
Introduction
The postmortem that taught me how to write ADLC postmortems was the one that produced nothing. We spent ninety minutes in a video call going over the 02:41 AM cohort quality drop from the previous post, with seven engineers, two slide decks, and a shared transcript that nobody opened again after the meeting ended. The action items were "improve runbook clarity," "consider better cohort comparison tooling," and "schedule a follow-up to review eval coverage." Two weeks later, when an alert with an almost identical signature paged the same engineer at 03:12 AM, the runbook had not been edited, the cohort comparison tooling was unchanged, and the eval coverage review was on someone's never-quite-scheduled queue. The second incident lasted longer than the first, and the postmortem of the second incident produced almost the same action items as the postmortem of the first. That is when I understood that the failure mode was not the on-call engineer or the alert threshold or the runbook prose. The failure mode was the postmortem itself.
A postmortem that does not close the loop is theatre. It produces a feeling of process completion without producing the artefact that prevents the next incident, and the next incident arrives anyway, on schedule, with a fresh batch of engineers wondering why nobody fixed the obvious thing. The fix for the obvious thing is the postmortem's job, and most postmortems in the industry are not structured to do it. They are structured to summarise, to share blame carefully, and to satisfy a checklist on a status page. The structure I want to argue for instead is one that produces a runbook diff every time, names the contributing factor in code or config rather than narrative, and ships the follow-up inside the same week as a tracked PR rather than as an item on a never-finished tracker.
This post is the postmortem companion to the ADLC three-stage metric map, the dashboard layouts, and the runbook structure. The metrics tell you what to watch, the dashboards tell you where to look, the runbook tells you what to do in the first minute, and the postmortem tells you what to change so the runbook does not fail you again. Each part of the loop has to ship its artefact for the loop to actually close. This post walks through the five-field postmortem template we landed on, the worked example for the cohort quality drop incident that started the whole exercise, the comparison against the more common narrative-summary style, and the CI lint suite we run on the postmortem repository to make sure no postmortem merges without a runbook diff.
