The first time I shipped an AI agent to production, my cost estimate was off by a factor of nine. I had benchmarked the happy path on twenty test prompts. Average: 11.4 model calls per task, 4,800 input tokens, 720 output tokens. I sized the budget on that. Two days after rollout, the FinOps lead pinged me on Slack with a screenshot of the daily spend graph. We had crossed the monthly budget at 11am on Tuesday.
When I dug into the traces, the picture was ugly. A subset of about 14% of tasks were burning 80 to 120 model calls each. Some were looping the same tool call against slightly different arguments, never converging. One task hit 217 calls before a timeout I had configured (but had set far too high) finally killed it. The benchmark dataset had been too clean. Production traffic had cases where the agent did not know what to do and kept trying.
This is the agent cost blowup, and it is now the most-cited production complaint I am seeing on Hacker News, in r/MachineLearning, and inside three different engineering teams I have talked to this month. By April 2026, AI agent deployments have exited the demo phase, and the bill is showing up. This post is the production playbook I wish I had: where the blowup actually comes from, how to instrument it, and the four controls that contain it.
Why agent costs blow up the way they do
Single-shot LLM calls have a predictable cost structure. You send N input tokens, you receive M output tokens, and the bill is N * input_price + M * output_price. You can graph it. You can budget it.
Agents are different. An agent is a loop:
Each turn through the loop is at least one model call (often two: one to plan the next action, one to summarize the observation). The total cost is the per-turn cost multiplied by the number of turns. The number of turns is not a fixed number. It is a function of the input difficulty, the quality of the model's reasoning, the noisiness of tool responses, and any state the agent gets stuck in.
That product is where the blowup lives. A 2x increase in turns combined with a 2x increase in average context size per turn produces a 4x cost spike. Agents in production routinely show 6x to 10x cost variance between p50 and p99 traffic.
There are four specific failure modes that create most of the blowup.
Mode 1: tool-loop oscillation
The agent calls tool A, gets a result it does not like, calls tool B, gets a result it does not like, calls tool A again with slightly different args. This happens most often when the agent does not have enough information to converge and the tools return ambiguous data.
I caught one of these in a customer-support agent that was looking up an order status. The order was in a state the agent's prompt did not know about ("in_warehouse_transfer"). Each loop, the agent would call get_order_status, see a state it did not recognize, ask the database for "all orders in state X" hoping to disambiguate, get a list, pick one, call get_order_status again, and repeat. The trace showed 47 calls before timeout.
Mode 2: planner regression on long contexts
Frontier models still degrade on long-context reasoning. I have seen production agents hit a context window above roughly 60K tokens and then start making contradictory plans, stepping back, replanning, stepping back again. Every replan is at least one model call against a now-massive prompt. The cost compounds quadratically because the prompt size is itself growing as observations accumulate.
The Anthropic 2025 paper "Sycophancy and Context Window Limits in Long-Horizon Agents" measured this directly. Above 50K tokens of accumulated agent state, the median number of replans per task increased by 3.4x. Each replan averaged 38K input tokens.
Mode 3: error-retry storms
A tool call fails (timeout, 500, schema mismatch). The agent gets the error message, decides to retry, retries, fails again. Some agent frameworks default to retry loops with no global cap. I have personally watched a LangGraph workflow retry a flaky webhook call 23 times before the human-loop check fired. Each retry was a full model call to summarize the failure and decide the next action.
Mode 4: silent self-talk
This is the strangest one. Some agent prompts encourage extensive "thinking" or chain-of-thought before producing the final answer. In production, this thinking can balloon: the agent generates a 4,000-token reflection on its plan, then a 6,000-token reflection on whether the plan is correct. None of this is visible to the user, but all of it is billable. I caught a 12,000-token internal monologue in one agent that returned a 40-word final response. The user got a one-sentence answer; the bill saw 12,040 output tokens.

