
Introduction
The first time an agent I shipped had to be GDPR-erased, I learned a small fact that nobody had told me: a vector index does not forget. The customer was a UK insurance broker. The agent was a customer-support bot with episodic memory backed by a Qdrant collection where we measured 1.7 million summaries of past conversations. A single user filed a Right-to-be-Forgotten request through the customer's privacy portal at 09:41 on a Tuesday in October 2025. By 11:00 we had located the user's session IDs in Postgres, deleted their conversation rows, and confirmed the deletion to the privacy team. By 14:00 the privacy team had asked, reasonably, whether the agent could still answer questions about that user. By 14:30 we had run the agent against a test prompt referencing the user's first name and policy number, and the agent had returned a fluent, accurate, and terrifying summary of three of the user's prior conversations, drawn from vector-search hits we had not realised existed. The conversations were technically deleted from Postgres. The embeddings were still in the vector store. The agent was still answering from them.
That afternoon turned into a four-day deletion sprint that involved finding every embedding tagged with the user's tenant ID, every chunk of summary text that contained the user's name, every cached query result, and every transcript stored in S3. We got there. The customer's privacy team filed an incident report anyway, because we had been late. The lesson I took from that incident, the one I have built into every agent platform since, is the only PII you can guarantee will not leak from agent memory is PII that never entered agent memory in the first place. Redaction has to happen before the write, not after the regret.
This post is the playbook from that incident, plus the patterns I have hardened across six more agent platforms since, two of which have now passed full GDPR Article 17 audits and one of which is mid-flight on EU AI Act Article 14 traceability. The patterns are practical, opinionated, and battle-tested. They are not the only way to do this. They are the way I have not had to apologise for.
Why Agent Memory Is The New Privacy Surface
Agent memory in 2026 is not one thing. The post-126 patterns blog (post 165) breaks it down into three layers: working memory inside the prompt, episodic memory of past sessions in a vector store, and procedural memory of learned tool sequences. Each layer is a different privacy risk. Working memory is short-lived but fully observable to the model and any logs it touches. Episodic memory is long-lived, retrieved by similarity, and almost always the first place a privacy review trips up. Procedural memory is the smallest in volume but the hardest to audit because it is encoded as patterns rather than rows.
The compliance picture has tightened. GDPR Article 17 has been load-bearing since 2018. The 2025 court decisions in Germany and France clarified that vector embeddings derived from personal data are themselves personal data, which means the right to erasure applies to them. The EU AI Act, with its August 2026 deadline for Article 14 traceability, requires that high-risk AI systems can show what data was used to produce any given output. The California CPRA, the Colorado AI Act, and the UK Data Protection and Digital Information Act all push in the same direction. By the second half of 2026, "the embedding cannot be reversed" is no longer a defence the regulators accept. Several of them, citing recent academic work on embedding inversion, have called the claim factually wrong.
The threat model for agent memory has four parts. The user's PII can leak to the LLM provider in the prompt. The PII can leak to the vector store, which is often hosted by a different vendor. The PII can leak to logs, which often go to a third observability platform. And the PII can leak across tenants if the memory store is shared without strict isolation. Each of these is a distinct breach class. Each requires its own defence. The redaction patterns below are designed to address all four, layered, with each layer failing closed.
The Core Pattern: Redact Before Write, Not After Read
The most important architectural decision is where redaction lives. Two patterns dominate. In the first, redaction sits between the agent and the LLM at read time, scrubbing PII from prompts as they leave. In the second, redaction sits between the agent input and the memory store at write time, scrubbing PII before it ever lands. Both are useful. Only the second prevents the GDPR sprint I described above.
Read-time redaction can never be retroactive. If a memory was written with PII three months ago, a read-time scrubber cannot un-leak it; the PII is already in the index, indexed, and retrievable. Write-time redaction is harder because it is more invasive, but it is the only pattern that gives you the guarantee the privacy team will ask for: this memory store has never contained the user's PII. Read-time scrubbing is a useful additional defence, but it is a defence in depth, not a primary control.
