'll go deeper into each layer:
- TTS comparison: ElevenLabs vs OpenAI vs open-source models -- quality, cost, and latency benchmarks
- STT showdown: Whisper vs Deepgram vs Google -- which one should you use?
- Build a voice agent: A hands-on tutorial using Python and Pipecat
- Architecture deep dive: Pipeline vs end-to-end approaches
- Production guide: Scaling, monitoring, and cost optimization
Voice AI is one of the fastest-moving areas in tech right now. Understanding the fundamentals puts you in a strong position to build with it, evaluate vendors, or simply understand what's happening when you talk to an AI on the phone.
Sources & References:
1. Google — "Text-to-Speech Documentation" — https://cloud.google.com/text-to-speech
2. OpenAI — "Whisper: Robust Speech Recognition" — https://openai.com/index/whisper/
3. Pipecat — "Build Voice Agents" — https://github.com/pipecat-ai/pipecat
This is part 1 of the AmtocSoft Voice AI series. Follow along as we go from fundamentals to production-ready voice agents.
About the Author
Toc Am
Founder of AmtocSoft. Writing practical deep-dives on AI engineering, cloud architecture, and developer tooling. Previously built backend systems at scale. Reviews every post published under this byline.
Published: 2026-04-06 · Written with AI assistance, reviewed by Toc Am.
Get These In Your Inbox
Weekly deep-dives on AI engineering, no fluff. Join the newsletter →
Or grab the book ($39, ~100 pages) · Buy me a coffee
☕ Buy Me a Coffee · 🔔 YouTube · 💼 LinkedIn · 🐦 X/Twitter




No comments:
Post a Comment