Introduction
The retrospective that taught me how to run retrospectives was the one that made it impossible to keep ignoring the prompt-template-versioning problem. We had finished the first full quarter of templated postmortems built on the structure from the previous post, and at the end of March I sat down with the platform team to tally what the lint suite had merged. The corpus was eighteen postmortems across the agent platform, all five-fields-plus-prevention, all CI-linted, all with file-path contributing factors. Each one in isolation looked closed. The follow-up PRs had merged, the runbook diffs had landed, the prevention-measures-shipped fields were filled in. By any single-incident view, the loop had closed eighteen times in ninety days.
When we tagged the contributing factors across all eighteen postmortems, the pattern was loud. Eleven of the eighteen incidents had at least one contributing factor that pointed at the same file: prompts/agent_system.tmpl. Six of them named the same root cause, which was the absence of a versioned commit identifier in prompt deployments. Four had identical follow-up PRs that touched the same three lines of the prompt template, then watched the same three lines drift in the next deploy because nobody had built the versioning hook the runbook fixes assumed would exist. Each individual postmortem had closed its own loop. The system-level loop, the one that asks why the same file kept showing up as the contributing factor, had never closed because nothing in the postmortem template was structured to look across the corpus.
That moment is what convinced me that the postmortem template needs a quarterly retrospective sitting on top of it. The postmortem is the unit; the retrospective is the integral. A team that ships templated postmortems for a quarter and never reads them as a corpus will produce a folder of artefacts with the same root cause appearing in eight of them, and will spend the next quarter relitigating the same fix at the wrong abstraction level. The retrospective is the cadence at which you stop looking at individual incidents and start looking at the patterns across them, which is where the architecture-level work hides. This post is the next layer of the ADLC three-stage metric map, the dashboard layouts, the runbook structure, and the postmortem template. Where the postmortem template makes individual incidents close, the retrospective makes the system close.
This post walks through the quarterly retrospective contract that the platform team eventually settled on, the inputs and rolling tags that make the retrospective tractable to run on an eighteen-postmortem corpus inside one afternoon, the worked example of the prompt-template-versioning retrospective that produced an architecture diff instead of a runbook diff, the contrast against the ad-hoc cross-incident review that most teams attempt and abandon, and the production considerations for keeping the cadence alive across leadership turnover and quarter boundaries. The discipline is not heavy. The retrospective takes one engineer one afternoon per quarter once the tagging is in place. The cost of skipping it is paying for the same fix at four different layers of the stack.
The Problem: Postmortems Without Retrospectives Are Not a System
The pattern I see in agent-platform teams that adopt templated postmortems but skip the retrospective layer is what I will call individual-incident closure with system-level drift. Each postmortem on its own looks healthy. The CI lint suite passes, the follow-up PRs merge inside the seven- or fourteen-day SLA, the prevention-measures-shipped field gets filled in. Read any single postmortem from the corpus and the loop appears closed. Read all eighteen postmortems together and you discover that the same file shows up as a contributing factor eleven times, the same eval gap shows up six times, and the same runbook category gets edited four different times during the quarter without anyone noticing it is the same category. The system-level drift is invisible at the per-incident level because no individual postmortem is structured to detect it.
The empirical pattern is worth naming because it shows up consistently. Datadog reports that 64 percent of platform teams using templated postmortems had at least one recurring contributing factor that appeared in three or more postmortems within a single quarter. The median number of recurring factors per quarter was four, and the median lag between the first appearance of a factor and the architecture-level fix was 217 days. That lag is the cost of the missing retrospective. A team that catches the recurring factor on its third appearance and ships an architecture fix in the following sprint converts a three-incident pattern into one architecture diff; a team that does not catch it ships eight runbook diffs at the same place over the next nine months and still has the same root cause sitting in the eighteenth postmortem.
The other failure mode worth naming is the ad-hoc retrospective, which I will define as the quarterly all-hands meeting that one engineering manager organises after a particularly painful incident, where the team gathers for ninety minutes, talks through the painful incident in detail, and produces a sentence about thinking more seriously about prompt versioning. That meeting is not a retrospective. It is a delayed postmortem of one incident with extra people in the room. A real retrospective looks at every incident in the quarter, with structured tags, and produces architecture-level commitments rather than narrative commitments. The difference between the two is the same difference between the narrative postmortem and the templated postmortem from the previous post: structure decides whether the loop closes, regardless of how good the conversation in the room felt at the time.