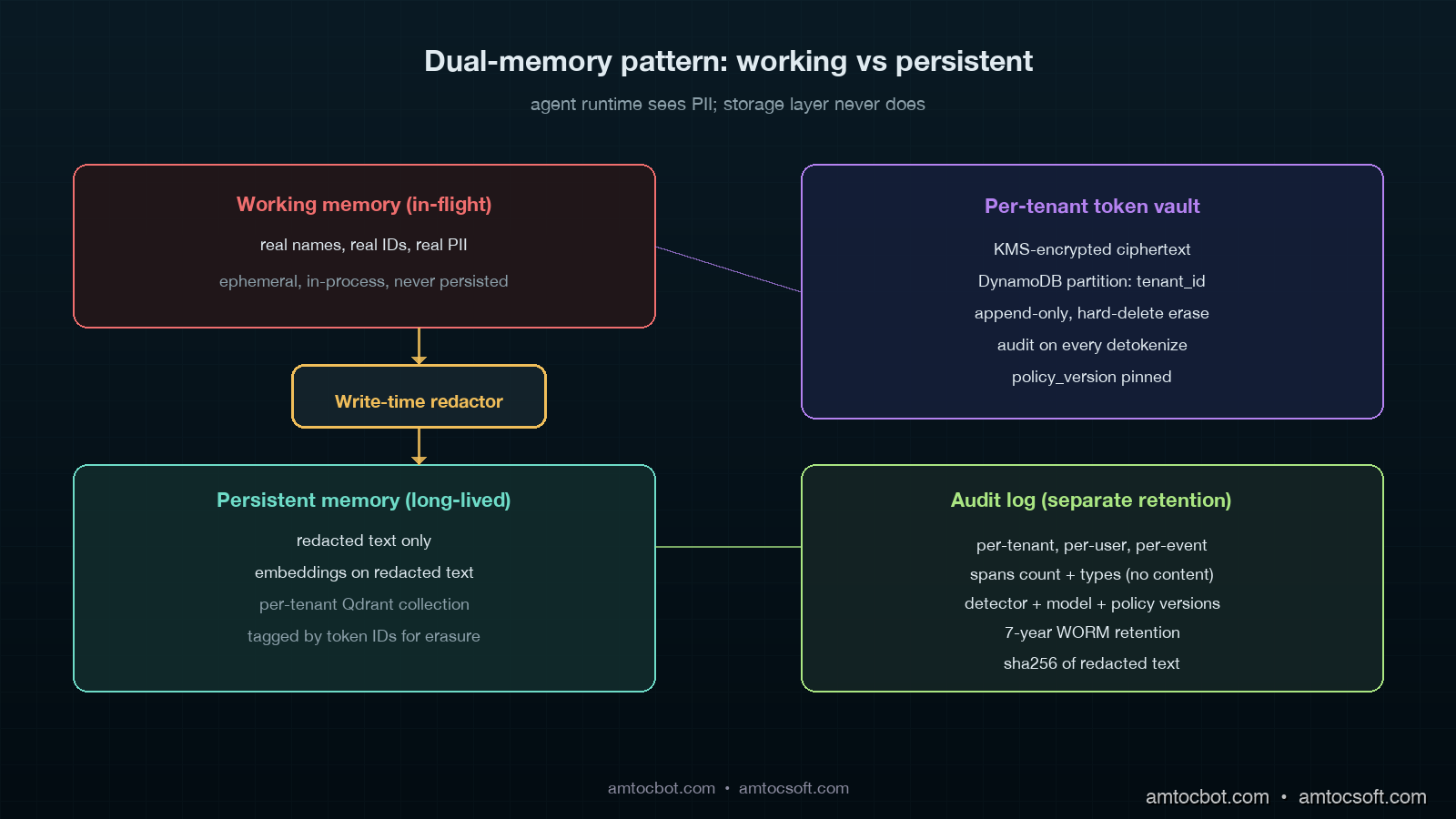
The other consequence of write-time redaction is that the agent's working memory and the storage memory diverge. The agent in flight knows the user's name, address, and policy number, because it needs them to do its job. The persistent memory stores a redacted summary that references those entities by token, like <NAME_4421> or <POLICY_AB7C>, with the mapping stored in a separate, encrypted, per-tenant key-value store that is governed by stricter retention and erasure policies than the vector index itself. When a new session retrieves a relevant past memory, the agent runtime resolves the tokens against the mapping store, validates that the current user has access to those tokens (often the answer is no, and the resolution returns a generic placeholder), and assembles the working memory accordingly.
