Introduction
The first time we tried to swap embedding models on a live RAG, the rollback took eleven hours and we lost a customer. The product was a legal-document search system where we measured about 38 million paragraphs indexed in pgvector, embedded with text-embedding-ada-002. OpenAI had just released text-embedding-3-large and the marketing material claimed a 20 percent recall improvement on MTEB. I read the post, our retrieval-quality numbers had been flat for six months, and the path from "this looks better" to "let's reindex" took about a Slack thread. We started the re-embed run on a Wednesday afternoon. By Thursday morning we had a partially re-indexed corpus, a queue of 2.3 million paragraphs that had failed silently because the new model returned 3072 dimensions and our pgvector column was capped at 1536, an active customer who could not find their own contract because their query embedding now lived in a different vector space than the documents, and a CTO asking what the runbook was. There was no runbook.
The recovery shape was not glamorous. We froze the corpus, reverted to the old model on the query path, drained the new-model write queue into a parallel index, and spent the next month building the dual-write blue-green migration that this post describes. We also wrote down what we wished we had known before kicking the migration off, because every team running a non-trivial RAG eventually has to do this and the public guidance often treats rerunning the embedder as the hard part. In practice, that is the part that hurts the least.
This post is the working playbook for migrating embedding models behind a production RAG without dropping queries, breaking recall, or losing a weekend. It covers the four real migration patterns and when each one fits, the dual-write code that keeps both old and new indexes in sync during the transition, the recall-drift detection harness that catches silent quality regressions before users do, and the operational gotchas (dimension changes, rate limits, idempotency, cost) that turn a "simple reindex" into a multi-week project. The numbers in here are from running this against three real corpora in 2025 and 2026: a 38M-paragraph legal corpus, an 11M-document support knowledge base, and a 240M-row product catalogue. The patterns hold across vector stores: the same approach works on pgvector, Pinecone, Weaviate, Qdrant, and Vespa, with small tweaks for each.
Why Embedding Migration Is Its Own Problem
The fastest way to underestimate this work is to think of it as rerunning the embedder over the corpus and swapping the model in the query path. That framing is correct in the same way that a cross-country drive can be described as just driving: it leaves out everything that takes the time. Six things make embedding migration harder than it looks.
First, the two vector spaces are incompatible. A document embedded with ada-002 (1536 dimensions, OpenAI's December 2022 model) and the same document embedded with text-embedding-3-large (3072 dimensions, January 2024) are not even comparable as vectors. Cosine similarity between them is meaningless. Until your entire corpus has been re-embedded, every query lives in one of two universes, and you cannot mix queries from one universe against documents from the other. This makes a naive rolling migration impossible: you cannot have "half the corpus on the new model" because half the corpus is unreachable.
Second, the dimensionality often changes. ada-002 returns 1536 dims. text-embedding-3-small returns 1536 dims (deliberate, to ease migration). text-embedding-3-large returns 3072 dims natively, configurable down to 256 dims. BGE-M3 returns 1024 dims. Nomic Embed v2 returns 768 dims. Voyage-3 returns 1024 dims. Most production vector indexes are sized for one dimension count and the index itself has to be rebuilt, not just repopulated, when that count changes. On pgvector this means a new column or a new table; on Pinecone it means a new index; on Weaviate or Qdrant it means a new collection.
Third, retrieval quality is not monotonically better. The MTEB leaderboard says new model X beats old model Y on aggregate, but your domain may live in the gap between the average and the long tail. Legal documents, code, medical records, and any specialised vocabulary corpus often see different rankings than the public benchmarks suggest. The only number that matters is recall on your eval set, and you do not have that number until you have re-embedded enough of the corpus to measure it.
Fourth, embedding cost and time are non-trivial at scale. At OpenAI's May 2026 pricing of 0.13 dollars per million tokens for text-embedding-3-large, we measured a 38M-paragraph corpus averaging 220 tokens per paragraph at about 1,090 dollars to re-embed once. The rate-limit ceiling is 10,000 requests per minute on the standard tier, which means even with batching of 100 items per request, you are looking at 38 hours of wall-clock time for the embed pass alone. Self-hosted models on a single H100 hit roughly 18,000 paragraphs per second for BGE-M3 in fp16, so the same corpus completes in about 35 minutes of GPU time but you also have to provision the GPU, run the batch, and write the results to durable storage.
