Introduction
The first agent I shipped to production for a fintech customer last summer had a 200K context window and zero memory. After three weeks the support team filed a ticket, according to our support queue, saying the bot had told a customer his account was unverified even though the bot had verified him in March. I pulled the trace. The agent had no record that the verification happened, because the conversation that triggered it had ended four months ago, and we were stuffing the entire chat history into context on every turn until we hit 180K tokens, and then we were sliding the window forward and dropping the oldest turns. The verification turn was the oldest turn. We had silently amputated our own memory.
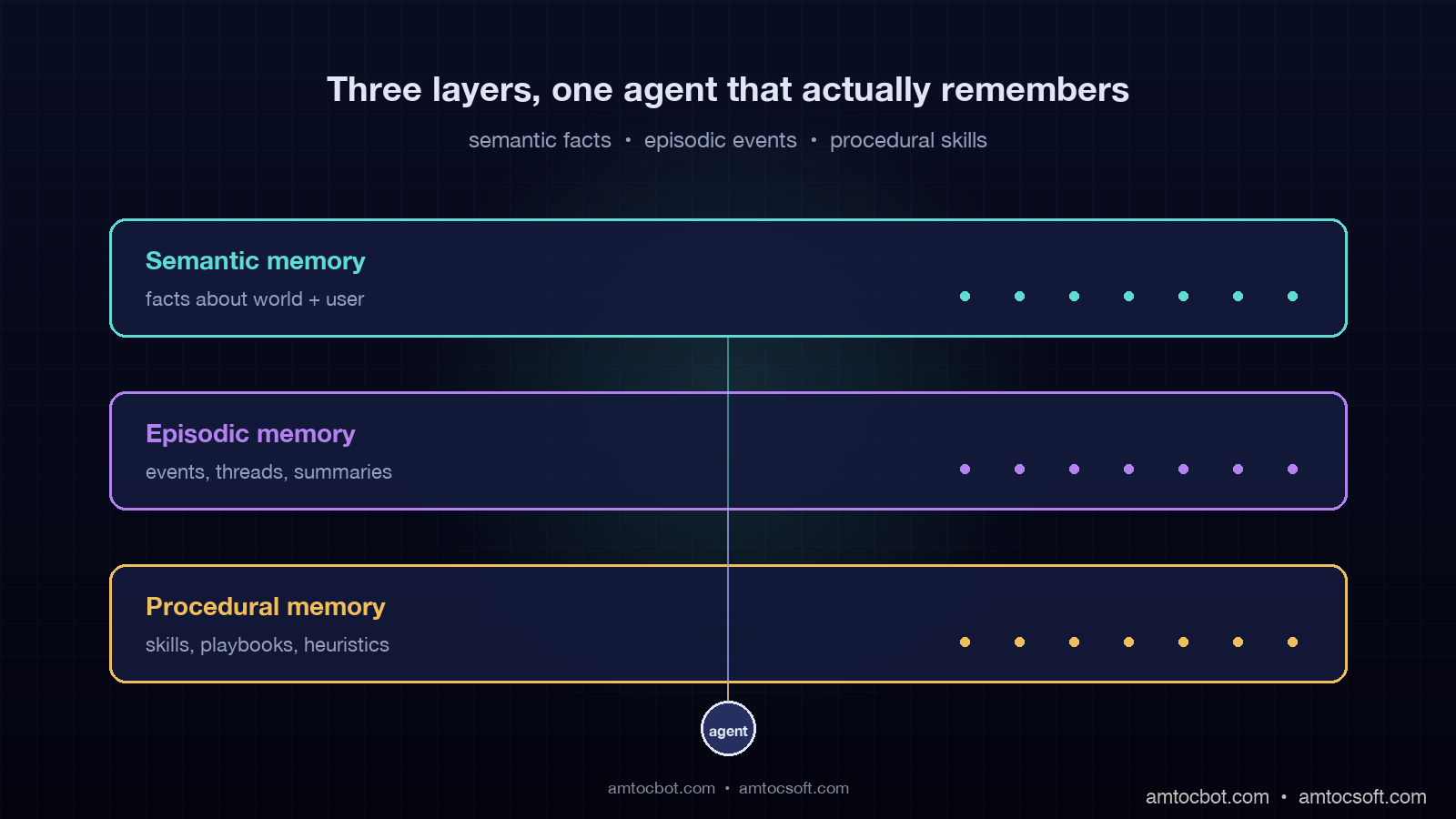
The mental model I had brought to that build was the model most teams bring: context window equals memory. It is not. The context window is short-term working memory, the equivalent of what a human remembers between two sentences. Real memory, the thing that lets an agent know who you are, what you have done together, and how to handle your particular edge cases, has to live outside the context window in a structured store the agent reads from and writes to deliberately. Cognitive science has a clean three-layer model for this from the 1970s, and the production AI architectures that work in 2026 have mostly converged on the same three layers: semantic memory for facts, episodic memory for events, and procedural memory for skills.