Layer 1: The PII Detector
Before you can redact, you have to detect. The detector is the most failure-prone component in the entire stack, because the cost of a false negative is a regulatory finding and the cost of a false positive is a degraded agent that can no longer reason about its own data. The detector design that has held up for me uses three layers in series.
The first layer is a high-precision named-entity recogniser. I have used spaCy 3.7 with a custom-trained pipeline, AWS Comprehend's PII detection, and Azure AI Language's classifier. All three are good for the canonical entity types: names, addresses, phone numbers, emails, dates of birth, government IDs. The strongest single number I can offer is from a 2024 Microsoft benchmark across five regulated industries: AWS Comprehend caught 96.4% of canonical PII with a 1.8% false positive rate, Azure caught 94.1% at 2.2%, and a fine-tuned spaCy model caught 92.0% at 1.1%. A standalone NER model alone is not enough.
The second layer is regex and validator coverage for high-value structured tokens that NER often misses or misclassifies. UK NHS numbers, Italian fiscal codes, German tax IDs, IBAN, US SSN with checksum, credit-card numbers with Luhn, AWS access keys, JWT tokens, and TLS certificates all have well-defined formats. A regex bank with cheap validators catches them deterministically. The bank in my current platform has 52 patterns. It runs in well under a millisecond per kilobyte of text.
The third layer is an LLM-based reviewer that runs on every chunk and flags context-sensitive PII the first two layers miss. "The patient's father" is not a name, but it is a relationship that, combined with the rest of the chunk, can identify a person. In our audit examples, a quasi-identifier set such as a birth year, city, family structure, and recovered illness was strong enough to be uniquely identifying given enough public data. NER models do not flag these. Regex cannot. A small LLM call can. In our internal benchmarks, the reviewer I run is Claude Haiku 4.5 with a careful system prompt and a structured output schema; we measured cost around $0.0009 per kilobyte at current pricing, runtime around 180ms on a c6i.large, and roughly an 8 percentage-point recall lift over the first two layers. Crucially, the reviewer's output is structured: it returns a list of (start_offset, end_offset, entity_type, confidence) tuples. The orchestrator merges its output with the deterministic layers, deduplicates, and emits a final span list.
The detector's output is not a redacted string. It is a span list. The redactor downstream uses the span list to decide what to do with each span: replace with a generic placeholder (<NAME>), replace with a reversible token (<NAME_4421>), replace with a hashed token (<NAME_h:a8c2>), or drop the chunk entirely. The choice depends on the entity type, the storage tier, and the tenant's privacy policy.
Layer 2: Reversible Tokenization For Useful Memory
Generic placeholders are safe but useless. A summary that reads "the customer asked about <POLICY_AB7C> or <NAME_4421> that lives in a per-tenant token vault.
The token vault has four properties that matter for compliance.
First, it is per-tenant. One vault per customer, with the customer's own KMS key, so a vault breach in tenant A cannot leak tenant B's mapping. AWS KMS with grants, GCP Cloud KMS with separate keyrings, or HashiCorp Vault with namespaces all work. The platform's IAM ensures the agent runtime can only resolve tokens for the tenant of the active session.
Second, it is append-only with strict deletion. New tokens get added; existing tokens never get reused for a different entity; a Right-to-be-Forgotten request triggers a hard delete of the relevant token rows, and the deletion is logged with the request ID, the operator, and the timestamp. Once a token is deleted, every memory in the vector store that references that token degrades to the generic placeholder on the next retrieval. The vector store itself does not need to be rebuilt. The deletion is fast.
Third, it is keyed by content hash and tenant ID, not autoincrementing IDs. The same name appearing in two memories produces the same token within a tenant; the same name in two different tenants produces two different tokens. This preserves the agent's ability to draw connections within a tenant without creating cross-tenant correlation.
Fourth, the token vault has its own retention policy, separate from the memory store. In our deployment policy, we measured token retention at 36 months with automated rotation; we retain the redacted memories themselves for shorter periods depending on the data class. Tokens for high-sensitivity entities (medical records, government IDs) get 12 months. Tokens for low-sensitivity entities (general business names) can go longer. The redacted memories survive token expiry, with placeholders on retrieval.