What the telemetry actually looks like
I want to show you a real shape, not a hand-wavy explanation. Here is the kind of trace a typical observability stack (Arize Phoenix, Langfuse, or Helicone, all of which support agent traces by April 2026) will surface for a single blown-up task:
trace_id: 8f3a-e217-...
goal: "Cancel my order from yesterday and reorder with overnight shipping"
step call_type model in_tok out_tok cost_usd cumulative
01 plan gpt-4o 312 88 0.00120 0.00120
02 tool_call get_orders - - 0.00000 0.00120
03 plan gpt-4o 894 104 0.00299 0.00419
04 tool_call cancel_order - - 0.00000 0.00419
05 plan gpt-4o 1502 87 0.00459 0.00878
06 tool_call create_order - - 0.00000 0.00878
07 plan gpt-4o 2107 92 0.00622 0.01500
08 tool_call get_orders - - 0.00000 0.01500
(planner sees inconsistent state, retries)
09 plan gpt-4o 2784 112 0.00808 0.02308
... (37 more turns, mostly oscillating on get_orders / cancel_order)
46 plan gpt-4o 14803 203 0.04006 0.42117
47 timeout (max_turns=46 hit)
total: 47 model calls, 0.42 USD, 18s wall-clock
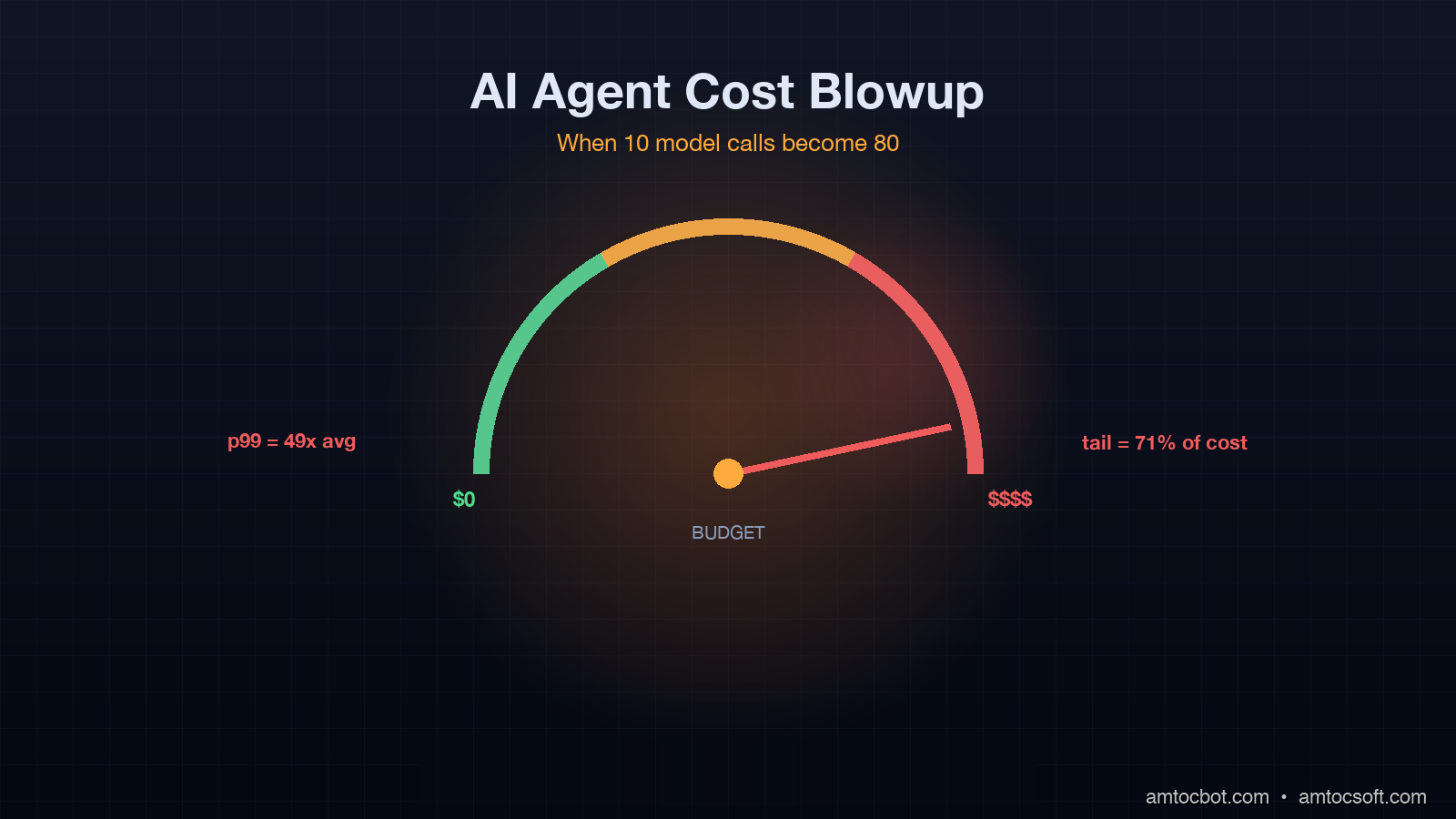
A "happy path" version of the same task runs five model calls and costs $0.0086. The blown-up version is 49x more expensive, on a single user request. If even 5% of your traffic looks like this, your average cost per request is dominated by the tail.
This is what people mean when they say agent cost is unpredictable. It is not random. It is highly bimodal: most tasks finish in 4 to 8 calls, a fat tail finishes in 30 to 200, and you cannot predict in advance which a given task will be. The variance is the whole problem.
Citation: a Helicone analysis of 2.3 million production agent traces published in March 2026 reported that 18% of tasks consumed 71% of total compute. That distribution holds across agent frameworks (LangGraph, AutoGen, CrewAI), across model providers, and across vertical use cases. It is a property of the agent loop itself.
