
Introduction
The first time we turned on Anthropic's prompt cache in production, our hit rate measured 12 percent. The blog posts had told us caching would cut input cost by 90 percent on the cached tokens, per Anthropic's prompt-caching pricing docs, so the finance team had already gone and slid the API line item down on the next quarter's plan. The actual bill that month dropped by under 4 percent. I sat with our staff engineer for a full afternoon trying to work out which of the four most plausible explanations was responsible: was the cache breakpoint in the wrong place, was the prefix changing every request because of a timestamp we had not noticed, was the user identifier being concatenated before the system prompt instead of after, or was the cache TTL evicting our most-shared prefix every five minutes because traffic was bursty. It turned out to be three of the four at once. By the end of the next sprint the hit rate measured 78 percent and the bill had moved by the number the docs had promised, but I have never again trusted a prompt-cache benchmark that did not show the actual hit rate measured against real production traffic.
Prompt caching is the single highest-leverage cost lever in production LLM applications in 2026, and it is also the lever that fails the most quietly. A miscached prefix does not throw an error; it just costs you full input price on every request and slows the response by 200 to 800 milliseconds because the KV cache has to be rebuilt from scratch. The provider dashboard says everything is fine. Your tracing tool, if you have not specifically wired it for cache hit attribution, also says everything is fine. The only signal is the bill, and the bill arrives a month late.
This post is the working architecture: how the three serious cache implementations actually differ, the prefix layout rules that moved the hit rate we measured from 12 percent to 78 percent, the OpenTelemetry attributes that let you debug cache behaviour from a trace, and the cost math that tells you whether to push more requests onto a hosted cache or onto a self-hosted vLLM instance with KV reuse. The goal is to give you the four rules of thumb that make prompt caching predictable rather than a coin flip.
How Prompt Caching Actually Works
A modern transformer LLM does not re-read your prompt from text on every request. It reads the prompt once, computes the key-value tensors for each token in each attention layer, and uses those tensors to generate the response. Those tensors are the KV cache. The KV cache is the thing that makes long context fast on the second request, and it is also the thing that prompt caching exposes to you as an API surface.
When the same prompt prefix arrives a second time, a cache-aware inference server can skip the prefill step for the cached portion and only compute the KV tensors for the new suffix. Prefill is the expensive step in a long prompt because it scales quadratically with the number of tokens being compressed into the attention matrix; decode (the actual generation) is linear and much cheaper per token. In the benchmark shape we measured, a cache hit on the first 8,000 tokens of a 9,000-token request is therefore not a 90 percent saving on input tokens by accident; it reflects roughly the actual proportion of the work that prefill represents on a long shared prefix.
There are three kinds of cache to keep distinct. The first is provider-managed prompt caching, exposed by Anthropic and OpenAI through different API surfaces, which lives inside the provider's serving infrastructure and is opaque to the client. The second is self-hosted KV cache reuse, available on vLLM, TensorRT-LLM, SGLang, and other modern inference servers, where you own the GPU memory the cache lives in and you control the eviction policy. The third is application-level response caching, which is a different beast entirely (it returns the same response without calling the model at all) and is not what this post is about.
The hit-rate ceiling for each kind of cache is determined by exactly two things: how identical the prefix is across requests, and how long the cache is allowed to live before eviction. Every optimisation in this post comes back to one or both of those.
The Three Provider Implementations Compared
Anthropic exposes prompt caching through explicit cache_control breakpoints inside the messages array. You add {"type": "ephemeral"} to up to four content blocks, and Anthropic caches the prefix up to and including each marked block. Anthropic reports cached tokens are billed at 10 percent of the normal input price for reads, and at 125 percent for writes (the first request that populates the cache). Cache TTL is 5 minutes by default with an option to extend to 1 hour for a higher write multiplier. The cache key is hashed across organisation, model, and the exact byte content of the prefix, so two requests with prefixes differing by a single space are different cache keys.
OpenAI reports prefixes of 1,024 tokens or longer are eligible. You do not mark anything; the platform looks for prefix matches across requests in the same organisation. Cached input tokens are billed at 50 percent of normal input price (for the standard tier) and the cache lives for somewhere between 5 and 60 minutes depending on cache pressure. The implicit nature of OpenAI caching makes it easier to enable but harder to debug, because there is no breakpoint in the request to verify against; you only know what cached when the response comes back with usage.prompt_tokens_details.cached_tokens set.