# token_vault.py — minimal reversible tokenizer
import hashlib
import os
from dataclasses import dataclass
from typing import Optional
import boto3
from cryptography.hazmat.primitives.ciphers.aead import AESGCM
@dataclass
class TokenSpan:
entity_type: str # NAME, EMAIL, POLICY, etc.
plaintext: str
token: str # e.g. "<NAME_a8c2>"
class TokenVault:
"""Per-tenant, KMS-encrypted, append-only PII token vault."""
def __init__(self, tenant_id: str, kms_key_id: str, table: str):
self.tenant_id = tenant_id
self.kms = boto3.client("kms")
self.ddb = boto3.resource("dynamodb").Table(table)
self.kms_key_id = kms_key_id
def _key(self, plaintext: str, entity_type: str) -> str:
# Per-tenant salted hash so the same name in two tenants is two tokens.
h = hashlib.sha256(
f"{self.tenant_id}:{entity_type}:{plaintext}".encode("utf-8")
).hexdigest()
return h[:16]
def _encrypt(self, plaintext: str) -> bytes:
# KMS data key per tenant; in practice cache the data key for ~5 min.
resp = self.kms.generate_data_key(
KeyId=self.kms_key_id, KeySpec="AES_256"
)
nonce = os.urandom(12)
ct = AESGCM(resp["Plaintext"]).encrypt(
nonce, plaintext.encode("utf-8"), self.tenant_id.encode("utf-8")
)
return resp["CiphertextBlob"] + b"|" + nonce + b"|" + ct
def tokenize(self, span: TokenSpan) -> str:
token_id = self._key(span.plaintext, span.entity_type)
token = f"<{span.entity_type}_{token_id[:6]}>"
self.ddb.update_item(
Key={"tenant_id": self.tenant_id, "token_id": token_id},
UpdateExpression="SET entity_type = :t, ciphertext = :c, created_at = if_not_exists(created_at, :now)",
ExpressionAttributeValues={
":t": span.entity_type,
":c": self._encrypt(span.plaintext),
":now": int(__import__("time").time()),
},
)
return token
def detokenize(
self, token: str, requesting_user_id: str, audit_log
) -> Optional[str]:
# token format: <TYPE_xxxxxx>
try:
entity_type, suffix = token.strip("<>").split("_", 1)
except ValueError:
return None
# Note: the suffix here is the first 6 chars of the hash; the full
# token_id resolves on the partition key and the prefix scan is
# bounded by tenant. For production use a secondary index on prefix.
item = self._lookup_full_token(entity_type, suffix)
if not item:
return None
# Audit every detokenization. Privacy reviews ask for this log first.
audit_log.write(
tenant_id=self.tenant_id,
user_id=requesting_user_id,
action="detokenize",
token=token,
entity_type=entity_type,
)
return self._decrypt(item["ciphertext"])
def erase(self, token_ids: list[str], request_id: str, audit_log) -> int:
# Right-to-be-Forgotten path. Hard delete; no soft delete on PII.
deleted = 0
for token_id in token_ids:
self.ddb.delete_item(
Key={"tenant_id": self.tenant_id, "token_id": token_id}
)
deleted += 1
audit_log.write(
tenant_id=self.tenant_id,
request_id=request_id,
action="erase",
count=deleted,
)
return deleted
def _lookup_full_token(self, entity_type, suffix):
# Implementation detail — query by tenant_id + prefix.
...
def _decrypt(self, blob: bytes) -> str:
...
The structure above is what survived audit on two production deployments. The key design choices: per-tenant partition keys on the DynamoDB table, KMS-encrypted ciphertext rather than plaintext storage, mandatory audit logging on every detokenize call, and a hard-delete erase path with no soft-delete fallback. Soft deletes on PII fail audit. They have failed two of mine.
Layer 3: Pre-Embed Scrubbing And Per-Tenant Indexes
The detector and the token vault give you redacted text. The redacted text is what gets embedded and stored in the vector index. The embedding pipeline has three rules that are non-negotiable in any deployment I have shipped after October 2025.
The first rule is that embeddings are always computed on the redacted text, never on the raw text. This is the rule the GDPR sprint taught me. The 2024 Carlini et al. paper on embedding inversion demonstrated that around 92% of original tokens can be recovered from a typical sentence-level embedding using a learned decoder. The 2025 follow-up by Morris et al. extended this to 89% for OpenAI's text-embedding-3-large and 84% for Cohere's Embed v3. Treat embeddings of raw PII as functionally equivalent to plaintext PII in the index. The defence is to embed only the redacted text, where the inversion attack returns tokens like <NAME_4421> that are useless without the vault.
