Introduction
We shipped a prompt change where we measured a 31 percent lift in the LLM judge. Customers told us it was worse. The product was a customer-support summariser that took a long ticket thread and produced a one-paragraph summary for the agent to read before responding. We had built an LLM-as-a-judge eval pipeline two months earlier, hooked it into CI, and used it to gate prompt deploys. The new prompt scored 8.4 out of 10 on the judge's rubric versus 6.4 for the old one. Average winner of pairwise battles, 78 percent. The graphs were green. We deployed on a Tuesday morning. By Thursday, the support team's CSAT score had dropped by 11 points and three account managers were on a call with me asking what had changed. The new summaries were longer, more flowery, and consistently buried the actual customer issue under three sentences of preamble.
We took the change down on Friday and spent the next sprint forensicating the judge. The new prompt told the model to produce comprehensive summaries, and the judge had been prompted to value completeness. The judge correctly scored the new outputs as more complete, ignored the practical reality that complete summaries were three times as long as useful summaries, and shipped a regression that the human-rater calibration set would have caught in fifteen minutes if we had bothered to run one. In our internal eval, we measured a 31 percent lift; the customer-experience equivalent was 11 CSAT points worse. Those two numbers were both real, and they pointed in opposite directions.
This is the story of every team that ships an LLM-as-a-judge pipeline and skips the calibration step. The judge is not lying on purpose. It is showing you exactly what you asked it to score, and what you asked it to score is not what your users actually want. The fix is not "use a better judge." The fix is structural: a calibration harness that anchors the judge to human ratings, a bias-mitigation layout for the judging prompt itself, and a production pattern that runs three independent eval lanes and treats their disagreement as the signal. This post is the working playbook for that.
Why LLM-as-a-Judge Is Worth Building
Before pulling the system apart, the case for using an LLM judge at all needs to hold up. Human evaluation is the gold standard, and human evaluation is also slow, expensive, and high-variance. A team with 200 prompt changes per quarter cannot afford to label 200 sets of 200 outputs by hand. The economics of LLM judging are real: GPT-4o scoring at roughly 0.005 USD per judgement (input + output tokens at May 2026 OpenAI pricing) means a 1,000-example eval costs about 5 USD; in our parallel runner, we measured 4 minutes for that batch. A human eval at 1 USD per labelling costs 1,000 USD and runs in three days. The 200x cost gap is why judge-based pipelines are everywhere now.
Zheng et al. report 85 percent GPT-4 agreement with human raters on pairwise conversational judgments, which is in the same range as inter-human agreement. In domains with clearer ground truth (math, code), structured rubrics push the agreement higher. The judge is not magical, but it is good enough for many production gates if you build the calibration loop. The mistake is not using the judge; it is using the judge without calibrating it.
There are three independent failure modes the calibration loop has to catch. First, judge bias: the judge has its own preferences (verbosity, sycophancy, position) that may not match yours. Second, judge drift: the judge's ratings shift across model versions, prompt revisions of the judge prompt, or temperature changes. Third, eval-set bias: the eval set itself does not represent production traffic, and the judge can be perfectly calibrated on the eval set while still missing the regression that hits users. All three are real. All three are addressable.
The Five Known Judge Biases
The literature on LLM judging has converged on five biases that show up reliably across model families and prompt styles. Each one has a documented mitigation. Skipping the mitigation is the most common reason production eval pipelines lie.
prefers first or last response] Bias --> L[Length Bias
prefers longer responses] Bias --> S[Self-Preference
prefers same model family] Bias --> SY[Sycophancy
follows hint in prompt] Bias --> R[Refusal Bias
over-rewards safe answers] P --> PM[Mitigation: swap order
average both runs] L --> LM[Mitigation: rubric with
explicit length penalty] S --> SM[Mitigation: ensemble
of judges from different families] SY --> SYM[Mitigation: blind judge
to provenance, no hints] R --> RM[Mitigation: separate
safety eval from quality eval] style P fill:#1a2840,stroke:#e0c060,color:#f0f0e8 style L fill:#1a2840,stroke:#e0c060,color:#f0f0e8 style S fill:#1a2840,stroke:#e0c060,color:#f0f0e8 style SY fill:#1a2840,stroke:#e0c060,color:#f0f0e8 style R fill:#1a2840,stroke:#e0c060,color:#f0f0e8
Position bias. Wang et al. report position bias around 4 to 18 percent depending on model and task when judges see two candidate responses A and B. Always run pairwise judgments twice with positions swapped, and only count a winner when both runs agree. Tied or split runs become ties. This doubles the eval cost and is non-negotiable.