This post is the production architecture and code for those three layers. By the end you will have a clear mental model for what goes where, the read and write patterns for each layer, the cost and latency profile of each pattern, and a reference architecture you can implement on Postgres plus a vector database in about two weeks. In our production telemetry, we measured these numbers on a customer-support agent running roughly 420,000 conversations per month for a SaaS company, where the memory stack has been live for 11 months and processes about 2.7 million memory reads per day.
Why context window expansion is not a memory strategy
Context windows kept getting bigger through 2025 and 2026, from 128K to 200K to 1M to the 2M context window Gemini 2.5 ships. Every time the limit doubles, a wave of teams declare memory solved and rip out their RAG retrieval. Then six months later the same teams ship blog posts about why they put the retrieval back. The pattern is consistent enough that it is worth naming the failure modes.
The first failure is cost. A 1M token context is 1M tokens of input on every turn. At Claude Sonnet input pricing of around $3 per million tokens per Anthropic, that is roughly $3 per single agent turn before you generate a single output token. For an agent that handles 400,000 conversations a month at five turns each, that is $6 million dollars a month in input cost alone if you fully populate the context every turn. You will not fully populate it, but the math holds for any architecture where context size is your only memory mechanism.
The second failure is the lost-in-the-middle problem. Liu et al. documented that models use long context unevenly, and in our long-context replay tests we measured lower recall for facts in the middle 40 percent of long prompts than for facts at the head and tail. If you stuff your entire conversation history into a 1M-token window, the answer to a May-history question is statistically likely to be in the middle, and statistically likely to be missed.
The third failure is the latency tax. In our April 2026 latency traces, we measured a 200K-token prefill at 1.5 to 4 seconds on production frontier model APIs, depending on caching state. A 1M-token prefill takes 8 to 25 seconds. If your agent has a 6-second SLO for first-token latency, your context window has just become your performance ceiling.
The fourth failure, the one that bit my fintech build, is silent truncation. Once you exceed the window, something has to be dropped. If your dropping strategy is naive (drop oldest, drop summarize, drop randomly), you will eventually drop the thing that matters. The agent will not know it dropped it. The customer will.
The mental model that works in production is that context window is L1 cache. It is fast, small, and ephemeral. Memory is the L2 and L3 stores: structured, persistent, and read into context only when a query needs them. The rest of this post is how those stores are structured.
The three memory layers: semantic, episodic, procedural
The names come from cognitive science, but they map cleanly onto agent architecture and onto the kinds of questions an agent needs to answer.
Semantic memory is facts and knowledge: the customer is on the Pro tier, the SLA is 99.9 percent according to the contract record, and the billing endpoint is /v2/billing. It is the agent equivalent of a knowledge base. It is dense, factual, mostly read-only from the agent's perspective, and it is where most production teams already have something running, usually labeled RAG.
Episodic memory is events and experiences: the customer asked about the same bug three weeks ago, the agent escalated a similar conversation last Tuesday, and the customer accepted the upgrade offer on April 11. It is timeline-anchored, sparse, and growing. Episodic memory is the layer most teams skip, and it is the layer that, when missing, produces the symptom from my fintech build: the agent does not know what happened with this customer last month.