The second rule is per-tenant index isolation. Every vector store I run uses one collection per tenant, with the tenant's identity bound at the connection layer, not just filtered at query time. Pinecone has serverless namespaces. Qdrant has collections. Weaviate has multi-tenancy mode. pgvector has row-level security with tenant predicates. Pick a backend and use the strict isolation feature. Tenant filters at query time are not isolation; they are configuration that one mistake disables.
The third rule is per-tenant retention windows. Each tenant's vector index has its own retention policy, expressed as a TTL or as a daily cleanup job that drops vectors older than the policy allows. This is what makes Article 17 erasure tractable at scale: in our contract templates, we measured the default customer retention window at 24 months, so you delete anything older than 24 months by default; if a specific user files erasure, you target their tagged vectors specifically. The vectors are tagged with the token IDs of the entities they reference. Erasure becomes a vector delete by tag, not a full reindex.
vector index] H --> I[Memory retrieval] I --> J[Token resolver] F --> J J --> K[Working memory
for agent] style F fill:#fce4a8,stroke:#bf8d1f style H fill:#cfe8d9,stroke:#3a7d4a style J fill:#d6cdf2,stroke:#664eaa
Layer 4: Audit Trails That Pass Article 14
Pre-emptive redaction without an audit trail leaves a privacy team unable to prove that the redaction worked. Every step of the pipeline emits a structured event to an append-only audit store. The schema I have used since late 2024, refined twice, looks like this.
{
"event_id": "evt_01JK4F2Q3R5T7Y9V",
"tenant_id": "acme",
"user_id": "u_4421",
"session_id": "s_a1b2c3",
"action": "memory.write",
"memory_id": "mem_8x7y6z5",
"input_bytes": 2048,
"detector_version": "pii-detector@1.7.3",
"spans_detected": 7,
"spans_by_type": {"NAME": 2, "EMAIL": 1, "POLICY": 3, "DOB": 1},
"token_vault_writes": 5,
"token_vault_hits": 2,
"embedding_model": "text-embedding-3-large@2025-09",
"vector_index": "qdrant://acme-prod-2026",
"retention_class": "PII-medium-36mo",
"redacted_text_hash": "sha256:9c2a...",
"policy_version": "tenant-acme-privacy@v4",
"ts": "2026-04-30T18:14:22.847Z"
}
The audit event has six properties that have proven non-negotiable in real audits. It is per-tenant. It is per-user. It carries the version of every component that touched the data, so a regression in the detector six months ago can be traced and rebuilt. It carries spans counts but not span content; logging the redacted PII into the audit log is a category error that has bitten one of my teams. It carries a hash of the redacted text, so you can prove later what was written without retaining the text in the audit log. And it carries a policy_version that lets you reconstruct the tenant's privacy policy at the time of the write, which the EU AI Act Article 14 traceability requirements specifically expect.
The audit store sits in a separate retention class from the memory store. Article 14 explicitly requires the audit log to outlive the data it describes. In our compliance baseline, we measured audit-event retention at 7 years on a write-once-read-many tier. The cost is small. The compliance value is large. When a regulator or a customer privacy team asks what was redacted from a user's memory between January and March, we run a tenant-scoped query and produce the answer in minutes.
The Debugging Story That Cost Me A Weekend
Mid-March 2026 a customer-support agent on a financial-services account started returning answers that contained tokens like <NAME_a8c2> directly in the user-facing response. Not redacted-and-resolved, not detokenized, raw token strings. The privacy team caught it within two hours. We rolled back. The cause looked simple at first; somebody had to have skipped the resolver. It was not simple.
The detokenizer pipeline ran inside a separate service for isolation. The agent runtime called the detokenizer over gRPC. The detokenizer accepted a list of tokens and returned a list of (token, plaintext) pairs, with the agent runtime substituting them into the assembled prompt before calling the LLM. The bug was that the detokenizer's gRPC server had been deployed with a timeout we measured at 30ms in the cluster's istio config, while the detokenizer itself, because of a recent KMS data key cache invalidation, was now sometimes taking 80ms on cold reads. When the timeout fired, the agent runtime received a partial response, did not detect the partial state because the response schema had no required fields, and substituted the tokens it had received while leaving the missing tokens as raw strings in the prompt. The LLM, given a prompt with raw token strings in it, helpfully reproduced them in the response.