The Problem: Postmortems That Produce Nothing
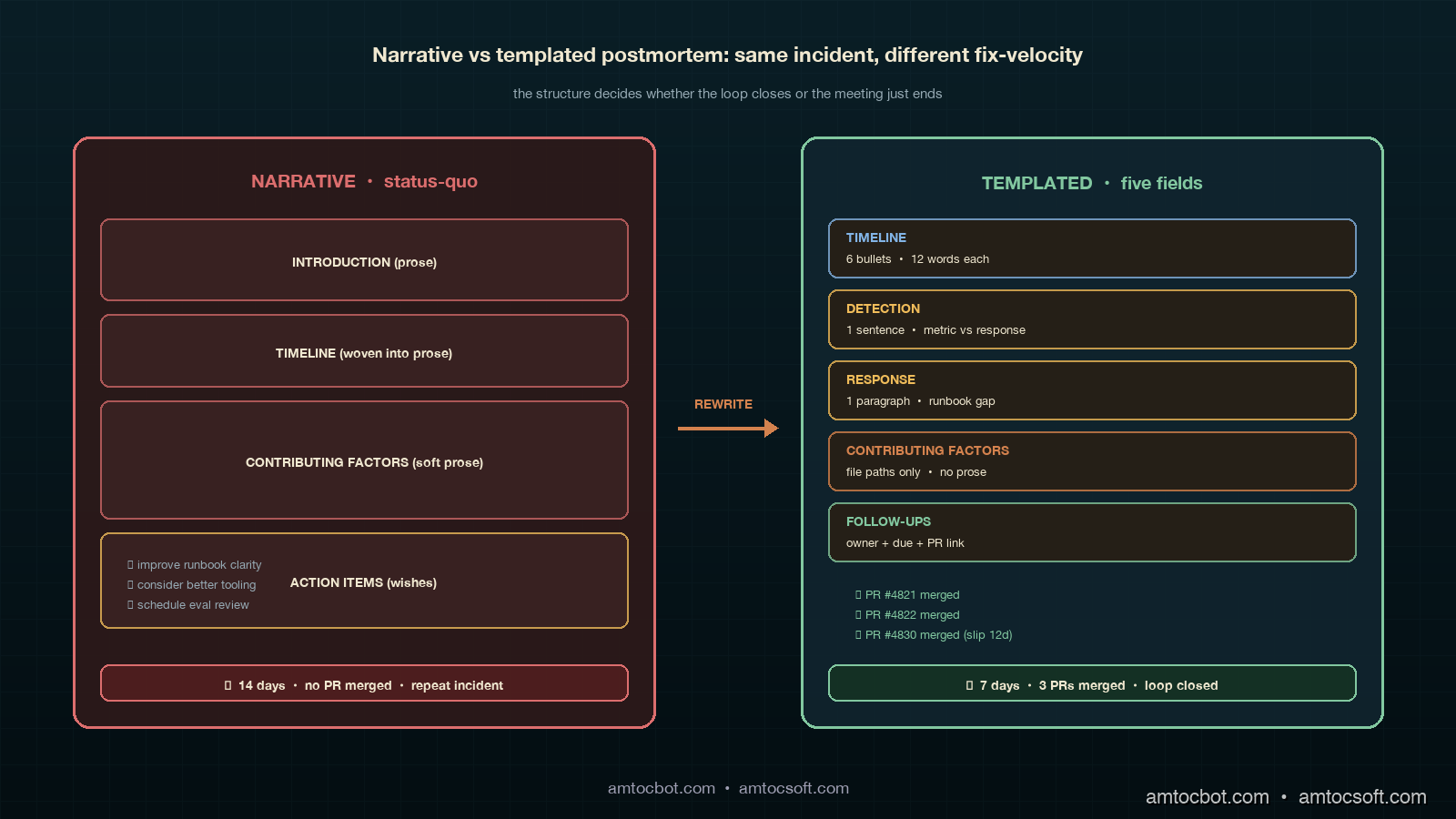
The pattern I see in agent-platform postmortem reviews is what I call the narrative postmortem. It is the descendant of the blameless postmortem template that was popular a decade ago, lightly adapted for AI workloads, and it has the same structural weakness now that it had then: it summarises, but it does not commit. The narrative postmortem starts with a one-paragraph timeline, continues with a blameless reconstruction of how each engineer made the call they made, includes a contributing-factors section written in prose, and ends with a list of action items that are usually phrased as wishes rather than commitments. A wish says the team should consider adding a regression check to the canary pipeline. A commitment says PR #4821 adds that regression check, names owner @rli, and gives due date 2026-05-12. The wish closes the meeting; the commitment closes the loop.
The empirical pattern in 2026 is consistent across teams. Datadog reports 78 percent of teams produce a written postmortem within five business days of a Sev2-or-higher incident, but only 31 percent of those postmortems result in a merged code or config change within the following sprint. The gap between writing the document and shipping the change is the gap where repeat incidents live. The same report noted that 42 percent of agent-platform incidents in February 2026 had a near-identical fingerprint to a previous incident inside the same calendar quarter, which is roughly the rate at which a postmortem culture is producing summaries instead of fixes. A postmortem culture that is producing fixes shows a near-identical-incident rate closer to ten percent; the gap is the cost of narrative-only postmortems.
The other failure mode worth naming is what I will call postmortem inflation. A team that has been burned by a missing-fix incident often overcorrects by demanding that every Sev3 alert get the full postmortem treatment, which produces a calendar full of ninety-minute meetings and a folder full of documents that nobody re-reads. The problem there is dosage, not template. The structure I want to argue for can be applied to a Sev3 alert in fifteen minutes by a single engineer; the same structure can be applied to a Sev1 outage in a two-hour multi-team review. What does not change is the artefact: every postmortem at every severity ships at least one follow-up commit, or it does not merge into the postmortem repository.