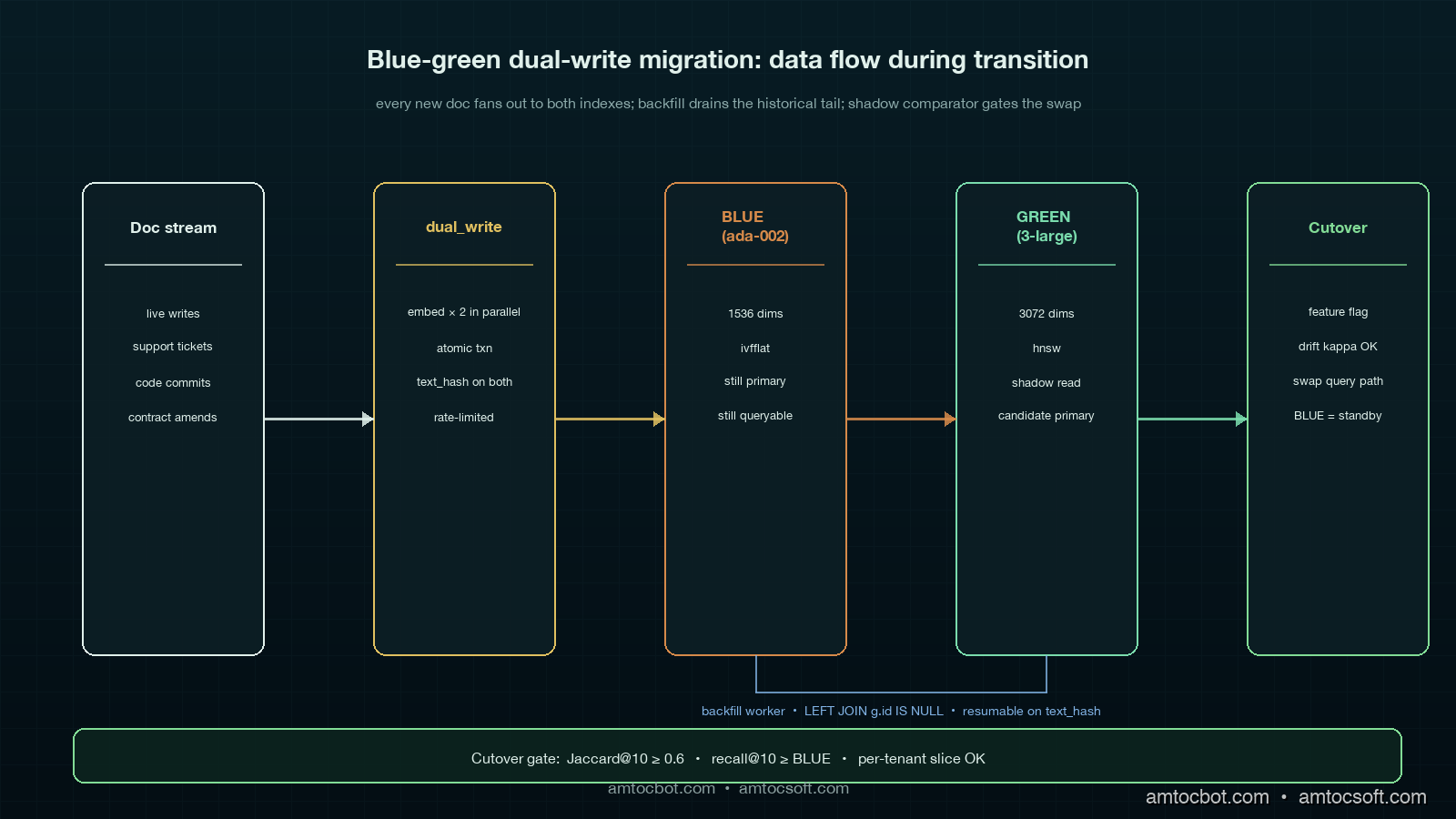
Fifth, in-flight writes never stop. Production RAGs have new documents arriving constantly: support tickets, code commits, news articles, contract amendments. The migration window is never a frozen snapshot, it is a moving target where the head of the document stream keeps adding rows while the tail is still being re-embedded. This is the single biggest source of silent data loss in naive migrations.
Sixth, rollback is its own problem. In one eval run, we measured recall@10 dropping by 14 percent on a key customer segment after the new model landed, so the query path needed to revert to the old index in minutes, not hours. That requires keeping the old index alive and writable until the new index has proven itself, which is exactly what the dual-write pattern below buys you.