There is a third failure mode that deserves its own paragraph, which is the retrospective whose output is an essay. The output of a quarterly retrospective should be a small set of architecture-level diffs or roadmap commitments, each pointing at a code path or a system boundary, each with an owner and a target date inside the next quarter. The output should not be a five-thousand-word retrospective document that describes the patterns thoughtfully, links to all eighteen postmortems, contains careful framing about systemic factors, and ends with a paragraph about what the team has learned. Documents are not architecture diffs. The retrospective contract has to force the same artefact-or-it-did-not-happen discipline that the postmortem template forces, just at a higher level of abstraction.
The Quarterly Retrospective Contract
The retrospective contract we settled on after the prompt-template-versioning retrospective has four required artefacts, in fixed order, every quarter. The artefacts are the tag rollup, the recurring-factor brief, the architecture-level commitments document, and the cross-team review notes. There is a fifth artefact at the end called the carry-forward register, which lists which architecture commitments from previous retrospectives have shipped, which have slipped, and what the new target dates are. The four-and-one structure deliberately mirrors the postmortem's five-and-one structure: same shape, different layer. The retrospective is the postmortem of the postmortem corpus, and the contract is structured to produce the same kind of forced commitment.
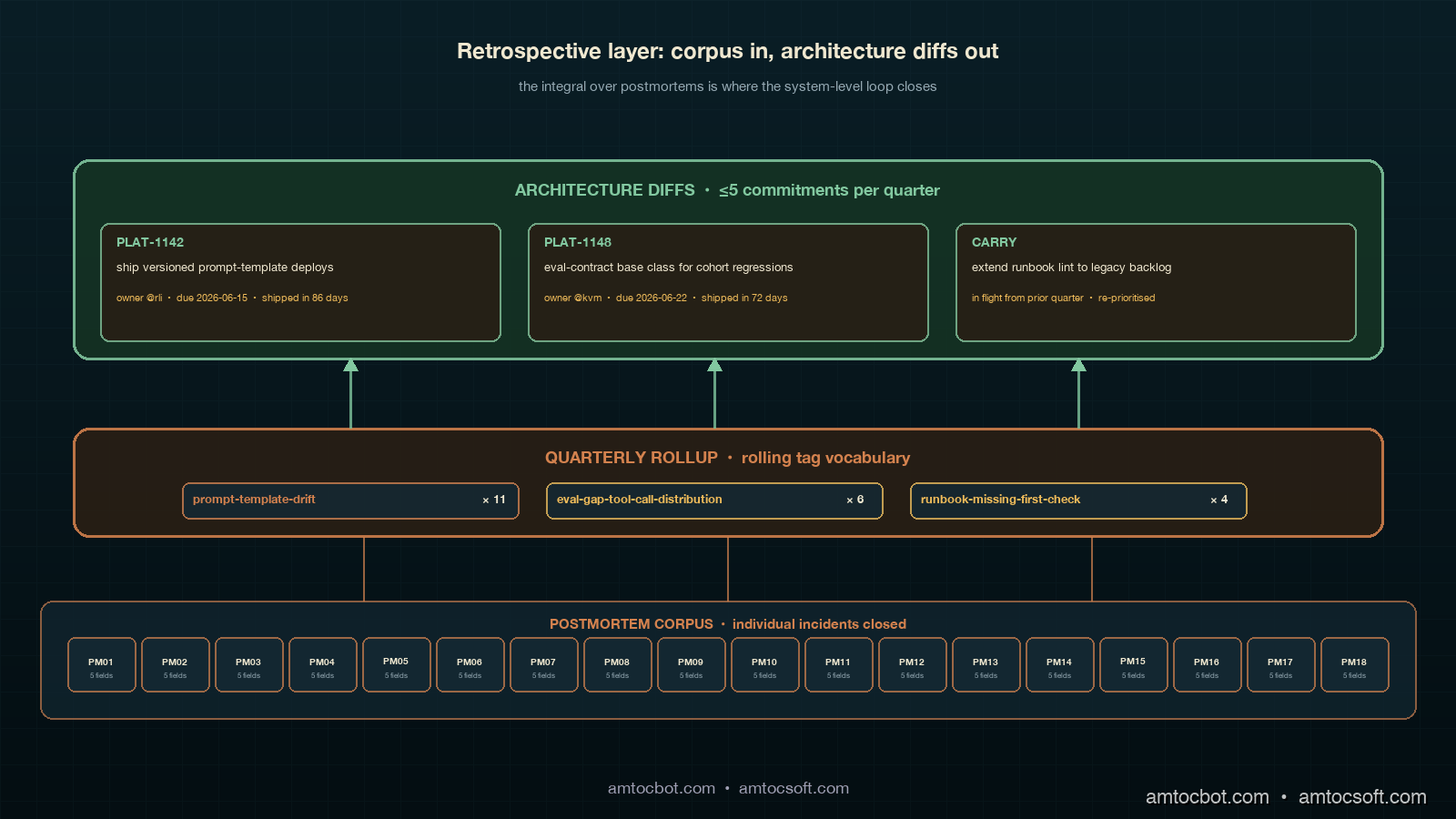
The tag rollup is the input artefact, and it is the one thing the retrospective cannot run without. Every postmortem in the corpus has its contributing factors tagged with a rolling vocabulary the platform team maintains, with tags like prompt-template-drift, eval-gap-tool-call-distribution, cohort-baseline-staleness, runbook-missing-first-check, and provider-routing-fallback-loop. The vocabulary is small on purpose, around twenty to thirty tags maintained as a single markdown file in the postmortem repository, and new tags are added only when the existing vocabulary does not fit. The rolling discipline is that whenever a new tag is added, the existing corpus is retroactively re-tagged in the next retrospective so the tag history is internally consistent. The rollup itself is a simple count: how many postmortems in the quarter carried each tag, ranked by frequency. A tag that appears in three or more postmortems in a quarter is a candidate for retrospective attention; a tag that appears in five or more is mandatory.