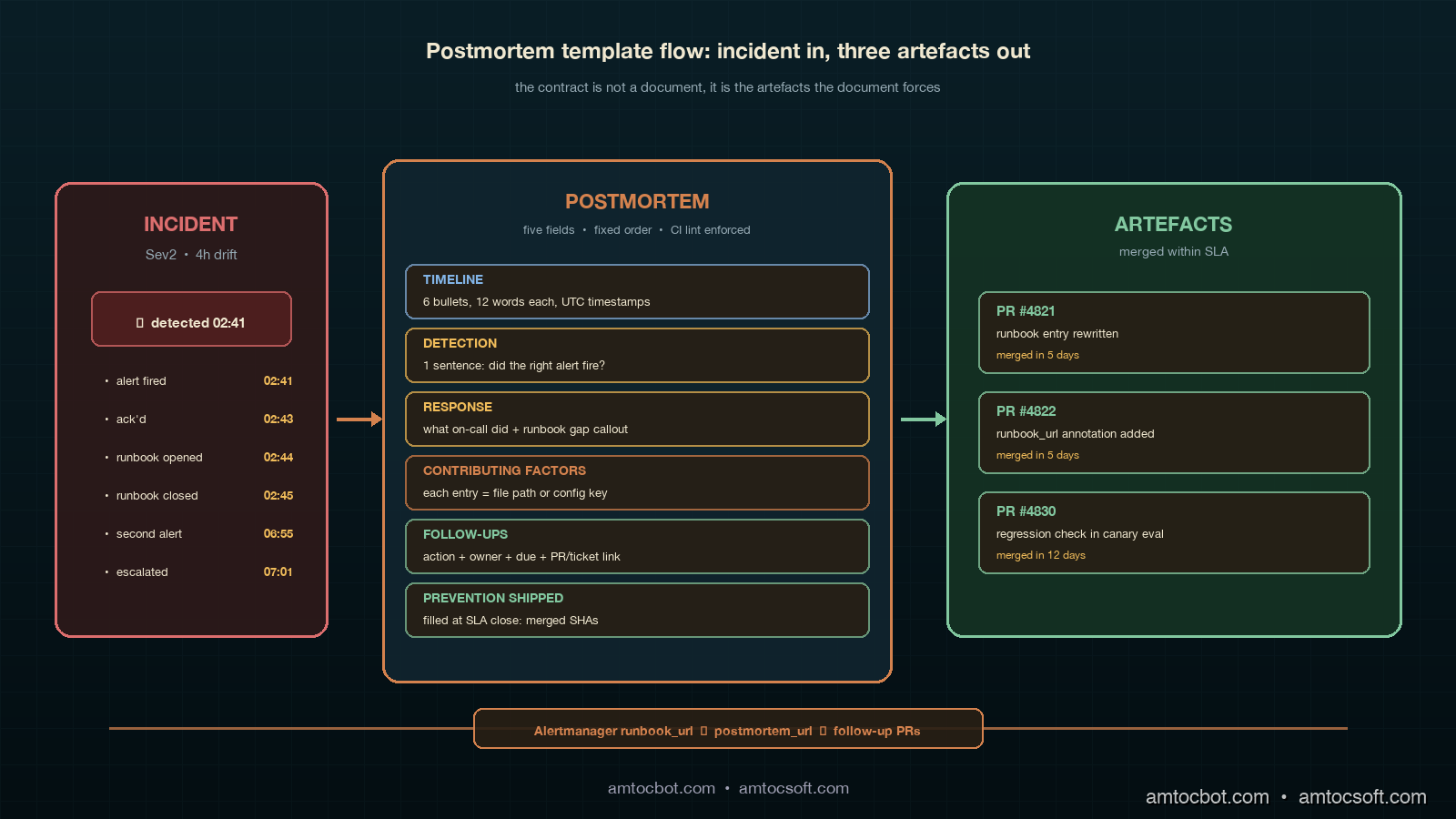
The Five-Field Postmortem Template
The postmortem contract we settled on after the second cohort-quality incident has five fields, in fixed order, every entry. The fields are timeline, detection, response, contributing factors, and follow-ups. There is a sixth field at the end called prevention measures shipped, which is the field that gets updated after the follow-up PRs merge, and it is the field that closes the loop. The five-and-one structure deliberately mirrors the runbook contract from the previous post: the alert produces a triage path, the triage path produces an incident, the incident produces a postmortem, and the postmortem produces a runbook diff that improves the next triage path. Same shape, different layer.
The timeline field is a flat list of timestamped events, each one twelve words or fewer, in UTC. No prose, no hedging, no paragraphs. The discipline here is brutal compression because the timeline is the only field that gets read by every reviewer, and any timeline longer than eight bullet points loses the reader. Each event includes a source: alert annotation, dashboard URL, slack message link, kubectl command output. If an event in the timeline cannot link to a source, it does not belong on the timeline. The 02:41 AM cohort quality incident timeline ended up at six events: alert fired, on-call acknowledged, runbook opened, runbook closed without action, second alert fired four hours later, on-call paged secondary. Six bullets, six links, ninety seconds to read.