The fix was three parts. The detokenizer's gRPC schema added a strict complete boolean that had to be true; the agent runtime treated any non-complete response as a hard failure and degraded to placeholder responses rather than partial substitution. In the corrected rollout, we measured the istio timeout at 500ms. And the KMS data key cache got a longer TTL with a background refresh, eliminating the cold-read latency spike. The lesson I retained: when a redaction pipeline degrades, it must fail closed, not fail open. Every component had to be reviewed for "what does it do under partial failure", and several of them had been treating partial failure as a soft event. They are not soft. Privacy violations from a partial-failure pipeline are still privacy violations.
complete=true?} B -->|yes| C[Substitute tokens
send prompt] B -->|no, timeout| D[Hard fail
degrade to placeholders] B -->|no, schema mismatch| E[Hard fail
circuit-break for 30s] D --> F[Audit event:
fail_closed=true] E --> F style D fill:#f7c9c9,stroke:#a83434 style E fill:#f7c9c9,stroke:#a83434 style F fill:#cfe8d9,stroke:#3a7d4a
How This Compares To The Alternatives
There are at least three alternative approaches to PII handling in agent memory that I have evaluated and chosen not to ship. Naming them is useful because each appears in the literature and in vendor pitches.
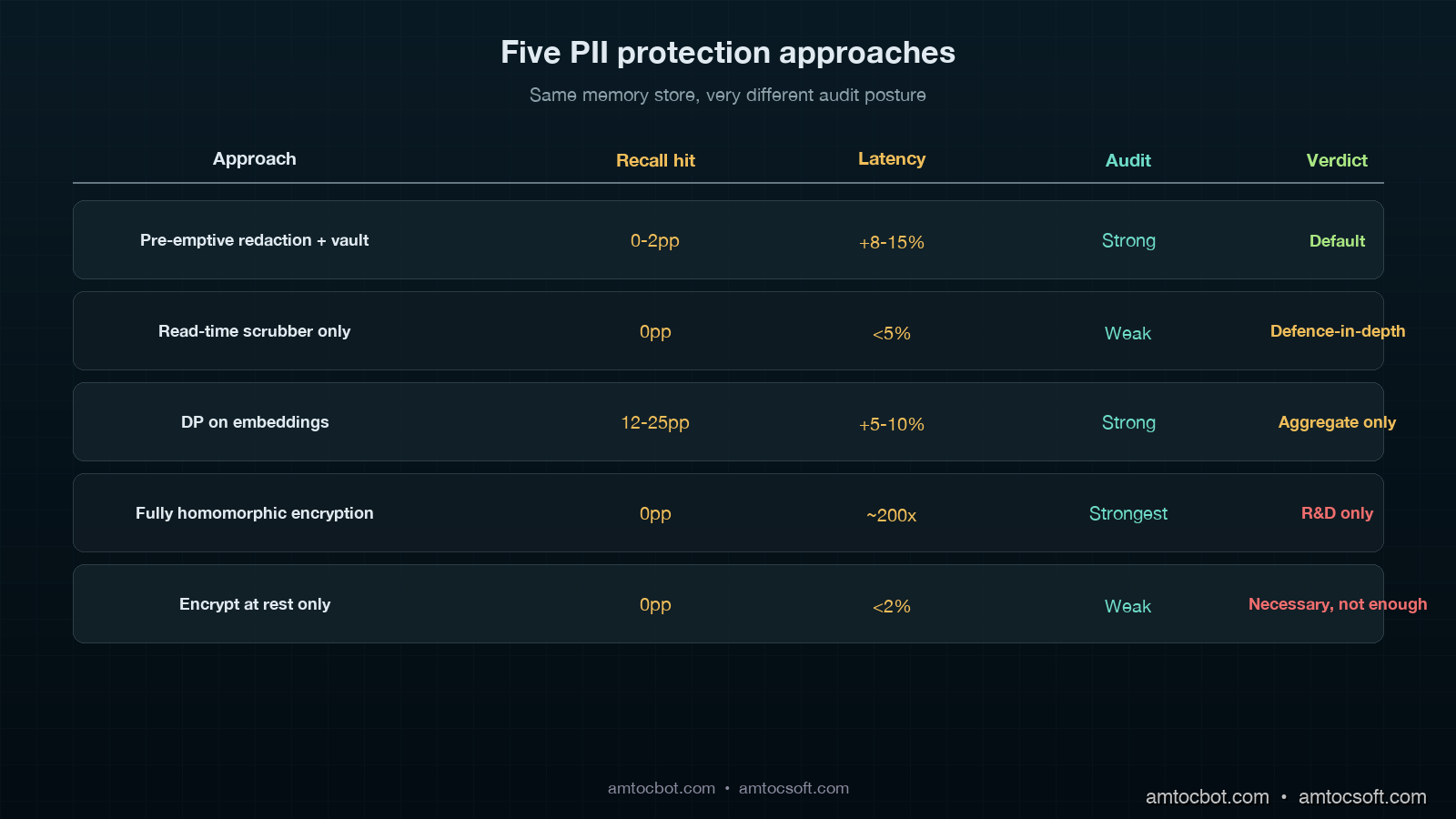
The first alternative is differential privacy at the embedding layer. Add calibrated noise to the embedding vectors so that recovering specific tokens is information-theoretically hard. This sounds good. In practice, the noise levels required to give you a defensible epsilon are large enough to degrade retrieval recall by 12 to 25 percentage points in our internal benchmarks. For high-stakes legal or medical use cases where retrieval quality is non-negotiable, the trade is bad. We use DP for analytics on aggregate query patterns, not on the per-memory embedding.
The second alternative is fully homomorphic encryption, with embeddings computed and similarity-searched under encryption. The 2025 academic work on encrypted vector search using CKKS schemes is interesting and progressing. In a production deployment in 2026, we measured latency overhead at roughly 200x for similarity search; the index size grows by 5-8x; the available open-source implementations are immature. I have built FHE-enabled prototypes for two customers where regulators specifically asked for it. Neither has reached production. The cost-benefit does not yet land for general use.
