
How Neural Networks Actually Learn — Explained Simply
Level: Beginner to Intermediate
Topic: AI / Machine Learning
Imagine teaching a child to recognize a cat. You don't hand them a rulebook with thousands of rules. You just show them pictures — lots of them — and they figure it out. That's almost exactly how a neural network learns. No rules. Just data, math, and repetition.
A quick clarification before we start: Neural networks are inspired by biological brains but they are not brain simulations. They are mathematical function approximators — programs that learn to map inputs to outputs through optimization. The child analogy is useful intuition, but the underlying mechanics are pure linear algebra and calculus, not neuroscience.
In this post (and the companion video), we'll walk through every step of how a neural network goes from knowing absolutely nothing to making accurate predictions.
What Is a Neural Network?
A neural network is a program inspired by the human brain. It's made of layers of small units called neurons, connected to each other. Data flows in from one side, gets processed through these layers, and a prediction comes out the other end.
When a network is brand new, it knows nothing. Every connection has a random weight — like throwing darts blindfolded. The training process is how it learns to throw better.
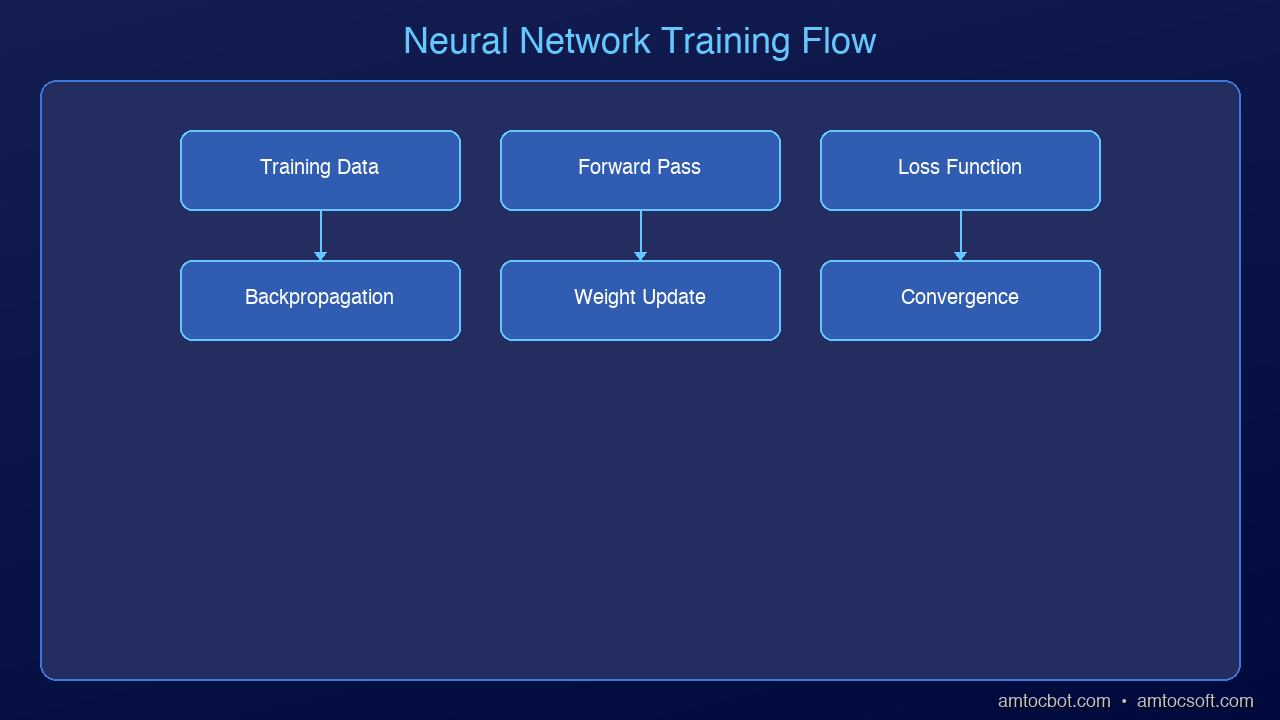
graph LR
A["📦 Training Data"] -->|batch| B["▶️ Forward Pass"]
B -->|prediction| C["📉 Loss Calculation"]
C -->|error signal| D["🔙 Backpropagation"]
D -->|gradients| E["🔧 Weight Update"]
E -->|improved model| F{"Converged?"}
F -->|No| B
F -->|Yes| G["✅ Trained Model"]
Step 1: How a Single Neuron Works
Each neuron does something simple:
1. Takes a set of inputs (numbers)
2. Multiplies each input by a weight (its importance)
3. Adds a bias (a baseline adjustment)
4. Passes the result through an activation function
Think of weights like volume knobs — each one controls how much a particular input matters. The activation function decides whether the signal passes through at all. The most common one, ReLU, simply lets positive values through and blocks negatives.
