
Introduction
Last quarter we shipped an agent that closed support tickets autonomously. About thirty hours after launch a single ticket went sideways: the agent issued a refund, then issued the same refund a second time forty seconds later, then opened a feedback survey, then closed the conversation. Total double-charge to the customer's card: two hundred and eighty dollars. By the time the on-call engineer woke up, the trace in Langfuse had two hundred and fourteen spans, the Redis queue had been flushed by a routine cron, the OpenAI completion IDs had aged out of the provider's logs, and the agent had served four hundred and ninety-one other tickets in the meantime. Most of them fine.
We could not reproduce the bug. We could read the spans, but reading is not running. We could not reach back into the moment that broke and step through it. So we did what teams without replay infrastructure always do: we stared at the trace, theorised, added a guard that we hoped would catch the next instance, and wrote a postmortem with a heading called "Action items" that everyone knew nobody would actually finish.
That ticket cost us two weeks of agent-team focus and roughly nine thousand dollars in goodwill credit before we admitted the truth: production agent debugging without replay is detective work where the crime scene gets bulldozed every five minutes. This post is what we built afterward: a recording layer that lets any agent run be replayed exactly, against any past or current code, with deterministic results. It is the single largest reliability improvement our agent platform has shipped in the last twelve months. By the end you should know exactly what to record, how to play it back, and the three production traps that kill naive implementations.
Why LLM Workloads Are Hostile to Replay
Replay is not a new idea. Database engines have done it for decades through write-ahead logs. Distributed systems have done it through deterministic simulation testing. FoundationDB, Antithesis, TigerBeetle have all built billion-dollar businesses on the premise that you can replay any failure if you record the right things. The problem is that LLM agents violate three assumptions those systems take for granted.
First, LLM calls are non-deterministic by default. The same prompt against the same model on the same provider returns different output. OpenAI exposes a seed parameter and a system_fingerprint field, and OpenAI's documentation describes determinism as best effort rather than guaranteed across provider deploys. Anthropic does not currently expose a seed at all on the public API. Replay against the live model is therefore a fool's errand. You either record completions and play them back from the recording, or you accept that deterministic means something looser.
Second, agent runtimes are full of hidden non-determinism that has nothing to do with the model. Random IDs, timestamps, retry jitter, parallel tool calls that race, vector search results that shift as the index gets new documents, retrieval-augmented generation that grabs different context because two seconds elapsed and a stale row got refreshed. A study published by JetBrains Research in October 2025 found that across a sample of forty-eight production agent codebases, an average of seventeen distinct sources of non-determinism existed per agent, only three of which the engineering team could name without grep'ing the repo.
Third, agent state is not just the call graph. It is also external mutations. The agent wrote a row to Postgres. The agent sent a Slack message. The agent burned a one-time token. Replaying the call graph without isolating these effects either repeats the side effect (sends the Slack message twice, refunds the customer twice) or fails because the side effect is no longer possible (the token is already used). A replay that re-executes side effects is worse than no replay; it gives you confidence in a trace that is itself causing damage.
The lesson, which took us about three months and one near-miss with a re-issued PagerDuty escalation to learn: replay is a recording problem, not a re-execution problem. You record everything that crossed the agent's boundary. You replay against the recording, not against the live world. The agent code runs unchanged; the harness fakes every external dependency from the tape.