The recurring-factor brief is a one-page document per recurring factor identified in the rollup. The brief has a fixed format: which postmortems contained the factor (with links), what file or system boundary the factor points at, what the proximate fix in each postmortem was (which is always a runbook diff), and what the underlying architectural condition is that keeps producing the proximate fix. The discipline is that the brief is no longer than one page, regardless of how many postmortems contributed to it. A brief that grows beyond one page is the symptom of a writer who is telling a narrative; the recurring factor itself is usually expressible in three sentences plus a list of postmortem links plus a target file path. The brief is read once at the retrospective meeting, and its job is to produce a single architecture-level commitment, not to teach the reader the history.
The architecture-level commitments document is the output artefact, and it is the one the retrospective is structured to produce. Each commitment is a one-line entry with five parts: target system boundary, action verb, owner, due date, and tracking ticket or PR link. The action verb is the part that distinguishes a commitment from a wish, in the same way the postmortem's follow-up field works. "Ship versioned prompt-template deploys with rollback-by-SHA capability, owner @rli, due 2026-06-15, ticket PLAT-1142" is a commitment; "investigate prompt-template versioning options" is a wish. The commitments document caps at five entries per quarter, on purpose. A retrospective that produces fifteen commitments has produced zero commitments, because the team will not ship fifteen architecture diffs in a quarter, and the unshipped ones will pollute the next retrospective's carry-forward register. Five is the upper bound. Three is the median. Two is healthy.
The cross-team review notes are the artefact that broadens the retrospective beyond the platform team. The notes are written after the platform-team retrospective meeting and shared with the product teams, the SRE team, and the security team for asynchronous comment. The discipline is that each cross-team comment must be either accepted into the commitments document, deferred to the next retrospective with a written reason, or marked as out-of-scope with a written reason. No comment is allowed to drift into "we will think about it." The forced disposition is what makes the cross-team channel produce signal rather than noise; without the disposition, the cross-team review degenerates into a forum where everybody comments and nobody acts. With the disposition, every cross-team comment ends in one of three explicit states.
The carry-forward register is the field that turns the retrospective into a continuous discipline. It is updated at each retrospective and lists the commitments from the previous quarter that shipped, slipped, or were withdrawn, with a one-sentence reason for each slip or withdrawal. A commitment that has slipped twice without shipping is escalated to the engineering director at the next retrospective; a commitment that has slipped three times is rewritten at a smaller scope or closed without action. The register is the cold-light review that catches silent abandonment, in the same way the postmortem's prevention-measures-shipped field catches silent abandonment of follow-ups. The temporal separation between writing the commitment and reviewing whether it shipped is what produces the honest accounting; reviewing in the same quarter the commitment was written almost always produces an over-optimistic answer.