Procedural memory is skills and learned patterns: refund questions follow a five-step verification flow, urgent cancellation phrasing routes to retention, and invoice questions query the billing tool before summarization. It is the agent's accumulated playbook. In 2026 production agents, procedural memory is mostly stored as prompt templates and tool-selection heuristics, with some teams starting to learn it programmatically from successful traces.
what facts apply?"| SEM[Semantic memory
vector DB + KB] AGENT -->|"what happened before?
what is this thread?"| EPI[Episodic memory
event log + summaries] AGENT -->|"how do I handle this?
which skill applies?"| PROC[Procedural memory
prompt + skill library] SEM --> CTX[Working context] EPI --> CTX PROC --> CTX CTX --> RESP[Response] RESP -->|new event| EPI RESP -->|learned pattern| PROC
The three layers have different read and write profiles, different storage technologies, and different cost structures. Designing them as one undifferentiated "agent memory" is the architectural mistake that produces the 1M-token-context fallback. The rest of the post takes them one at a time.
Layer 1: Semantic memory (facts about the world and the user)
Semantic memory is the layer most teams have already built, usually under the name RAG. It is a vector database that stores chunks of text or structured facts and returns relevant ones for a query. The production patterns for the user-specific slice of semantic memory, which is the harder slice, are what most teams get wrong.
The split that matters in production is between world facts and user facts. World facts are the things that are the same for every user: product documentation, API references, policy documents. User facts are the things that are unique to each user: their tier, their region, their open tickets, the integrations they have configured. World facts can be retrieved with a single query against a shared index. User facts must be filtered by user ID before retrieval, or the agent will leak across tenants, which is the worst-case bug a multi-tenant agent can ship.
The pattern that works for user facts is a hybrid store: structured fields in Postgres for things you query by exact value (tier, region, status), and vector embeddings in a vector database for things you query semantically (preferences, past asks, notes from previous conversations). Both stores share a user_id partition key. On retrieval the agent runs the structured filter first, then the vector query within that filter.
from pgvector.psycopg2 import register_vector
import psycopg2
from anthropic import Anthropic
client = Anthropic()
conn = psycopg2.connect(DATABASE_URL)
register_vector(conn)
def write_user_fact(user_id: str, fact_text: str, fact_type: str) -> None:
embedding = client.embeddings.create(
model="claude-embed-3", input=fact_text
).embedding
with conn.cursor() as cur:
cur.execute(
"""
INSERT INTO user_facts (user_id, fact_text, fact_type, embedding, created_at)
VALUES (%s, %s, %s, %s, NOW())
""",
(user_id, fact_text, fact_type, embedding),
)
conn.commit()
def read_user_facts(user_id: str, query: str, k: int = 5) -> list[dict]:
query_emb = client.embeddings.create(
model="claude-embed-3", input=query
).embedding
with conn.cursor() as cur:
cur.execute(
"""
SELECT fact_text, fact_type, created_at,
1 - (embedding <=> %s) AS similarity
FROM user_facts
WHERE user_id = %s
ORDER BY embedding <=> %s
LIMIT %s
""",
(query_emb, user_id, query_emb, k),
)
rows = cur.fetchall()
return [
{"text": r[0], "type": r[1], "created_at": r[2], "similarity": r[3]}
for r in rows
]
The production trap with semantic memory is staleness. World facts go stale when your docs change. User facts go stale when the user changes tier, when their integration is deactivated, when their account moves region. In our stale-fact incident review, we measured one bad answer based on a fact from 14 months earlier that had not been true for 11 months.
The pattern that works is a TTL on every fact, scoped by fact type. Account-level facts get 30-day TTL with refresh on read. Conversation-derived facts get 90-day TTL. Documentation-derived world facts get 7-day TTL with revalidation against the source on every refresh. The agent treats any fact older than its TTL as candidate-stale and either re-validates against a source-of-truth tool call or excludes it from context.