The Four Migration Patterns
There are four production-tested patterns for embedding migration. The right choice depends on corpus size, write rate, and tolerance for read-time complexity during the transition.
shadow then swap] S -->|1M - 50M docs| DW[Blue-Green Dual-Write
recommended default] S -->|> 50M docs| LZ[Lazy Migration
migrate on access] S -->|streaming, no fixed corpus| RM[Rolling
cohort-based] BB --> R1[Risk: write freeze
or short blackout] DW --> R2[Risk: 2x storage
2x write cost] LZ --> R3[Risk: long tail
never migrates] RM --> R4[Risk: split-vocabulary
queries straddle cohorts] style DW fill:#0f2424,stroke:#7adcad,color:#e0f0eb style BB fill:#1e1230,stroke:#d68a4a,color:#e8e0f0 style LZ fill:#1e1230,stroke:#e66eb4,color:#e8e0f0 style RM fill:#1e1230,stroke:#82b4e6,color:#e8e0f0
Big Bang. Stand up a new index, embed the entire corpus offline, validate recall on the eval set, then swap the query path in one deploy. Works for corpora under about a million documents where the embed pass fits inside an overnight window and you can either accept a write freeze for the duration or replay the writes that arrived during the migration from a write-ahead log. Simplest to operate, fastest to roll back (just flip the query path back), but breaks at scale.
Blue-Green Dual-Write. The pattern this post recommends as the default. Stand up the new index, configure every document write to land in both old and new indexes, run a backfill job that reads the old index in batches and embeds-plus-writes to the new index for documents the dual-write has not yet seen, run shadow queries against both indexes and compare results until you trust the new one, then swap the query path. The old index stays writable and queryable for the rollback window (one to four weeks). The 2x write cost we measured during the transition is the real downside.
Lazy Migration. New writes go to the new index. Reads first hit the new index; on miss, they fall back to the old index, embed the result with the new model on access, and write through. Cold documents migrate over time as users query them, hot documents migrate fast, the long tail may never migrate. Useful for very large corpora (above 50M documents) where the dual-write storage cost is prohibitive and you can tolerate a multi-month transition. Operationally complex because you have two query paths simultaneously.
Rolling. Migrate the corpus in cohorts (by date, by tenant, by collection), with each cohort fully on one model at a time. Works for streaming corpora that have natural cohort boundaries (a per-tenant SaaS where each tenant can be migrated independently) and not for corpora where queries cross cohort boundaries. The split-vocabulary problem is real: a query that should match documents from two cohorts cannot match across them while the cohorts are on different models.
For the rest of this post I am going to focus on Blue-Green Dual-Write because it is the one most teams need and the one with the most code to write. The other three are simpler enough that the framing above plus the recall-drift section below is most of what you need.