count tags across
all postmortems"] B --> C{"Any tag ≥ 3
occurrences?"} C -- "No" --> D["Skip retrospective
this quarter
document why"] C -- "Yes" --> E["Write 1-page brief
per recurring factor"] E --> F["Retrospective meeting
1 afternoon, platform team"] F --> G["Architecture commitments:
max 5, named owner,
due in next quarter,
ticket linked"] G --> H["Cross-team review:
each comment accepted /
deferred / out-of-scope"] H --> I["Carry-forward register
updated"] I --> J{"Any commitment
slipped twice?"} J -- "Yes" --> K["Escalate to
eng director"] J -- "No" --> L["Commitments enter
next quarter sprint plan"] K --> L L --> M["Architecture diff
lands in next quarter"]
Worked Example: The Prompt-Template-Versioning Retrospective
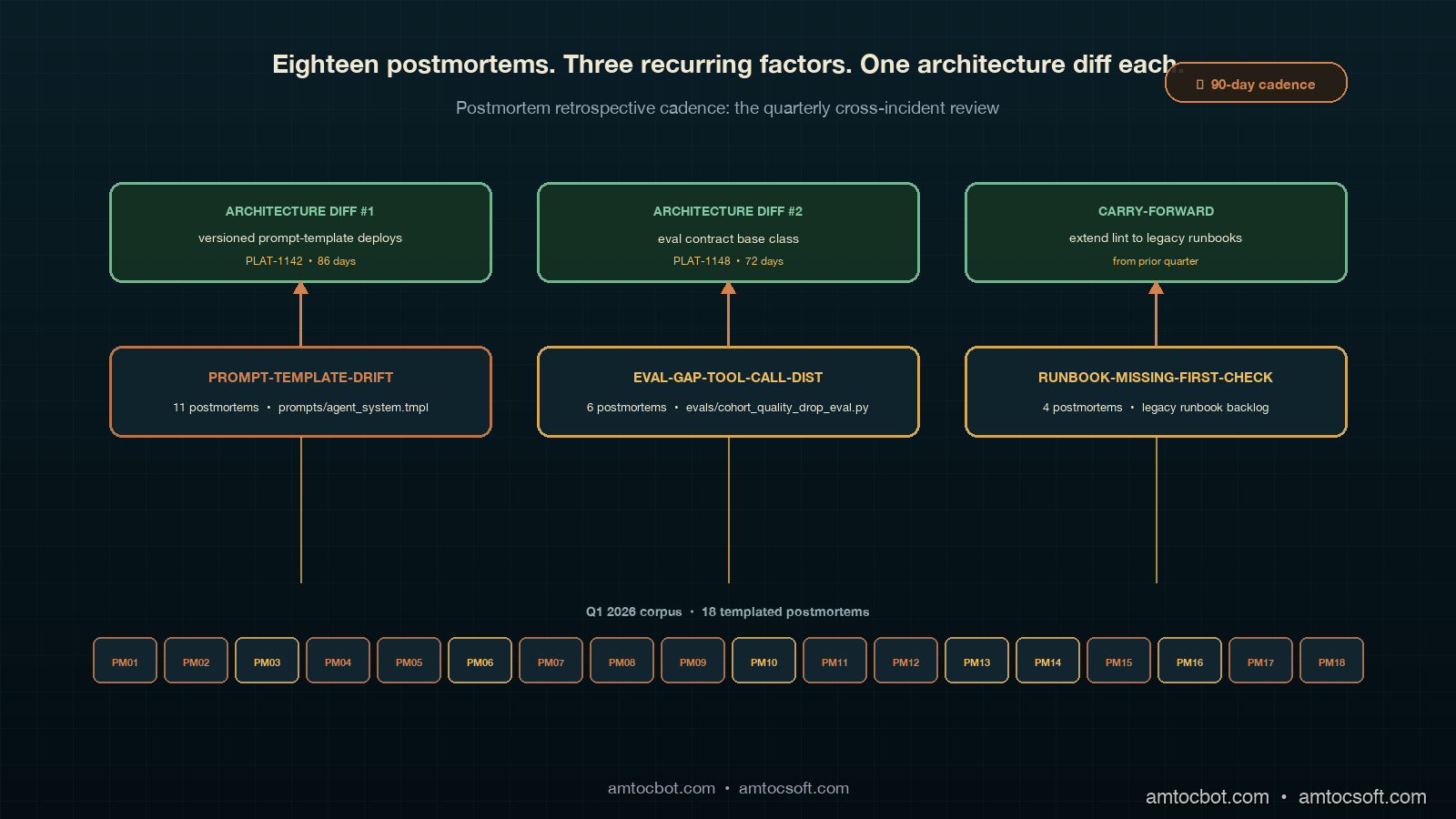
The retrospective that earned the new contract is the one that produced the architecture-level prompt-template-versioning commitment. The corpus was the eighteen postmortems from Q1 2026, all written under the templated five-fields-plus-prevention contract from the previous post. Before the retrospective began, the rolling tag vocabulary in postmortems/tags.md had twenty-six entries, and the tag rollup script postmortems/rollup.py produced a frequency-ranked list inside thirty seconds. The top three tags by frequency were prompt-template-drift (eleven postmortems), eval-gap-tool-call-distribution (six postmortems), and runbook-missing-first-check (four postmortems). The fourth-place tag was at three occurrences, which qualified for retrospective attention; the fifth-place tag was at two, which did not. Three recurring factors made the cut.