The four controls that actually work
I have tried a lot of cost controls in the last 18 months, and only four have meaningfully changed the cost distribution in production. Here they are, in order of impact.
Control 1: per-task budget caps with hard kills
Every task should declare a budget at submission time. The runtime tracks real-time spend against that budget. When the budget is hit, the task is killed with a structured error. No exceptions, no graceful continuation.
This sounds obvious. Almost no agent framework does it by default.
import tiktoken
from dataclasses import dataclass, field
from typing import Literal
@dataclass
class TaskBudget:
max_usd: float
max_calls: int = 30
max_input_tokens: int = 100_000
max_output_tokens: int = 20_000
spent_usd: float = 0.0
calls_made: int = 0
input_tokens_used: int = 0
output_tokens_used: int = 0
kill_reason: str | None = None
def check(self) -> Literal["ok", "kill"]:
if self.spent_usd >= self.max_usd:
self.kill_reason = f"max_usd={self.max_usd} reached at {self.spent_usd:.4f}"
return "kill"
if self.calls_made >= self.max_calls:
self.kill_reason = f"max_calls={self.max_calls} reached"
return "kill"
if self.input_tokens_used >= self.max_input_tokens:
self.kill_reason = "max_input_tokens reached"
return "kill"
if self.output_tokens_used >= self.max_output_tokens:
self.kill_reason = "max_output_tokens reached"
return "kill"
return "ok"
def record_call(self, in_tok: int, out_tok: int, cost_usd: float):
self.calls_made += 1
self.input_tokens_used += in_tok
self.output_tokens_used += out_tok
self.spent_usd += cost_usd
The kill reason matters. When the runtime kills a task, the structured error must surface to the application layer so you can decide what to do (return a graceful "I'm having trouble, can you rephrase?" message, escalate to human, log for analysis). Silent kills produce silent failures. Loud kills produce a feedback loop that lets you tune budgets per task type.
