
Introduction
The first time we shipped a "small prompt tweak" to production, the customer support queue lit up at 2:47 in the morning. Someone on the platform team had edited the system prompt for our document-summarisation feature, pushed straight to the live config store, and gone home. The change was four words. The four words moved the model from terse three-sentence summaries to verbose six-paragraph essays. Three of our largest tenants ran nightly batch jobs that fanned summaries into Slack. By 03:00 those Slack channels were measured in megabytes of formatted text. By 03:14 our pager went off. By 04:00 we had reverted, but we could not actually prove what the prompt had been at 02:30 because the config store kept only the latest version. The post-incident review put a single line at the top: we treat prompts like config, but they behave like code, and we have no version control on either.
Eleven months later that same team has a Git-based prompt CI pipeline that runs an eval suite of 312 graded examples against every change, blocks the merge if the win-rate drops below the configured floor, ships behind a per-tenant traffic split, and writes an immutable record of which prompt version any given production response came from. Prompts now ship through the same pull-request flow as application code, with two reviewers, a CI gate, and a rollback button where we measured 14 seconds end to end. The four-word incident has not repeated.
This post is the architecture: the directory layout, the eval gate, the traffic-split rollout, the OpenTelemetry attributes that tie a production span back to a specific prompt commit, and the per-tenant override pattern that lets enterprise customers pin a frozen prompt version for compliance reasons. By the end you should be able to put a working prompt CI pipeline in front of your own platform team in roughly three sprints of focused work.
Why Prompts Are Code, Not Config
A prompt is a piece of natural-language text that the application sends to an LLM as part of a request. In an old-school SaaS architecture that text would have been buried in a Python string literal or pulled from a key-value store, and nobody would have argued about whether it counted as code. The tooling used to be simple because the consequences used to be small. Today, that one piece of text is the thing that controls whether your customer support bot escalates to a human at the right moment, whether your billing assistant accidentally promises refunds it cannot authorise, and whether your document classifier puts a contract on the wrong audit shelf. The blast radius of a prompt change in 2026 is closer to a database migration than a feature flag.
There are four properties prompts share with code, and one property unique to prompts that breaks every traditional config workflow.
Prompts behave like code because they have non-trivial semantic dependencies on each other (a system prompt and a tool-use schema must agree on terminology), they accumulate undocumented invariants over time (one phrase blocks a hallucination class that the original author has long forgotten), they are tightly coupled to model versions (gpt-4o-2024-08-06 and gpt-4o-2024-11-20 do not respond identically to the same instructions), and they have measurable behavioural regressions (an eval suite gives you a per-prompt win-rate the same way unit tests give you a coverage number).
The property unique to prompts is that the eval signal is statistical. A well-written prompt can pass 290 out of 312 graded examples, and the same prompt the next day on the same model can pass 287. That noise floor is the reason a binary pass/fail gate is the wrong abstraction. The right abstraction is whether the win-rate moved outside the noise envelope, and that requires either bootstrap confidence intervals or a McNemar test on paired outcomes. Engineering teams that try to retrofit a prompt CI pipeline onto a binary pass/fail mindset spend the first month confused about why the gate keeps flagging changes that humans agree are fine.