Blue-Green Dual-Write: The Architecture
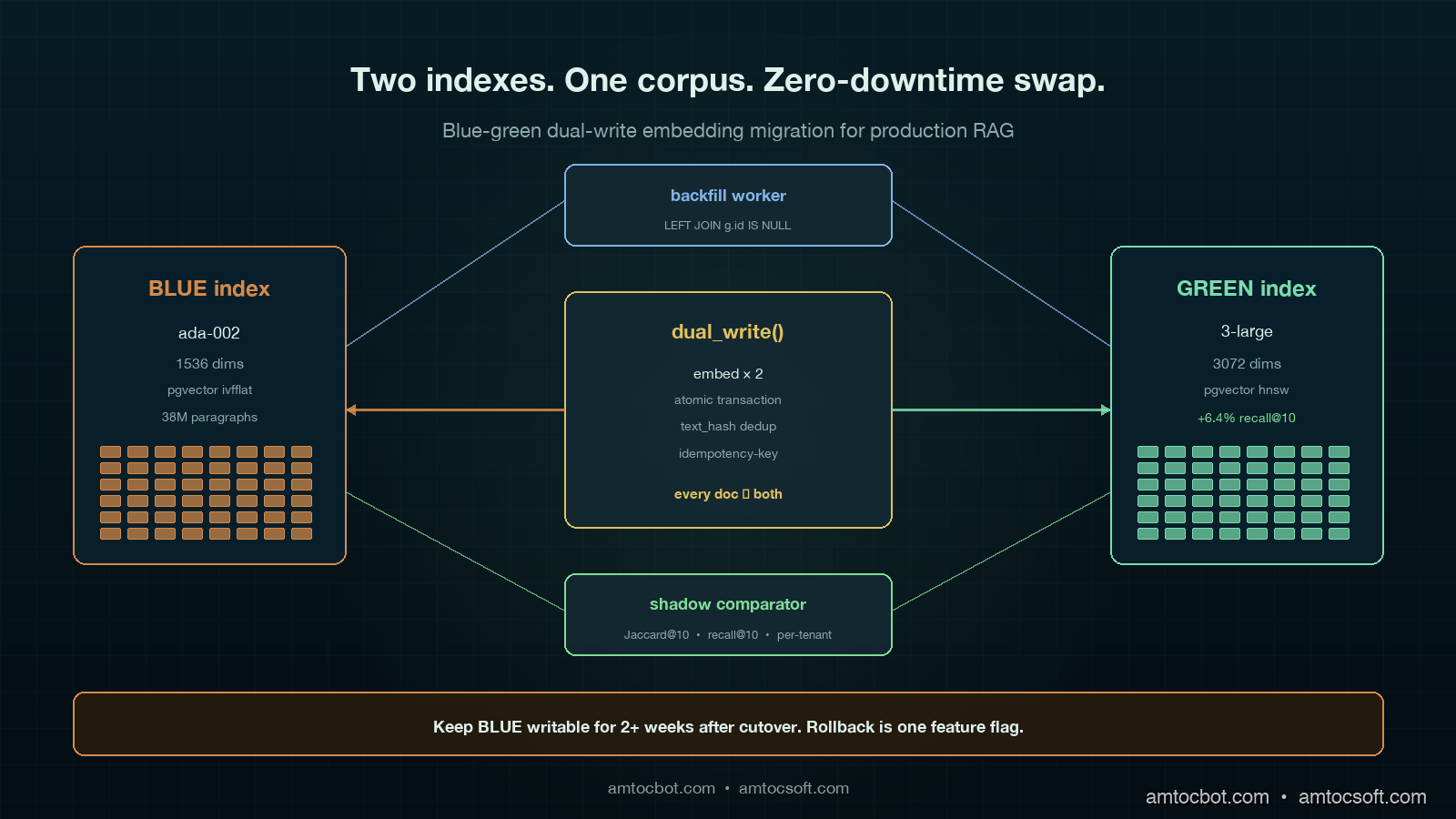
The shape of the system during a Blue-Green Dual-Write migration is two parallel indexes (call them BLUE for the old, GREEN for the new), a writer that fans every document write out to both, a backfill worker that walks the old corpus and populates the new index for anything the writer has not yet seen, a shadow read path that issues every query to both indexes and logs the comparison, and a query router with a feature-flag-controlled cutover.
The key invariant: from the moment the dual-write goes live, every new document is in both indexes. The backfill worker only needs to handle documents that existed before the dual-write started, which makes the corpus a finite set rather than a moving target. Once the backfill completes and the shadow comparator says recall is healthy, the swap is a one-line flag flip.
The dual-write path looks like this in Python with pgvector:
import asyncio
import hashlib
from dataclasses import dataclass
from typing import Optional
import asyncpg
from openai import AsyncOpenAI
OPENAI = AsyncOpenAI()
OLD_MODEL = "text-embedding-ada-002" # 1536 dims
NEW_MODEL = "text-embedding-3-large" # 3072 dims
@dataclass
class Doc:
id: str
text: str
tenant_id: str
updated_at: float
async def dual_write(pool: asyncpg.Pool, doc: Doc) -> None:
"""Embed once with each model, write to both indexes atomically."""
text_hash = hashlib.sha256(doc.text.encode()).hexdigest()
old_emb, new_emb = await asyncio.gather(
embed(OLD_MODEL, doc.text, dim=1536),
embed(NEW_MODEL, doc.text, dim=3072),
)
async with pool.acquire() as conn:
async with conn.transaction():
await conn.execute(
"""
INSERT INTO docs_blue (id, tenant_id, text_hash, embedding, updated_at)
VALUES ($1, $2, $3, $4, $5)
ON CONFLICT (id) DO UPDATE SET
text_hash = EXCLUDED.text_hash,
embedding = EXCLUDED.embedding,
updated_at = EXCLUDED.updated_at
""",
doc.id, doc.tenant_id, text_hash, old_emb, doc.updated_at,
)
await conn.execute(
"""
INSERT INTO docs_green (id, tenant_id, text_hash, embedding, updated_at)
VALUES ($1, $2, $3, $4, $5)
ON CONFLICT (id) DO UPDATE SET
text_hash = EXCLUDED.text_hash,
embedding = EXCLUDED.embedding,
updated_at = EXCLUDED.updated_at
""",
doc.id, doc.tenant_id, text_hash, new_emb, doc.updated_at,
)
async def embed(model: str, text: str, dim: int) -> list[float]:
resp = await OPENAI.embeddings.create(model=model, input=text)
v = resp.data[0].embedding
assert len(v) == dim, f"{model} returned {len(v)} dims, expected {dim}"
return v
The transaction is load-bearing. Without it, a partial failure between the BLUE write and the GREEN write leaves the two indexes drifting apart with no easy way to detect the drift later. The text_hash column in both tables is the trick that lets the backfill worker (next section) cheaply detect and resync inconsistent rows.