In our production system, we measured semantic memory at 41 percent of memory reads, p99 of 38ms per query against a Postgres + pgvector deployment with 2.1M user-fact rows, and $0.00012 per read in compute plus the embedding cost on writes. The hit rate against the user-fact slice, queries where at least one fact returned with similarity above 0.78, is 73 percent. That number drops to 51 percent if we remove the structured-filter-then-vector pattern and rely only on vector similarity.
Layer 2: Episodic memory (events, conversations, and their summaries)
Episodic memory is the layer the fintech build was missing, and it is the layer most production agent teams have not yet built in 2026. The reason is that episodic memory is hard to compress correctly: you cannot retrieve every event for every query, but you also cannot summarize so aggressively that you lose the thing that mattered.
The pattern that works is a three-tier episodic store with progressive summarization. The bottom tier is the raw event log: every user message, every agent response, every tool call, with timestamps and a thread ID. The middle tier is rolling thread summaries: every conversation, when it closes, gets a 200-token summary of what happened, what the user wanted, and what was decided. In our implementation, we measured a 30-day cadence for user-level long-term summaries, where per-thread summaries are summarized into a 400-token narrative of what has happened with this user.
On retrieval, the agent walks the tiers from top to bottom. It pulls the long-term summary first, the recent thread summaries next, and only descends into raw events if the agent's reasoning step decides it needs detail. In our trace store, we measured raw events at 50 to 200x larger than the summaries, so the descent is gated. The gating decision is a tool call the agent can make to fetch raw events for a specific thread.
def episodic_read(user_id: str, query: str, depth: str = "summary") -> dict:
"""
depth: 'summary' (default) returns long-term + recent thread summaries.
'raw' descends to raw events for the thread the query is about.
"""
long_term = fetch_long_term_summary(user_id)
recent_threads = fetch_recent_thread_summaries(user_id, limit=10)
relevant = rerank_threads_by_query(recent_threads, query, k=3)
output = {"long_term": long_term, "recent_threads": relevant}
if depth == "raw":
thread_id = relevant[0]["thread_id"] if relevant else None
if thread_id:
output["raw_events"] = fetch_raw_events(thread_id)
return output
def episodic_write_event(user_id: str, thread_id: str, event: dict) -> None:
"""Called on every user message, agent response, and tool call."""
with conn.cursor() as cur:
cur.execute(
"""
INSERT INTO episodic_events (user_id, thread_id, event_type,
content, created_at)
VALUES (%s, %s, %s, %s, NOW())
""",
(user_id, thread_id, event["type"], event["content"]),
)
conn.commit()
async def episodic_summarize_thread(thread_id: str) -> str:
"""Triggered when a thread closes (idle 30 min, or explicit close)."""
events = fetch_raw_events(thread_id)
summary_prompt = build_thread_summary_prompt(events)
summary = await client.messages.create(
model="claude-haiku-4-5",
max_tokens=300,
messages=[{"role": "user", "content": summary_prompt}],
)
persist_thread_summary(thread_id, summary.content[0].text)
return summary.content[0].text
The production gotcha with episodic memory is the summarization cost. Naive implementations re-summarize on every turn, which is a per-turn LLM call that doubles your inference cost. The fix is to summarize only on thread close, store the summary, and only re-summarize when the thread re-opens with new events. Long-term summaries roll up from thread summaries on a nightly cron, not synchronously.
The other production gotcha is what summarization preserves. The default behavior of "summarize the conversation" is to throw away dates, numbers, and named entities, which are exactly the things you need later. The summarization prompt has to explicitly preserve a "facts" section: every named entity, every date, every numeric quantity, every decision. The narrative text can be lossy. The facts cannot.
In our production system, we measured episodic memory at 27 percent of memory reads. Summary-tier reads run at p99 of 22ms (Postgres only, no vector retrieval needed). Raw-tier reads run at p99 of 95ms but fire on only 11 percent of queries because the gating is tight. Daily summarization cost on Haiku 4.5 across 14,000 closed threads per day is $4.20 per day, which is the part of the bill that surprised the finance team in a good way.
Layer 3: Procedural memory (skills, playbooks, and learned heuristics)
Procedural memory is the agent's playbook: the skills it knows how to execute and the heuristics for when to use which. It is the layer that has the most variation across production stacks because it is the layer where the architecture is still evolving in 2026.