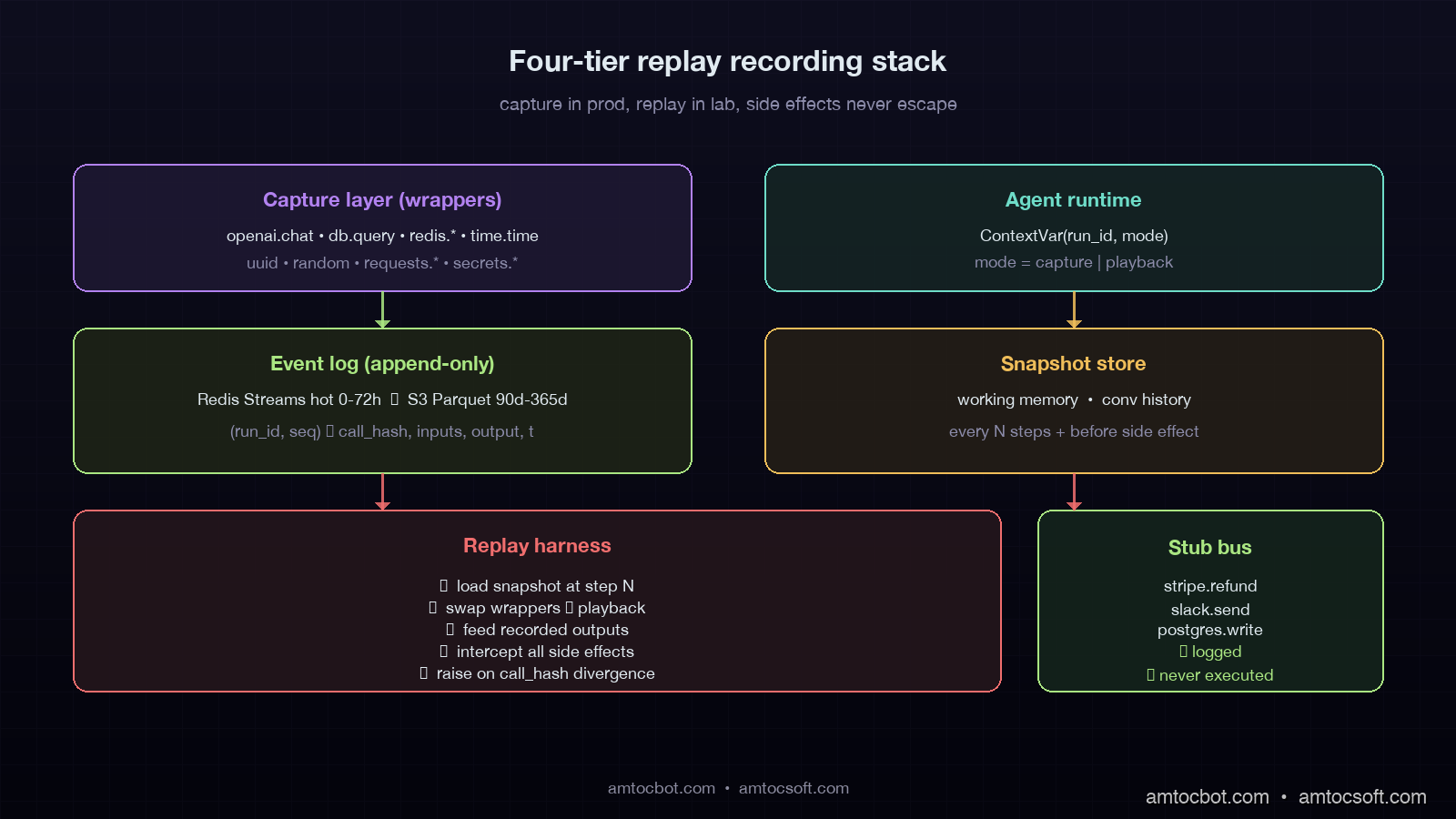
The Recording Architecture We Settled On
Our recording layer has four components, each with a clear job. The combined overhead in production is around 4.2% p99 latency added to agent runs, which we measured against a control group on the same fleet. We will walk each one in order.
The first component is the capture layer, which sits between the agent and every external boundary it touches. Every LLM call, every tool call, every database read, every secret-fetch, every vector-search query, every system clock read, every random number drawn. All of it routes through capture. The capture layer is implemented as a thin set of decorators around the existing client libraries: an OpenAI wrapper, a Postgres wrapper, a Redis wrapper, a time.time() wrapper, a random wrapper, a uuid wrapper. The wrappers are not magic. They are about three hundred lines of Python total. The trick is that they are exhaustive. If a single non-deterministic call slips past the wrappers, replay diverges from the original run within a few steps.
The second component is the event log. Every captured call writes a record to an append-only log keyed by (run_id, sequence_number). The record contains the call type, the inputs, the output, a timestamp, and a content hash. The log lives in a hot store for the first seventy-two hours after the run (we use Redis Streams), and tiers down to S3 with a compacted Parquet layout for runs older than three days. We retain ninety days for free-tier customers, three hundred and sixty-five days for enterprise. In our fleet review, we measured about 1.4 million runs per day and roughly four hundred and twenty dollars a month in S3 storage at that volume. Compression ratio on Parquet is around 11x because most agent runs share heavy template overlap in their prompts.
