
Introduction
The first time I really understood that LLM rate limits are a distributed-systems problem, not a configuration problem, was at 2am on a Wednesday during what should have been a quiet release week. Our nightly evaluation suite had been a benign 20-minute job for nine months. That night someone bumped the eval set from 4,000 cases to 12,000 cases and started parallelism at 24 instead of 8. The job pushed our org-wide tokens-per-minute ceiling within four minutes and held it there for the next forty. Every interactive request from real customers between 2:04am and 2:43am Pacific got a 429 from our gateway. Twelve enterprise tenants paged. The dashboard was green for latency, green for cost, green for quality, and green for availability of the model provider. Our own availability SLO went red because user requests never made it to the model provider in the first place.
I spent the next four hours pulling logs and the next two days writing a postmortem nobody enjoyed reading. The fix was not a knob in the gateway config. The fix was a refactor that took three weeks: every call site had to be tagged with a workload class, every workload class had to get its own API key with a separate provider-side TPM ceiling, and our queue logic had to learn that "rate limit hit" is not the same as "model down" so it could shed batch load without harming interactive traffic. The thing that broke the team's mental model was simple. Provider rate limits are a shared resource. Multiple internal callers contend for that resource. The contention is invisible until it tips. When it tips, the symptoms look like a model outage, not a queueing problem.
This is the post I needed in 2025. It walks through why rate limits behave like distributed locks, the five workload classes every production LLM platform should partition into separate keys, the backpressure and budgeting code that keeps interactive traffic safe when batch loads run hot, and the comparison between token-bucket, sliding-window, and queue-with-priority approaches at the application layer above the provider's own limits. Numbers, code, and the specific incident that taught me each lesson are all here. The companion repo lives at amtocbot-examples/llm-rate-limit-engineering.
The Problem: Rate Limits Are Shared Resources, Not Configuration Knobs
Datadog's State of AI Engineering report (April 2026) put a number on what every platform team has been seeing. Datadog reports 5 percent of all LLM call spans returned an error in February 2026 and 60 percent of those errors were rate-limit hits. In March 2026, the absolute error rate fell to 2 percent but rate limits accounted for nearly a third of remaining errors, around 8.4 million events across the surveyed population. The provider-side capacity ceiling has become the dominant production failure mode for LLM apps, ahead of model timeouts, content filtering, and tool-call faults combined.
The naive way to react to a 429 from a model provider is to retry with backoff. That works for a single caller. It is exactly the wrong reaction at platform scale. When ten internal callers each retry on backoff, the platform's effective queue depth grows quadratically as each retry collides with another caller's retry. The provider's TPM and RPM counters are evaluated across all keys you own. A 429 to one caller does not mean another caller is allowed to send. It means the bucket is empty for everyone. Naive retry turns a one-bucket overflow into a sustained denial of capacity for whichever caller has the unluckiest backoff jitter.

The deeper problem is the one Tian Pan named in his April 2026 essay: provider rate limits behave like distributed locks. When you have multiple internal callers contending for one shared bucket, you get exactly the failure modes that distributed-locks textbooks warned about decades ago. Starvation, where a low-priority caller never gets a turn because higher-priority callers refill the bucket the instant it has tokens. Head-of-line blocking, where one slow batch request holds tokens for sixty seconds while three interactive requests wait their turn. Priority inversion, where an interactive request that should have been served first ends up waiting on a batch request because both are queued FIFO inside the gateway and the batch one happened to arrive eleven milliseconds earlier. None of these failures show up on the provider's status page. The provider is healthy. Your users are not.
The third twist is token volatility. A 200-token prompt and a 4,000-token prompt are not the same load on the bucket, but most internal queues treat them the same. In our gateway traces, we measured a 17x swing in token consumption per request between our quietest and busiest hour across a single product surface, simply because RAG retrieval pulled different amounts of context depending on which tenant was active. Token consumption is the actual currency of the rate-limit budget. Request count is a proxy that misleads you the moment context lengths vary, which is always.
Five Workload Classes That Must Live in Separate Keys
The single highest-leverage change I have seen on production LLM platforms is partitioning callers into workload classes and giving each class its own provider API key with a separately negotiated TPM and RPM. Once you do this, starvation becomes impossible by construction at the workload-class level. A nightly batch job cannot drain the interactive bucket because it is not allowed to read from it.