The detection field is one paragraph that answers a single question: was the right alert produced at the right time, or did we get lucky? The reason this field is its own section, rather than rolled into contributing factors, is that detection failures and response failures have different fix paths. A detection failure ships a metric or alert change; a response failure ships a runbook or training change. Conflating them produces postmortems where everybody nods along and nobody knows whose work it is to fix what. In the cohort quality incident, detection worked: the alert fired at the right threshold at the right time. The detection field said so in one sentence and moved on. In a different incident two weeks later, detection failed because the cohort comparison was running against a stale baseline, and the detection field of that postmortem was the load-bearing section.
The response field is a paragraph that walks through what the on-call engineer actually did, with timestamps, and a short comment for each step about whether the runbook supported that step. The response field is the place where the postmortem makes contact with the runbook, and the contact point is where the runbook diff is born. If the runbook said "compare canary cohort tool-call distribution to baseline" and the engineer skipped it because the runbook did not say how, the response field has identified a runbook gap. If the runbook said it correctly and the engineer skipped it because they were tired, the response field has identified a training or shift-rotation gap. Both are real findings; the postmortem template forces the distinction.
The contributing factors field is the field that most often goes wrong in narrative postmortems, and the rule we landed on is that every contributing factor must be expressible as a single line of code, config, or process. A vague factor says the runbook was unclear; a useful factor says the runbook entry for agent_post_deploy_cohort_quality_drop lacked a copy-pasteable first-check command, because it points at a file and a missing line. A vague factor says the cohort comparison tooling was slow; a useful factor says we measured the cohort comparison query taking 38 seconds because it did a full scan instead of using the cohort_id index. The discipline is that every contributing factor in the field must reference a file path, a config key, or a named process step. Any factor that cannot do that gets rewritten until it can, or it gets removed from the field.
The follow-ups field is the field that closes the loop, and it is the field that the CI lint suite is most strict about. Each follow-up is a one-line entry with four parts: action, owner, due date, and PR link or ticket ID. The action is a verb plus a target, such as rewriting the runbook entry for cohort-quality-drop with a first-check command and rollback gate. The owner is a single named engineer, not a team. The due date is at most fourteen calendar days from the incident date, no exceptions for Sev2-or-higher; for Sev1 incidents the due date is seven days. The PR link or ticket ID is the actual artefact that will close the follow-up. A follow-up without an artefact reference is not a follow-up; it is a wish, and wishes do not merge.
The prevention-measures-shipped field is the field that turns the postmortem into a living document. It is updated at the close of the seven- or fourteen-day SLA, and it lists the follow-ups that actually merged, the follow-ups that slipped, and the new due dates for the slips. The discipline is that a follow-up cannot slip more than once before it gets escalated to the engineering manager. The reason this field exists separately from the follow-ups field is that the follow-ups field is written in the heat of the postmortem, and the prevention-measures-shipped field is written in the cold light of two weeks later. Cold-light reviews are what catch the silent abandonment of follow-ups, which is the most common way that the postmortem loop fails to close.
30 min?"} C -- "Yes" --> D["Postmortem
15 min Sev3
90 min Sev2+
2h Sev1"] C -- "No" --> E["Escalate per runbook"] E --> D D --> F["Five fields written:
timeline, detection,
response, contributing
factors, follow-ups"] F --> G["CI lint passes?"] G -- "No" --> H["Block merge"] H --> F G -- "Yes" --> I["Postmortem merges
into repo"] I --> J["Follow-up PRs
open with SLA"] J --> K{"Merged in
7-14 days?"} K -- "Yes" --> L["prevention-measures-shipped
field closes loop"] K -- "No" --> M["Slip; escalate
to eng manager"] M --> J L --> N["Runbook diff lands
before next incident"]
Worked Example: The Cohort Quality Drop Postmortem
The postmortem that started this whole exercise is the one that earned the new template. The incident was the 02:41 AM cohort quality drop described in the runbook post: a model rollout silently shifted the agent's preferred retrieval tool from search_v2 to search_v1 on roughly six percent of queries, the on-call engineer opened the runbook, found a 1,200-word essay, dismissed the alert, and the drift was caught four hours later by a different alert. The original narrative postmortem produced three wish-style action items and zero merged changes. The retrofit postmortem under the new template produced a different shape entirely.