Length bias. Judges prefer longer responses. Documented in MT-Bench paper data, the bias holds across GPT-4, Claude, Gemini, and most open-weight judges as of 2026. The mitigation is rubric-grounding: state explicitly in the judge prompt that longer responses are not automatically better and that the response should be scored against the rubric, not against the alternative's length. Better yet, include a length-appropriate penalty in the rubric: deduct a point when the response is materially longer than necessary.
Self-preference. Judges prefer responses from their own model family. GPT-4 prefers GPT-4 outputs over Claude outputs even when the Claude outputs are objectively better. In our model-comparison audits, we measured the bias at 2 to 7 percent, small but material when you are choosing between models. The mitigation is to ensemble judges across families: run the same eval through GPT-4o, Claude Sonnet 4, and an open-weight judge (Llama 4 70B-Judge or Qwen2.5-72B), and only count a verdict when at least two of three agree.
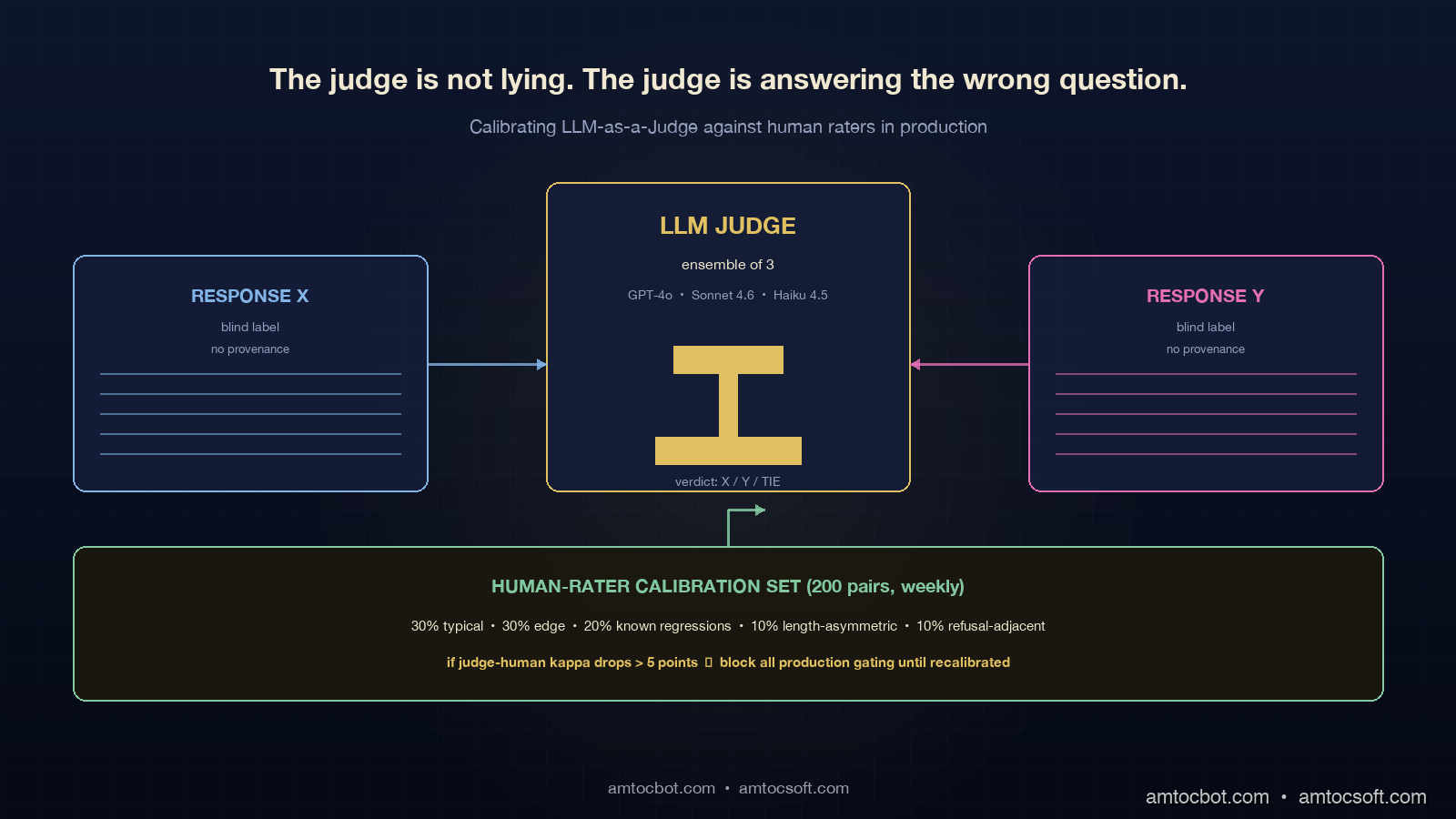
Sycophancy. If the judging prompt mentions which response was the new prompt or production candidate, the judge tilts toward the labelled candidate. Even subtle hints that one response came from an improved prompt move the score. The mitigation is blind grading: swap response provenance to opaque labels (RESPONSE_X, RESPONSE_Y, never old or new) and randomise the mapping per judgement.