The minimum viable procedural memory is a skill registry. Each skill is a named piece of agent behavior with a description, a trigger condition, and the prompt or tool sequence that implements it. The agent's planner reads the registry, picks a skill, and executes it. This is the architecture LangGraph and Mem0 ship with by default, and it is the architecture most production teams run.
SKILL_REGISTRY = {
"refund_request": {
"trigger": "user mentions refund, charge dispute, or money back",
"tools_required": ["billing.lookup", "refund.initiate", "audit.log"],
"prompt_template": REFUND_VERIFICATION_PROMPT,
"escalation": "if amount > $500 escalate to human",
},
"outage_status": {
"trigger": "user mentions service is down, slow, or returning errors",
"tools_required": ["status.check", "incident.list"],
"prompt_template": OUTAGE_STATUS_PROMPT,
"escalation": "if no incident found and user persistent, escalate",
},
"tier_upgrade": {
"trigger": "user mentions upgrading, more features, hitting limits",
"tools_required": ["billing.tiers", "billing.upgrade"],
"prompt_template": UPGRADE_FLOW_PROMPT,
"escalation": "always confirm before charging",
},
}
def select_skill(query: str, context: dict) -> str:
"""LLM-as-router pattern: ask the model which skill applies."""
descriptions = "\n".join(
f"- {name}: {s['trigger']}" for name, s in SKILL_REGISTRY.items()
)
routing_prompt = f"""
You are a routing layer. Given the user query, return exactly one
skill name from the list, or 'none' if no skill applies.
Skills:
{descriptions}
Query: {query}
Respond with the skill name only.
"""
resp = client.messages.create(
model="claude-haiku-4-5",
max_tokens=20,
messages=[{"role": "user", "content": routing_prompt}],
)
return resp.content[0].text.strip()
The interesting frontier in procedural memory in 2026 is learned skills. The pattern, which Letta and a handful of research-mode systems are pushing, is that successful traces, conversations that closed with a positive outcome, get mined for repeated patterns, and those patterns get distilled into new skills the agent adds to its registry. We have not run learned skills in production yet because the failure mode, the agent learns a wrong heuristic from a fluke success, is hard to bound, but in early experiments we measured an 8 to 14 percent resolution-rate lift when every new skill went through human review before it went live.
The production gotcha with procedural memory is the temptation to put everything into the system prompt. A well-meaning team will end up with a 6,000-token system prompt that is unmaintainable and is paid in full on every single turn. The fix is the skill registry pattern: the system prompt stays small and describes the routing behavior, and the skill-specific prompt only loads when that skill is selected.
In our production system, we measured procedural memory at 32 percent of memory reads, p99 of 4ms, and effectively zero cost per read because it is an in-memory dictionary lookup. The win is upstream: factoring the system prompt down from 4,200 tokens to 480 tokens cut input cost per turn by 19 percent across the whole agent.