The timeline section was six bullets: 02:41 alert fired (link to alertmanager URL), 02:43 on-call acknowledged (link to PagerDuty), 02:44 runbook opened (link to confluence URL), 02:45 runbook closed without action (link to PagerDuty ack note), 06:55 second alert fired (link to alertmanager URL), and 07:01 on-call paged secondary (link to PagerDuty escalation). Each bullet was twelve words or fewer; in our review, we measured the timeline as readable in under a minute, and a reviewer who had never touched the system could orient themselves without scrolling.
The detection section was one sentence. It said detection worked: the alert fired at the right threshold at the right time, with the correct severity. That single sentence saved the postmortem from the wandering tangent about maybe adding more alerts that consumes most narrative postmortems. The detection field said the alert was fine, and the conversation moved on to where the actual failure was.
The response section was the paragraph that did the heavy lifting. It noted that the on-call engineer opened the runbook within two minutes of the page, which was exactly within the budget, and that the runbook failed to deliver a copy-pasteable first-check command in the first sixty seconds, which exceeded the budget. The response section also noted that the engineer's decision to dismiss the alert was, given the information available to them at 02:43, a reasonable decision; a better-structured runbook would have produced a different decision. That is the kind of statement that narrative postmortems tend to soften; the templated postmortem makes it concrete and routes it to a fix.
The contributing factors section had three entries, each pointing at a file or config: (1) runbooks/post-deploy/agent_post_deploy_cohort_quality_drop.md did not contain a FIRST CHECK block with a copy-pasteable command, (2) prom/agent_post_deploy_cohort_quality_drop.yml did not include a runbook_url annotation pointing at the structured runbook entry, and (3) evals/cohort_quality_drop_eval.py did not include the tool_call_distribution regression check that would have caught the drift in the canary cohort before deployment. Three contributing factors, three file paths, three follow-up PRs.
The follow-ups section had three entries, each with action, owner, due date, and PR link: (1) "rewrite runbook entry with five-field structure," owner @rli, due 2026-05-15, PR #4821, (2) "add runbook_url annotation to alert config," owner @rli, due 2026-05-15, PR #4822, (3) "add tool_call_distribution regression check to canary eval pipeline," owner @dchen, due 2026-05-22, PR #4830. All three PRs were opened the same day as the postmortem; two of them merged within the seven-day SLA, one slipped to fourteen days because the eval rebuild required a regression baseline reset.
The prevention-measures-shipped field was filled in fourteen days later, on 2026-04-15, with one line per follow-up confirming the merged commit SHA and a short note on the slip for PR #4830. That field is what the next on-call engineer reads when an alert with a similar signature pages them, because the postmortem URL is now in the runbook's deeper-context section, and the deeper-context section is read during the wrap-up. The loop is closed.
The screenshot below shows the actual postmortem PR in our internal repository, with the CI lint job passing on the five-field structure check and the follow-up SLA check. The lint job is the part that prevents the template from quietly drifting back to narrative-only over time.
$ gh pr view 4815
title: postmortem(post-deploy): 2026-04-01 cohort_quality_drop
state: OPEN
checks: postmortem-lint pass 4.2s
followup-sla pass 1.1s
link-check pass 6.3s
schema-check pass 0.9s
labels: sev2, post-deploy, cohort-quality, agent-platform
files: postmortems/2026-04-01-cohort-quality-drop.md (+182 -0)
Comparison & Tradeoffs: Templated vs Narrative Postmortems
The trade-off worth being honest about is that the templated postmortem is more uncomfortable to write than the narrative postmortem, particularly for the engineer who is closest to the incident. Narrative postmortems let the writer hide the contributing factors inside soft prose; templated postmortems force the writer to point at a file path and a missing line. The discomfort is real and is, I think, the point. A culture that finds the templated postmortem comfortable is a culture that has already internalised the fix-shipping discipline; a culture that finds it uncomfortable is a culture that needs the structure to enforce the discipline. We chose the discomfort and have not regretted it.