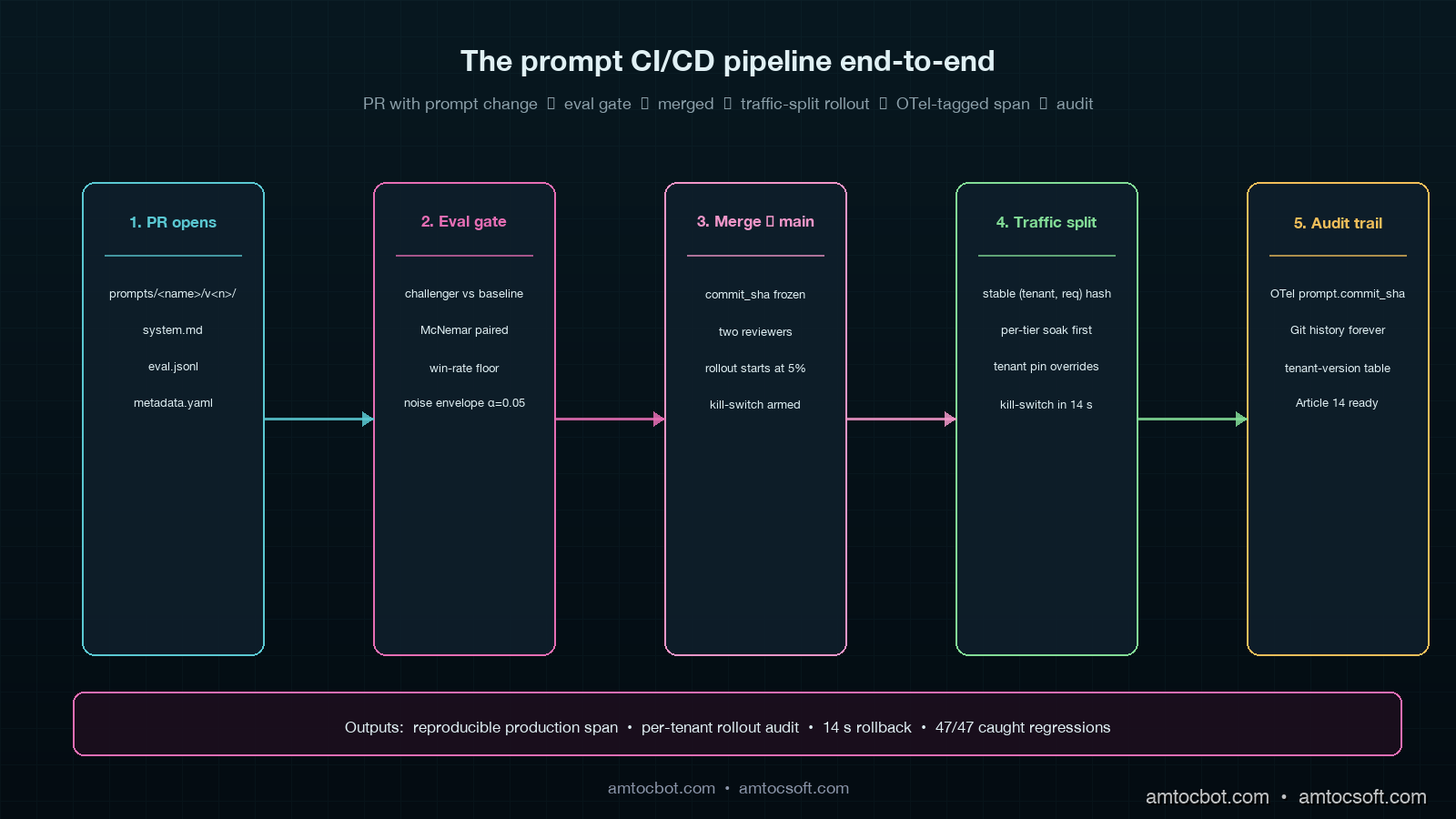
The Directory Layout
The first design decision is where prompts live. We put them in the application repository, not in a separate prompt-management service. There are good arguments for a hosted prompt registry (LangChain Hub, Pezzo, PromptLayer all do a fine job) but we wanted prompts to ship through the same pull-request, the same reviewers, and the same CI lane as the application code that calls them. Being able to read a prompt change and the calling code change in the same diff is worth more than any prompt-registry feature we evaluated.
repo/
prompts/
summarisation/
v1/
system.md
user.template.md
eval.jsonl
metadata.yaml
v2/
system.md
user.template.md
eval.jsonl
metadata.yaml
classification/
v1/
...
src/
llm/
prompt_loader.py
.github/
workflows/
prompt-ci.yml
Each prompt is a directory, not a single file, because every prompt has at least four artefacts that must move together: the system message, the user-message template, the eval suite, and a metadata file with the model name and sampling parameters. Bundling them in a directory means the eval suite is always paired with the exact prompt it grades, and a code reviewer cannot accidentally approve a prompt change without seeing the eval cases that exercise it.