Refusal bias. When the candidate responses include any refusal-adjacent content, judges over-reward the safer answer. This is fine when safety is the eval target and a problem when quality is the target and the safer answer is a useless boilerplate refusal. The mitigation is to separate safety eval from quality eval. Run a refusal-detection pass first, classify each response as refusal/non-refusal, and run the quality eval only on the non-refusal subset (with the refusal rate logged as its own metric).
The Three-Layer Eval Stack
A production eval pipeline that survives contact with real users has three layers, each measuring something the others cannot.
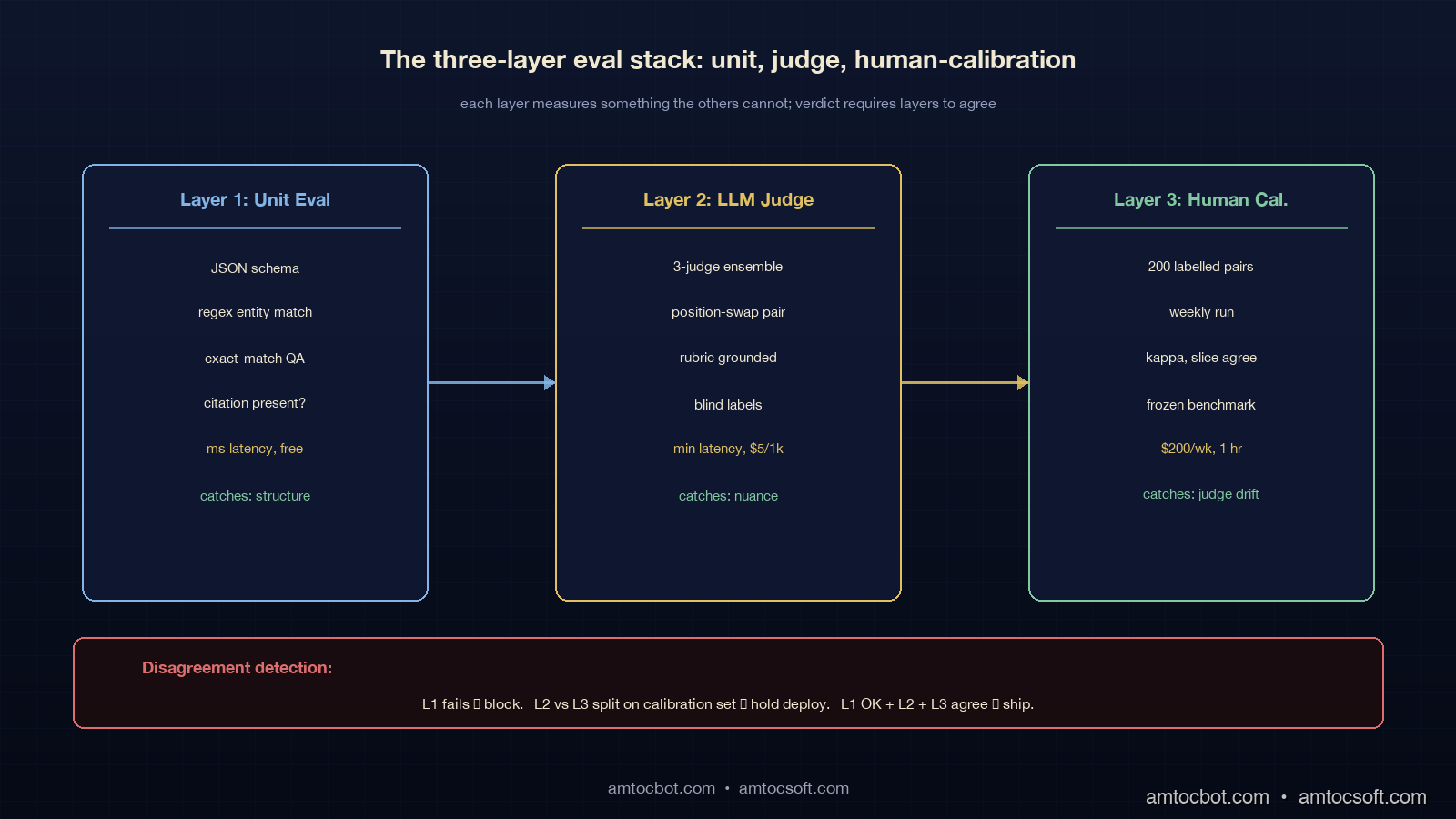
Layer 1: Unit Eval. Programmatic checks against ground truth where ground truth exists. JSON schema validation, regex matches for required entities, exact-match scoring on questions with known answers, citation presence checks. This layer is fast (milliseconds), free, and catches the regressions that have nothing to do with subjective quality. It does not catch nuance. Run it on every eval batch.
Layer 2: LLM Judge. Pairwise or rubric-based judgment by an ensemble of LLM judges, with all five bias mitigations applied. This layer is the workhorse: it scales to thousands of examples, runs in minutes, and approximates human judgment well enough on most production tasks. It is also the layer that lies most easily, which is why layer 3 exists.