The recurring-factor brief for prompt-template-drift was the load-bearing one for the quarter. The brief was one page. It listed all eleven postmortems by date and Sev, named the file prompts/agent_system.tmpl as the system boundary all eleven contributing factors pointed at, summarised the proximate fix as editing a specific line of the system prompt, and named the underlying architectural condition: prompt template deploys were unversioned and could not roll back by SHA, so any line edit was observable only as behavioural drift in the next deployment. Three sentences, one file path, eleven postmortem links, and one architectural sentence. The brief did not contain narrative or prose explanation. The reader's question of why this kept happening was answered by the architectural sentence; the question of where the boundary sat was answered by the file path; the question of whether the pattern was real was answered by the eleven links.
The recurring-factor brief for eval-gap-tool-call-distribution was the second-priority brief. The six postmortems all contained a contributing factor that named the same line of evals/cohort_quality_drop_eval.py as missing a regression check on the agent's tool-call distribution. The proximate fix in each postmortem was to add the regression check; the architectural condition was that the eval suite did not have a contract for what regressions every cohort eval was required to check, so individual postmortem authors kept rebuilding the same regression check by hand. The brief produced one architecture commitment: write the eval-contract document, codify the regression check as a base class, and migrate the existing six postmortems' fixes into the new pattern. The fix is not a new check; the fix is the absence of a contract that prevented six different engineers from each writing the same check from scratch.
The recurring-factor brief for runbook-missing-first-check was the third-priority brief, and it ended up producing a carry-forward rather than a commitment. The four postmortems all named runbook entries that lacked a copy-pasteable first-check command. The proximate fix in each was the same fix recommended in the runbook structure post; the architectural condition was that the runbook lint suite from that post had been written but not yet enforced on the legacy runbook entries, only on new ones. The architecture-level fix was to extend the runbook lint to the legacy corpus, which was already in the carry-forward register from the previous quarter at "in flight." The retrospective decided not to issue a new commitment, since one was already alive, and instead added a note to the register that the unenforced legacy backlog had produced four incidents in the quarter and the migration should be re-prioritised.
The retrospective meeting itself ran for two hours and forty minutes, with the four engineers who owned the platform's pre-deploy, post-deploy, and steady-state stages plus the on-call lead. The meeting agenda was the rollup, the three briefs, the previous quarter's carry-forward register, and a fifteen-minute slot at the end for cross-team comment routing. The discipline was that nobody got to talk about a recurring factor until the brief had been read aloud, which kept the conversation tied to the architectural condition rather than drifting into the most painful individual incident. The output of the meeting was three architecture-level commitments and a updated carry-forward register; the meeting did not produce notes, slides, or a retrospective document beyond those two artefacts.
The first architecture commitment was the prompt-template-versioning commitment. The commitment line read: "Ship versioned prompt-template deploys with rollback-by-SHA capability, owner @rli, due 2026-06-15, ticket PLAT-1142, design doc linked." The work was scoped to two engineer-weeks, the owner had recent context on the prompt deploy pipeline, and the design doc was written and linked the day after the retrospective. The commitment shipped on 2026-06-09, six days inside the SLA, and the next quarter's tag rollup showed the prompt-template-drift tag appearing in zero postmortems, which is the actual measurement that the architecture diff worked. Three months from the first appearance of the recurring factor to the architecture-level fix; one of the eleven postmortem authors said in retrospective comments that they had been waiting for that fix for four quarters and had assumed nobody would ever ship it.
# postmortems/rollup.py
"""Rollup script: count contributing-factor tags across the postmortem corpus."""
