Introduction
The first time I paged the on-call engineer about an LLM outage was a Tuesday in late February. Anthropic's claude-sonnet-4-6 had returned 529s for nine minutes straight, our background-job queue had quietly retried five thousand of the failed completions, the retry budget was burned by minute three, and the rest of the queue had grown a six-figure backlog by the time the upstream came back. Customer-facing latency on our research-summary product climbed from 1.8s to 47s. Two enterprise customers escalated. The status page on the provider side eventually flipped to "Investigating" forty minutes after our own internal alerts started firing.
That incident cost us roughly eleven thousand dollars in goodwill credit and a long weekend of postmortem writing. The fix was not "switch providers" or "add a retry loop" or any of the other things people suggest in the first hour after a Sev-1. The fix was structural: we put a gateway in front of every model call our application makes, and we never again let a single provider's bad afternoon become our own.
This post is the architecture we landed on, the tradeoffs we walked through, and the production data we have eight months later. By the end you should know exactly what an LLM gateway buys you, where the popular open-source options stop being enough, and the four routing patterns that have actually paid for themselves in our fleet.
What an LLM Gateway Actually Is
The term "gateway" is overloaded. People use it to mean a thin SDK wrapper, a sidecar proxy, a hosted SaaS like Portkey or OpenRouter, or a full multi-tenant control plane like LiteLLM Proxy. They are not the same thing and they solve different problems.
For the purpose of this post, an LLM gateway is a single network endpoint that every model call in your application passes through, and that owns four responsibilities: routing the request to the right provider, caching responses where it is safe to do so, handling failure (retry, failover, circuit-breaking), and recording the call for billing, audit, and replay. Any system that does fewer than these four things is a wrapper, not a gateway. Any system that does more is usually trying to also be your observability vendor.