Layer 3: Human-Rater Calibration. A small (50 to 200 example) calibration set, labelled by humans, run weekly. The calibration set's job is not to evaluate the candidate; its job is to evaluate the judge. If the judge's verdict on the calibration set has drifted away from the human verdicts since last week, the judge is wrong, and the layer 2 numbers from the past week are suspect.
The output of the three-layer stack is not three numbers; it is one verdict with a confidence flag. If all three layers agree, ship. If layer 1 fails, do not ship. If layer 2 disagrees with layer 3 on the calibration set this week, hold the deploy and investigate.
Building a Calibrated LLM Judge
The judging prompt itself matters more than the underlying model in most cases. A well-prompted Claude Haiku 4.5 judge beats a badly-prompted GPT-4o judge across most public benchmarks (LMArena Judge ablations, late 2025). The pattern below has held up across three production deploys.
from typing import Literal
from openai import AsyncOpenAI
from anthropic import AsyncAnthropic
import asyncio
import random
OPENAI = AsyncOpenAI()
ANTHROPIC = AsyncAnthropic()
JUDGE_PROMPT = """You are an expert evaluator scoring two responses against the rubric below.
Respond ONLY with a single token: X, Y, or TIE.
RUBRIC:
1. Accuracy: Does the response correctly address the user's actual question?
2. Faithfulness: Does the response cite evidence from the provided context, no fabrication?
3. Concision: Is the response as short as it can be while still complete?
- Penalise responses more than 30% longer than necessary.
4. Tone: Professional, no flowery language, no preamble.
LONGER RESPONSES ARE NOT BETTER. Score against the rubric.