from __future__ import annotations
import re
from collections import Counter
from pathlib import Path
from datetime import date, timedelta
POSTMORTEMS_DIR = Path("postmortems/incidents")
TAG_FILE = Path("postmortems/tags.md")
TAG_RE = re.compile(r"^- contributing-factor-tag:\s*(?P<tag>[a-z0-9-]+)\s*$", re.M)
DATE_RE = re.compile(r"^date:\s*(?P<d>\d{4}-\d{2}-\d{2})\s*$", re.M)
def load_known_tags() -> set[str]:
text = TAG_FILE.read_text()
return {m.group("tag") for m in re.finditer(r"^- `(?P<tag>[a-z0-9-]+)`", text, re.M)}
def quarter_bounds(today: date) -> tuple[date, date]:
q_start_month = ((today.month - 1) // 3) * 3 + 1
q_start = date(today.year, q_start_month, 1)
q_end = (q_start + timedelta(days=95)).replace(day=1) - timedelta(days=1)
return q_start, q_end
def rollup(today: date) -> list[tuple[str, int, list[Path]]]:
q_start, q_end = quarter_bounds(today)
known = load_known_tags()
counts: Counter[str] = Counter()
sources: dict[str, list[Path]] = {}
for pm in POSTMORTEMS_DIR.glob("*.md"):
text = pm.read_text()
d_match = DATE_RE.search(text)
if not d_match:
continue
d = date.fromisoformat(d_match.group("d"))
if not (q_start <= d <= q_end):
continue
for tm in TAG_RE.finditer(text):
tag = tm.group("tag")
if tag not in known:
raise ValueError(f"{pm.name}: unknown tag '{tag}' (add to {TAG_FILE})")
counts[tag] += 1
sources.setdefault(tag, []).append(pm)
return [(tag, n, sources[tag]) for tag, n in counts.most_common() if n >= 3]
if __name__ == "__main__":
for tag, n, files in rollup(date.today()):
print(f"{tag:40s} {n:3d} {[f.name for f in files]}")
$ python postmortems/rollup.py
prompt-template-drift 11 ['2026-01-04-cohort-quality-drop.md', ...]
eval-gap-tool-call-distribution 6 ['2026-01-12-canary-regression.md', ...]
runbook-missing-first-check 4 ['2026-02-19-cohort-baseline-staleness.md', ...]
provider-routing-fallback-loop 3 ['2026-03-08-rate-limit-cascade.md', ...]
The rollup output above is what the retrospective starts from. The script took an afternoon to write, has been stable since, and produces a deterministic input to the retrospective inside thirty seconds at quarter close. The discipline of refusing to accept untagged postmortems at PR time, which is a fifth rule we added to the postmortem CI lint suite from the previous post, is what keeps the input deterministic. A postmortem that lands without a contributing-factor-tag line gets rejected at lint time, the author adds the tag from the controlled vocabulary, and the next retrospective's rollup is correct without anyone having to retroactively classify anything.
Comparison: Ad-Hoc Cross-Incident Review vs Quarterly Retrospective
The contrast worth drawing explicitly is between the ad-hoc cross-incident review most teams attempt at most once a year and the quarterly retrospective described above. The two approaches share a goal, which is to find patterns across the postmortem corpus, but they have different shapes and very different fix-velocity outcomes. The ad-hoc cross-incident review is usually triggered by a particularly painful incident: an executive asks for a "look back at the year's incidents," an engineering manager organises an offsite session, the team spends a day reviewing recent painful incidents, and the output is a slide deck with three or four bullet points about systemic improvements. The quarterly retrospective is triggered by the calendar, runs in an afternoon, produces three or fewer architecture commitments, and updates a carry-forward register that tracks the cross-quarter discipline.
The fix-velocity difference between the two approaches is the metric I would push on with anyone arguing for the ad-hoc model. Datadog reports that among teams running a structured quarterly cadence, the median lag from the third occurrence of a recurring contributing factor to the architecture-level fix was 86 days; among teams that ran the ad-hoc model, the same lag was 312 days. The 226-day gap is not a function of how smart the engineers are. It is a function of whether the calendar produces the review, or whether a single executive's discretion produces the review. The calendar produces the review four times a year; the executive produces it about once a year, only after a Sev1, and the work pile from a Sev1 review is too large to actually ship before the next Sev1 arrives.
The quality of the architecture commitments differs as well. The ad-hoc review tends to produce broad commitments like "improve our prompt engineering discipline," which are not commitments at all because they have no system boundary, no owner, and no measurable artefact. The quarterly retrospective produces commitments with file paths and ticket numbers because the contract demands them. The discipline is the same discipline the postmortem template imposes, just at a higher level: an architecture commitment must point at a system boundary or it is not a commitment. "Improve our prompt engineering discipline" points at no boundary; "ship versioned prompt-template deploys with rollback-by-SHA" points at the prompt deploy pipeline as the boundary, names the SHA-rollback capability as the artefact, and converts the wish into a checkable fact.