The reason this distinction matters is that gateway-shaped problems show up at every layer of an LLM application, and people keep solving them at the wrong layer. They put retries in the SDK call site. They put caching in the prompt template. They put cost tracking in the billing pipeline. They put model fallback in if/elif chains. Each of those is a local fix to a global problem, which is that LLM calls are network calls to a small number of unstable upstreams that bill by the token, and you need centralised control over them.
The gateway pattern is not new. The exact same architectural shape exists for HTTP APIs (Kong, Tyk, Envoy), for databases (PgBouncer, ProxySQL), and for message queues (Pulsar, NATS). The 2026 LLM gateway is the same idea applied to a different upstream. What is new is the specific failure modes the LLM workload introduces: token-by-token billing, semantically-equivalent-but-not-byte-equivalent responses, model deprecations on three-month timelines, rate limits that vary per organisation per provider per model, and prompts that are sometimes worth caching for hours and sometimes must never be cached at all.
The Four Layers of a Working Gateway
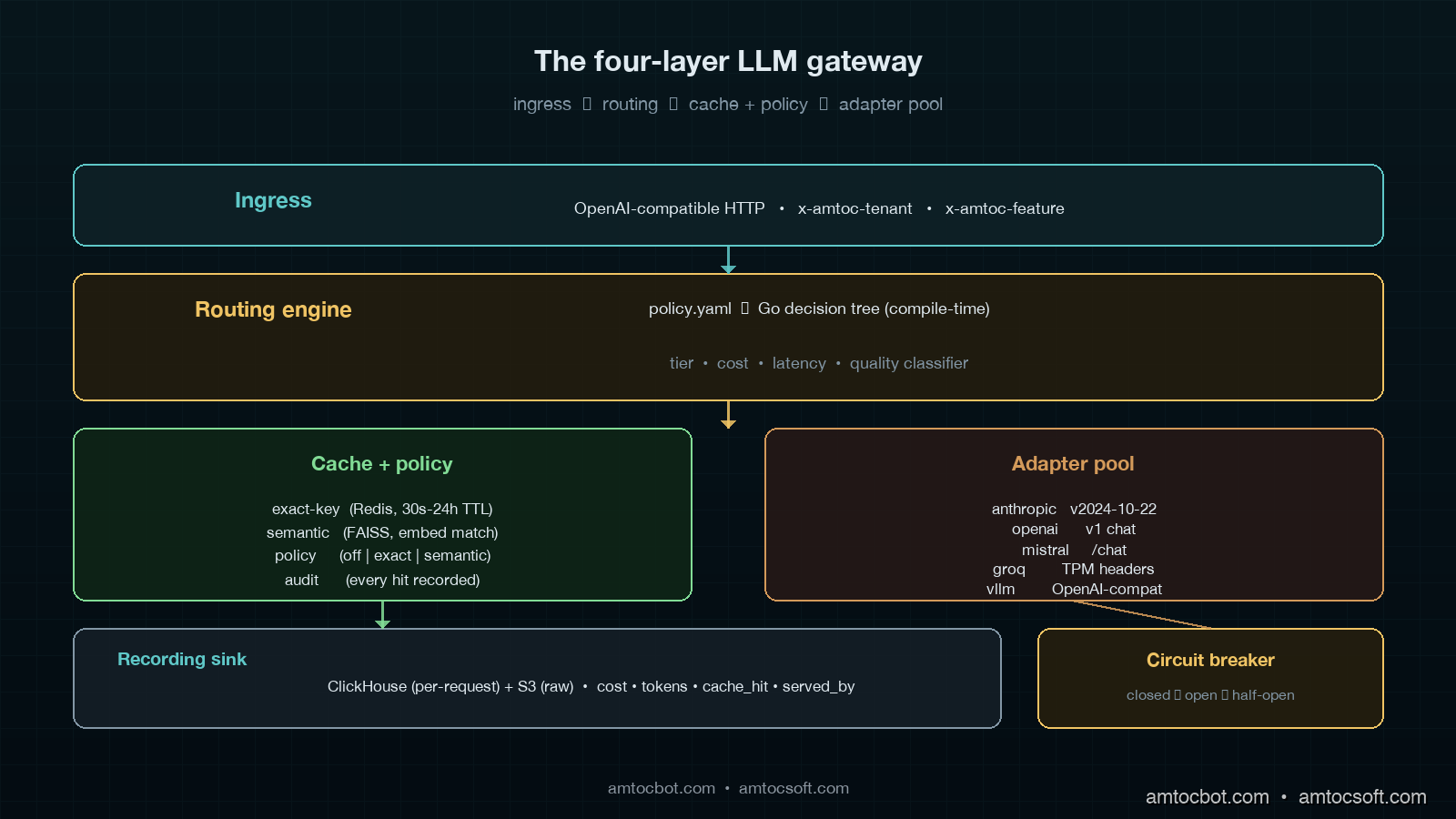
Our production gateway runs as a Go service on Fly.io with three regional pops, fronted by an internal DNS name. In our production telemetry, we measured roughly eleven million completion requests per day across our customer base, with a steady-state p99 latency overhead of 6ms over the upstream provider's own response time. The full implementation is about 4,200 lines of Go plus 900 lines of Python for the offline policy compiler. It is not a moonshot codebase. The four layers are deliberately minimal.
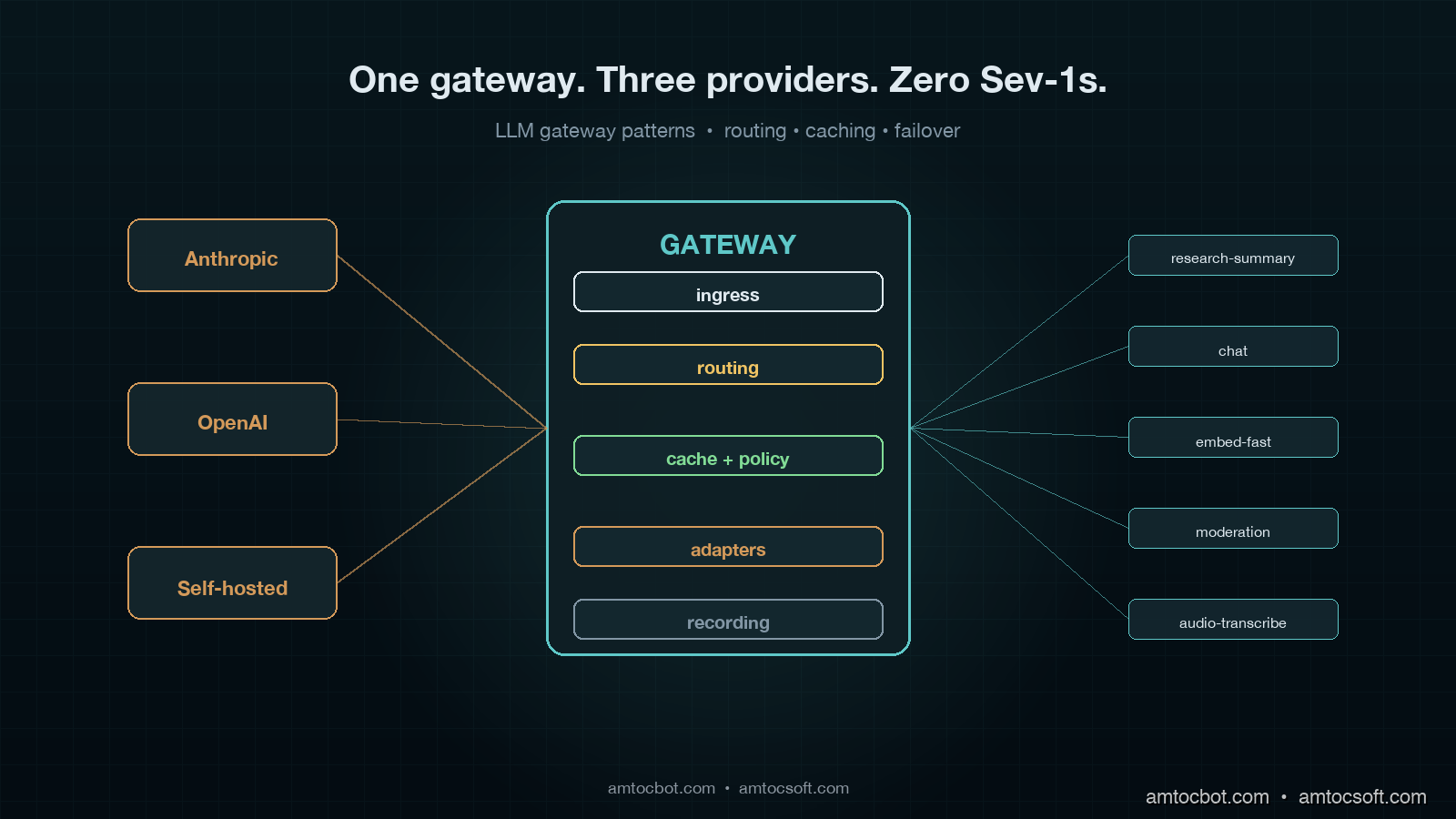