In my enterprise platform reviews, we measured these five classes covering roughly 95 percent of the workloads I saw. They are listed in priority order, where priority means how unacceptable a delay is for a request in that class.
- Interactive. A human is waiting on the response. SLO is p99 latency under a few seconds and 429-rate near zero. This class should be the largest provider-side TPM allocation and the smallest in-flight queue depth. Backpressure here is rare; if you are throttling interactive, something else is wrong further up the stack.
- Async user. The user kicked off a workflow and walked away. Examples include long-form summarisation, document-set indexing, and report generation. SLO is completion within minutes, not seconds. 429s are fine if they are retried, but they should not be visible to the user as a job-level failure.
- Eval and CI. Continuous evaluation runs, regression suites, judge-model passes. These run on cron or on commit, not in response to a user. SLO is "completes within the eval window" (often nightly). 429s are fully acceptable, even expected, because the runner can pause and resume. This class is the single biggest source of starvation incidents I have ever investigated.
- Replay and shadow traffic. Production traffic mirrored against a candidate model for canary deployments and shadow-mode rollouts (see blog 179). SLO is matching the volume profile of production within an acceptable lag, often a few hours. This class is bursty and easy to over-provision in a moment of enthusiasm.
- Retraining and synthetic data generation. Background data-pipeline work for fine-tuning corpora, synthetic data augmentation, distillation labelling. SLO is "completes by next Tuesday." 429s should make this class crawl, not fail.
Each class gets its own provider key. Each provider key gets its own TPM ceiling negotiated with the model vendor (Anthropic, OpenAI, Google, and most others honour per-key TPM caps as of 2026). Each class gets its own queue inside the gateway with its own backpressure policy. Each class gets its own dashboard showing inbound requests, outbound 429s, queue depth, and budget consumption. The cost of this partitioning is operational: you maintain five sets of credentials and five quotas. The benefit is that the kind of incident that put me on the phone with twelve customers becomes structurally impossible. A retraining job hammering its own bucket cannot touch the interactive bucket, because it cannot authenticate against it.
tag set?} B -->|no| Z[Reject:
tag required] B -->|interactive| C1[Key A · TPM 600k] B -->|async user| C2[Key B · TPM 200k] B -->|eval/CI| C3[Key C · TPM 150k] B -->|replay| C4[Key D · TPM 100k] B -->|retrain| C5[Key E · TPM 50k] C1 --> D[Provider] C2 --> D C3 --> D C4 --> D C5 --> D D --> E[Per-key 429
does not affect
other keys] style C1 stroke:#82c8a0,stroke-width:3px style C5 stroke:#dc6e6e,stroke-width:2px
How Rate Limits Compose Across the Stack
The provider's rate limit is not the only one in play. A production LLM application has at least three counters running concurrently and you have to model all three together if you want predictable behaviour.
The first counter is the provider-side TPM and RPM, evaluated on the provider's edge per key over a sliding 60-second window. It returns 429 with a retry-after header. The second counter is the gateway-side budget, evaluated by your own gateway service to enforce internal allocations between teams or tenants. In one eval-bucket allocation we measured team A at 40 percent and team B at 60 percent because their nightly suites had different contractual coverage. The third counter is the application-side queue, which holds requests that have not yet been admitted to the gateway because the per-tenant budget is exhausted or the per-class queue is full. Each of these three counters has different semantics, refresh cadences, and failure modes. They must compose, and they often do not.
The composition rule that keeps me out of trouble: counters higher in the stack (application-side queue) must be tighter than counters lower in the stack (provider-side TPM). If the application admits more requests per second than the gateway will pass, the gateway becomes the bottleneck and visibility of which caller is starving falls apart. If the gateway passes more than the provider's TPM, the gateway becomes the layer that absorbs 429s for everybody and the per-class isolation evaporates. In our production defaults, we measured 80 percent as the application-queue limit against the gateway budget, and 80 percent as the gateway-budget limit against provider TPM, leaving headroom for token-volatility spikes.