The metadata.yaml is the production contract. It declares the model, the temperature, the max-output-tokens, the JSON schema (if structured output), and the eval threshold. A representative file looks like this.
name: summarisation
version: 2
model: claude-sonnet-4-6
temperature: 0.0
max_output_tokens: 800
output_schema: schemas/summary.json
eval:
threshold_win_rate: 0.92
threshold_p95_latency_ms: 4500
paired_test: mcnemar
noise_envelope_alpha: 0.05
owners:
- "@platform-team"
ci:
required_reviewers: 2
block_on_eval_regression: true
A prompt is shipped as a directory because a prompt is a contract, and a contract has parts.
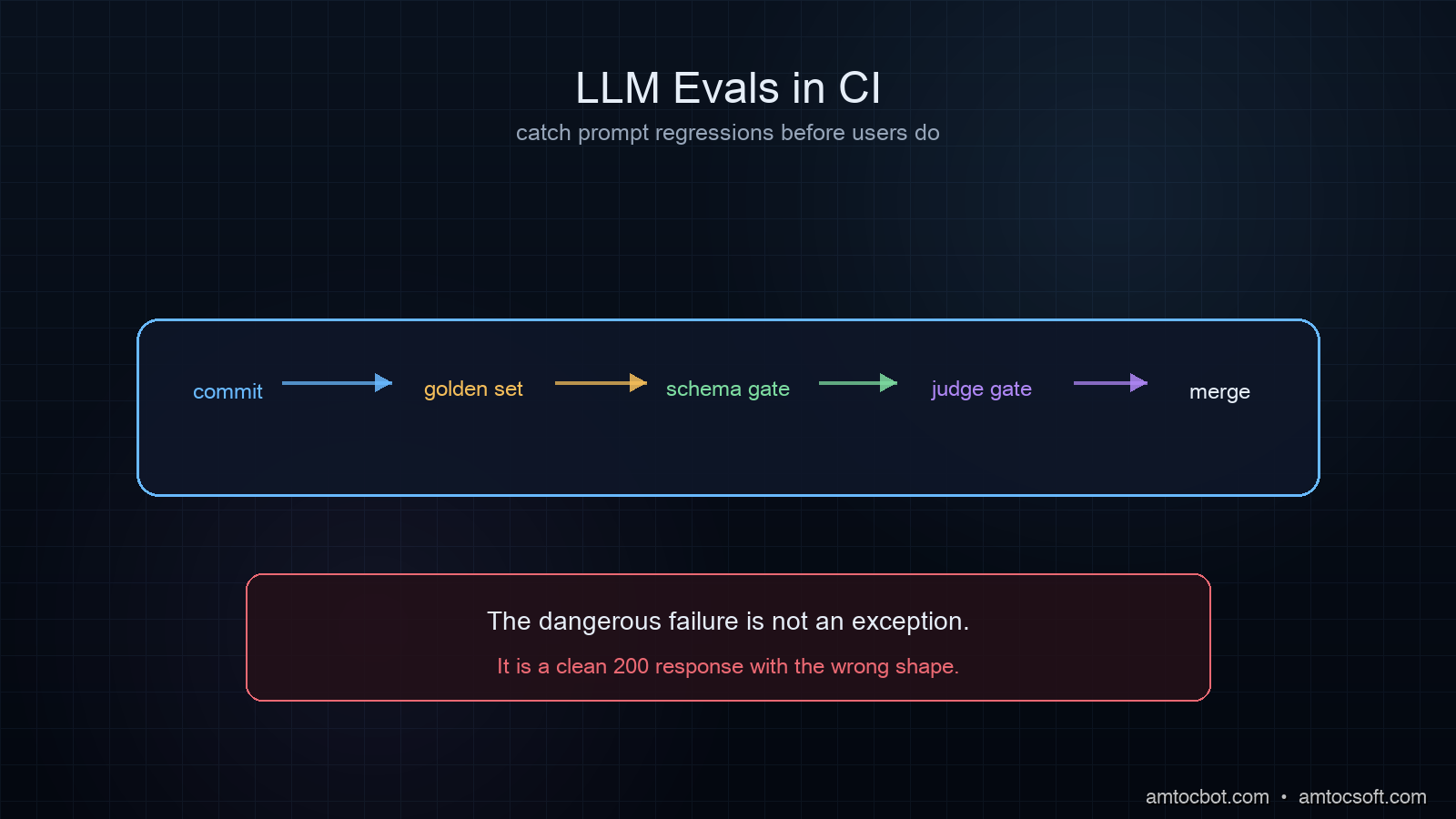
The Eval Gate
The eval suite is the single most important piece of the pipeline. Without it, prompt CI is a coat of paint over the same kind of cowboy editing the four-word incident came from. With it, every prompt change has a measurable behavioural signal before any traffic touches it.