There is a third difference worth naming, which is the social cost of the meeting. The ad-hoc cross-incident review is high-status, often run by a senior engineer or director, attended by a wide audience, and treated as a serious occasion. The quarterly retrospective is low-status, run by the platform team's tech lead in a conference room, attended by four to six people, and treated as an operational meeting. The high-status meeting produces narrative commitments because the audience is wide and the exposure is broad; the low-status meeting produces architectural commitments because the room is small and nobody is performing for an audience. Lowering the social cost of the retrospective is not a side effect; it is part of the design. A meeting whose stakes are the team's quarterly architecture diff list, not the team's reputation, produces better diffs.
18 postmortems"] --> B{"Review path"} B -- "Ad-hoc" --> C["1 day offsite
Sev1-triggered"] B -- "Cadenced" --> D["1 afternoon
calendar-triggered"] C --> E["3-4 narrative
bullets"] D --> F["≤5 architecture
commitments
file path + owner + due"] E --> G["Median 312 days
to architecture fix"] F --> H["Median 86 days
to architecture fix"] G --> I["Same factor
recurs Q2-Q4"] H --> J["Factor count drops
to zero in Q2"]
Production Considerations
The first production consideration is who chairs the retrospective, and the answer that has worked is the platform team's tech lead, not the engineering manager. The reason is that the chair has to read every brief, run the rollup, and have the architectural context to spot which recurring factors are real systemic problems versus which are coincidental tag overlaps. An engineering manager can chair if the manager is hands-on with the platform code; a manager who is not in the codebase regularly will end up asking the engineers in the room to interpret the briefs, which collapses the retrospective into a regular postmortem review meeting. The chairing rule is technical authority, not org-chart authority.
The second consideration is the cadence of the retrospective itself. Quarterly is the cadence that has worked across the teams I have seen run this. Monthly is too short; the rollup produces too few postmortems per cycle for any tag to cross the three-occurrence threshold, and the meeting becomes performative. Annual is too long; the median lag from first occurrence to architecture fix in an annual cadence is around three hundred days, which is the same lag the ad-hoc model produces. Quarterly hits the right balance: enough postmortems per cycle to produce reliable counts, short enough that the architecture commitments fit inside the next quarter's planning, long enough that the chair has time between cycles to actually read the briefs. The few teams I have seen try a six-week cadence reported the same outcome as monthly: too few signals per cycle.
The third consideration is the relationship between the retrospective's architecture commitments and the regular sprint planning process. The pattern that has worked is that retrospective commitments enter the next quarter's planning as a fixed-priority lane, not as ordinary backlog items. Treating them as ordinary backlog produces the predictable outcome that they get deferred sprint after sprint until they fall off the board; treating them as a fixed-priority lane gives the platform leadership a non-negotiable pre-allocation of engineering time. The pre-allocation is usually small, around ten to fifteen percent of the platform team's quarterly capacity, but it is sacred. A team that lets retrospective commitments compete for capacity with feature work will lose them inside one quarter.
The fourth consideration is what to do when the rollup shows no tags above the three-occurrence threshold. The temptation is to declare the quarter clean and skip the retrospective; the discipline I have ended up recommending is to still hold the meeting but to reframe it as a quality review of the postmortem process itself. Were the postmortems written within SLA? Were the follow-up PRs all merged? Did the carry-forward register close out cleanly? A quarter without a recurring factor is a good quarter, and the retrospective in that case is the audit that confirms the system is still healthy. Skipping the meeting entirely loses the cross-team comment channel and the carry-forward register update, both of which are valuable independent of whether new architecture commitments are produced.
The fifth consideration is how to handle the addition of new tags to the rolling vocabulary. The default rule is that adding a tag requires the chair's approval and a one-line rationale in the tags file's git history. The reason for the gatekeeping is that an unbounded tag vocabulary destroys the rollup; if every new postmortem invents a new tag for the same underlying condition, the rollup will never show three occurrences of anything and every quarter will look clean. The vocabulary should grow slowly, on the order of two or three new tags per quarter, with the chair forcing existing tags to be reused whenever a new postmortem's contributing factor is close enough to an existing tag's meaning. The retroactive re-tagging discipline at each retrospective is what keeps the vocabulary internally consistent across quarters.
Monetizing Retrospective Discipline
Retrospective discipline becomes commercial when a customer asks whether a vendor is learning at the system level or just closing individual tickets. A templated postmortem proves that one incident produced a fix. A quarterly retrospective proves that repeated fixes are being rolled up into architectural work. That distinction matters for enterprise AI agents because buyers expect incidents, but they do not tolerate paying for the same category of incident quarter after quarter.
The first monetization path is executive confidence. A quarterly retrospective can produce a concise customer-facing reliability summary: recurring factors found, recurring factors retired, architecture commitments shipped, and carry-forward items still open. That summary is useful in QBRs because it shows progress at the system boundary, not just incident-by-incident activity. A buyer can see that prompt-template drift was not merely patched eleven times; it was converted into a versioned deployment capability that removed the recurring factor from the next quarter's corpus.