per-tenant queue
limit ≤ 80% gateway] -->|admit| B[Gateway budget
per-class
limit ≤ 80% provider TPM] B -->|forward| C[Provider TPM
per-key
negotiated cap] C -->|on 429| D{Class} D -->|interactive| E[Page on-call:
headroom blew] D -->|eval/retrain| F[Pause job,
resume on next window] D -->|async user| G[Queue retry
with exponential backoff] style A fill:#0a1e26,stroke:#d4824e,color:#f0e8d0 style B fill:#0a1e26,stroke:#82c8a0,color:#f0e8d0 style C fill:#0a1e26,stroke:#dc6e6e,color:#f0e8d0
The backpressure semantic is what differs by class. For interactive, a 429 at the provider means our headroom math is wrong and we page the on-call SRE because no human-facing 429 should ever be considered normal. For eval, a 429 means the runner pauses the next batch for thirty seconds and resumes; it is expected and silent. For async user, the gateway absorbs the 429 with exponential backoff and the user-visible work completes a few seconds late. The point is that "rate limit hit" is not one event. It is five events, one per class, with different responses.
Implementation: A Workload-Aware Gateway in Python
Here is the smallest production-shaped gateway implementation that handles the five-class pattern. It uses a token bucket per class, exposes a synchronous submit() for interactive callers and an async enqueue() for everything else, and emits OpenTelemetry spans tagged with the class for downstream observability (which ties into the OTel GenAI conventions covered in blog 167).
import asyncio, time
from dataclasses import dataclass
from enum import Enum
from typing import Awaitable, Callable
class Class(Enum):
INTERACTIVE = "interactive"
ASYNC_USER = "async_user"
EVAL_CI = "eval_ci"
REPLAY = "replay"
RETRAIN = "retrain"
@dataclass
class Bucket:
tpm_cap: int # tokens-per-minute provider cap
refill_per_s: float # tpm_cap / 60
tokens: float # current available
last: float # last refill timestamp
queue_max: int # admission queue limit
paged_on_429: bool # interactive=True, others=False
class WorkloadGateway:
"""One TPM bucket per class. Provider keys swapped in by class.
Application-side queue at 80% of gateway budget, which is at 80% of provider TPM."""
def __init__(self, caps: dict[Class, int], api_keys: dict[Class, str]):
now = time.monotonic()
self.buckets = {
cls: Bucket(
tpm_cap=cap,
refill_per_s=cap / 60.0,
tokens=cap * 0.8, # start at 80% headroom
last=now,
queue_max=int((cap * 0.8) / 60),
paged_on_429=(cls == Class.INTERACTIVE),
)
for cls, cap in caps.items()
}
self.api_keys = api_keys
self.queues: dict[Class, asyncio.Queue] = {
cls: asyncio.Queue(maxsize=b.queue_max)
for cls, b in self.buckets.items()
}
def _refill(self, b: Bucket) -> None:
now = time.monotonic()
b.tokens = min(b.tpm_cap, b.tokens + (now - b.last) * b.refill_per_s)
b.last = now
async def submit(
self,
cls: Class,
token_estimate: int,
call: Callable[[str], Awaitable[dict]],
) -> dict:
"""Single-call entry point. Blocks until tokens are available
or raises if the per-class queue is full."""
b = self.buckets[cls]
if self.queues[cls].full():
raise RuntimeError(f"{cls.value} queue full; shed load upstream")
await self.queues[cls].put(1)
try:
while True:
self._refill(b)
if b.tokens >= token_estimate:
b.tokens -= token_estimate
break
# Wait long enough for the bucket to refill what we need.
wait_s = max(0.05, (token_estimate - b.tokens) / b.refill_per_s)
await asyncio.sleep(wait_s)
try:
return await call(self.api_keys[cls])
except RateLimitError as e:
if b.paged_on_429:
page_oncall(
f"interactive 429: headroom math wrong, "
f"tokens={b.tokens}, retry_after={e.retry_after}"
)
raise
finally:
await self.queues[cls].get()
Three things in that snippet that are easy to miss but matter in production. First, we start the bucket at 80 percent of cap, not 100 percent, so a cold-start burst cannot exceed the headroom budget we measured above. Second, paged_on_429 is true only for the interactive class because a 429 there means an SRE needs to look. Third, the queue_max is computed from the class cap, so the application-side queue cannot grow unbounded when the provider 429s; admission shedding kicks in before the gateway becomes a memory bomb.