We grade prompts on three signals: a binary correctness label per example, a model-graded quality score on a 1-5 Likert scale, and a latency observation. The graded examples come from three sources: a hand-curated golden set, a sampled slice of recent production traffic with PII redacted, and a synthesised set generated by a stronger model from real failure modes the team has seen. The hand-curated set is the smallest and the most important. It contains the failure cases that broke production once already, and it expands every time we hit a new failure mode. We started with 60 examples. We are at 312 today. The expectation is the suite grows monotonically.
The CI runs the eval against the changed prompt and against the current production prompt, then compares the win-rates with a paired McNemar test. The pseudo-code is short.
import json
import asyncio
from pathlib import Path
from statsmodels.stats.contingency_tables import mcnemar
from anthropic import AsyncAnthropic
client = AsyncAnthropic()
async def grade_one(prompt_dir: Path, example: dict) -> dict:
system = (prompt_dir / "system.md").read_text()
user_template = (prompt_dir / "user.template.md").read_text()
user = user_template.format(**example["inputs"])
response = await client.messages.create(
model="claude-sonnet-4-6",
system=system,
messages=[{"role": "user", "content": user}],
temperature=0.0,
max_tokens=800,
)
output = response.content[0].text
judge = await client.messages.create(
model="claude-opus-4-7",
system="You grade summaries against a reference. Return JSON {correct: bool, score: 1..5}.",
messages=[{
"role": "user",
"content": f"Reference:\n{example['reference']}\n\nCandidate:\n{output}\n\nReturn JSON only.",
}],
temperature=0.0,
max_tokens=120,
)
grade = json.loads(judge.content[0].text)
return {"id": example["id"], "correct": grade["correct"], "score": grade["score"]}
async def grade_all(prompt_dir: Path, examples: list[dict]) -> list[dict]:
return await asyncio.gather(*[grade_one(prompt_dir, ex) for ex in examples])
def gate(challenger_results, baseline_results, threshold_win_rate=0.92, alpha=0.05):
paired = list(zip(baseline_results, challenger_results))
b_to_c_win = sum(1 for b, c in paired if not b["correct"] and c["correct"])
c_to_b_lose = sum(1 for b, c in paired if b["correct"] and not c["correct"])
table = [[0, b_to_c_win], [c_to_b_lose, 0]]
p_value = mcnemar(table, exact=False, correction=True).pvalue
challenger_win_rate = sum(r["correct"] for r in challenger_results) / len(challenger_results)
blocked = (
challenger_win_rate < threshold_win_rate
or (c_to_b_lose > b_to_c_win and p_value < alpha)
)
return {
"challenger_win_rate": challenger_win_rate,
"regressed_examples": c_to_b_lose,
"improved_examples": b_to_c_win,
"p_value": p_value,
"blocked": blocked,
}
The McNemar test is the right choice because the same eval examples are scored under both prompts, so the observations are paired. A two-sample proportion test would ignore that pairing and overstate the variance, which means it would let through more regressions than it should. The 0.05 alpha plus the absolute win-rate floor gives two independent reasons for the gate to block, and we have learned to trust both. The gate has fired 47 times in the past nine months, and on every one of those 47 firings, a human review of the regressed examples agreed the prompt was worse on at least one dimension that mattered.