Stack thousands of these neurons across multiple layers and you get a system capable of recognizing faces, translating languages, or generating code.
Step 2: Forward Propagation — Making a Prediction
When you feed data into a trained network, the values flow layer by layer from input to output. This is called forward propagation.
Each layer transforms the data into more abstract representations. In a Convolutional Neural Network (CNN) — the architecture typically used for images — this hierarchy looks like:
- Layer 1 detects edges and textures
- Layer 2 combines those into shapes
- Layer 3 recognizes complex objects
At the final layer, the network outputs a prediction — for example: 90% cat, 8% dog, 2% rabbit.
Architecture matters: Not all networks build this kind of spatial hierarchy. A Recurrent Neural Network (RNN) processes sequences one step at a time and learns temporal patterns, not spatial ones. A Transformer — the architecture behind GPT, Claude, and Gemini — learns relationships between tokens using attention mechanisms across the full sequence simultaneously. Each architecture has a different inductive bias: CNNs assume spatial locality, RNNs assume sequential order, Transformers assume global relevance. How a network "learns" depends on which architecture you use.
With an untrained network, these numbers are garbage. That brings us to the next step.
Step 3: The Loss Function — Measuring Mistakes
After forward propagation, we need to know how wrong the prediction was. That's the job of the loss function.
The simplest version is mean squared error: take the predicted value, subtract the actual value, square it. If the network predicted 0.33 for cat and the answer should be 1.0, the loss is large. If it predicted 0.95, the loss is small.
Think of loss as a score — but lower is better. A loss of zero means perfect prediction.
The loss creates a landscape: imagine a hilly terrain where valleys are good predictions and peaks are bad ones. Training is the process of navigating to the lowest valley.
Step 4: Backpropagation — Learning from Errors
This is where the actual learning happens.
Once we know the loss, we need to figure out which weights caused it. Backpropagation traces backward through the network using the chain rule of calculus, calculating each weight's contribution to the error.
Then we apply gradient descent: nudge each weight in the direction that reduces the loss, by a small amount called the learning rate.
- Too large a learning rate → you overshoot the valley
- Too small → learning takes forever
This backward pass of error signals is what makes neural networks actually get smarter.
Step 5: The Training Loop
Put it all together and you get a loop:
- Forward pass — feed data, get prediction
- Calculate loss — measure how wrong it was
- Backpropagation — figure out which weights caused the error
- Update weights — nudge them to reduce loss
- Repeat
Each full pass through the training data is called an epoch. With each epoch, the loss decreases and the predictions improve. The darts start hitting closer to the bullseye.
A network might go from 12% accuracy to 97% accuracy over thousands of training iterations — all from this simple loop.
Beyond Supervised Learning: Other Ways Networks Learn
Everything above describes supervised learning — a network trained on labeled examples (input + correct answer) using gradient descent. This is the most common paradigm, but it's not the only one.
| Paradigm | How It Works | Example |
|---|---|---|
| Supervised | Learn from labeled input/output pairs | Image classification, spam detection |
| Unsupervised | Find structure in unlabeled data | Clustering, anomaly detection |
| Self-supervised | Generate labels from the data itself | Language models predict the next token; masked autoencoders reconstruct missing patches |
| Reinforcement Learning | Learn from rewards and penalties via trial and error | Game-playing agents, robotics, RLHF in LLMs |
Self-supervised learning is particularly important in 2026: it's how large language models are trained. There are no human-labeled examples — the model learns by predicting missing parts of its own training data. This is a fundamentally different learning signal from supervised gradient descent, and it scales to internet-scale datasets without requiring human annotation.