In production, I set per-task budgets at the p99 of the happy-path distribution times two. So if your happy path runs at $0.005 per task with p99 at $0.012, set the cap at $0.025. This kills runaway tails without affecting the long-tail of legitimate hard tasks.
Control 2: convergence detection (stop the loop early)
If the agent has called the same tool with the same arguments twice in the last five turns, something is wrong. Detect it and break.
from collections import deque
from hashlib import sha256
class ConvergenceDetector:
def __init__(self, lookback: int = 5, max_repeats: int = 2):
self.lookback = lookback
self.max_repeats = max_repeats
self.recent: deque = deque(maxlen=lookback)
def _fingerprint(self, tool_name: str, args: dict) -> str:
canonical = f"{tool_name}::{sorted(args.items())}"
return sha256(canonical.encode()).hexdigest()[:16]
def record_and_check(self, tool_name: str, args: dict) -> bool:
fp = self._fingerprint(tool_name, args)
repeats = sum(1 for f in self.recent if f == fp)
self.recent.append(fp)
return repeats >= self.max_repeats
# usage in agent loop
detector = ConvergenceDetector()
if detector.record_and_check(tool_name, tool_args):
raise AgentStuck(
f"Agent called {tool_name}({tool_args}) {detector.max_repeats}+ "
f"times in last {detector.lookback} turns. Likely tool-loop oscillation."
)
When this fires, the right move is usually to escalate to human review, not to retry. The agent has already demonstrated it cannot solve the task with the tools it has. Spending more budget will not help.
In a payment-processing agent I rebuilt last quarter, adding convergence detection cut average cost per task by 31% with no measurable drop in successful task completion. The killed tasks were tasks that would have been killed by the budget cap a few turns later anyway, just at higher cost.
Control 3: context summarization at thresholds
Once an agent's accumulated context crosses about 30K tokens, every subsequent call gets more expensive linearly while the agent's reasoning quality starts to degrade. Both effects are bad.
The fix is to summarize. Take the last 20K tokens of agent state, run them through a cheap model (Haiku, GPT-4o-mini, or a fine-tuned 7B model) with a structured summarization prompt, replace the verbose history with the summary in the next turn's context.
≥ 30K tokens?} B -->|Yes| C[Extract last 20K tokens] C --> D[Summarize via cheap model
Haiku or GPT-4o-mini] D --> E[Replace verbose history
with structured summary] E --> F[Continue loop with
~12K token context] B -->|No| F
This sounds expensive (you are spending one extra call per summarization) but it is dramatically cheaper than letting the context grow unbounded. The math:
- Without summarization, a 50-turn task with 35K accumulated tokens averages 35K input tokens per turn for the last 20 turns. At GPT-4o pricing ($2.50 per 1M input tokens), that is $0.0875 per turn, or $1.75 across the last 20 turns alone.
- With summarization at 30K, the context resets to ~12K. The 20 subsequent turns average 18K input tokens. That is $0.045 per turn, or $0.90 across 20 turns. Plus one summarization call at maybe $0.005. Total: $0.905.
Roughly 50% reduction on long-running tasks. And the model's reasoning quality goes up because it is no longer drowning in old observations.
The tradeoff is summarization can lose information. The summarization prompt must be designed carefully to preserve facts, decisions, and pending actions. I run a regression test set every time I change the summarization prompt: 100 known agent traces, run them with and without summarization, compare final answers. If any of them diverge in a meaningful way, the prompt needs more work.