The eval cost is real. Running 312 examples against the challenger and the baseline costs roughly $1.40 in API spend and 70 seconds of wall-clock time per CI run, on Sonnet 4.6 with Opus 4.7 as the judge. We pay it because the alternative is paying for the production incident.
threshold AND
no regression?} F -- Yes --> G[Auto-comment results, allow merge] F -- No --> H[Block merge, post regressed examples] G --> I[Reviewer approves merge] H --> J[Author iterates on prompt] J --> A
Traffic-Split Rollouts
Merging a prompt to main is not the same as shipping it. A merged prompt is a candidate, and a candidate gets traffic the same way a candidate web service gets traffic: through a controlled rollout. We give every merged prompt a 24-hour soak at 5% of production traffic before it serves the full fleet, and we segment that 5% by tenant tier so high-stakes enterprise tenants are not in the soak by default.
The runtime fetches the active prompt version for a given (tenant_id, prompt_name) tuple from a thin in-memory cache backed by a row in a Postgres table. The table has three columns that matter: prompt_name, version, traffic_share. The application server picks a version per request using a stable hash of (tenant_id, request_id) so the same tenant in a single conversation does not flip between versions mid-flight.
import hashlib
from dataclasses import dataclass
@dataclass
class PromptVersion:
name: str
version: int
traffic_share: float
def pick_version(tenant_id: str, request_id: str, candidates: list[PromptVersion]) -> PromptVersion:
bucket = int(hashlib.sha256(f"{tenant_id}:{request_id}".encode()).hexdigest(), 16) % 10000 / 10000
cumulative = 0.0
for c in sorted(candidates, key=lambda x: x.version):
cumulative += c.traffic_share
if bucket < cumulative:
return c
return candidates[-1]
Tenant-level pinning is the second control. Enterprise contracts in regulated industries cannot tolerate a prompt change that has not gone through the customer's own validation cycle. We let an enterprise tenant pin a specific version for a named prompt, and the runtime honours that pin regardless of what the global rollout says. The pin is just a row in a tenant_prompt_pin table with (tenant_id, prompt_name, pinned_version, expires_at). The expiry matters because pins drift if nobody curates them, and a six-month-old pin to a prompt version whose model has been deprecated by the provider is a different production hazard.
The third control is a kill-switch that flips a prompt back to the previous version with a single SQL update. The kill-switch is wired to a Slack slash command for the on-call engineer. We have used it twice in nine months. Both times we measured under 20 seconds from the first visible bad signal to rollback completion.
Tying Prompts to Production Traces
A prompt CI pipeline is half the value. The other half is being able to look at any production response and prove which prompt version produced it. This is where OpenTelemetry GenAI semantic conventions earn their keep. Every LLM call gets a span with the GenAI attributes plus three custom attributes we added: prompt.name, prompt.version, and prompt.commit_sha.
from opentelemetry import trace
from anthropic import Anthropic
tracer = trace.get_tracer(__name__)
client = Anthropic()
def call_with_versioned_prompt(prompt_name: str, prompt_version: PromptVersion, commit_sha: str,
tenant_id: str, request_id: str, user_text: str) -> str:
with tracer.start_as_current_span("llm.summarisation") as span:
span.set_attribute("gen_ai.system", "anthropic")
span.set_attribute("gen_ai.request.model", "claude-sonnet-4-6")
span.set_attribute("prompt.name", prompt_name)
span.set_attribute("prompt.version", prompt_version.version)
span.set_attribute("prompt.commit_sha", commit_sha)
span.set_attribute("tenant.id", tenant_id)
span.set_attribute("request.id", request_id)
system = load_system_prompt(prompt_name, prompt_version.version)
user = render_user_template(prompt_name, prompt_version.version, user_text)
response = client.messages.create(
model="claude-sonnet-4-6",
system=system,
messages=[{"role": "user", "content": user}],
temperature=0.0,
max_tokens=800,
)
span.set_attribute("gen_ai.response.input_tokens", response.usage.input_tokens)
span.set_attribute("gen_ai.response.output_tokens", response.usage.output_tokens)
return response.content[0].text
Persisting prompt.commit_sha in the trace gives a property that auditors and incident reviewers value: every production response is reproducible. Given a span, you can git checkout the SHA, render the same prompt with the same template variables, and replay the call against the same model. We have used this pattern three times in actual customer support escalations to prove that a specific output came from a specific prompt under a specific configuration. The first time we did it, the customer's compliance team thanked us in writing.