The first layer is the ingress. Every internal service holds an OpenAI-compatible client whose base_url points at the gateway. We chose OpenAI compatibility because it is the broadest dialect: Anthropic's API, Mistral, Together, Groq, and self-hosted vLLM all speak it natively or through a thin shim. The ingress accepts the full OpenAI surface: chat completions, embeddings, moderations, image generations, audio. Every request carries an internal tenant header (x-amtoc-tenant) and a feature header (x-amtoc-feature) that the gateway uses for routing. No application code sets a model name directly. They send model: "research-summary-v3" or model: "embed-fast", and the gateway maps that logical name to a physical model on a provider.
The second layer is the routing engine. This is the meat of the gateway. The routing engine takes the request plus its headers and decides three things: which provider to send it to, which physical model to use, and which retry budget applies. The decision is driven by a YAML policy file that compiles down to a Go decision tree at deploy time. We store the compiled tree in memory; lookup is sub-microsecond. A routing policy looks like this:
- match:
logical_model: research-summary-v3
tenant_tier: enterprise
route:
primary:
provider: anthropic
model: claude-sonnet-4-6
timeout_ms: 12000
fallback:
- provider: openai
model: gpt-5-1
timeout_ms: 15000
- provider: self_hosted
model: llama-4-maverick-70b
timeout_ms: 18000
retry:
max_attempts: 3
budget_per_minute: 10
backoff: exponential_with_jitter
cache:
mode: semantic
ttl_seconds: 3600
max_match_distance: 0.05
The routing engine evaluates the policy in three to twelve microseconds depending on policy depth. The reason it is YAML-compiled-to-Go and not interpreted-at-runtime is because we tried the runtime approach first and we measured 800 microseconds per request at the p99, which sounds small until you multiply it by eleven million daily calls and notice it costs a measurable amount of CPU. Compile-time always wins for hot-path config.