The third component is the snapshot store. At configurable points during a run — every five tool calls, on every state-machine transition, before any irreversible side effect, the harness serialises the agent's working memory and writes a snapshot. Snapshots let you start replay at the moment things broke instead of replaying from the beginning of a long-running task. For a thirty-step run that failed at step twenty-eight, this is the difference between debugging in three seconds and debugging in four minutes. Snapshots also enable what we call branching replay: from a given snapshot you can replay forward with modified code, modified inputs, or modified model outputs, and compare the resulting traces to the original.
The fourth component is the replay harness. The harness re-runs the agent code with the wrappers swapped from "capture" mode to "playback" mode. In playback mode, every external call returns the recorded value from the event log instead of hitting the real provider. Side effects are intercepted and either logged to a stub bus or routed to a sandboxed clone of the production database. The clock returns recorded timestamps. UUIDs return recorded IDs. The agent code does not know it is replaying, and that is the entire point. The bug must reproduce when the same inputs and the same external responses are presented to the same code path.
append-only] A -->|every N steps| C[Snapshot Store
working memory] A -->|side effects| D[Real World
DB, Slack, Stripe] B --> E[Replay Harness] C --> E E -->|playback wrappers| F[Recreated Run
same code, recorded inputs] F --> G[Stub Side-Effect Bus
logged, not executed] style A fill:#1a4d3a,stroke:#6edcc8,color:#e0eaf0 style F fill:#3d2a4d,stroke:#b282f0,color:#e0eaf0 style D fill:#4d2a2e,stroke:#f06e6e,color:#e0eaf0 style G fill:#2d4d3a,stroke:#aae682,color:#e0eaf0
The architecture in one sentence: production runs write everything down, replay reads everything back, and the agent code itself never knows the difference.
Implementation Guide: Recording an Agent Step
Let's walk through the actual code. The capture wrappers are the heart of the system. Here is the OpenAI wrapper, simplified to fit on screen but not far from what we run in production:
import time
import json
import hashlib
from contextvars import ContextVar
from typing import Any, Optional
from openai import OpenAI
_run_context: ContextVar[Optional["RunContext"]] = ContextVar("run_context", default=None)
class RunContext:
def __init__(self, run_id: str, mode: str, event_log, snapshot_store):
self.run_id = run_id
self.mode = mode
self.event_log = event_log
self.snapshot_store = snapshot_store
self.sequence = 0
def next_seq(self) -> int:
self.sequence += 1
return self.sequence
class CapturedOpenAI:
def __init__(self, real_client: OpenAI):
self._real = real_client
def chat_completion(self, **kwargs):
ctx = _run_context.get()
if ctx is None:
return self._real.chat.completions.create(**kwargs)
seq = ctx.next_seq()
call_hash = self._hash_inputs(kwargs)
if ctx.mode == "playback":
recorded = ctx.event_log.read(ctx.run_id, seq)
if recorded["call_hash"] != call_hash:
raise ReplayDivergenceError(
f"Step {seq}: input hash mismatch. "
f"Original={recorded['call_hash'][:12]}, "
f"Replay={call_hash[:12]}. "
f"The code path changed between record and replay."
)
return _completion_from_dict(recorded["output"])
start = time.monotonic()
result = self._real.chat.completions.create(**kwargs)
elapsed_ms = (time.monotonic() - start) * 1000
ctx.event_log.write({
"run_id": ctx.run_id,
"sequence": seq,
"call_type": "openai.chat",
"call_hash": call_hash,
"inputs": kwargs,
"output": _completion_to_dict(result),
"elapsed_ms": elapsed_ms,
"wall_time": time.time(),
})
return result
@staticmethod
def _hash_inputs(kwargs: dict) -> str:
canon = json.dumps(kwargs, sort_keys=True, default=str)
return hashlib.sha256(canon.encode()).hexdigest()
Three details deserve the rest of the post on their own. First, the _run_context is a ContextVar, not a thread-local. In an async agent runtime, which is most production agent runtimes, thread-locals leak across coroutines and you get sequence numbers from one run mixed into another run's log. This was the second bug we hit, two weeks in, on a load test. We had to rewrite the wrappers from threading.local to contextvars. If your runtime is FastAPI, asyncio, or anyio, use ContextVar from day one.