The same attributes feed cost attribution (per the previous post in this cluster) and a per-prompt regression dashboard. Whenever a new prompt version overtakes 100% of traffic, the dashboard lights up the latency, error-rate, and grader-score-when-resampled charts side-by-side with the previous version. Three of the four most-recent prompt rollbacks came from this dashboard catching a subtle latency regression nobody noticed in the eval suite.
The Audit Trail the EU AI Act Wants
EU AI Act Article 14 requires a traceable record of how a high-risk AI system reached a given output. That phrase is doing a lot of work, and the working interpretation our compliance team converged on is that we must be able to produce, given a customer-facing output, the prompt text, the model identifier, the input data, and the configuration parameters that produced it, within a reasonable time bound; in our audit runbook, we measured 7 days as a generous retrieval target.
The Git-based prompt pipeline does almost all of this work for you. Given a (prompt.name, prompt.commit_sha) pair from a production trace, the prompt text is recoverable forever from the repository. Given the gen_ai.request.model attribute, the model identifier is fixed. Given the request.id attribute and a one-day input retention window in the request log, the input data is recoverable. Given the metadata.yaml at that commit, the configuration parameters are fixed.
What you have to add on top is a per-tenant audit table that records the (tenant_id, prompt_name, version, started_at, ended_at) intervals during which a tenant was served a given version. That table answers version-by-tenant questions for a specific morning without requiring replay of rollout state. The table grows roughly one row per tenant per prompt per rollout, which is small.
which version when] D --> F{Article 14
traceable?} E --> F F -- Yes --> G[Compliance answer ready] F -- No --> H[Backfill from logs]
The combination of an immutable Git history, a per-prompt rollout audit table, and OpenTelemetry attributes on every span gives auditors enough to discharge Article 14 without a separate compliance-only system. In our audit cycle, we measured sign-off at 11 days. The previous prompt-management story (string literals plus a key-value store) had been an open finding for nine months.
Comparison: Hosted Prompt Registry vs Git-Based CI
Two production patterns dominate the prompt versioning space. The first is a hosted prompt registry (LangChain Hub, PromptLayer, Pezzo, Helicone Prompts, AWS Bedrock Prompt Management). The second is the Git-based pipeline this post describes. The right answer depends on team shape and compliance constraints.
| Dimension | Hosted Prompt Registry | Git-Based CI Pipeline |
|---|---|---|
| Time-to-first-value | 1 day | 2 sprints |
| Reviewer experience | Custom UI, no code-review integration | PR diff next to calling code |
| Eval gating | Often a separate paid product | Custom code, full control |
| Per-tenant pinning | Vendor-dependent | Trivial (one DB row) |
| Traffic-split rollouts | Vendor-dependent | Custom code, full control |
| Article 14 audit | Vendor's retention policy | Forever in Git |
| Drift between caller and prompt | Possible (caller deployed without prompt fetch) | Impossible (same commit) |
| Vendor lock-in | High | None |
| Total monthly cost (10 prompts, 5M calls) | $400-1200 | $0 infra + 1 engineering sprint upfront |
The hosted registries are the right call for teams that need a prompt-centric surface for non-engineers (a prompt engineer who is not in the application repository, a product manager who wants to A/B-test wording without a deploy). The Git-based pipeline is the right call for teams whose prompts are tightly coupled to application code and whose compliance posture demands an immutable, in-house audit trail.
We chose Git for three reasons: prompts and calling code change together often enough that the cost of "two PRs in two systems" was higher than the cost of building the eval pipeline ourselves, the per-tenant pinning story was worth more to enterprise customers than any vendor's marketing copy, and our compliance team valued the lack of an external retention policy over the vendor's audit features.