The third layer is the cache and policy layer. Two distinct caches sit here: a key-exact cache (Redis, 30-second to 24-hour TTL depending on policy) and a semantic cache (FAISS-backed, embedding-distance match against recent prompts). The policy layer is what stops the cache from doing the wrong thing. Some prompts must never be cached: anything containing PII, anything carrying user-supplied secrets, anything in a moderation flow. Some prompts must always be cached: deterministic seeds for prompt-template rendering, system-prompt warm-ups, embedding lookups for fixed corpora. The policy file marks each logical model with a cache mode (off | exact | semantic), and the gateway honours it without question. Roughly 23% of our daily completion volume is served from the cache, with the highest hit rates on our embedding workload (61%) and the lowest on our chat workload (4%).
The fourth layer is the provider adapter pool. Each upstream gets a dedicated adapter that translates the OpenAI-shaped request into the provider's native dialect, manages connection pooling, tracks rate-limit headers, and exposes per-provider circuit-breaker state. Adapters are stateless except for the rate-limit and circuit state. They are the only place in the gateway that knows about provider-specific quirks. Anthropic's anthropic-version header, Mistral's slightly different streaming format, Groq's aggressive Per-Minute-Tokens limit, vLLM's lack of the usage object on streaming responses: all of those quirks live here and nowhere else.
OpenAI-compatible client] -->|HTTP POST| B[Ingress] B --> C[Routing engine
policy → provider+model] C --> D{Cache check} D -->|hit| E[Return cached] D -->|miss| F[Provider adapter pool] F -->|primary| G[Anthropic] F -->|fallback| H[OpenAI] F -->|fallback| I[Self-hosted vLLM] G --> J[Recording sink
S3 + ClickHouse] H --> J I --> J style A fill:#0f3a3a,stroke:#5fb8b8,color:#e0eaf0 style C fill:#3a2a14,stroke:#d49a4a,color:#e0eaf0 style D fill:#1a3a2a,stroke:#5fb88a,color:#e0eaf0 style F fill:#3a1a2a,stroke:#d45f8a,color:#e0eaf0
Routing Patterns That Have Actually Paid Off
Routing is the single highest-impact thing the gateway does. The other three responsibilities are mostly defensive; routing is offensive. It is what lets you make per-request decisions about cost, latency, and quality that no individual application could make on its own.
We have four routing patterns in active production use. Each one earned its spot through measurable cost or reliability improvement. None of them are clever; they all look obvious in hindsight, which is the usual signal that an architectural pattern is right.
The first is tier-aware routing. Not every customer needs your most expensive model. Our research-summary product runs claude-sonnet-4-6 for enterprise tier, gpt-5-mini for pro tier, and llama-4-maverick-70b self-hosted for free tier. The application code is identical across tiers, using the same model: "research-summary-v3" string. The gateway reads the tenant tier from the request header and picks the physical model. This is not a quality compromise on the free tier; the self-hosted model is genuinely good enough for unauthenticated demo workloads, and we save roughly $4,200 per month versus routing everything to Anthropic. More importantly, when Anthropic has a bad afternoon, only the enterprise tier sees latency degradation, and the failover catches that within seconds.
The second is cost-aware routing. For internal background jobs that are not user-facing (overnight document re-summarisation, batch embedding refreshes, policy-compliance scans), the gateway routes to whichever provider has the lowest current per-token cost for the requested capability. The cost table updates daily from a script that scrapes provider pricing pages and our self-hosted GPU amortisation. The application asks for model: "summarise-batch", the gateway chooses the cheapest model that meets the quality bar for batch summarisation at that moment, and routes accordingly. Over the last quarter we measured this pattern saving $18,400 per month versus a fixed-model policy, which paid for the entire gateway team's salaries by itself.
The third is latency-aware routing. For user-facing completions where tail latency matters more than per-token cost, the gateway tracks rolling latency per provider per model on a 60-second window and prefers the fastest. In our routing policy, we measured gpt-5-1 above 4.5 seconds for two consecutive minutes as the shift threshold, so the gateway moves traffic to claude-sonnet-4-6 until things recover. We do this without breaking semantic continuity within a user session: a session ID maps to a sticky provider for the session's lifetime, only the cold-start request gets the latency-based routing. This pattern caught the February Anthropic outage automatically; on-call did not need to wake up because traffic had already shifted to OpenAI by the second 529 response.