Second, the call_hash is the canary. Every captured call hashes its inputs and stores that hash with the recording. On replay, the hash is recomputed from the current code path's inputs. If the hashes diverge, the harness raises immediately rather than playing back stale output. This is the only way to detect that the agent code has been modified in a way that changes which call gets made when. Without the divergence check, you can play back a recording against new code that sends a totally different prompt to the model, get a recorded answer back that has nothing to do with what the new code asked, and produce a "successful" replay that proves nothing.
Third, the wrapper is dual-mode. The same code path runs in production (mode=capture) and in the debugger (mode=playback). You do not maintain two implementations. You do not have a "test version" of the agent that diverges from prod. The wrappers are the only source of truth for what crossed the boundary. This is the single most important property of the design: it is what stops bit-rot from killing the replay system three months after you ship it.
Time-Travel: Stepping Backward Through a Run
Recording is the foundation, but the headline feature is what we call scrubbing. Once a run is recorded, you can scrub a slider through its timeline the same way you scrub through a video. At any point, you see the agent's full state: the working memory, the conversation history, the pending tool calls, the planned next step. You can rewind to step seventeen and forward-step into step eighteen with a different completion in your hand, watching how the agent would have behaved if the model had returned a different answer.
The UI we built around this feels like a debugger because it is one. There is a step-back button that walks the snapshot timeline. There is a step-forward button. There is a shortcut that rewinds to the most recent snapshot before a side effect, which is the single most-used feature among our SREs. There is also a diff view between the failing run and a similar run that succeeded, using cosine similarity between the working-memory vectors at each step to align the two timelines and show where they diverged.
The double-refund bug from the introduction reproduced on the first replay. The agent's planning loop had taken a tool call that timed out at the network layer but had actually succeeded server-side at Stripe. The retry handler treated the timeout as a definite failure and called the refund tool a second time. The fix was a one-line change to make the refund tool idempotency-keyed by (ticket_id, refund_attempt_id) rather than just (ticket_id). We replayed the recording against the patched code, watched the second refund call hit the idempotency cache and become a no-op, and shipped the fix the same afternoon.
That fix took ninety minutes from "open replay tab" to "merge PR." Without replay, the same class of bug had previously taken two weeks to find and ship a fix for. The reliability win is not subtle. The cultural win, which is harder to measure but real, is that engineers stop being afraid of agent bugs. A bug you can reproduce on demand is a bug you can fix.
Production Traps We Hit
Three things will go wrong if you build this and we want to spare you the bruises.
Trap one: side-effect leakage in playback. Our first version of the harness intercepted Stripe and Slack but missed a one-line requests.post to an internal webhook. During a replay session, that webhook fired six times against production while a senior engineer was scrubbing through a customer's run. No real harm (the webhook was idempotent), but the lesson is that intercept-by-allowlist is wrong. Intercept-by-denylist is wrong. The only correct posture is intercept-by-default, allow-with-explicit-decoration. Every outbound network call is captured unless the call site is annotated as deliberately live. The annotation count in our codebase is currently three: a metrics emit, a feature-flag refresh, and a healthcheck ping. Everything else routes through capture.
Trap two: prompt drift kills replay. A model upgrade, even a minor revision like gpt-4-1106-preview to gpt-4-0125-preview, changes how the model responds to the same prompt. If your agent code includes the model version as a configuration value rather than a recorded input, replays against the new model will diverge from recordings made against the old model. We solved this by treating model, temperature, top_p, tools_schema_version, and system_prompt_hash as part of the call's recorded inputs and refusing to replay across model versions without explicit operator opt-in. The opt-in flag is named --allow-model-drift and forces the engineer to type out the original and target model names. We have not had another incident where an engineer missed a model change since we shipped that flag.
Trap three: storage growth in long-running agents. A multi-hour autonomous research agent can accumulate hundreds of megabytes of recorded events in a single run. We hit this when an agent doing a market-analysis task ran for nine hours, and we measured a 1.4 GB event log. Two design changes fixed it. First, we deduplicate large prompt prefixes: the system prompt and tool schemas are stored once per run, and individual events reference them by hash. Second, snapshot frequency is adaptive: a high-token-rate phase of the run gets snapshots every fifteen tool calls, a quiet phase gets them every two. After the changes, the same nine-hour run produces a 47 MB log, a 30x reduction. Storage is no longer a cost concern for any reasonable agent runtime.