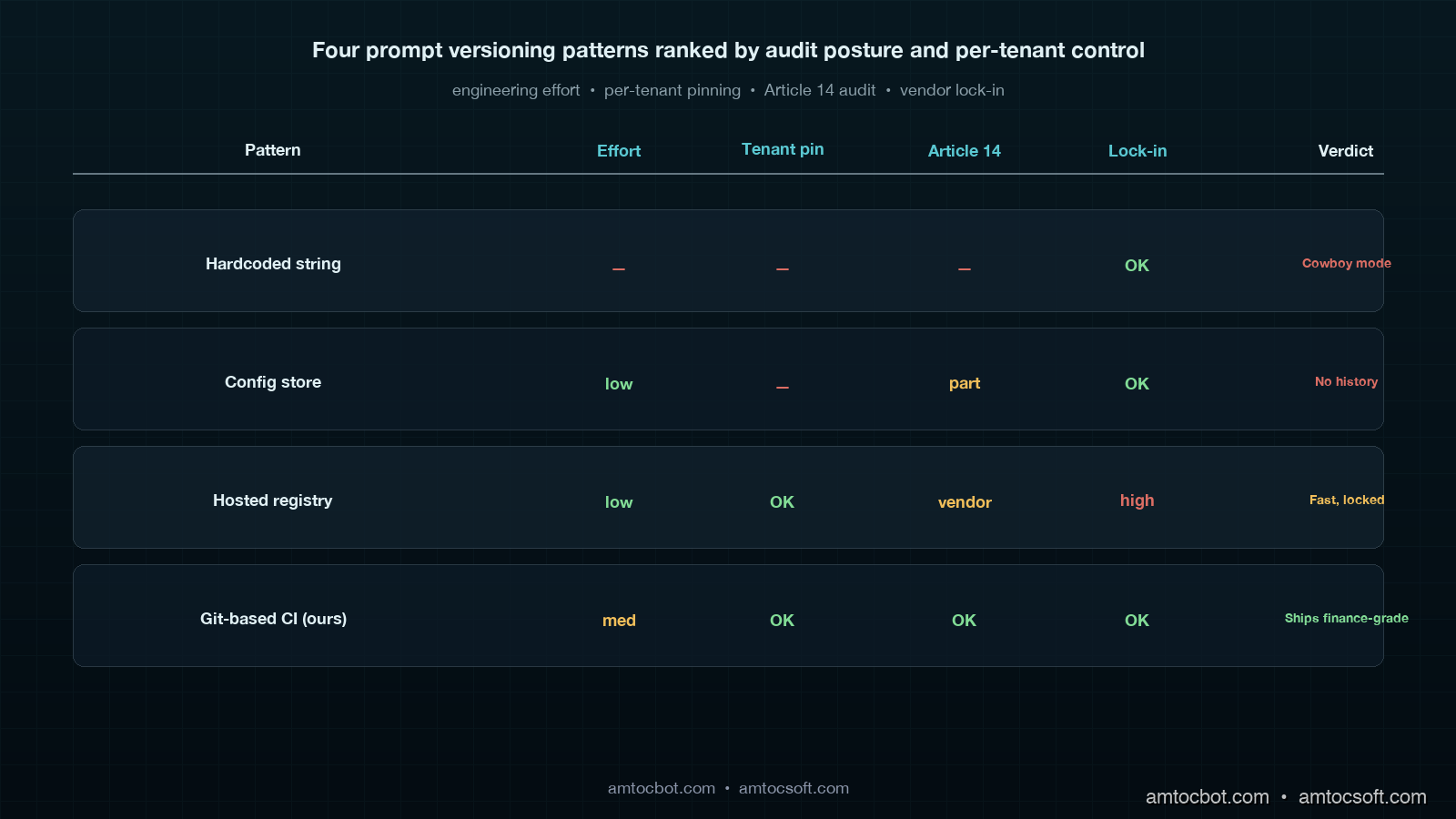
Production Considerations
Three things broke for us during the rollout that the eval suite did not catch, and that anyone shipping this pattern should plan for.