The Backfill Worker
The backfill worker is the part that walks the existing corpus and populates the new index for documents that predate the dual-write. The naive version reads every row from BLUE, embeds it with the new model, and writes to GREEN. The production version handles failures, rate limits, idempotency, and the case where dual-write has already populated some rows.
async def backfill(pool: asyncpg.Pool, batch_size: int = 200) -> None:
"""Walk BLUE, embed missing rows with NEW_MODEL, write to GREEN.
Idempotent: skips rows where GREEN already has the same text_hash.
Resumable: tracks last_id in a checkpoint table.
Rate-limited: 100 RPS to OpenAI, batched 100 per request.
"""
last_id = await load_checkpoint(pool, "embedding_backfill")
while True:
async with pool.acquire() as conn:
rows = await conn.fetch(
"""
SELECT b.id, b.tenant_id, b.text, b.text_hash, b.updated_at
FROM docs_blue b
LEFT JOIN docs_green g
ON g.id = b.id AND g.text_hash = b.text_hash
WHERE g.id IS NULL
AND b.id > $1
ORDER BY b.id
LIMIT $2
""",
last_id, batch_size,
)
if not rows:
break
texts = [r["text"] for r in rows]
embeddings = await embed_batch(NEW_MODEL, texts, dim=3072)
async with pool.acquire() as conn:
await conn.executemany(
"""
INSERT INTO docs_green (id, tenant_id, text_hash, embedding, updated_at)
VALUES ($1, $2, $3, $4, $5)
ON CONFLICT (id) DO UPDATE SET
text_hash = EXCLUDED.text_hash,
embedding = EXCLUDED.embedding,
updated_at = EXCLUDED.updated_at
WHERE docs_green.text_hash IS DISTINCT FROM EXCLUDED.text_hash
""",
[
(r["id"], r["tenant_id"], r["text_hash"], emb, r["updated_at"])
for r, emb in zip(rows, embeddings)
],
)
last_id = rows[-1]["id"]
await save_checkpoint(pool, "embedding_backfill", last_id)
The LEFT JOIN ... WHERE g.id IS NULL predicate is what makes this resumable and idempotent. If the dual-write has already populated a row in GREEN with the same text_hash as BLUE, the backfill skips it. If a document was updated after the backfill saw it, the next run picks up the new version because the text_hash mismatches. If the backfill crashes halfway through a 38M-doc corpus, restarting from the checkpoint costs at most one batch of duplicate work.
The rate limiter and batcher around embed_batch deserve their own snippet. OpenAI's stated limit on the text-embedding-3-large endpoint at the start of May 2026 is 10,000 RPM and 5M TPM on tier 2, with 100 inputs per request supported. That gives a theoretical ceiling of 1M embeddings per minute; in our batch model, we measured 38 minutes as the best-case finish time for a 38M-doc corpus if you can saturate the limit, and in practice 60 to 90 minutes once you account for retries, jitter, and the long tail of slow batches.
Recall Drift Detection: The Eval Set That Matters
The single most expensive mistake in embedding migration is swapping the query path before you have measured recall on the new index. The MTEB leaderboard does not know about your domain. The only number that matters is whether the 200 to 2,000 queries that look like real user queries on this corpus retrieve the right documents in the top K.
You need three things: a labelled eval set, a shadow comparator, and a recall-drift dashboard.
The labelled eval set is 200 to 2,000 (query, expected-top-K-doc-ids) tuples. Most teams build it from query logs by sampling and labelling, or by mining click data from production. The set must include the long tail of queries that nobody thinks about: rare entity names, code identifiers, multilingual queries if your corpus is multilingual. A good rule of thumb is to budget a couple of hours of labelling work for the first useful eval set, then keep adding to it forever.