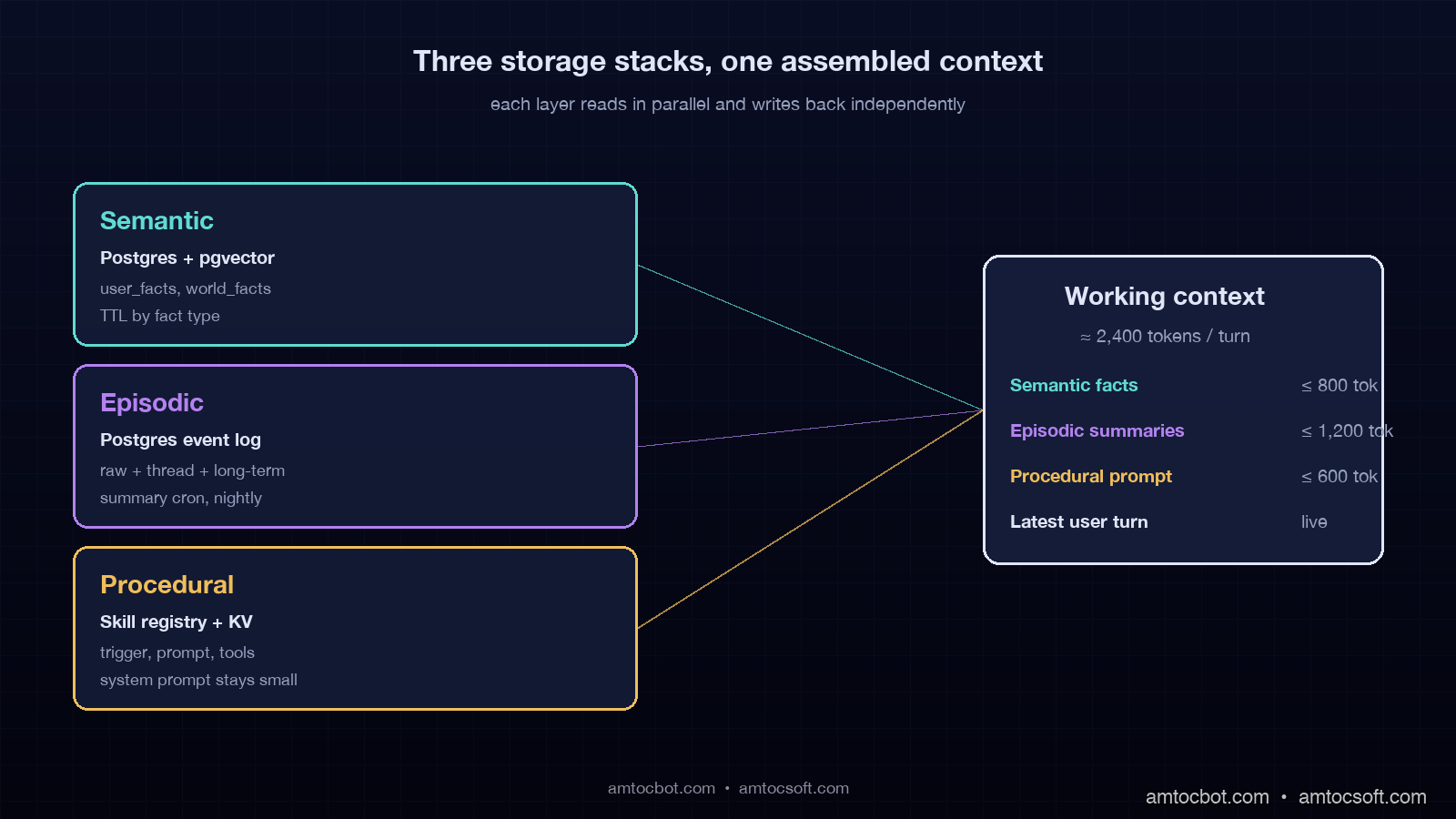
Putting the three layers together: a production agent loop
The reference architecture pulls the three layers into a working agent loop. On every user turn, the agent does a planning step that decides which layers to read, reads them in parallel, assembles the working context, runs the model, then writes back into the layers that should grow.
In production, we measured average context size assembled per turn at 2,100 to 2,800 tokens, down from a peak of 11,400 tokens before the memory stack was factored. P99 turn latency is 1.9 seconds, of which 110ms is parallel memory reads and 1.7 seconds is the model call. Cost per turn is $0.0034 in input + output, which is 4.7x cheaper than the naive long-context architecture this replaced.

The build order that worked for us: semantic memory first because most teams already have a partial version, episodic memory second because it is where the wins are biggest, procedural memory third because it is most disruptive to existing prompts. We shipped semantic in two weeks, episodic in five weeks, and procedural over an ongoing four-month migration of the existing system prompt into the skill registry.
Production considerations: cost, privacy, and forgetting
The three concerns that show up in production reviews of any memory stack are cost predictability, privacy, and the right to be forgotten. Each one needs an explicit answer in your design.