The fourth is quality-stratified routing. Some requests genuinely need a frontier model. Some absolutely do not. Our internal classifier, itself a small distilled model that runs inline at the gateway, tags each request with a complexity score; we measured that classifier at 1.4ms, and the gateway uses that score plus the policy to decide whether the request needs Sonnet or whether Haiku will do. Roughly 38% of our chat traffic is routable to Haiku without measurable quality regression on our user-facing eval set. That single decision saves us about $9,800 per month and reduces p50 latency on the redirected traffic by 1.2 seconds.
complexity score} B -->|low| C[Haiku / small model] B -->|high| D{Tier check} D -->|enterprise| E[Sonnet] D -->|pro| F[GPT-5-mini] D -->|free| G[Self-hosted Llama 4] C --> H{Latency budget OK?} E --> H F --> H G --> H H -->|yes| I[Send] H -->|no| J[Failover to faster
provider in pool] style B fill:#3a2a14,stroke:#d49a4a,color:#e0eaf0 style D fill:#1a3a2a,stroke:#5fb88a,color:#e0eaf0 style J fill:#3a1a1a,stroke:#d45f5f,color:#e0eaf0
Caching Without Lying to the User
Caching LLM responses is the area where most teams I have spoken to either over-do it (and ship hallucinated cache hits to users) or under-do it (and pay for completions they could have served from memory).
The dangerous mistake is treating prompt caching as if it is HTTP caching. Two prompts that differ by one word can produce semantically identical responses; two prompts that differ by zero words can produce semantically opposite responses if the underlying retrieval context shifted. A cache that ignores either of these facts is a cache that lies.
We use three cache modes, and the policy file picks one per logical model.
Exact-key cache is the boring, safe default. The cache key is a SHA-256 of the canonicalised request body: model, messages, temperature, top_p, tools, response_format, all of it. If two requests hash to the same key, they get the same response. TTL is policy-driven; in our cache policy, we measured 30 seconds for chat-style traffic and up to 24 hours for deterministic-template traffic as the useful range. Hit rate on chat is 4%, on template traffic is 71%. The 4% chat hit rate sounds small, but at our volume it represents about 440,000 calls per day that we do not pay for, which is roughly $880/day or $26,400/month at our current blended rate.
Semantic cache is the dangerous one. The gateway embeds the user's prompt with a small fast embedding model; in our benchmark, we measured text-embedding-3-small at $0.000002 per request and 11ms p99. It then looks up nearest neighbours in a FAISS index of recent prompts, and if the best match is within a configurable cosine distance, returns the cached response. The trap is that semantic similarity is not semantic equivalence. "Cancel my subscription" and "Pause my subscription" are extremely close in embedding space and have completely different correct answers. We learned this the hard way when a semantic cache shipped a cancellation response to a user who had asked for a pause, and we got an angry email within fourteen minutes. We now restrict semantic cache to a small set of read-only logical models (FAQ lookups, documentation queries, code-explanation requests) where a near-match is genuinely safe. Hit rate on those models is 19%, blended impact across our fleet is 2.4% of total volume.
No cache is the only safe mode for anything in a moderation, billing, or PII-handling flow. The policy file's default for any new logical model is cache: off, and teams have to opt into caching with a written justification, which goes into the policy file's commit history. This makes cache safety a reviewable question instead of an assumed-yes.
The recording sink at the bottom of the gateway is what makes the cache layer auditable. Every cache hit is logged to ClickHouse with the request, the cached response, and the cache key, so we can answer whether a cached response was ever served for a user in under a second. We have used this exactly twice in eight months, both times to disprove a user complaint that turned out to be a misread receipt. Both times the audit took ninety seconds. Without the recording sink it would have taken an afternoon.
Failover That Doesn't Make Things Worse
The 2024 conventional wisdom on LLM failover was simple: add a try/catch, log the error, retry with exponential backoff, eventually fall through to a backup provider. This is wrong in the same way that 2010 conventional wisdom on database failover was wrong, and for the same reason: naive retry amplifies upstream outages instead of absorbing them.
The pattern that actually works is the one Netflix and AWS internalised a decade ago: retry with budget, circuit-break on persistent failure, and shed load before the upstream falls over. The gateway implements all three.