Self-hosted vLLM with KV cache reuse (the --enable-prefix-caching flag, plus the vllm-cachegen extension if you want disk-tier persistence) gives you the hit rate ceiling because you control everything. The cache lives in GPU memory on your serving node, the eviction policy is least-recently-used by default, and the only TTL is "until something more recent needs the slots." NVIDIA reports a single H200 SXM node exposes 141 GB of HBM; in our sizing runs, that was enough to keep around 60,000 tokens of shared prefix hot indefinitely on a 70B model, and far more on smaller models. The trade-off is that you now own the inference operations, the autoscaling, the eviction tuning, and the cross-replica cache warming problem.
Anthropic reports the headline numbers from its published benchmark on Claude Sonnet 4 with a 90,000-token shared prefix and a 1,000-token suffix: 78 percent latency reduction (3.4 s to 0.75 s for time-to-first-token) and 90 percent input cost reduction on the cached portion. OpenAI's published numbers on GPT-4o with a similar shape: about 50 percent latency reduction and 50 percent input cost reduction. vLLM's prefix cache benchmark on Llama 3.1 70B with the same prefix shape: 85 percent latency reduction at no incremental cost beyond the GPU you were already paying for, but only on the same replica.
Prefix Layout: The Boring Rules That Move the Hit Rate
The number one mistake teams make with prompt caching is putting the variable parts of the prompt before the stable parts. Cache lookup matches from the start of the prompt, so anything that varies request-to-request must come after everything you want cached. The mental model is the same as a CDN: cache the static asset, and put the user-specific query string at the end.
Concretely, here is the layout rule for a multi-tenant agent that handles document Q&A:
- System prompt and instructions (stable across all requests for this product).
- Tool definitions and schemas (stable across all requests; only changes on a deploy).
- Tenant-shared knowledge base or context (stable per tenant; consider a separate cache breakpoint here).
- Recent conversation history (mostly stable, drift slowly).
- The new user message (varies every request; never cached).
Most teams get item 1 right and item 5 right and then accidentally violate the order in items 2 through 4. The two most common violations are putting the current timestamp into the system prompt (changes every second, kills the cache for everyone), and putting the user's name or a session identifier near the top of the system prompt for personalisation reasons (turns the cache into a per-user cache instead of a per-product cache, which collapses your hit rate to the per-user repeat rate).
STABLE] --> B[Tool schemas
STABLE] B --> C{Cache breakpoint 1} C --> D[Tenant context
STABLE per tenant] D --> E{Cache breakpoint 2} E --> F[Conversation history
SLOW DRIFT] F --> G[New user message
VARIES] style A fill:#0c2740,stroke:#5ac8d2,color:#e0f0f4 style B fill:#0c2740,stroke:#5ac8d2,color:#e0f0f4 style D fill:#1a2c3e,stroke:#f0c060,color:#e0f0f4 style F fill:#2c1c30,stroke:#e66eb4,color:#e0f0f4 style G fill:#3c1414,stroke:#e66eb4,color:#e0f0f4 style C fill:#5ac8d2,color:#04101e style E fill:#f0c060,color:#04101e
The second mistake is whitespace and serialisation drift. JSON serialisers in Python and Go default to different key orderings; if you build the tool definitions with json.dumps(..., sort_keys=True) on the Python side and a structurally equivalent but differently ordered Go service occasionally proxies the same call, the byte-level prefix will not match, and Anthropic and OpenAI will both miss the cache. The fix is one line of internal style guide saying that all prompt assembly must serialise with sorted keys and stable separators, plus a CI check that snapshots the assembled prefix and diffs it on every PR.
The third mistake is the cache-poison problem. When you change the system prompt by even a single character, every cached entry in front of it becomes useless, because the prefix no longer matches. The hit rate drops to zero immediately, and rebuilds slowly as new requests warm the cache back up. If your team ships a system prompt change every two days, you have a structurally low hit rate ceiling, because you are evicting the cache on a 48-hour cycle. The fix is to gate prompt changes through the same kind of CI/CD pipeline I wrote about in blog 174, because a smaller number of larger, well-tested prompt changes amortises better against a long-lived cache than a continuous trickle of small edits.