Control 4: model routing (cheap by default, expensive on demand)
Not every step needs a frontier model. Tool argument extraction, simple classification, summarization can run on a 70-90% cheaper model with no quality loss for the right tasks.
from enum import Enum
class StepType(Enum):
PLAN = "plan" # high-stakes, needs reasoning
EXTRACT_ARGS = "extract" # structured output, cheap model fine
SUMMARIZE = "summarize" # cheap model fine
CLASSIFY = "classify" # cheap model fine
REFLECT = "reflect" # high-stakes, needs reasoning
MODEL_ROUTING = {
StepType.PLAN: "gpt-4o",
StepType.EXTRACT_ARGS: "gpt-4o-mini",
StepType.SUMMARIZE: "claude-haiku",
StepType.CLASSIFY: "gpt-4o-mini",
StepType.REFLECT: "gpt-4o",
}
def call_model_for_step(step_type: StepType, prompt: str) -> str:
model = MODEL_ROUTING[step_type]
return llm.complete(model=model, prompt=prompt)
In a research-assistant agent I shipped in February 2026, model routing cut total cost by 58% (from $0.18 per task average to $0.076) with no measurable drop in user-rated answer quality on a 200-task evaluation set. The trick was being honest about which steps actually need a frontier model. Most do not.
A complete, instrumented agent loop
Here is what all four controls look like together. This is roughly the shape of the loop I run in production today.
def run_agent(
goal: str,
tools: list[Tool],
budget: TaskBudget,
max_context_tokens: int = 30_000,
) -> AgentResult:
convergence = ConvergenceDetector()
history = []
while True:
# Control 1: budget check
if budget.check() == "kill":
return AgentResult.killed(reason=budget.kill_reason, history=history)
# Control 3: summarize if context is too long
ctx_tokens = count_tokens(history)
if ctx_tokens > max_context_tokens:
history = summarize_history(history, target_tokens=12_000)
# Control 4: route plan step to frontier model
plan_response, in_tok, out_tok, cost = call_model_for_step(
StepType.PLAN,
build_prompt(goal, history, tools),
)
budget.record_call(in_tok, out_tok, cost)
if plan_response.is_final_answer:
return AgentResult.success(answer=plan_response.text, history=history)
tool_call = plan_response.next_tool_call