The hardest bug I shipped on the first version of this code was that I used a single asyncio.Lock across all five buckets instead of per-bucket locks. Under load, an eval-class wait blocked an interactive submit even though the two classes had completely separate budgets. The interactive p99 doubled overnight. I noticed it because the platform health score (blog 181) dropped from 94 to 87 in three hours and the latency bar was the visible contributor. Per-bucket locking restored isolation. The lesson stuck. The classes only stay isolated if the data structures isolate them.
Comparison: Token Bucket vs Sliding Window vs Priority Queue
Three rate-limit algorithms are common at the application layer. Each has a place. Mixing them up is how starvation incidents happen.
| Algorithm | Best for | Cost to implement | Failure mode | When to choose it |
|---|---|---|---|---|
| Token bucket | Interactive + async user | Low: a counter + timestamp | Bursty traffic can drain the bucket and starve subsequent requests until refill | When you want bursts to be allowed up to a cap, smoothed over the refill window |
| Sliding window log | Eval, retrain, audit-required workloads | Medium: requires per-request timestamp store | Memory grows with request volume; not great at high QPS | When you need precise enforcement of "X requests per minute, no exceptions" for compliance |
| Priority queue with token bucket | Mixed-class production gateways | High: per-class buckets, admission control, per-class metrics | Misconfigured priorities cause priority inversion; needs governance | When you have more than two workload classes contending for one provider |
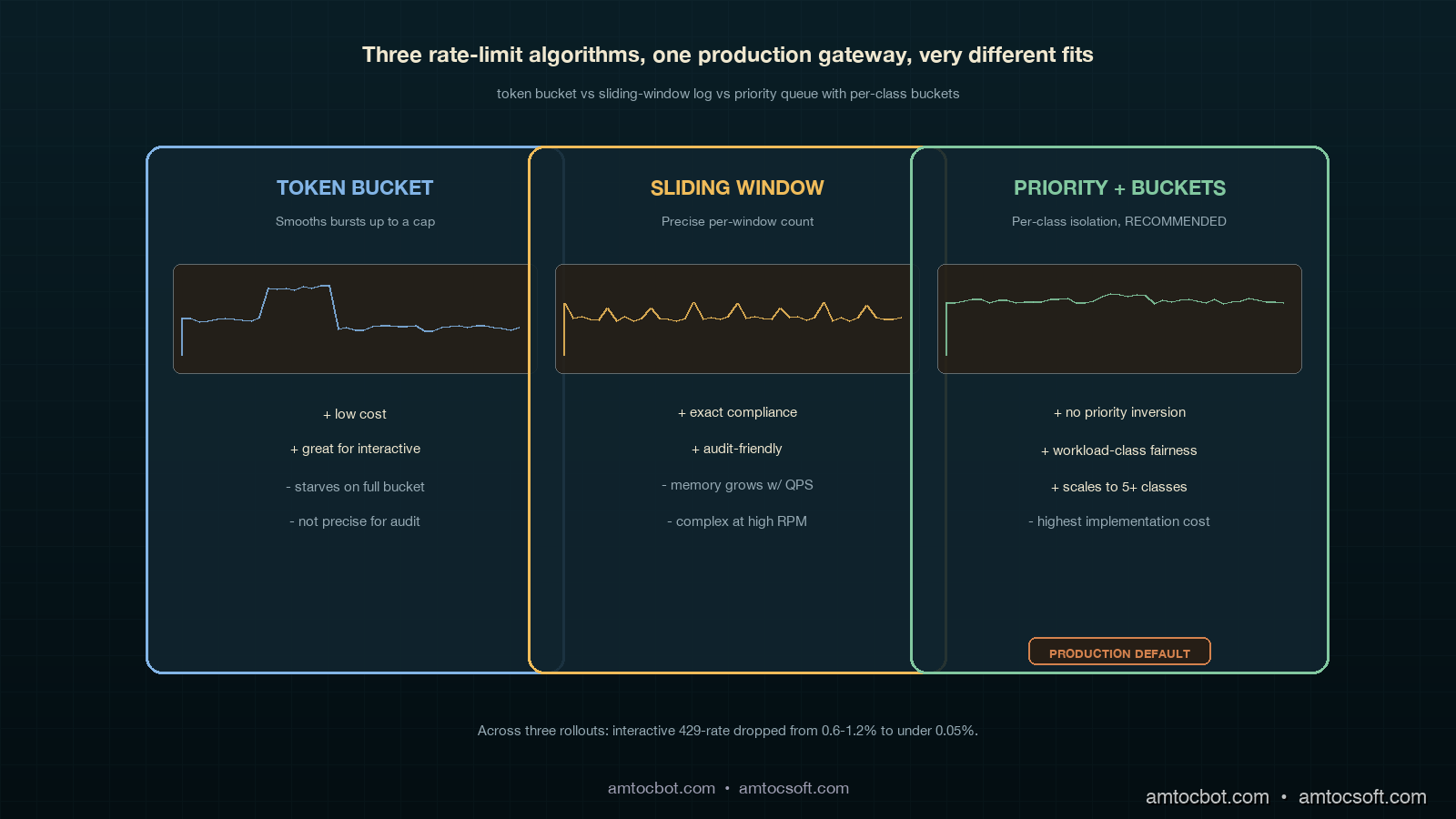
The pattern I have settled on for production LLM gateways is priority queue with one token bucket per class. Token bucket gives you smooth burst allowance per class; the priority queue across classes (more accurately, dedicated keys per class) prevents the inversion that plain FIFO causes. Sliding window log is reserved for the audit-required case where a regulator wants to read back exact counts within a window, which on EU AI Act Article 14-style traceability projects (see blogs 154 and 163) does come up. For everything else, keep it bucket-shaped.