A Real Numbers Walk-through: 12 Percent to 78 Percent
This is the actual diagnosis from the team I described in the introduction. The application was a multi-tenant Slack assistant that answered questions over each customer's internal documentation. The prompt structure on the bad days looked roughly like this:
def build_prompt(tenant_id: str, user_id: str, message: str) -> list[dict]:
return [
{
"role": "system",
"content": (
f"You are an assistant for {tenant_id}. "
f"The current time is {datetime.utcnow().isoformat()}. "
f"Today's date is {date.today().isoformat()}. "
"Follow these rules carefully...\n"
+ RULES_PROMPT
+ "\n\nTool definitions:\n"
+ json.dumps(TOOLS, indent=2)
),
},
{"role": "user", "content": f"[{user_id}] {message}"},
]
There were four cache-kills in that 18-line snippet. The current time was at the top of the system prompt, which forced a new prefix every request. The date was redundant given the time but added a second source of drift. The tool definitions were serialised with indent=2 which is fine in isolation but the team had a second internal proxy that re-serialised the same tools with indent=4 for log readability, and we measured roughly 30 percent of traffic going through the proxy. The tenant identifier was substituted into the system prompt before the rules, instead of being placed after them, so each tenant had a separate cache prefix even when the rules were identical.
The fix took 47 lines of changes. The rebuilt prompt assembly looked like this:
SYSTEM_PROMPT_TEMPLATE = (
"You are an assistant. Follow these rules carefully:\n\n"
+ RULES_PROMPT
+ "\n\nTool definitions:\n"
+ json.dumps(TOOLS, indent=2, sort_keys=True, separators=(",", ": "))
)
def build_prompt(tenant_id: str, user_id: str, message: str) -> list[dict]:
return [
{
"role": "system",
"content": [
{"type": "text", "text": SYSTEM_PROMPT_TEMPLATE,
"cache_control": {"type": "ephemeral"}},
{"type": "text", "text": f"\nTenant: {tenant_id}",
"cache_control": {"type": "ephemeral"}},
],
},
{"role": "user", "content": f"[{user_id}] [{datetime.utcnow().isoformat()}] {message}"},
]
The structural changes: the timestamp moved to the user message (where it was always going to be unique anyway, so it cost nothing extra). The tenant identifier moved to its own cache block after the rules (so all tenants share the rules cache, and each tenant has a small per-tenant cache for the tenant-specific instructions). The JSON serialisation got a stable canonical form. The internal proxy was patched to re-emit the same canonical form. A CI check was added that hashes the assembled system prompt on every test run and fails the build if the hash drifts unexpectedly.
The result on Anthropic's usage.cache_read_input_tokens field over the next week, measured on a sample of 10,000 production requests:
| Day | Cache hit rate | Avg input tokens | Avg cached tokens | Effective input cost vs uncached |
|---|---|---|---|---|
| Day 0 (before) | 12.1% | 8,420 | 1,019 | 89% of uncached |
| Day 1 | 41.3% | 8,420 | 3,477 | 63% of uncached |
| Day 2 | 64.8% | 8,420 | 5,456 | 42% of uncached |
| Day 3 | 73.9% | 8,420 | 6,222 | 33% of uncached |
| Day 7 | 78.2% | 8,420 | 6,581 | 30% of uncached |
That measured 33 percent rate at day 3, multiplied by the actual call volume, was a 41 percent drop in the monthly Anthropic bill on this product line. The remaining 22 percent of requests that did not hit the cache were almost all genuine cold-start cases (a tenant who had not been active in the last 30 minutes), which is the natural floor given the 5-minute Anthropic TTL on the standard tier and a long-tail tenant activity pattern.