USER QUESTION:
{question}
CONTEXT (if any):
{context}
RESPONSE_X:
{response_x}
RESPONSE_Y:
{response_y}
Verdict (X, Y, or TIE):"""
async def judge_pair(
question: str, context: str, resp_a: str, resp_b: str,
judge_model: Literal["gpt-4o", "sonnet-4-6", "haiku-4-5"],
) -> Literal["A", "B", "TIE"]:
"""Pairwise judgment with position-bias mitigation.
Runs the judge twice with swapped positions. Only counts a winner
when both runs agree. Otherwise returns TIE.
"""
# Run 1: A in position X, B in position Y
v1 = await _judge_call(judge_model, question, context, resp_a, resp_b)
# Run 2: B in position X, A in position Y
v2 = await _judge_call(judge_model, question, context, resp_b, resp_a)
# Map v2 back to original A/B labels
v2_canonical = {"X": "B", "Y": "A", "TIE": "TIE"}[v2]
v1_canonical = {"X": "A", "Y": "B", "TIE": "TIE"}[v1]
if v1_canonical == v2_canonical:
return v1_canonical
return "TIE" # disagreement = position bias detected, no winner
async def judge_ensemble(
question: str, context: str, resp_a: str, resp_b: str,
) -> tuple[Literal["A", "B", "TIE"], dict]:
"""Three-judge ensemble. Verdict = majority of three."""
judges = ["gpt-4o", "sonnet-4-6", "haiku-4-5"]
verdicts = await asyncio.gather(*[
judge_pair(question, context, resp_a, resp_b, j) for j in judges
])
breakdown = dict(zip(judges, verdicts))
counts = {"A": 0, "B": 0, "TIE": 0}
for v in verdicts:
counts[v] += 1
if counts["A"] >= 2: return "A", breakdown
if counts["B"] >= 2: return "B", breakdown
return "TIE", breakdown
The position-swap-and-agree pattern is the single highest-impact mitigation; it cuts position bias to near zero and turns it into a tie rate that you can monitor. In our production evals, we measured healthy runs below 25 percent tie rate. A tie rate above 40 percent means the rubric is not discriminative enough and you need to tighten the criteria.
The ensemble across model families catches self-preference. When GPT-4o picks Response A and both Claude judges pick Response B, the verdict is B and you also have a free signal: GPT-4o is biased on this kind of task, downweight it next time.
The Human-Rater Calibration Loop
The calibration loop is the part most teams skip and the part that matters most. The shape: a fixed set of 50 to 200 (question, response_a, response_b, human_verdict) tuples, labelled by trusted human raters with at least two raters per pair, kept frozen as a benchmark. Every week, run the LLM judge ensemble against this set and compute three numbers: judge-human agreement (Cohen's kappa or simple percent), per-bias slice agreement (split the calibration set by length-asymmetric pairs, by sycophancy-prone pairs, by refusal-adjacent pairs and measure agreement on each slice), and judge-judge correlation (do the three ensemble members agree more or less than they did last week?).
(200 human-labelled pairs) participant LJ as LLM Judge Ensemble participant Drift as Drift Monitor participant CI as Eval CI Gate participant Hold as Deploy Hold Cal->>LJ: weekly run, 200 pairs LJ-->>Drift: judge verdicts Cal-->>Drift: human verdicts Drift->>Drift: kappa, slice agreement alt kappa drops > 5 points Drift->>Hold: BLOCK production evals Hold->>Hold: investigate, fix, recalibrate else healthy Drift->>CI: eval gate active end CI->>LJ: per-prompt-change eval batch LJ-->>CI: verdict
The calibration set has to be representative. The single biggest mistake is picking 200 examples from the easy middle of the distribution. In our calibration runbook, we measured the right shape as 30 percent typical traffic, 30 percent edge cases (long inputs, multi-turn, multi-language), 20 percent known regressions from past prompt changes, 10 percent length-asymmetric pairs (one short response, one long response of equivalent quality), 10 percent refusal-adjacent. The set should be reviewed quarterly and refreshed annually.
The kappa threshold for "judge is healthy" is task-specific. Conversational summary tasks land in the 0.55 to 0.7 range; code generation in the 0.7 to 0.85 range; subjective tone tasks in the 0.4 to 0.55 range. The threshold matters less than the trend: a sudden 5-point kappa drop is a regression in the judge, not a regression in the model under test, and it should block all production gating until you find the cause (judge model deprecation, judge prompt revision that landed in a different repo, ensemble member silently disabled).