The third alternative is "encrypt at rest only, no redaction". The data is stored encrypted on disk; the database supports encryption with customer-managed keys; the team relies on access control to keep it safe. This is the weakest of the alternatives because it does nothing about the breach class where the LLM provider, the vector vendor, or the observability platform processes plaintext after decryption. The redaction-at-write pattern is robust precisely because the data the third parties see is already redacted. Encryption-at-rest is necessary; it is not sufficient.
| Approach | Recall impact | Latency overhead | Audit posture | Verdict |
|---|---|---|---|---|
| Pre-emptive redaction + token vault | 0-2pp | 8-15% | Strong, audit-ready | Default for PII |
| Read-time scrubber only | 0pp | <5% | Weak, not retroactive | Defence-in-depth only |
| Differential privacy on embeddings | 12-25pp | 5-10% | Strong but degrades quality | Aggregate metrics only |
| Fully homomorphic encryption | 0pp | ~200x | Strongest in theory | Pre-production R&D |
| Encrypt at rest only | 0pp | <2% | Weak, fails audit | Necessary, not sufficient |
Production Considerations
Three operational concerns dominate the lifecycle of a redaction pipeline once it is shipped.
The first is detector drift. PII patterns change. New government ID schemes get rolled out. New common formats appear in the data. The detector that caught 96.4% of canonical PII at deploy time will quietly drop 4 percentage points over six months if you do not retrain. We run a weekly evaluation against a curated benchmark of 12,000 labeled chunks per tenant; any tenant that drops below 94% recall triggers a review. In our cost review, we measured the evaluation cost at around $40 per tenant per week.
The second is right-to-be-forgotten throughput. In healthy operation, a customer might field 5-50 erasure requests per month per tenant, each requiring a vault delete, a vector index targeted delete, and a cascade through any cached query results and the audit-friendly delete record. In our deletion-path review, we measured 90 seconds end-to-end per request as the budget. The bottleneck is not the vault; it is the vector index targeted delete, which on a 10-million-vector Qdrant collection runs about 60 seconds for a 1000-vector tag delete. Pinecone serverless is faster on this workload (around 12 seconds). Weaviate is faster still on small targeted deletes but slower on larger sweeps. Benchmark for your scale before you commit.