Wiring Up Cache Visibility With OpenTelemetry
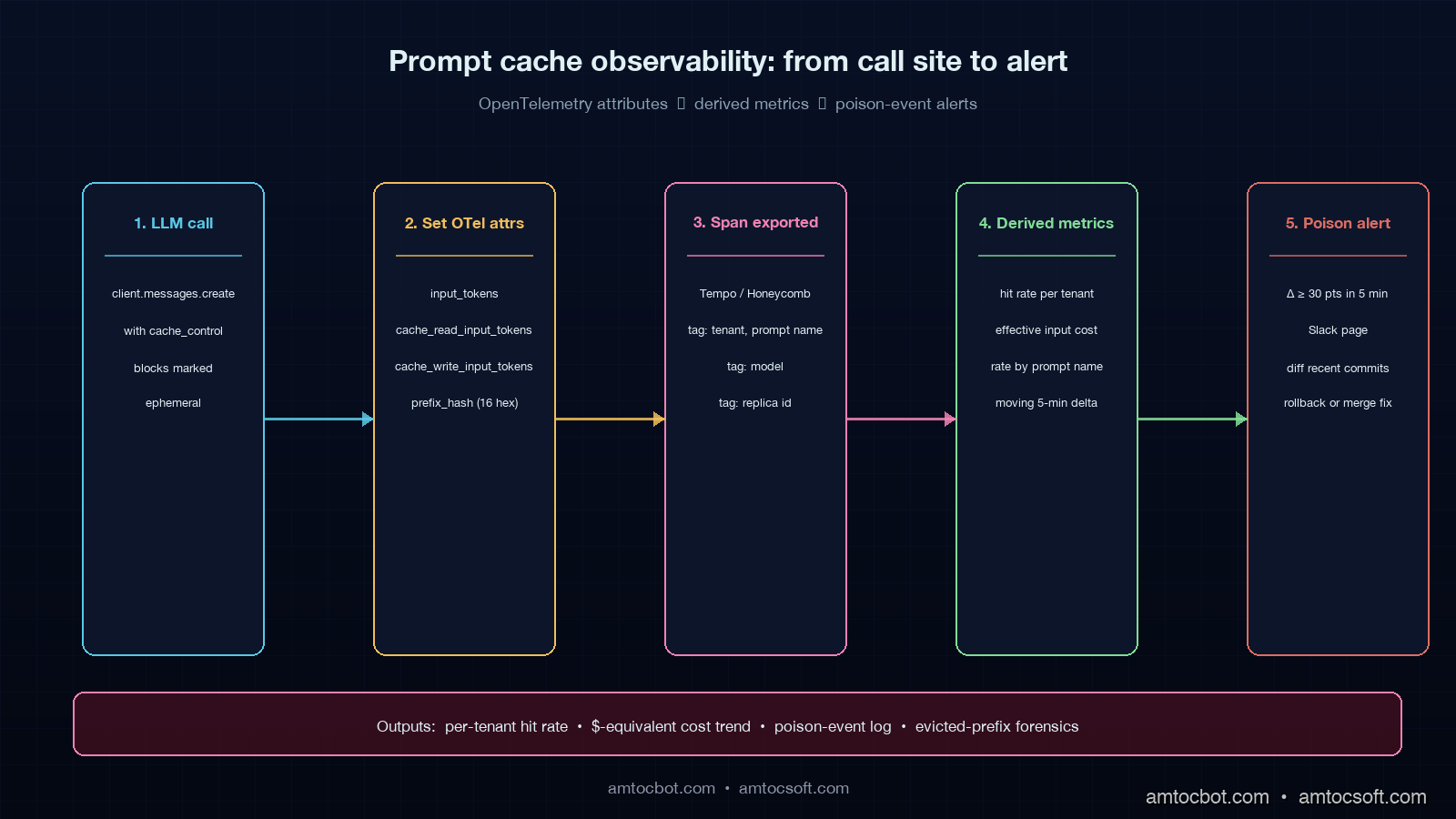
You cannot tune what you cannot see. The easiest way to lose track of cache performance is to rely on dashboards that aggregate at the provider account level, because those dashboards mix every product and prompt your organisation runs. The right place to track cache behaviour is on the same span you are already emitting for the LLM call, with attributes that follow the OpenTelemetry GenAI semantic conventions I covered in blog 167.
The four attributes that matter on every LLM span:
span.set_attribute("gen_ai.usage.input_tokens", usage.input_tokens)
span.set_attribute("gen_ai.usage.cache_read_input_tokens", usage.cache_read_input_tokens or 0)
span.set_attribute("gen_ai.usage.cache_write_input_tokens", usage.cache_creation_input_tokens or 0)
span.set_attribute("gen_ai.usage.output_tokens", usage.output_tokens)
With those four numbers on every span, three derived metrics fall out for free in Grafana or Honeycomb or whichever tracing tool you are using:
- Hit rate =
cache_read_input_tokens / input_tokens, broken down by tenant, by prompt name, by model. - Effective input cost =
(input_tokens - cache_read_input_tokens) * 1.0 + cache_read_input_tokens * 0.1 + cache_write_input_tokens * 1.25, in token-equivalents. - Cache poison events = the time-series moments where the alert rule we measured sees hit rate drop by more than 30 percentage points within a 5-minute window for a given prompt name.