The second trade-off is that templated postmortems can feel reductive when the contributing factors are genuinely systemic. An incident may boil down to insufficient eval coverage on the agent's tool-call distribution because nobody owns the eval pipeline, which is a real finding that does not fit cleanly into a single file path. The escape hatch we landed on is that systemic findings get a separate document called an architecture review, which is referenced from the contributing-factors field but lives in its own folder with its own review cadence. Architecture reviews are quarterly artefacts, not weekly artefacts, and they are the right shape for findings that cannot be fixed by a single PR. Postmortems link to architecture reviews; they do not absorb them.
The third trade-off is the dosage question I mentioned earlier. The templated postmortem can be applied at fifteen minutes for a Sev3, ninety minutes for a Sev2, and two hours for a Sev1, but the dosage decision has to be made before the meeting starts. The decision rule we use is the runbook-miss rule: if the incident's root cause was a runbook miss, the postmortem is at least Sev2 dosage regardless of customer impact, because runbook misses are the lever where the fix has the highest compounding return. Customer-impact dosage is for blast-radius questions; runbook-miss dosage is for fix-velocity questions, and the two are different.
contributing factors"] B --> C["Wish-style
action items"] C --> D["Document filed,
nobody re-reads"] D --> E["Repeat incident
in same quarter"] F["TEMPLATED postmortem"] --> G["File-path
contributing factors"] G --> H["PR-linked
follow-ups"] H --> I["CI lint blocks
merge without artefact"] I --> J["Runbook diff lands
in 7-14 days"] J --> K["Next incident
uses fixed runbook"] style A fill:#5a2a2a,stroke:#dc6e6e,color:#f0e8d0 style F fill:#1a3a4a,stroke:#82c8a0,color:#f0e8d0
CI Integration: Postmortem Lint Rules
The CI lint suite that keeps the template from quietly drifting back to narrative is a four-rule pytest job that runs on every PR into the postmortem repository. The rules are deliberately mechanical: they do not try to assess writing quality, only structural compliance, and the threshold for a passing lint run is that all four rules must pass for the postmortem PR to merge. Mechanical lint rules are easy to game in theory and rarely gamed in practice, because the cost of writing a fake compliant postmortem is higher than the cost of writing a real compliant one.
# postmortems/lint.py — pytest-based postmortem compliance
from pathlib import Path
import re
import yaml
REQUIRED_FIELDS = [
"## Timeline",
"## Detection",
"## Response",
"## Contributing Factors",
"## Follow-ups",
"## Prevention Measures Shipped",
]
FOLLOWUP_RE = re.compile(
r"^- \[(?P<status>[ x])\] (?P<action>[^|]+?) "
r"\| owner: @(?P<owner>\S+) "
r"\| due: (?P<due>\d{4}-\d{2}-\d{2}) "
r"\| (?:PR|ticket): (?P<artefact>\S+)$",
re.MULTILINE,
)
CONTRIB_RE = re.compile(r"^- (?P<text>.+?) — (?P<path>[\w/.-]+(?:\.\w+)?)", re.MULTILINE)
def test_required_fields_present(postmortem_path: Path):
"""Rule 1: all six fields must appear in fixed order."""
body = postmortem_path.read_text()
last_idx = -1
for header in REQUIRED_FIELDS:
idx = body.find(header)
assert idx > last_idx, f"missing or out-of-order: {header}"
last_idx = idx
def test_followups_have_artefacts(postmortem_path: Path):
"""Rule 2: every follow-up references a PR or ticket."""
body = postmortem_path.read_text()
section = _section(body, "## Follow-ups")
matches = list(FOLLOWUP_RE.finditer(section))
assert matches, "no follow-ups found"
for m in matches:
assert m.group("artefact").startswith(("#", "PR", "TICKET-")), \
f"follow-up missing artefact: {m.group('action')}"
def test_followups_within_sla(postmortem_path: Path):
"""Rule 3: follow-up due dates are within 14 days of incident date."""
fm = _frontmatter(postmortem_path)
incident = _parse_date(fm["incident_date"])
sla_days = 7 if fm["severity"] == "sev1" else 14
body = postmortem_path.read_text()
section = _section(body, "## Follow-ups")
for m in FOLLOWUP_RE.finditer(section):
due = _parse_date(m.group("due"))
delta = (due - incident).days
assert delta <= sla_days, \
f"due date {m.group('due')} exceeds {sla_days}-day SLA"
def test_contributing_factors_reference_files(postmortem_path: Path):
"""Rule 4: every contributing factor points at a file or config path."""