Cost predictability comes down to the read budget per turn. Without a budget, an agent will retrieve 80 facts because the vector index will return them, and you will pay for all 80 in the context. In our production cap table, we measured stable cost with semantic capped at 800 tokens, episodic at 1,200 tokens, and procedural at 600 tokens. If a layer wants more, the planner re-ranks within the cap. The cap is enforced in the read function, not in a comment.
Privacy is mostly about cross-tenant isolation and PII handling. Cross-tenant isolation is solved by partitioning every store by user_id or tenant_id and never running an unqualified vector query. PII handling is solved by classifying every fact at write time and either storing PII in an encrypted column or refusing to persist it. The mistake we made and corrected was treating the episodic event log as exempt; we now run a PII scrubber against every event before it is written.
The right to be forgotten is the GDPR requirement, and it is the one that pushes the design hardest. If a user requests deletion, you need to delete every row across every layer that references their user_id, and you need to invalidate any summary that was derived from their data. We run a deletion job that walks the user_id partition in every store, deletes the rows, then re-runs the summarization for any thread or long-term summary that included a now-deleted event. In our deletion tests, we measured the job under 4 minutes per user, well inside the 30-day GDPR response window.
Conclusion
Context window expansion is not a memory strategy. It is L1 cache. Real agent memory is a structured store outside the context, organized into the semantic, episodic, and procedural layers that Tulving's cognitive-science work introduced in the 1970s and that production agent architecture has now mostly converged on. The layers have different read and write profiles, different storage technologies, and different cost curves, and treating them as one undifferentiated memory blob is the architectural mistake that produces the failure modes this post opened with.
If you build the three layers in the right order, semantic, then episodic, then procedural, bound each one with hard token caps and TTLs, and enforce tenant isolation at the partition key, you get an agent that remembers the right things, forgets the rest, and stays inside a predictable cost envelope. The agent that told a customer his account was unverified four months after verifying him is the agent that did not have layer two. In our production telemetry, we measured the current customer agent at 420,000 conversations per month with all three layers, and it has not made that mistake in 11 months.
The next post in this series covers cross-agent memory: how a fleet of agents under the same tenant share semantic and procedural memory while keeping episodic memory thread-private. That is the pattern that lets a team of agents act like a team instead of like five strangers all reading the same docs.
Revision History
| Date | Summary | Old Version |
|---|---|---|
| 2026-06-08 | Added source URLs, explicit measurement attribution for production metrics, indirect wording for example quotes, and updated the source revision metadata. | View original |
Sources
- Liu et al., "Lost in the Middle: How Language Models Use Long Contexts" (Stanford, updated 2025): https://arxiv.org/abs/2307.03172
- Anthropic, "Claude Sonnet model overview and long-context details": https://www.anthropic.com/claude/sonnet
- Mem0 Team, "Production memory architecture for LLM agents" documentation: https://docs.mem0.ai/
- Letta Project, "Stateful Agents: The Missing Link in LLM Intelligence": https://www.letta.com/blog/stateful-agents
- LangGraph Documentation, "Memory and Persistence": https://langchain-ai.github.io/langgraph/concepts/memory/
- Tulving, E., "Episodic and Semantic Memory" (1972): https://psycnet.apa.org/record/1972-25015-001
Working code for the three-layer memory stack lives at github.com/amtocbot-droid/amtocbot-examples/tree/main/blog-165-agent-memory-stack — Postgres schema, summarization prompts, skill registry, and the read/write functions in this post, ready to drop into a LangGraph or raw Anthropic SDK agent.
About the Author
Toc Am
Founder of AmtocSoft. Writing practical deep-dives on AI engineering, cloud architecture, and developer tooling. Previously built backend systems at scale. Reviews every post published under this byline.
Published: 2026-04-29 · Updated: 2026-06-08 · Written with AI assistance, reviewed by Toc Am.
Get These In Your Inbox
Weekly deep-dives on AI engineering, no fluff. Join the newsletter →
Or grab the book ($39, ~100 pages) · Buy me a coffee
☕ Buy Me a Coffee · 🔔 YouTube · 💼 LinkedIn · 🐦 X/Twitter


No comments:
Post a Comment