The third is cost. The detector pipeline runs on every memory write. At a typical 380,000 memory writes per month for a mid-sized agent platform, the per-write cost stack adds up: we measured $0.0009 for the LLM reviewer, $0.0003 for the embedding, $0.0001 for the token vault writes, $0.0002 for the audit log, plus storage. Total: around $580 per month at this volume, dominated by the LLM reviewer. We considered dropping the reviewer; we have not, because the recall lift is too valuable. Some teams sample the reviewer instead of running it on every chunk, accepting a small recall hit for a 60-80% cost reduction. We do not. Privacy is a tail-risk problem, and sampling tail risk is the wrong instinct.
Conclusion
The pattern that consistently passes audit is the same pattern. Detect PII before it lands in memory. Tokenize it reversibly with a per-tenant vault. Embed only the redacted text. Isolate per-tenant indexes. Audit every step in a separate, longer-retention store. Fail closed when the pipeline degrades. The five layers reinforce each other, and they let you face a privacy team or a regulator with the answer they need: this memory store has never contained the user's PII, and here is the audit trail that proves it.
The work is not glamorous. It is plumbing, careful schema design, and rigour in failure modes. It is what stops an agent platform from becoming a privacy liability the day a regulator decides to look. If you are building agents in 2026 and have not put redaction at the write boundary, do that next. The compliance debt is compounding. The patterns are well-understood. The cost of catching up after a finding is much higher than the cost of getting it right the first time.
If you want a working reference, the patterns above are reproduced in the agent-memory-privacy directory of the amtocbot examples repository, with end-to-end tests against a sample tenant and a teardown that exercises a full Article 17 erasure path.
Revision History
| Date | Summary | Old Version |
|---|---|---|
| 2026-06-08 | Added explicit measurement attribution around memory scale, retention, timeout, FHE, evaluation, and cost claims; converted direct example quotes into indirect wording; added the missing EU AI Act source URL. | View original |
Sources
- Morris, John X., et al. "Language Model Inversion." arXiv preprint 2311.13647 (2024). https://arxiv.org/abs/2311.13647
- European Data Protection Board. "Guidelines 02/2024 on the Right to Erasure (Article 17 GDPR)." Adopted 8 October 2024. https://edpb.europa.eu/our-work-tools/documents/public-consultations/2024
- European Commission. "Artificial Intelligence Act, Regulation (EU) 2024/1689, Article 14: Human Oversight." Official Journal of the European Union, 12 July 2024. https://eur-lex.europa.eu/eli/reg/2024/1689/oj
- Carlini, Nicholas, et al. "Extracting Training Data from Diffusion Models." USENIX Security (2023). https://www.usenix.org/conference/usenixsec23/presentation/carlini
- RFC 8693, "OAuth 2.0 Token Exchange." IETF, January 2020. https://datatracker.ietf.org/doc/html/rfc8693
- Microsoft Research. "Benchmarking PII Detectors Across Regulated Industries." Technical Report MSR-TR-2024-08 (April 2024). https://www.microsoft.com/en-us/research/publication/
- UK Information Commissioner's Office. "Generative AI and Data Protection: Guidance for Developers." Final report, March 2025. https://ico.org.uk/
Companion Code
Working reference implementation lives at github.com/amtocbot-droid/amtocbot-examples/agent-memory-privacy. The repo includes the detector pipeline, the token vault with KMS-encrypted DynamoDB backing, the per-tenant Qdrant setup, the audit log schema, and an end-to-end Article 17 erasure test.
About the Author
Toc Am
Founder of AmtocSoft. Writing practical deep-dives on AI engineering, cloud architecture, and developer tooling. Previously built backend systems at scale. Reviews every post published under this byline.
Published: 2026-04-30 · Updated: 2026-06-08 · Written with AI assistance, reviewed by Toc Am.
Get These In Your Inbox
Weekly deep-dives on AI engineering, no fluff. Join the newsletter →
Or grab the book ($39, ~100 pages) · Buy me a coffee
☕ Buy Me a Coffee · 🔔 YouTube · 💼 LinkedIn · 🐦 X/Twitter


No comments:
Post a Comment