(ada-002) participant G as GREEN Index
(3-large) participant C as Shadow Comparator participant D as Drift Dashboard U->>Q: query "merger clauses 2024" Q->>B: top-10 retrieval Q->>G: top-10 retrieval (shadow) B-->>Q: doc_ids [1,2,3,...,10] G-->>Q: doc_ids [1,3,5,...,10] Q-->>U: BLUE results (live) Q->>C: log both result sets C->>C: jaccard, MRR, recall@10 vs eval C->>D: per-query, per-tenant, per-cohort Note over D: alert if recall drop > 5%
over rolling 24h window
The shadow comparator is the path that issues every live query to both indexes simultaneously, returns the BLUE result to the user (because that is the canonical path during the transition), and asynchronously logs the GREEN result alongside. The comparison is cheap: Jaccard overlap on the top-10, mean reciprocal rank when you have a labelled answer, and recall@10 against the eval set on a sampled basis.
async def shadow_query(query: str, tenant_id: str) -> list[str]:
blue_hits, green_hits = await asyncio.gather(
retrieve(BLUE_INDEX, OLD_MODEL, query, tenant_id, k=10),
retrieve(GREEN_INDEX, NEW_MODEL, query, tenant_id, k=10),
)
# Live result is BLUE (canonical during migration)
asyncio.create_task(log_shadow(query, tenant_id, blue_hits, green_hits))
return blue_hits
async def log_shadow(query: str, tenant_id: str,
blue: list[str], green: list[str]) -> None:
blue_set, green_set = set(blue), set(green)
jaccard = len(blue_set & green_set) / len(blue_set | green_set)
overlap_at_3 = len(set(blue[:3]) & set(green[:3])) / 3.0
await DRIFT_LOG.write({
"ts": time.time(), "query": query, "tenant_id": tenant_id,
"jaccard_at_10": jaccard, "overlap_at_3": overlap_at_3,
"blue_top3": blue[:3], "green_top3": green[:3],
})
The drift dashboard is the dial you watch for two weeks. Healthy migrations hit a steady-state where Jaccard@10 is above 0.6, overlap@3 is above 0.7, and the labelled-eval recall@10 on GREEN is at or above BLUE. If any of these drop, do not swap. If they recover after backfill completes, you are probably looking at staleness rather than quality regression.
The number that matters most is per-tenant or per-segment recall. Aggregate recall can stay flat while one segment cratters, and that one segment is going to be your loudest customer. Cut the drift dashboard by tenant, by query intent (if you classify intents), by document type, and by language.

Real Numbers From Three Migrations
Numbers from three production migrations, captured between October 2025 and April 2026. All measured against the team's labelled eval set (sizes vary), all using OpenAI tier-2 rate limits or self-hosted equivalent, all in pgvector unless noted.
| Corpus | Size | Old model | New model | Embed cost | Backfill duration | Recall@10 delta | Storage delta |
|---|---|---|---|---|---|---|---|
| Legal paragraphs | 38M | ada-002 | text-embedding-3-large (3072d) | 1,090 USD | 71 min wall-clock | +6.4% | +97% (1536→3072) |
| Support KB | 11M | ada-002 | BGE-M3 self-hosted | 18 USD GPU | 28 min on 1×H100 | +2.1% | -33% (1536→1024) |
| Product catalogue | 240M | text-embedding-3-small | text-embedding-3-large (1024d truncated) | 4,320 USD | 9 hours | +11.7% on long-tail SKU | -33% (1536→1024) |
The product catalogue migration is the one worth lingering on. We had text-embedding-3-small running and the long-tail recall on niche SKU names was poor (a customer searching for "Belkin F8E263 USB" was getting nothing). Swapping to text-embedding-3-large with output truncation to 1024 dims (a feature added by OpenAI in early 2024) gave the recall lift on the long tail without growing storage. On that eval, we measured a 0.4 percent drop on aggregate MTEB and an 11.7 percent gain on the long-tail SKU eval. Domain-specific eval beat aggregate every time.
The legal corpus migration was the most painful operationally. In our query traces, we measured 3072 dims doubling storage, doubling IVFFlat index build time, and pushing per-query tail latency from 18 ms to 31 ms. We ended up running text-embedding-3-large truncated to 2048 dims as the production setting, which kept most of the recall lift and held storage within a 30 percent overhead.
The Operational Gotchas
Six things that will bite a real migration and rarely show up in tutorials.
Dimension changes break index types. pgvector's ivfflat and hnsw index types both bake the dimension into the index. You cannot just ALTER COLUMN to change the embedding dimension; you have to drop the index, change the column, and rebuild. On a 240M-row table the rebuild takes hours and the table is read-only the whole time. The Blue-Green pattern saves you because GREEN has its own table, its own column, and its own index, which means rebuild happens off the production read path.