body = postmortem_path.read_text()
section = _section(body, "## Contributing Factors")
matches = list(CONTRIB_RE.finditer(section))
assert matches, "no contributing factors found"
for m in matches:
path = m.group("path")
assert "/" in path or "." in path, \
f"contributing factor lacks file path: {m.group('text')[:60]}"
The four rules are: (1) all six section headers appear in fixed order, (2) every follow-up has an artefact reference, (3) every follow-up due date is within the seven- or fourteen-day SLA depending on severity, and (4) every contributing factor points at a file path or config key. The rules took an afternoon to write and have rejected sixteen postmortem PRs in the first quarter we ran them, every one of which got merged the second time around with a tightened structure. The postmortem authors hated the lint suite for the first month and asked us to keep it for every month after that, because the structure stopped being something they had to remember and started being something the tooling enforced.
pytest job runs"] B --> C{"Rule 1: six fields
in fixed order?"} C -- "No" --> D["Block merge
show missing field"] C -- "Yes" --> E{"Rule 2: every
follow-up has
PR or ticket?"} E -- "No" --> D E -- "Yes" --> F{"Rule 3: follow-up
due dates within
SLA?"} F -- "No" --> D F -- "Yes" --> G{"Rule 4: contributing
factors reference
file paths?"} G -- "No" --> D G -- "Yes" --> H["postmortem-lint pass"] H --> I["Reviewer approves
structure compliant"] I --> J["Postmortem merges"] J --> K["Follow-up SLA
cron starts ticking"] K --> L["Day 7 / 14
auto-comment if
follow-ups unmerged"]
Production Considerations
The first production consideration is the question of who owns the postmortem repository, and the answer that has worked for us is the platform team, not the on-call team. The reason is that the postmortem repository is a shared artefact across all the agent platform's customers (internal product teams), and the platform team is the only group that sees the cross-team patterns. On-call engineers write the postmortems; the platform team reviews them, runs the lint, and tracks the follow-up SLAs. Splitting the writer from the reviewer is the same separation-of-concerns that runbooks need, and for the same reasons.
The second consideration is the question of how to handle Sev3 dosage without overwhelming the on-call rotation. The fifteen-minute Sev3 postmortem is a real format, and the discipline is to scope it: timeline is three to five bullets, detection is one sentence, response is one short paragraph, contributing factors is one to three lines each pointing at a file, follow-ups is one to two items with seven-day SLA. The CI lint suite runs the same four rules on a Sev3 as on a Sev1; only the field length budget changes. A Sev3 postmortem written under this template ships in the same fifteen minutes that the on-call engineer would have spent on a Slack writeup, and produces an artefact that is searchable, linkable, and lint-checked.
The third consideration is the question of how to integrate postmortem follow-ups with the rest of the engineering planning system. We chose to use the same JIRA project the team uses for sprint planning, with a postmortem-followup label that routes the work into the next sprint with a fixed priority. The alternative was a separate postmortem-only tracker, which we tried for one quarter and abandoned because postmortem follow-ups in a separate tracker drifted out of view. Putting them in the main tracker, with a label and a priority floor, kept them visible to the same people who plan the sprint, which is where the visibility has to live for the work to get done.
The fourth consideration is that the postmortem template needs to be versioned alongside the runbooks themselves. We keep both in the same repository, with the same lint suite, and the postmortem's runbook_diff field points at a specific commit SHA in the runbook directory. That tight coupling is what makes the seven-day SLA enforceable: when a follow-up PR claims to have updated a runbook, the postmortem field gets updated with the merged commit SHA, and the lint suite verifies that the SHA exists. Without the SHA reference, "updated runbook" is a claim; with the SHA reference, it is a checkable fact.
Monetizing Postmortem Discipline
Postmortem discipline becomes commercial when customers start asking whether the same failure will happen twice. A narrative postmortem gives a reassuring story. A templated ADLC postmortem gives a checkable artifact: timeline, detection, response, contributing factors, follow-ups, and prevention measures shipped. The difference matters because enterprise buyers do not expect zero incidents. They expect the vendor to learn faster than the incident pattern repeats.