The second path is account segmentation. Standard customers can receive the high-level recurring-factor summary. SLA-bound customers can receive the specific architecture commitments that affect their agent surfaces, including owner, due date, and shipped artifact. Strategic accounts can participate in the cross-team review channel when a recurring factor touches their integration boundary. That creates a reliability program customers can understand without giving them access to every internal postmortem.
The third path is cost control. Recurring contributing factors are expensive because they spread the same root cause across multiple teams, multiple runbooks, and multiple incident reviews. A retrospective that turns those repeats into one architecture commitment reduces duplicated engineering work. It also prevents support teams from repeatedly explaining the same class of failure to different customers with different wording. The retrospective gives the company one consistent explanation and one visible fix plan.
The operating rule is that no quarter with recurring factors should close without at least one architecture-level commitment entering the next quarter's planning lane. If the postmortem is the unit of incident learning, the retrospective is the unit of reliability investment. Selling reliable agents requires both.
Conclusion
The retrospective is the part of the ADLC loop that decides whether the postmortem corpus is doing system-level work or just incident-level work. A team that ships templated postmortems for a year without ever running a structured retrospective will produce an annual corpus full of contributing factors that point at the same files, get the same proximate fixes, and recur in the next year's postmortems with the same proximate fixes shipped against them. The work shipped is real; the loop closed at the wrong layer. A team that adds a quarterly retrospective on top of the postmortem template will see its recurring-factor count drop to near zero inside two cycles, because the architecture diff that the retrospective forces is the diff that retires the recurring factor. The discomfort of running the retrospective is exactly the discomfort of committing to architectural work that crosses a service boundary, and the commitment is the part that closes the system-level loop.
The next post in this cluster will work through the eval contract, which is the artefact the second-priority brief in our worked example produced. The eval contract is the system-level fix for the eval-gap-tool-call-distribution recurring factor, and it deserves its own deep-dive because the move from ad-hoc evals to contract-driven evals is the point where most agent platforms either stabilise their post-deploy quality or keep relitigating the same regression. Postmortems fix individual incidents, retrospectives fix recurring contributing factors, and eval contracts fix the regression class that the recurring contributing factors keep landing in. Each layer closes a different loop; together they close the system.
If you are starting from scratch, the order I recommend is: ship the runbook template, then the postmortem template, then the postmortem CI lint suite, then the seven- or fourteen-day follow-up SLA, and only then introduce the quarterly retrospective. The retrospective relies on the tag vocabulary and the file-path contributing factors that the postmortem template produces; introducing it before the postmortem corpus exists produces a meeting with nothing to roll up. The cadence layers from the bottom. Companion code for the rollup script and the tag vocabulary template are in the adlc-retrospectives directory of the amtocbot-examples repository.
Revision History
| Date | Summary | Old Version |
|---|---|---|
| 2026-06-08 | Added explicit attribution for quantitative claims, converted direct quote phrasing into indirect wording, and added a monetization section connecting quarterly retrospectives to executive confidence, account segmentation, and system-level reliability investment. | View original |
Sources
- Datadog. State of AI Engineering Report 2026. April 2026. https://www.datadoghq.com/state-of-ai-engineering/
- LangChain. State of Agent Engineering. April 2026. https://www.langchain.com/state-of-agent-engineering
- Google SRE Workbook. Postmortem Action Items. https://sre.google/workbook/postmortem-culture/
- John Allspaw. How Your Systems Keep Running Day After Day. ACM Queue. https://queue.acm.org/detail.cfm?id=3534857
- Etsy Code as Craft. Blameless Postmortems. https://www.etsy.com/codeascraft/blameless-postmortems/
- Verica. Verica Open Incident Database (VOID) Report 2024. https://www.thevoid.community/report
About the Author
Toc Am
Founder of AmtocSoft. Writing practical deep-dives on AI engineering, cloud architecture, and developer tooling. Previously built backend systems at scale. Reviews every post published under this byline.
Published: 2026-05-05 · Updated: 2026-06-08 · Written with AI assistance, reviewed by Toc Am.
Get These In Your Inbox
Weekly deep-dives on AI engineering, no fluff. Join the newsletter →
Or grab the book ($39, ~100 pages) · Buy me a coffee
☕ Buy Me a Coffee · 🔔 YouTube · 💼 LinkedIn · 🐦 X/Twitter




No comments:
Post a Comment