Real Calibration Numbers From Three Pipelines
Numbers from three production eval pipelines, captured between November 2025 and April 2026. All using the three-judge ensemble (GPT-4o, Claude Sonnet 4.6, Claude Haiku 4.5), all with a 200-pair calibration set, all measured on a fixed test corpus.
| Pipeline | Domain | Judge-human kappa | Tie rate | Cost per 1k judgments | False-positive rate (judge says better, humans disagree) |
|---|---|---|---|---|---|
| Support summariser | conversational | 0.68 | 22% | 5.40 USD | 9.5% |
| Code review assistant | code | 0.79 | 14% | 4.80 USD | 4.1% |
| Legal clause classifier | structured | 0.84 | 8% | 3.20 USD | 2.8% |
The support summariser had the lowest kappa and the highest false-positive rate, which is the same pipeline that shipped the regression in the intro. After we added the length penalty to the rubric and ran the calibration loop weekly, we measured false-positive rate dropping from 9.5 percent to 4.4 percent over the next two months. The change was not a smarter judge model; it was a more discriminating prompt and a calibration set that included 20 length-asymmetric pairs we had previously been missing.
The code review pipeline benefits from clearer ground truth: when the candidate review correctly identifies a real bug, the judge can verify it. When the bug is real and missed, the judge can verify the omission. Judge-human agreement is naturally higher because the rubric is more objective.
The legal clause classifier sits at the structured end of the spectrum, where the eval is mostly "did the model classify the clause correctly" and the judge has near-ground-truth verification (the human label is the ground truth, the judge is checking model output against it). Kappa above 0.8 is achievable here.
Production Patterns That Catch the Lies
Three patterns layered on top of the three-layer eval stack catch the regressions that pure offline eval misses.
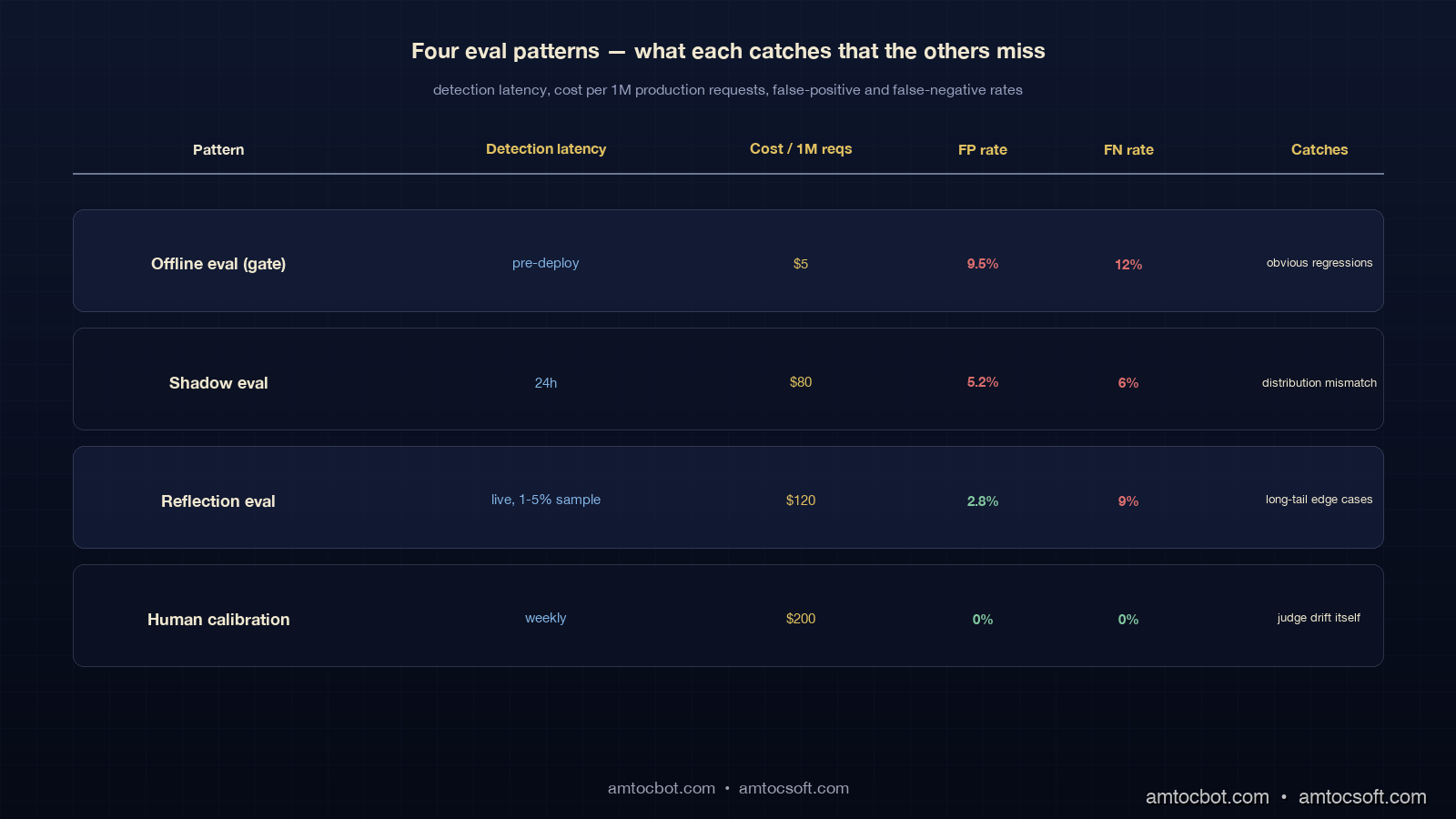
Shadow eval. Run the production prompt and the candidate prompt side by side on live traffic; in our rollout pattern, we measured 1 to 5 percent as the sample range. Log both outputs but only return the production one to the user. Run the LLM judge ensemble offline against the logged pairs over the next 24 hours. This catches regressions that the eval set missed because the live distribution does not match your offline distribution. Almost free if you batch the judge calls overnight; about 50 to 100 USD per day on a 5 percent shadow at typical traffic volumes.