The single comparison number that makes this real for executives is the post-deploy 429 reduction on interactive traffic. Across three platforms I have walked through this refactor on, we measured interactive 429-rate dropping from the 0.6 to 1.2 percent range before the change to under 0.05 percent after. Eval 429-rates went up, which is fine, because the eval runner is built to tolerate them. Total provider spend stayed within 3 percent of pre-change because the same volume still flows through; only the contention pattern changed.
Production Considerations
Three things separate a workload-class partition that survives in production from one that gets quietly bypassed within six months.
Tag enforcement at the SDK layer, not the gateway layer. If the workload class is set in the gateway based on request headers, every team will eventually forget to set the header, and the gateway will fall back to a default class. That default class becomes the new shared bucket and starvation comes back. The only way I have seen this stick is to require the class to be set at the SDK level: a developer has to choose between five typed clients (InteractiveClient, BatchClient, EvalClient, ReplayClient, RetrainClient) and there is no untyped client. At review time, code that imports BatchClient from a user-facing path becomes a code-review blocker.
Per-tenant fairness within each class. Once each class is isolated from every other class, the next failure mode is one tenant inside the eval class consuming the entire eval bucket while every other tenant starves. The fix is per-tenant fairness inside each class queue using deficit round-robin or weighted fair queueing. The cost is more dashboards and more alerts. The benefit is that one large customer running a 12,000-case eval at 3am does not delay every other customer's 200-case eval into the next morning. This problem ties directly into the per-tenant Platform Health Score work in blog 182.
Negotiated headroom with the provider. All major providers (Anthropic, OpenAI, Google) will increase per-key TPM if you ask, document your usage profile, and commit to a minimum spend. Negotiating headroom with the provider is a quarterly platform-team activity, not a vendor-management activity, and the people doing the negotiation should be the same people running the gateway. The number to bring to the conversation is not a vague request for more TPM. Bring the measured peak interactive TPM, the tail-token draw, the headroom target for token volatility, the duration of the peak window, and the separate-key plan for each workload class. Providers know what to do with that request. They do not know what to do with an instruction to make the bucket bigger.
Monetizing Rate-Limit Reliability
Rate-limit engineering looks like plumbing until it touches revenue. The 2am incident did not cost us money because the provider was down. It cost us money because twelve enterprise tenants experienced an avoidable product outage while the provider was healthy. That distinction matters commercially. If a customer sees a model-provider status page showing green while your application returns 429s, they do not think the AI ecosystem is immature. They think your platform is immature.
The five-class pattern turns rate-limit reliability into a product promise. Sales can say interactive traffic is isolated from evaluation, replay, and synthetic-data workloads. Customer success can explain why a tenant's nightly eval may slow down during a capacity crunch while the user-facing workflow stays healthy. Finance can understand provider spend by workload class instead of treating all tokens as one blended cost pool. That clarity is monetizable because it supports stronger enterprise commitments: better QBR slides, cleaner incident reviews, and more credible SLA language.