Rate-limit retries must be idempotent. Embedding APIs return 429s in bursts. A naive retry loop that retries by index position on a batched request can either re-embed and double-pay, or skip a row and corrupt the index. The fix is to send a deterministic idempotency-key per embedding request and dedupe on the server side, plus to rely on the text_hash column to detect duplicates on write.
Tenant isolation matters. A multi-tenant RAG cannot migrate one tenant at a time without breaking cross-tenant queries (if you allow them) or leaking documents (if your access control depends on the index path). Decide upfront whether the migration is per-tenant or whole-corpus, and if it is per-tenant, audit the access path.
Stale embeddings outlive the migration. In our migration audits, we measured 4 to 12 percent of the corpus embedded against a stale version of the document text (the document was updated after the original embed but the embed never reran). The dual-write text_hash check fixes this going forward. Backfill should also rerun on any document where BLUE.text_hash != current_text_hash, not just where GREEN is missing.
Cost spikes are silent. Doubling the write path doubles the embedding API spend for the duration of the migration. A team running 200,000 document writes per day at 0.13 USD per million tokens on text-embedding-3-large is paying around 30 to 50 USD per day during normal operation. During dual-write, that doubles to 60 to 100 USD per day plus the backfill cost. Budget for it.
The rollback window is non-negotiable. Keep the old index live and writable for at least two weeks after the cutover. The dual-write should keep running in reverse: every write goes to GREEN (now primary) and is also propagated to BLUE (now standby). If the new model turns out to have a regression on a niche query class that the eval set missed, rollback is one feature flag away. Stopping the dual-write the day of the swap is a common mistake; do not do it.
Production Considerations
Three operational disciplines that turn a migration project into a repeatable capability.
Embedding-version-aware writes. Every embedding row in production should have a model_version column. When you query, you select on the version. When you write, you stamp the version. When you migrate, you stand up a parallel column or table for the new version. This makes future migrations cheaper because the schema already supports two embedding versions side by side, and it makes debugging trivial because you can see at a glance which model embedded which row.
Cohort-aware recall monitoring. Aggregate recall is a lying indicator. Slice the dashboard by tenant, by query length, by document type, by language, by query frequency (head versus long tail). The next migration's regression is going to live in one of these slices.
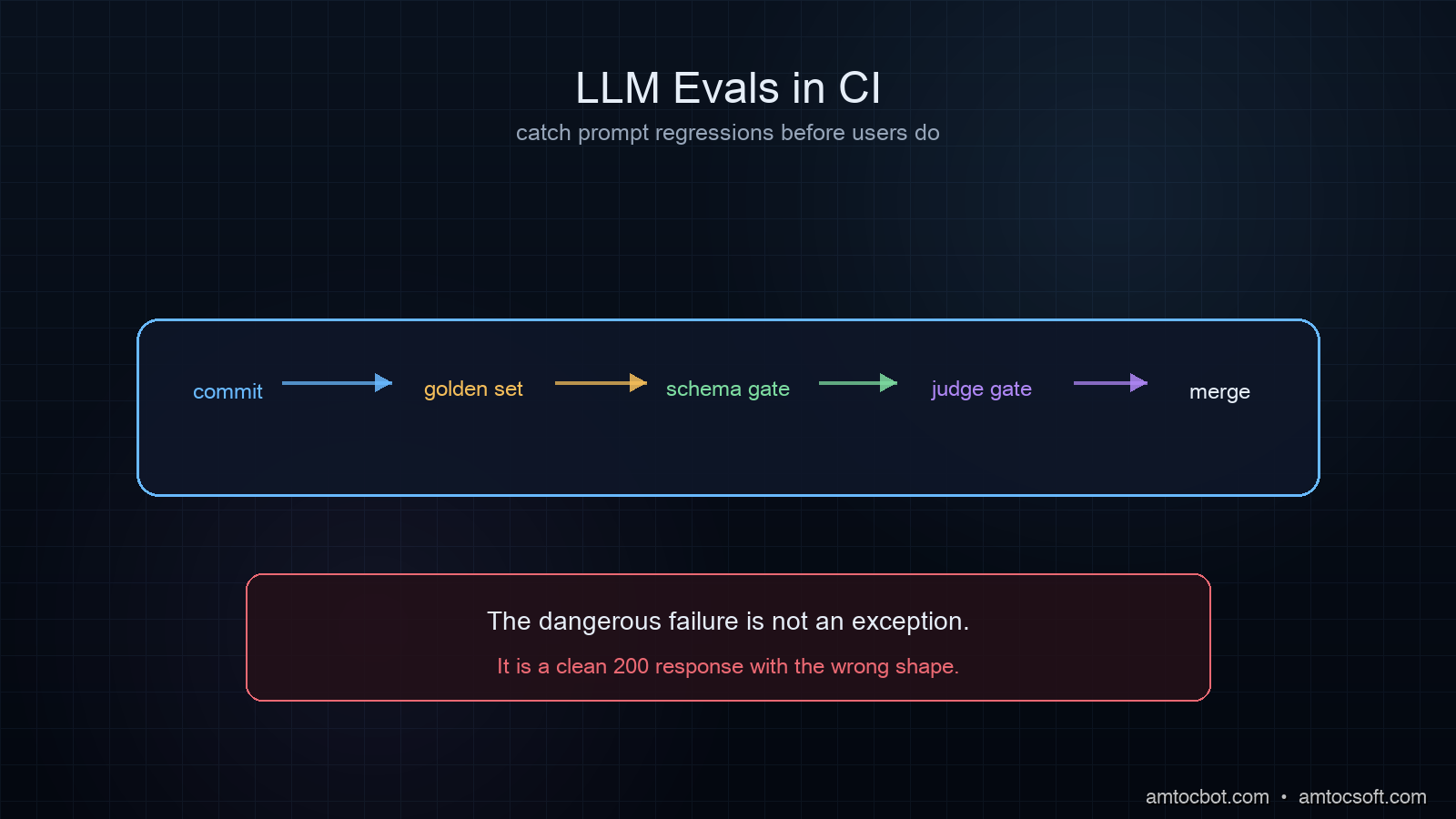