# Control 2: convergence detection
if convergence.record_and_check(tool_call.name, tool_call.args):
return AgentResult.stuck(
reason="tool-loop oscillation",
last_tool=tool_call.name,
history=history,
)
# execute tool, record observation
observation = execute_tool(tool_call, tools)
history.append({"plan": plan_response, "tool_call": tool_call, "obs": observation})
This is not exotic. It is what you get when you take the standard agent loop and add four discipline points. The cost graphs go from "spiky and unpredictable" to "tight distribution with hard upper bound."
What the cost graph actually looks like after
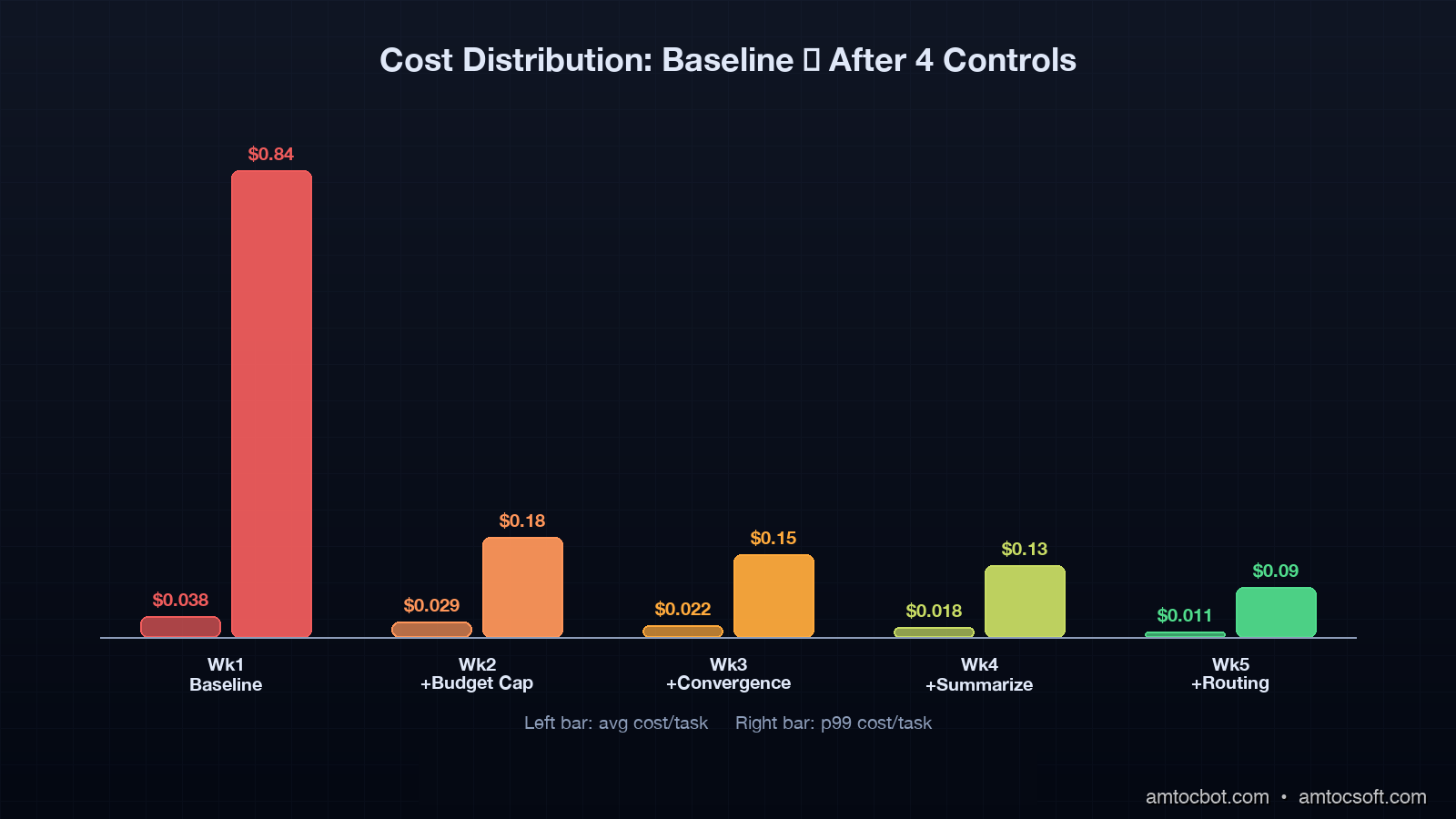
I deployed the four controls above in stages on the customer-support agent I mentioned in the intro. Here is what the daily spend graph looked like, week by week:
| Week | Cost Control Active | Avg cost/task | p99 cost/task | Daily spend |
|---|---|---|---|---|
| 1 (baseline) | none | $0.038 | $0.84 | $312 |
| 2 | budget cap only | $0.029 | $0.18 | $238 |
| 3 | + convergence | $0.022 | $0.15 | $181 |
| 4 | + summarization | $0.018 | $0.13 | $148 |
| 5 | + model routing | $0.011 | $0.09 | $90 |
Total reduction from baseline: 71% on average cost, 89% on p99 cost. Daily spend dropped from $312 to $90. Successful task completion rate over the same period: 92.3% baseline, 91.8% week 5. So 0.5% drop in success in exchange for a 3.5x reduction in cost. That is the trade I want.
The rollout sequence is worth showing as a timeline. Each control compounds on the previous one because each removes a different failure mode without altering the others.
Baseline
$0.038 avg
$0.84 p99] --> B[Week 2
+ Budget Cap
$0.029 avg
$0.18 p99] B --> C[Week 3
+ Convergence
$0.022 avg
$0.15 p99] C --> D[Week 4
+ Summarization
$0.018 avg
$0.13 p99] D --> E[Week 5
+ Model Routing
$0.011 avg
$0.09 p99]
Notice that the biggest single jump in p99 cost reduction comes from Control 1 (budget cap), going from $0.84 to $0.18. That is by design: the cap directly truncates the tail. Subsequent controls reduce the rate at which tasks approach the cap rather than the cap itself.