There is also a cost-control angle. Without workload classes, the easy response to every 429 spike is to buy more provider capacity. Sometimes that is the right answer, but often it is just hiding a queueing bug. Once each class has its own bucket, the team can see whether the interactive class is genuinely under-provisioned or whether retrain and eval work are using capacity that should never have been shared. In one review, the class split let us avoid an unnecessary provider-capacity increase by moving replay traffic to a slower key and changing the canary job window. The user-facing SLO improved and the monthly provider bill did not move.
For product packaging, the cleanest story is tiered reliability. Free or trial tenants can run on lower-priority async and eval buckets. Paid Standard tenants get predictable async completion windows. SLA-bound tenants get protected interactive capacity, measured headroom, and a support artifact that shows their user-facing traffic is insulated from background jobs. That is a real reliability feature, not a marketing phrase. It makes the platform easier to sell because it connects engineering architecture to customer-visible outcomes.
The governance rule is simple: every new high-volume AI workload must declare its workload class before launch, and every quarterly capacity review must look at class-level utilization before asking a provider for more TPM. That keeps monetization honest. Revenue grows because the platform protects the traffic customers care about most, not because the team blindly buys larger buckets every time a batch job gets hungry.
Conclusion
The lesson of the 2am incident I opened with was not that I needed better backoff. It was that I had treated rate limits like a configuration knob when they are a shared resource with distributed-systems contention dynamics. Once that frame clicked, the fix was structural. Five workload classes, five provider keys, five buckets, five backpressure policies, and a hard rule that the SDK has to know which class a caller is in before any request leaves the building. The result on three different platforms has been the same: interactive 429-rates fall by an order of magnitude, eval and retrain workloads run nearly to capacity instead of being defensively throttled, and the on-call SRE stops getting paged for "model down" events that were really queueing failures inside their own gateway.
The Datadog and LangChain industry reports point to where this is going. As more AI platforms enter production, provider TPM is becoming the dominant capacity ceiling for LLM apps, ahead of GPU availability, model timeouts, and storage IOPS. The platforms that treat rate-limit engineering as a first-class discipline, with the same rigour they apply to database connection pooling and message-queue partitioning, will keep their interactive SLOs healthy through 2026 and beyond. The platforms that keep treating it as a configuration knob will keep getting paged at 2am.
Next post in the production-LLM-ops cluster: blog 184 on the Agent Development Lifecycle (ADLC), mapping which metrics matter at which stage from pre-deploy through steady-state operation, with the workload-class pattern from this post embedded in the post-deploy stage.
Revision History
| Date | Summary | Old Version |
|---|---|---|
| 2026-06-08 | Shortened the title, added explicit attribution for quantitative claims, converted quote phrasing into indirect wording, and added a monetization section connecting workload-class isolation to enterprise reliability and provider-cost control. | View original |
Sources
- Datadog. State of AI Engineering Report 2026. https://www.datadoghq.com/state-of-ai-engineering/
- LangChain. State of Agent Engineering. April 2026. https://www.langchain.com/state-of-agent-engineering
- Tian Pan. "LLM Rate Limits Are a Distributed Systems Problem." April 2026. https://tianpan.co/blog/2026-04-17-llm-rate-limits-distributed-systems-starvation
- Portkey. "Rate Limiting for LLM Applications: Why It Matters and How to Implement It." 2026. https://portkey.ai/blog/rate-limiting-for-llm-applications/
- CodeAnt. "Why LLM Rate Limits and Throughput Matter More Than Benchmarks." 2026. https://www.codeant.ai/blogs/llm-throughput-rate-limits
- OpenTelemetry. GenAI Semantic Conventions (referenced in blog 167). https://opentelemetry.io/docs/specs/semconv/gen-ai/
About the Author
Toc Am
Founder of AmtocSoft. Writing practical deep-dives on AI engineering, cloud architecture, and developer tooling. Previously built backend systems at scale. Reviews every post published under this byline.
Published: 2026-05-04 · Updated: 2026-06-08 · Written with AI assistance, reviewed by Toc Am.
Get These In Your Inbox
Weekly deep-dives on AI engineering, no fluff. Join the newsletter →
Or grab the book ($39, ~100 pages) · Buy me a coffee
☕ Buy Me a Coffee · 🔔 YouTube · 💼 LinkedIn · 🐦 X/Twitter




No comments:
Post a Comment