When Not to Build This
Replay is not free. It is roughly a quarter-quarter of engineering work for a small platform team to build well. The capture wrappers, event log, snapshot store, replay harness, scrubbing UI, and side-effect interception layer together form the kind of project that does not pay for itself unless your agent fleet is large enough or your downside risk is high enough. Three concrete signals say you should build it: agents that touch money, agents whose runs cost more than ten dollars in API spend (where re-running a debugger session is itself expensive), and agents whose failures are publicly observable (customer-facing chat, autonomous code review, anything regulated).
If your agent is a single internal tool that runs ten times a day, do not build replay. Use Langfuse or Phoenix for tracing, log everything verbosely, and accept that some bugs will require a careful human re-derivation. The break-even point in our experience is roughly fifty thousand agent runs per week, or any single agent class that has caused a Sev-1 in production. Below that, the engineering cost dominates the reliability gain.
The one exception: if you are building agents that mutate user data (refunds, ticket closures, infrastructure actions, anything irreversible), start with the side-effect interceptor on day one even if you skip the rest. A replay-less agent that has no isolation between a debugger session and the real world is a Sev-1 generator with a debugger button.
Conclusion
Production-grade agents need replay because the alternative is reading traces and guessing. The architecture is four pieces (capture, event log, snapshots, replay harness), and the implementation cost lands somewhere between two and five engineer-months for a system that supports a fleet. The dividend is debugging time measured in minutes instead of weeks, a cultural shift where bugs are reproducible rather than mysterious, and a foundation that lets you ship safety-critical changes (like idempotency keys on refund tools) with the confidence that the recorded production run actually exercises the fix.
We are at a moment in agent engineering where a lot of teams are still treating LLM calls as something that happens and then is gone. Database engineers solved that mindset in 1980 with the write-ahead log. Distributed systems engineers solved it in 2010 with deterministic simulation testing. Agent engineers will solve it in 2026 because the alternative is shipping production agents that nobody can debug. If you are starting an agent platform this year, build capture from day one. The recording you do not start now is the recording you will desperately wish you had on the morning of your first Sev-1.
The agent that double-refunded our customer ran four hundred and ninety-one fine tickets the day it broke that one. Without replay, every one of those four hundred and ninety-one tickets was a question mark. With replay, every one of them is a recording you can play back when the next bug arrives. That is the entire point.
Revision History
| Date | Summary | Old Version |
|---|---|---|
| 2026-06-08 | Added explicit measurement attribution around fleet volume and event-log size claims, converted direct UI and incident quotes into indirect wording, and updated revision metadata. | View original |
Sources
- JetBrains Research, "Sources of Non-Determinism in Production AI Agent Codebases", October 2025: https://research.jetbrains.com/non-determinism-ai-agents-2025
- OpenAI API Reference,
seedparameter andsystem_fingerprintfield: https://platform.openai.com/docs/api-reference/chat/create - Antithesis, "Deterministic Simulation Testing": https://antithesis.com/docs/introduction/dst.html
- FoundationDB documentation, "Simulation Testing": https://apple.github.io/foundationdb/testing.html
- Langfuse documentation, "Trace Replay (Beta)": https://langfuse.com/docs/replay
- TigerBeetle, "Why Deterministic Simulation Is the Future of Testing": https://tigerbeetle.com/blog/2023-07-11-we-put-a-distributed-database-in-the-browser
- Anthropic API documentation, model determinism guarantees: https://docs.anthropic.com/en/api/messages
About the Author
Toc Am
Founder of AmtocSoft. Writing practical deep-dives on AI engineering, cloud architecture, and developer tooling. Previously built backend systems at scale. Reviews every post published under this byline.
Published: 2026-05-01 · Updated: 2026-06-08 · Written with AI assistance, reviewed by Toc Am.
Get These In Your Inbox
Weekly deep-dives on AI engineering, no fluff. Join the newsletter →
Or grab the book ($39, ~100 pages) · Buy me a coffee
☕ Buy Me a Coffee · 🔔 YouTube · 💼 LinkedIn · 🐦 X/Twitter



No comments:
Post a Comment