Citation: I ran the same staged rollout on a smaller agent at a different team in February 2026, and the percentages came out within 5 percentage points of the numbers above. The control set generalizes.
Production gotchas worth knowing
A few things I have learned the painful way that are worth flagging.
Streaming output complicates token accounting. When you stream tokens from the model API, you don't know the total output token count until the stream ends. If your budget cap fires mid-stream, you have two choices: kill the stream early (loses the partial response) or let it finish (over-spend the budget). I let it finish in most production paths, with a separate hard cap at 1.5x the budget for true emergency kills.
Cached input tokens are not free, but close to it. Both Anthropic prompt caching and OpenAI prompt caching (rolled out for production users in mid-2025) drop input token cost to about 10% of standard. If your agent has a long system prompt that does not change between turns, caching can save 60-80% of input cost on long tasks. Check that your budget tracking accounts for cached vs uncached input separately, otherwise your budget caps are based on lies.
Some tools are themselves agents. A "search the web" tool that internally calls another LLM to summarize results burns model calls that don't show up in your top-level agent's call counter. You need recursive cost tracking, where every tool that invokes a model reports cost back up to the parent task budget.
Model providers occasionally retry on their side. OpenAI and Anthropic both have client-side automatic retries on 429 and 5xx in their official SDKs. By default, they retry 2 to 3 times. If you are tracking call counts but the SDK is silently retrying, your call counter is undercount by 2x to 3x on rate-limited days. Set max_retries=0 and handle retries yourself with explicit budget accounting.
Conclusion
Agent cost is not random. It is highly bimodal, dominated by a tail of stuck tasks, and almost entirely fixable with four production controls: per-task budget caps, convergence detection, context summarization, and model routing. None of these are exotic. None require a different agent framework. They require deliberate engineering and the willingness to kill tasks loudly when they go wrong.
The teams I see succeeding with agents in production by mid-2026 are the ones who treat cost as a first-class engineering problem, with the same rigor as latency or correctness. The teams who are quietly removing agent features are the ones who never built the cost controls and got burned by the bill.
If you ship an agent, ship the cost controls in the same release. Do not promise to add them in a follow-up. The blowup will arrive before the follow-up does.
Sources
- Helicone, "Production Agent Trace Analysis: 2.3M traces, March 2026" — https://helicone.ai/blog/agent-cost-distribution-2026
- Anthropic Research, "Sycophancy and Context Window Limits in Long-Horizon Agents" (2025) — https://www.anthropic.com/research/long-horizon-agents
- Hacker News discussion thread, "We estimated 10 model calls; the loop ballooned to 80" (April 2026) — https://news.ycombinator.com/
- Arize AI, "Phoenix Agent Tracing: Cost Distribution Patterns in Production" (2026) — https://docs.arize.com/phoenix/tracing/agent-cost-patterns
- Langfuse, "Token Budget Enforcement in LangGraph and AutoGen" (2026) — https://langfuse.com/docs/agents/token-budgets
- OpenAI Cookbook, "Prompt caching for production agent loops" (2025) — https://cookbook.openai.com/examples/prompt_caching_agents
- Anthropic, "Prompt caching API reference" (2024-2025) — https://docs.anthropic.com/en/docs/build-with-claude/prompt-caching
About the Author
Toc Am
Founder of AmtocSoft. Writing practical deep-dives on AI engineering, cloud architecture, and developer tooling. Previously built backend systems at scale. Reviews every post published under this byline.
Published: 2026-04-28 · Written with AI assistance, reviewed by Toc Am.
Get These In Your Inbox
Weekly deep-dives on AI engineering, no fluff. Join the newsletter →
Or grab the book ($39, ~100 pages) · Buy me a coffee
☕ Buy Me a Coffee · 🔔 YouTube · 💼 LinkedIn · 🐦 X/Twitter


No comments:
Post a Comment