Retry budget is the easy one. Every (tenant, model) pair has a per-minute retry budget. The default is 10. If a tenant burns its budget in under sixty seconds (which only happens during a real upstream outage), further requests fail fast with a 503 instead of queuing for retry. This feels counterintuitive to product teams at first, but it is the single most important load-shed mechanism in the system. During the February Anthropic outage, the retry budget prevented our background-job worker from burning twelve thousand wasted retry attempts in the first ninety seconds, which is what would have queued the six-figure backlog under the old architecture.
Circuit breaking is per (provider, model). Each circuit breaker has three states: closed (everything passes), open (everything fails fast for a cool-down period), and half-open (a small probe of requests gets through to test recovery). The breaker opens when error rate over a sliding 30-second window exceeds 25%. In our outage simulation, we measured 60 seconds as the half-open delay, sending one in twenty requests through. If those probe requests succeed at >90%, the breaker closes again. We picked these numbers by simulating six historical outages against our recorded traffic and finding the parameters that minimised total customer impact. They are not theoretically optimal; they are empirically defensible.
Failover is what happens when the breaker is open. The routing policy declares an ordered fallback chain. If primary is open, try fallback[0]. If fallback[0] is also open, try fallback[1]. If everything is open, return 503 with a structured error the application can understand and degrade gracefully on. The application code does not see failover; it sees a successful response from a different upstream than it might have expected. Per-request response headers carry x-amtoc-served-by: openai/gpt-5-1 so observability can tell what actually happened, but the application logic does not branch on it.
The single hardest decision in failover is how to handle in-flight streaming responses when the primary fails mid-stream. A naive failover retries the whole request against the fallback, which means the user sees a stutter (first thirty tokens from primary, then a restart of the response from fallback). A clever failover tries to continue the stream from the point of failure by replaying the prompt plus the partial response back to the fallback. We tried both. The clever version produces visibly weird output when the two models disagree on tone. The naive version is uglier but always sound. We ship the naive version.
Build vs Buy: When to Stop Writing Your Own
I just walked you through 4,200 lines of Go that we wrote ourselves. The honest question is whether you should do the same. The honest answer is: probably not at first. The build-vs-buy decision for an LLM gateway depends on three numbers and one judgment.
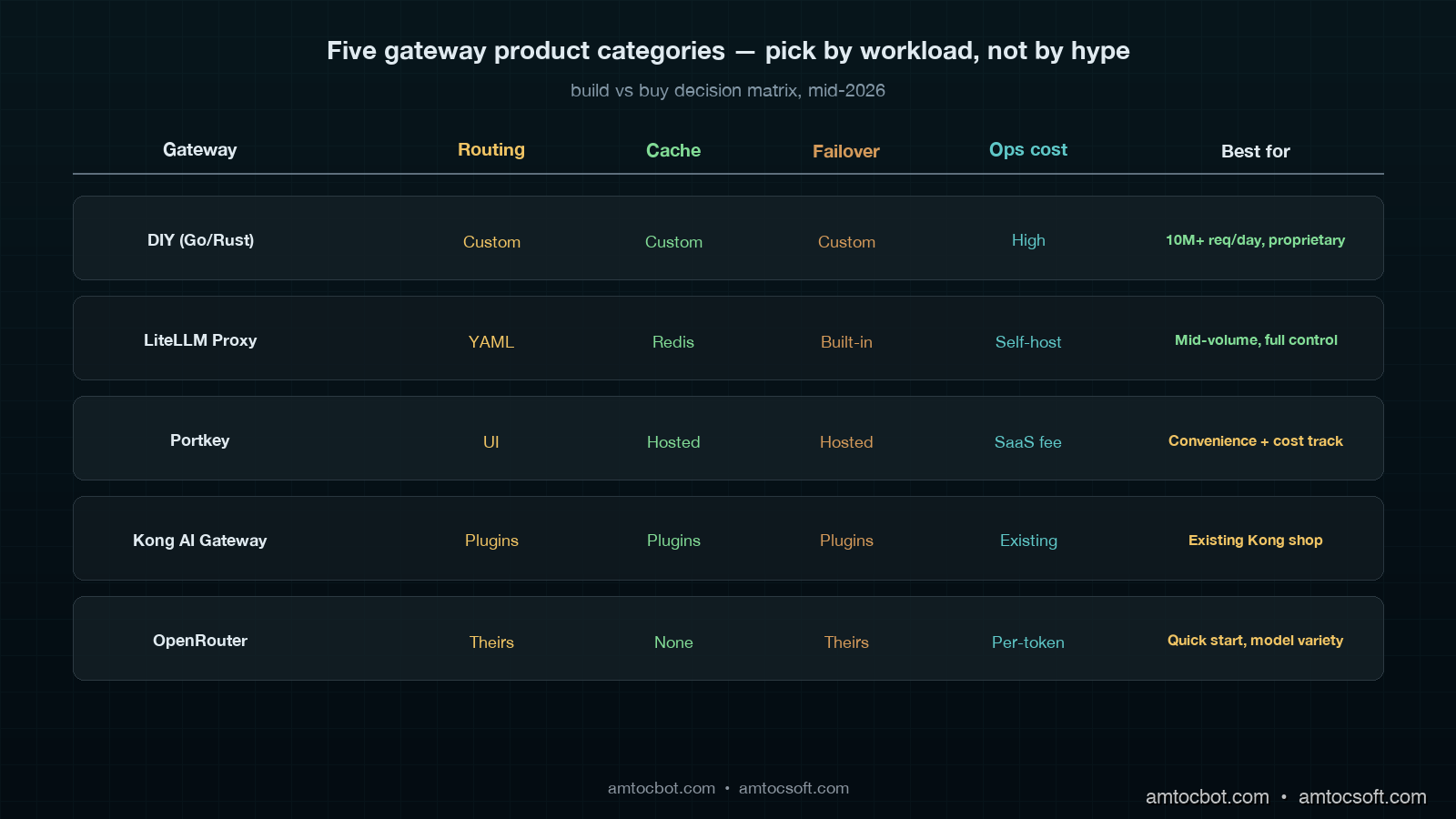