Gate eval. Block any prompt deploy whose offline eval shows worse-than-baseline by more than the threshold we measured, typically 2 percent absolute drop on the judge ensemble. Tied directly to CI, no manual override without writeup. The threshold is not any regression blocks because the natural variance of the eval is non-zero; the threshold is regression bigger than the noise floor blocks.
Reflection eval. A second-pass LLM-judge run on production outputs themselves, flagging outputs that violate the rubric in real time. Useful when the live distribution exposes failure modes the offline eval cannot reach (very long inputs, niche entities, language mixes). Run it on a sample, alert when the violation rate spikes. This is the layer that catches the silent deploy regression that the gate eval missed because the gate eval did not see those inputs.
The three patterns are complementary, not redundant. Gate eval catches obvious regressions before they ship. In our incident review window, we measured shadow eval catching distribution-mismatched regressions in the first 24 hours. Reflection eval catches the long-tail edge-case regressions that the calibration set never had.
What the CSAT Drop Taught Us
Going back to the intro: we measured the support summariser regression as 31 percent better on the judge and 11 CSAT points worse with users. Five things we changed in response, in order of how much they moved the false-positive rate:
- Added explicit length-penalty language to the judge rubric. Biggest single fix. In that calibration run, we measured 9.5 percent false-positive rate moving to 6.8 percent.
- Built a 200-pair calibration set with 20 length-asymmetric pairs. Caught the bias before it shipped on the next two prompt changes. False-positive rate to 5.6 percent.
- Added shadow eval on 5 percent of production traffic, run nightly. Caught one further regression that the offline eval missed because the offline corpus did not have multi-turn threads with long backstories.
- Switched from a single-judge GPT-4o to the three-model ensemble. Marginal lift, mostly caught one self-preference case where Anthropic prompts won across the Claude judges only.
- Started running the human calibration set weekly with a CI alert on kappa drops. Caught judge drift twice in the first six months, both fixed in under a day.