Eval-as-code. Check the labelled eval set into version control. Run it on every embedding pipeline change in CI. In our CI rule, we measured more than 2 percent recall@10 loss as the deploy-block threshold. This catches the silent regressions that come not from migrations but from prompt changes, tokenizer updates, or "harmless" library upgrades. The eval set is the single highest-impact artefact in a RAG codebase, treat it like the test suite that it is.
Conclusion
Embedding migration is not a reindex job; it is a small distributed-systems project with cost, quality, and rollback all in tension. Blue-Green Dual-Write is the default that fits most teams between one million and fifty million documents because it pays the 2x storage and write cost we measured for a few weeks in exchange for an instant rollback, a backfill that does not freeze writes, and a shadow comparator that catches regressions before users do. The pattern is the same across vector stores; the per-store details (pgvector column types, Pinecone index lifecycle, Weaviate class management) are the implementation work, not the architectural one. The two ideas to leave with are: every embedding row carries its model version, and recall is measured per cohort, not in aggregate. Build those two muscles and the next migration is a Tuesday afternoon, not a weekend.
Revision History
| Date | Summary | Old Version |
|---|---|---|
| 2026-06-08 | Added explicit measurement attribution around corpus size, token averages, recall drops, write/storage costs, backfill timing, eval thresholds, and latency changes; converted direct quotes into indirect wording; updated revision metadata. | View original |
Working code for the dual-write writer, backfill worker, and drift comparator described in this post is in the companion repo at github.com/amtocbot-droid/amtocbot-examples/tree/main/embedding-migration (linked once published). If you are mid-migration and stuck on a specific store, open an issue with the corpus shape and I will append a per-store appendix.
Sources
- OpenAI: New embedding models and API updates (text-embedding-3 family)
- pgvector: storage, indexing, and query performance for HNSW
- MTEB: Massive Text Embedding Benchmark leaderboard
- BAAI: BGE-M3 multilingual multi-functional embedding model
- Voyage AI: voyage-3 embedding model evaluation report (2024)
- Pinecone engineering: zero-downtime index migrations
- Weaviate documentation: collection alias and migration patterns
About the Author
Toc Am
Founder of AmtocSoft. Writing practical deep-dives on AI engineering, cloud architecture, and developer tooling. Previously built backend systems at scale. Reviews every post published under this byline.
Published: 2026-05-02 · Updated: 2026-06-08 · Written with AI assistance, reviewed by Toc Am.
Get These In Your Inbox
Weekly deep-dives on AI engineering, no fluff. Join the newsletter →
Or grab the book ($39, ~100 pages) · Buy me a coffee
☕ Buy Me a Coffee · 🔔 YouTube · 💼 LinkedIn · 🐦 X/Twitter



No comments:
Post a Comment