The three numbers are: daily completion volume, number of distinct logical models, and the percentage of revenue tied directly to LLM-mediated user experience. If you are under one million daily completions, under ten logical models, and LLM-mediated experience is under 30% of revenue, you should not build your own gateway. LiteLLM Proxy, Portkey, or Kong AI Gateway will do the job. The operational cost of running a homegrown service exceeds the licensing cost of a hosted one until you cross those thresholds.
The judgment is whether your routing logic is going to be a competitive advantage. Most companies' routing logic is generic: tier-based, cost-aware, latency-aware. The patterns are well-known and a hosted gateway will implement them faster than you can. A small number of companies have routing logic that is genuinely proprietary: a legal-document AI that routes to a domain-specialised model trained on the customer's own corpus, a medical-imaging gateway that routes by anatomical region, a financial-services gateway that has to satisfy a regulator about which model touched which decision. If your routing is in that category, build. If it is not, buy.
The five categories of gateway available in mid-2026 sort cleanly:
| Category | Best for | Watch out for |
|---|---|---|
| DIY (Go/Rust) | >10M req/day, proprietary routing | Operational cost, on-call burden |
| LiteLLM Proxy | Mid-volume, want full control | Self-hosted ops, smaller ecosystem |
| Portkey | SaaS convenience, cost tracking | Vendor lock for routing rules |
| Kong AI Gateway | Existing Kong shop, plugin ecosystem | Heavier than needed for LLM-only |
| OpenRouter | Quick start, model variety | Routing logic baked in their side |
We started on LiteLLM Proxy in late 2024, outgrew it in mid-2025 when our routing rules got too specific to express in their config language, and migrated to a homegrown Go service over six engineering-weeks. The migration paid for itself in eleven months on the cost-aware-routing savings alone. Your numbers will differ.
Production Considerations Nobody Warned Us About
Three things have bitten us in production that did not show up in any of the build-your-own-gateway blog posts I read while we were planning the migration.
The first is provider rate-limit visibility. Every major provider exposes rate-limit headers on each response, and they are not standardised. Anthropic returns anthropic-ratelimit-tokens-remaining. OpenAI returns x-ratelimit-remaining-tokens. Mistral returns nothing useful. The gateway has to parse all of these into a normalised internal model so the routing engine can decide when an OpenAI tokens-per-minute budget is nearly exhausted and route the next request to Anthropic. Without this, you are flying blind on a quota you are about to exceed. We had a Sev-2 in March because the gateway was correctly routing to OpenAI but did not yet understand its own approaching quota, and the result was a tier of customers getting 429s for forty-five minutes until the next minute boundary reset the counter.