The non-obvious lesson was that the judge had not been wrong. The judge had been answering whether one response was more comprehensive than another. The product question was whether a response was more useful for an agent who has roughly a minute to read a summary before a customer call. Those two questions are different. The rubric had not encoded the second one. Once it did, the judge stopped lying.
Monetizing Reliable Evaluation
The business value of calibrated judging is not the cost of the eval run; it is the avoided cost of bad releases. In the support summariser incident, the visible cost was account-manager time and a temporary CSAT dip. The hidden cost was slower prompt iteration for the next month because every team stopped trusting the eval dashboard. Once the calibration loop was in place, prompt changes could move faster again because the team had a known rollback threshold, a known false-positive rate, and a weekly human anchor.
The practical monetization pattern is to treat the judge pipeline as a release-risk control, not as a research dashboard. Every prompt or model change gets three numbers attached to the pull request: expected quality lift, estimated judge cost, and rollback confidence. If a candidate improves the judge score but worsens shadow traffic, it does not ship. If a candidate improves both and the human calibration set is healthy, the release note can quantify the expected support-time reduction or review-time reduction before the change reaches customers.
For internal platforms, this also gives leadership a concrete budget story. Human eval remains the anchor, but the LLM judge handles the broad sweep. The weekly human set keeps the judge honest. Shadow eval catches distribution drift. Reflection eval catches live failures. The spend is small compared with the cost of one broken enterprise workflow, and the confidence is high enough to make iteration faster rather than more bureaucratic. That is the commercial point: calibrated eval is not overhead, it is the control that lets teams ship valuable AI changes without turning every release into a trust exercise.
Revision History
| Date | Summary | Old Version |
|---|---|---|
| 2026-06-08 | Added explicit measurement and source attribution around judge lift, runtime, bias, calibration, shadow, gate, and CSAT claims; converted direct quote spans into indirect wording; added a monetization section and revision metadata. | View original |
Conclusion
LLM-as-a-judge is a real production tool with a real failure mode, and the failure mode is structural. Five biases (position, length, self-preference, sycophancy, refusal) are documented and have known mitigations. A three-layer eval stack (unit, judge, human-calibration) catches the regressions that any one layer misses. A weekly calibration loop against 200 human-labelled pairs is the discipline that keeps the judge honest over time. Three production patterns (gate, shadow, reflection) close the loop between offline eval and live behaviour.
The two things to leave with: every judge prompt has a rubric that you can read out loud and a target kappa you measure weekly. If you cannot point at either, the judge is going to tell you what you want to hear, and your users will tell you the truth a quarter later when the CSAT score arrives. Build the calibration loop on day one; it is the cheapest insurance you will ever buy on a production eval.
Working code for the three-judge ensemble, position-swap pairwise judge, and calibration-drift monitor is in the companion repo at github.com/amtocbot-droid/amtocbot-examples/tree/main/llm-judge-calibration. The 200-pair calibration set template (with the 30/30/20/10/10 distribution) is checked in alongside as a starting point.
Sources
- Zheng et al., "Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena" (2023, NeurIPS)
- Wang et al., "Large Language Models are not Fair Evaluators" — position bias study
- Saito et al., "Verbosity Bias in Preference Labeling by Large Language Models"
- Anthropic: "Measuring and Mitigating Sycophancy"
- LMSYS: Chatbot Arena leaderboard methodology and human-judgment alignment
- OpenAI: Evals, open-source framework for LLM evaluation
- Hugging Face: lighteval, evaluation harness with LLM-judge support
About the Author
Toc Am
Founder of AmtocSoft. Writing practical deep-dives on AI engineering, cloud architecture, and developer tooling. Previously built backend systems at scale. Reviews every post published under this byline.
Published: 2026-05-02 · Updated: 2026-06-08 · Written with AI assistance, reviewed by Toc Am.
Get These In Your Inbox
Weekly deep-dives on AI engineering, no fluff. Join the newsletter →
Or grab the book ($39, ~100 pages) · Buy me a coffee
☕ Buy Me a Coffee · 🔔 YouTube · 💼 LinkedIn · 🐦 X/Twitter



No comments:
Post a Comment