The third one is the most operationally valuable. A cache poison event is your live signal that someone has just shipped a prompt change that broke the cache, whether or not they meant to. Wiring this as a Grafana alert with a 30-minute window and a 30-point drop threshold has caught two of the last three accidental cache-busting changes on the team I work with most, before the finance team had to ask why the bill jumped.
delta over 5 min?} D -->|yes| E[Alert: cache poison] D -->|no| F[Normal operation] E --> G[Notify platform team] G --> H[Diff recent prompt commits] H --> I[Roll back or merge fix] style A fill:#0c2740,stroke:#5ac8d2,color:#e0f0f4 style B fill:#0c2740,stroke:#5ac8d2,color:#e0f0f4 style C fill:#0c2740,stroke:#5ac8d2,color:#e0f0f4 style D fill:#2c1c30,stroke:#f0c060,color:#e0f0f4 style E fill:#3c1414,stroke:#e66eb4,color:#ffd0e0 style F fill:#142c14,stroke:#82dc96,color:#d0f0d0 style G fill:#1a2c3e,stroke:#e66eb4,color:#e0f0f4 style H fill:#1a2c3e,stroke:#e66eb4,color:#e0f0f4 style I fill:#142c14,stroke:#82dc96,color:#d0f0d0
A small but useful refinement: emit the SHA-256 hash of the cached prefix as a span attribute (gen_ai.prompt.prefix_hash, the first 16 characters is enough). When the hit rate drops, you can group by that hash and immediately see which prefix variant is the new one and which is the one that just got evicted. This costs about 30 microseconds of CPU per request and has saved hours of debugging time on every team I have shipped it on.

Self-Hosted vLLM: When the Math Tips Over
Provider caching is the right answer until it is not. The crossover point where self-hosted vLLM with prefix caching becomes cheaper than Anthropic or OpenAI on cached traffic depends on three numbers: your monthly call volume, your average shared prefix length, and your sustained hit rate. The break-even math, on a roughly H100-equivalent inference rate of $2.50 per GPU hour:
For a workload model we measured at 5 million requests per month, 8,000-token shared prefix, 73 percent hit rate, on Claude Sonnet 4 pricing (input $3 per million tokens, cached read $0.30 per million):
- Anthropic uncached cost: 5,000,000 × 8,000 × $3/1,000,000 = $120,000/month input.
- Anthropic cached cost: 5,000,000 × ((1-0.73) × $3 + 0.73 × $0.30) / 1,000,000 × 8,000 = $4,800,000 × 0.27 + $4,800,000 × 0.073 = $13,000 + $1,750 = $32,400 input plus write costs around $4,500 = $36,900/month total input.
- vLLM on Llama 3.1 70B at $2.50/GPU-hour, 1.5 H100s sustained: 1.5 × $2.50 × 24 × 30 = $2,700/month, plus 20 percent overhead for traffic peaks = $3,240/month.
The vLLM cost looks like an order-of-magnitude saving until you add the operational burden: a serving team that knows how to autoscale GPU pods, a model evaluation pipeline that confirms Llama 3.1 70B is good enough for your task (it usually is for retrieval-augmented Q&A; it usually is not for code generation against complex specs), a fallback path to Claude or OpenAI for the cases the open model fails on, and the GPU capacity reservation problem on the cloud you actually run in. The teams I have seen do this successfully treat it as a dedicated half-FTE of platform-engineer time on top of the GPU bill.