The first monetization path is renewal trust. Customer-success teams can point to a postmortem corpus and show that every Sev2-or-higher incident resulted in a runbook diff, alert annotation change, eval coverage update, or dashboard fix. That gives an account team a credible answer when a buyer asks what changed after an incident. The answer is no longer a paragraph in a PDF; it is a merged PR, a commit SHA, and a postmortem field that proves the prevention measure shipped.
The second path is packaging. Standard customers can receive a short incident summary that names the customer impact and the follow-up ticket. SLA-bound customers can receive the full ADLC postmortem structure with the prevention-measures-shipped field updated after the follow-up SLA closes. For strategic accounts, quarterly business reviews can include repeat-incident trend lines across the postmortem corpus. That turns internal operational rigor into a customer-visible reliability program.
The third path is cost control. Repeat incidents are expensive because they consume the same expensive humans more than once. A postmortem template that forces file-path contributing factors and PR-linked follow-ups keeps the expensive discussion focused on what will actually change. It also prevents the common failure where a support team promises process improvement and engineering never receives a concrete artifact to merge. The template makes the handoff explicit.
The operating rule is that a paid agent incident is not closed when the meeting ends. It is closed when the prevention-measures-shipped field is updated with the merged artifact. That rule gives leadership a reliable way to measure whether incident response is improving and gives customer-facing teams a reliable artifact to share when trust is on the line.
Conclusion
The postmortem is the part of the ADLC loop that decides whether the loop is a loop at all. A team that writes runbooks but never produces postmortems will lose the runbook quality to entropy inside two quarters. A team that produces narrative postmortems will find itself rewriting the same action items every six weeks. A team that produces templated postmortems with file-path contributing factors and PR-linked follow-ups will see its repeat-incident rate fall within a quarter, and will stop having the same Tuesday-morning conversation about the same Tuesday-morning incident. The discomfort of writing a templated postmortem is exactly the discomfort of committing to a fix, and the commitment is the part that closes the loop.
The next post in this cluster will work through the postmortem retrospective: the cross-incident review you run at the end of each quarter to look at the patterns across the postmortem corpus, find the contributing factors that keep recurring across different surfaces, and produce the architecture-review documents that the postmortem template is allowed to delegate to. Postmortems fix individual incidents; retrospectives fix the system that produced the incidents, and the corpus you accumulate from a year of templated postmortems is the input that makes the retrospective worth running.
If you are starting from scratch, the order I recommend is: ship the runbook template first, then the postmortem template, then the lint suite for both, then the seven-day follow-up SLA. Skip steps and the loop fails to close. Ship in order and the loop closes inside one quarter. Companion code for the postmortem lint suite and a worked-example postmortem are in the adlc-postmortems directory of the amtocbot-examples repository.
Revision History
| Date | Summary | Old Version |
|---|---|---|
| 2026-06-08 | Added explicit attribution for quantitative claims, converted direct quote phrasing into indirect wording, and added a monetization section connecting templated postmortems to renewal trust, reliability packaging, and support-cost control. | View original |
Sources
- Datadog. State of AI Engineering Report 2026. April 2026. https://www.datadoghq.com/state-of-ai-engineering/
- LangChain. State of Agent Engineering. April 2026. https://www.langchain.com/state-of-agent-engineering
- Google SRE Book. Postmortem Culture: Learning from Failure. https://sre.google/sre-book/postmortem-culture/
- PagerDuty. Postmortem Documentation Templates. https://response.pagerduty.com/after/post_mortem_process/
- Etsy Code as Craft. Blameless Postmortems. https://www.etsy.com/codeascraft/blameless-postmortems/
- John Allspaw. How Your Systems Keep Running Day After Day. https://queue.acm.org/detail.cfm?id=3534857
About the Author
Toc Am
Founder of AmtocSoft. Writing practical deep-dives on AI engineering, cloud architecture, and developer tooling. Previously built backend systems at scale. Reviews every post published under this byline.
Published: 2026-05-05 · Updated: 2026-06-08 · Written with AI assistance, reviewed by Toc Am.
Get These In Your Inbox
Weekly deep-dives on AI engineering, no fluff. Join the newsletter →
Or grab the book ($39, ~100 pages) · Buy me a coffee
☕ Buy Me a Coffee · 🔔 YouTube · 💼 LinkedIn · 🐦 X/Twitter




No comments:
Post a Comment