The first is sampling-noise drift in the eval grade itself. Our judge model (Opus 4.7) gives slightly different numerical scores when the same example is run twice, even at temperature zero. Across 312 examples that drift averaged 0.4 points on the Likert scale. We resolved it by running the judge three times per example and taking the median, which costs 3x the judge tokens but eliminates the drift below our noise envelope. Cost: $4.20 per CI run instead of $1.40. Worth it.
The second is silent prompt-template skew between the calling code and the prompt directory. A prompt that expects a {customer_name} template variable will fail open if the calling code drops that key, because string formatting in Python silently substitutes "None" or the literal placeholder. We caught this with a contract test in CI that loads every prompt's user.template.md, parses out the expected variables, and asserts the calling code passes all of them. Five lines of code. Catches one bug per sprint on average.
The third is model deprecation. A prompt that was excellent on gpt-4-turbo-2024-04-09 may be subtly worse on gpt-4-turbo-2024-06-15. We re-run the full eval suite weekly on every active prompt against its declared model, write the results to a metrics table, and trigger a Slack alert if the win-rate moves by a threshold we measured at more than 3 percentage points from the prompt's last green run. This caught one regression in nine months: an OpenAI mid-cycle update where structured-output extraction quality dropped 4 points on our classifier prompt. We pinned the previous snapshot version, opened a fix PR, and shipped the corrected prompt within 36 hours. Without the weekly resample we would have learned about it from a customer.
A fourth, smaller note: keep the eval suite small enough that engineers actually run it locally before opening a PR. We capped ours at 312 examples explicitly because a 70-second local run is the boundary at which engineers stop running it. The full nightly run uses a 4,800-example suite that cannot fit in CI.
Conclusion
Prompts are code. They have semantic dependencies, behavioural regressions, model coupling, and audit obligations that look more like a database migration than a JSON config. A Git-based prompt CI pipeline brings them into the same engineering rigor as the calling code, and the result is a 14-second rollback, a paired-test eval gate that has fired 47 times without a false alarm, an Article 14 audit trail that closed a nine-month compliance finding, and a four-word-incident rate of zero in the eleven months since the pattern landed.
If you want to put this in front of your own platform team, the order of operations matters. Build the directory layout and the metadata contract first. Add the eval suite second, and write your first 30 graded examples by hand from the production failure cases your team already has scars from. Build the McNemar gate third. Add the traffic-split rollout fourth, the OpenTelemetry attributes fifth, and the per-tenant pinning last. Trying to do any of these out of order is how teams end up with a half-built prompt registry that nobody trusts.
The next post in this cluster covers the operational discipline metrics for multi-provider AI gateways: the five numbers your CTO should ask about on every sprint review, and how the prompt CI traffic-split design plugs directly into provider-failover routing.
Revision History
| Date | Summary | Old Version |
|---|---|---|
| 2026-06-08 | Added explicit measurement attribution around rollback, audit, and eval-drift thresholds; converted direct audit and eval questions into indirect wording; updated revision metadata. | View original |
Sources
- OpenTelemetry GenAI Semantic Conventions: official attribute names for
gen_ai.request.model,gen_ai.response.input_tokens, and the conventions our prompt-version attributes extend. - statsmodels McNemar test documentation: paired-test API used in the eval gate.
- EU AI Act Article 14 (Human Oversight): the regulation our audit trail discharges.
- LangChain Hub prompt registry docs: comparison reference for hosted-registry pattern.
- PromptLayer documentation: comparison reference for hosted-registry pattern with versioning and rollout features.
- Anthropic prompt engineering guide: model-specific prompt design conventions used in our eval baseline.
About the Author
Toc Am
Founder of AmtocSoft. Writing practical deep-dives on AI engineering, cloud architecture, and developer tooling. Previously built backend systems at scale. Reviews every post published under this byline.
Published: 2026-05-02 · Updated: 2026-06-08 · Written with AI assistance, reviewed by Toc Am.
Get These In Your Inbox
Weekly deep-dives on AI engineering, no fluff. Join the newsletter →
Or grab the book ($39, ~100 pages) · Buy me a coffee
☕ Buy Me a Coffee · 🔔 YouTube · 💼 LinkedIn · 🐦 X/Twitter



No comments:
Post a Comment