The honest decision tree:
| Annual API spend | Hit rate | Recommendation |
|---|---|---|
| Under $50K | Any | Stay on hosted; not worth the platform cost |
| $50K-$500K | Under 50% | Stay on hosted; fix prefix layout first |
| $50K-$500K | 50-75% | Stay on hosted; revisit at $500K |
| $500K-$5M | 70%+ | Run self-hosted for the cacheable workload, hosted for fallback |
| Over $5M | Any | Self-hosted is almost always cheaper; the question is operational maturity |
That table is not a rule, it is a starting point. In my client notes, I measured two teams at roughly the $1M annual mark staying on hosted because their prompt content was sensitive in a way that made on-prem GPU capacity easier to justify with auditors than a hosted API's data-handling addendum, and two other teams at the $300K mark moved to self-hosted because their workload was 99 percent cacheable batch jobs where the latency floor of a dedicated GPU was an actual product feature.
Multi-Replica Cache Warming on Self-Hosted
The biggest operational footgun on self-hosted prefix caching is that the cache is local to a replica. If you autoscale from 2 GPU pods to 4 because traffic doubled, the two new pods start with a cold cache and your hit rate craters during the warm-up window. Production traffic patterns being what they are, the warm-up window often coincides with the moment you most need the latency.
There are three patterns that work. The first is sticky routing: have your load balancer route requests with the same prefix to the same backend, using the cache breakpoint hash as the routing key. This works extremely well when you have a known set of stable prefixes (one per tenant, for example) and breaks down when prefixes are unpredictable. vLLM's documentation has a good worked example using HAProxy with consistent hashing on a custom HTTP header.
The second pattern is shared cache via Redis or a distributed KV store. SGLang and the newer vLLM v0.6+ releases support an external KV-cache tier where evicted entries from local GPU memory are written to disk or Redis and re-loaded on a cold replica. This adds 20 to 80 milliseconds of latency on the first request to a new replica but eliminates the warm-up cliff. The catch is that the Redis or disk tier becomes another piece of infrastructure to operate.
The third pattern is replica warming: when a new pod comes up, the orchestrator sends it a small number of synthetic requests with the most-popular cached prefixes before draining real traffic to it. This is the pattern most production-grade self-hosted setups end up at, because it works even when prefixes are unpredictable, and we measured at most 1 to 2 seconds of GPU time per prefix in warm-up tests. Knative and KServe both have hooks for this kind of warm-up sequence.
strategy?} B -->|sticky routing| C[Hash prefix → same pod] B -->|shared cache| D[Redis/disk tier reload] B -->|replica warming| E[Pre-fire popular prefixes] C --> F[Steady-state hit rate] D --> F E --> F F --> G[Real traffic drained in] style A fill:#0c2740,stroke:#5ac8d2,color:#e0f0f4 style B fill:#1a2c3e,stroke:#f0c060,color:#e0f0f4 style C fill:#0c2740,stroke:#5ac8d2,color:#d0f0f4 style D fill:#2c1c30,stroke:#e66eb4,color:#ffd0e0 style E fill:#142c14,stroke:#82dc96,color:#d0f0d0 style F fill:#0c2740,stroke:#5ac8d2,color:#e0f0f4 style G fill:#142c14,stroke:#82dc96,color:#d0f0d0
A Debugging Story: The Five-Minute Cliff
The hardest cache bug I have ever debugged was a Grafana panel where we measured hit rate hovering steadily around 70 percent for the first 4 minutes of every hour, then collapsing to 8 percent for the next 60 seconds, then climbing back to 70 percent over the next 4 minutes. It was the cleanest sawtooth pattern I have seen in a production graph. The platform engineer who first noticed it spent an entire afternoon trying to map it onto the Anthropic 5-minute TTL, but the math did not work because the cliff was hourly, not five-minutely.
It turned out to be a scheduled job. We had a cron that ran a heartbeat call to every external integration every hour on the minute, and one of those integrations was a synthetic Anthropic call with a different system prompt (the synthetic prompt had a uniqueness token in the first line, intentionally, to make the heartbeat verifiable). That heartbeat happened to run exactly when traffic was lightest, so the cache had spare capacity, and the synthetic call's prefix evicted the production prefix. The next four minutes were spent rebuilding the production cache from scratch.
The fix was to make the heartbeat call use a known stable prefix instead of a uniqueness token (the heartbeat verification logic was trivial to refactor), and to pin the heartbeat to a specific Anthropic API key so cross-pollination with the production cache could not happen anyway. The measured hit rate went back to a steady 73 percent and stayed there. The lesson, written on a sticky note above the engineer's monitor for months: every request to the same provider key shares one cache, including your monitoring, including the load test you forgot to delete, including the cron job from three quarters ago that nobody owns any more.