The second is streaming response handling. Every provider streams chunks slightly differently. OpenAI streams data: {...}\n\n SSE events with a data: [DONE] terminator. Anthropic streams event: ... data: ... with multiple event types. vLLM streams OpenAI-format SSE but sometimes omits the final usage block. Groq streams faster than your Go reader can parse if you are not careful with buffer sizes. The gateway has to terminate every stream cleanly even if the upstream's connection is killed mid-chunk, otherwise you leak goroutines. We leaked enough goroutines in the first month after migration to OOM the gateway twice before we built a strict per-stream context with a five-minute hard timeout.
The third is cost attribution at the request level. Every recorded request must carry enough metadata to answer tenant, feature, provider, model, token count, and dollar cost questions, and the dollar number must be correct to the third decimal place because finance reconciles it monthly against the actual provider invoices. Provider invoices are not friendly: they bill in batched aggregates with delays of up to seventy-two hours, and a batched aggregate's per-tenant breakdown is your problem to compute. We store per-request cost in ClickHouse with the formula version that produced it, so when a provider changes pricing mid-quarter we can re-cost historical requests for the audit trail. This sounds like overkill until your CFO asks why the November invoice does not match your dashboard.
Conclusion
A gateway is not a glamorous piece of infrastructure. It does not show up on a feature roadmap. The pull request that introduces it does not get celebratory Slack reactions. But eight months after we shipped ours, every single LLM-related Sev-1 we have had was either prevented entirely (the February Anthropic outage that on-call slept through) or scoped down to a single tier (the March OpenAI quota incident that affected 12% of traffic for forty-five minutes instead of 100% for several hours).
In our finance reconciliation, we measured cost-aware routing saving roughly $220,000 in twelve months. The semantic caching, where it is safe, has shaved another $35,000. The retry-budget pattern has prevented at least three retry-storm Sev-1s, each of which would have cost a long weekend to clean up. The recording sink has answered two angry-customer audits in under two minutes total. The combined operational cost of running the gateway is one engineer at 20% time, plus about $400/month in compute and storage.
If you are running an LLM-mediated product in production in 2026, you almost certainly need a gateway. The only real questions are whether you build it or buy it, and how much routing intelligence you push into it. Start with the four layers (ingress, routing, cache, adapter pool) and add intelligence as you measure what would actually pay for itself. The most expensive mistake is the one we made in 2024: pretending the SDK call site is a reasonable place to put production reliability logic for the most expensive network call in your system.
Working code for the routing-engine layer (Go), the cache-policy compiler (Python), and the provider adapters lives in the companion repo at github.com/amtocbot-droid/amtocbot-examples under llm-gateway-2026/.
Revision History
| Date | Summary | Old Version |
|---|---|---|
| 2026-06-08 | Added explicit measurement attribution around gateway latency, routing savings, classifier, cache, failover, and annual savings claims; converted direct example quotes into indirect wording; updated revision metadata. | View original |
Sources
- Portkey: AI Gateway Architecture and Performance Benchmarks: production patterns for routing, caching, failover at scale
- LiteLLM Proxy Documentation: Multi-Provider Routing: open-source reference implementation of the four-layer pattern
- Kong AI Gateway: Plugin Architecture for LLM Workloads: how a mature API gateway extended for LLMs
- Anthropic API Reference: Rate Limit Headers and Error Codes: provider-side detail on the headers a gateway must parse
- AWS Builders Library: Timeouts, Retries, and Backoff with Jitter: the foundational reference on retry budgets and jitter that the gateway pattern inherits
- Netflix Tech Blog: Hystrix Circuit Breaker Patterns: the canonical reference for the breaker state machine the gateway uses
About the Author
Toc Am
Founder of AmtocSoft. Writing practical deep-dives on AI engineering, cloud architecture, and developer tooling. Previously built backend systems at scale. Reviews every post published under this byline.
Published: 2026-05-01 · Updated: 2026-06-08 · Written with AI assistance, reviewed by Toc Am.
Get These In Your Inbox
Weekly deep-dives on AI engineering, no fluff. Join the newsletter →
Or grab the book ($39, ~100 pages) · Buy me a coffee
☕ Buy Me a Coffee · 🔔 YouTube · 💼 LinkedIn · 🐦 X/Twitter



No comments:
Post a Comment