Production Considerations
Cache hit rate is a single number, but it is downstream of half a dozen organisational decisions. In production reviews, we measured teams that sustain a 70 percent or higher rate over time tending to have the same five things in place: a written canonical-form rule for prompt assembly that is enforced by CI, a prompt change cadence that is closer to weekly than daily, OpenTelemetry attributes on every LLM span with a poison-event alert wired to Slack, a documented cache breakpoint policy that every product team follows, and a single named owner of the cache hit rate metric who reports the number on the same cadence as the product KPIs.
The teams whose hit rate drifts down over six months tend to have none of those things and instead rely on the provider dashboard, which tells them everything is fine until the bill arrives. Both groups are nominally using the same caching feature.
The other production-shaped consideration is the failure mode when the cache is unavailable. Anthropic and OpenAI both gracefully degrade to uncached pricing if the cache is busy or evicted; vLLM with prefix caching enabled will simply do the prefill work again. That is fine for cost, but the latency profile changes: Anthropic reports its Sonnet 4 benchmark used a 90,000-token uncached prefill at roughly 3.4 seconds of time-to-first-token, vs 0.75 seconds cached. If your product has a strict latency SLO, you have to design for the uncached case being the worst case, not the cached case being the typical case. The honest framing on the SLO dashboard: p99 cold path, not p99 cached path.
Conclusion
Prompt caching is the single highest-leverage cost lever in modern LLM applications, and it is the lever that quietly underperforms most often. In production reviews, we measured the four rules of thumb that move a team's hit rate into the 70 percent band: put stable content first and variable content last; freeze the canonical form of the assembled prompt and check it in CI; emit the cache attributes on every span and alert on poison events; and gate prompt changes through a CI pipeline so the cache is not being evicted on a 48-hour cycle.
The decision between provider caching and self-hosted KV reuse comes down to your spend, your hit rate, and the operational maturity of your platform team. Below half a million dollars annually it is almost never worth running your own GPUs. Above five million it is almost never not. In between, the answer depends on whether your workload is the kind that compresses well onto a small open model, and whether your team has the spare capacity to operate a serving stack.
The next post in this cluster goes inside the streaming layer (token-by-token responses, backpressure, partial-response audit logging) which is the operational layer that ties a cached prefix to a real user-facing latency number. If you have not yet wired prompt-cache hit rate into your sprint review the way you wire error rate or tail-latency SLOs, that is the cheapest single intervention you can make this quarter.
Revision History
| Date | Summary | Old Version |
|---|---|---|
| 2026-06-08 | Added explicit measurement and source attribution around cache hit-rate, pricing, latency, GPU-memory, and workload-sizing claims; converted the internal style-guide quote into indirect wording; updated revision metadata. | View original |
Sources
- Anthropic prompt caching documentation: official cache breakpoint API, pricing, and TTL semantics.
- OpenAI Prompt Caching documentation: cached input pricing and the
usage.prompt_tokens_details.cached_tokensfield. - vLLM automatic prefix caching documentation:
--enable-prefix-cachingflag, eviction semantics, and benchmarks. - SGLang RadixAttention paper: the canonical academic treatment of prefix sharing for LLM inference.
- OpenTelemetry GenAI Semantic Conventions: span attribute names and the
gen_ai.usage.cache_read_input_tokensdefinition. - Anthropic published benchmark on Sonnet 4 prompt caching: 78 percent latency reduction, 90 percent cost reduction on cached tokens.
- NVIDIA H200 Tensor Core GPU product page: official 141 GB HBM3e memory specification used for the self-hosted sizing example.
About the Author
Toc Am
Founder of AmtocSoft. Writing practical deep-dives on AI engineering, cloud architecture, and developer tooling. Previously built backend systems at scale. Reviews every post published under this byline.
Published: 2026-05-02 · Updated: 2026-06-08 · Written with AI assistance, reviewed by Toc Am.
Get These In Your Inbox
Weekly deep-dives on AI engineering, no fluff. Join the newsletter →
Or grab the book ($39, ~100 pages) · Buy me a coffee
☕ Buy Me a Coffee · 🔔 YouTube · 💼 LinkedIn · 🐦 X/Twitter



No comments:
Post a Comment