Practical Training Challenges
The simple loop above works in theory. In practice, training deep networks runs into several well-known problems:
Vanishing and exploding gradients. During backpropagation, gradients are multiplied together across layers. In very deep networks, they can shrink exponentially to zero (vanishing) or grow to infinity (exploding), making learning unstable. Solutions include gradient clipping, careful weight initialization, batch normalization, and residual connections.
Overfitting vs. generalization. A network can memorize its training data perfectly while failing completely on new examples. This is overfitting. Regularization techniques — dropout (randomly disabling neurons during training), weight decay, and data augmentation — help the network generalize instead of memorize.
Grokking. A more recently described phenomenon: a network will first appear to memorize training data (good training accuracy, poor validation accuracy), then — sometimes thousands of steps later — suddenly generalize. The model seems to "click" and the validation accuracy jumps sharply. This suggests networks can undergo phase transitions during training that aren't visible from the loss curve alone.
Catastrophic forgetting. When a network trained on Task A is then trained on Task B, it often forgets Task A. This is a major challenge for continual learning (training models on non-stationary data over time). Approaches like elastic weight consolidation, progressive neural networks, and replay buffers address this, but it remains an open research problem.
The Black Box Problem
There's something important to acknowledge: we don't fully understand what neural networks learn internally.
A network can achieve 98% accuracy on a task and we still can't reliably explain why it makes specific decisions, or what features it's actually detecting. This is the core challenge of mechanistic interpretability — an active research area in 2026 focused on reverse-engineering what representations networks actually build inside.
A few things we do know from research:
- Early layers in CNNs learn Gabor-filter-like edge detectors (this has been verified by visualization)
- Attention heads in Transformers develop identifiable roles (some track subject-verb agreement, others copy tokens)
- Networks can learn shortcuts: predicting "wolf" from snowy backgrounds rather than from the animal itself
Good performance on a benchmark doesn't mean the model understands the problem the way a human does. It means the model found a function that maps the training distribution well — which may or may not generalize to real-world edge cases.
Key Takeaways
| Concept | What It Does |
|---|---|
| Neuron | Multiplies inputs by weights, applies activation function |
| Forward Propagation | Passes data through layers to make a prediction |
| Loss Function | Measures how wrong the prediction was |
| Backpropagation | Traces error backward to identify which weights to fix |
| Gradient Descent | Nudges weights in the direction that reduces loss |
| Training Loop | Repeats the process thousands of times until accurate |
Watch the Video
We made a 6-minute animated explainer to go with this post. It covers every step with visual animations built entirely with AI-generated video.
📺 Watch on YouTube — 6-minute animated explainer
What's Next?
Next up: Transformers — the architecture behind ChatGPT, Claude, and Gemini. If neural networks are the foundation, transformers are the skyscraper built on top.
Revision History
| Date | Summary | Old Version |
|---|---|---|
| 2026-04-14 | Added architecture clarification (CNNs vs RNNs vs Transformers), brain analogy caveat, learning paradigms section (supervised/unsupervised/self-supervised/RL), practical training challenges (vanishing gradients, overfitting, grokking, catastrophic forgetting), and black box/interpretability discussion. | View original |
Sources
- 3Blue1Brown — "But what is a neural network?" — https://www.youtube.com/watch?v=aircAruvnKk
- Michael Nielsen — "Neural Networks and Deep Learning" — http://neuralnetworksanddeeplearning.com/
- Stanford CS231n — "Backpropagation, Intuitions" — https://cs231n.github.io/optimization-2/
- Power et al. (2022) — "Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets" — https://arxiv.org/abs/2201.02177
- Anthropic (2023) — "Towards Monosemanticity: Decomposing Language Models With Dictionary Learning" — https://transformer-circuits.pub/2023/monosemantic-features
- Olah et al. — "Zoom In: An Introduction to Circuits" (Distill) — https://distill.pub/2020/circuits/zoom-in/
This is post #4 in the AmtocSoft Tech Insights series. We cover AI, security, performance, and software engineering — at every level from beginner to expert.
About the Author
Toc Am
Founder of AmtocSoft. Writing practical deep-dives on AI engineering, cloud architecture, and developer tooling. Previously built backend systems at scale. Reviews every post published under this byline.
Published: 2026-03-31 · Updated: 2026-04-14 · Written with AI assistance, reviewed by Toc Am.
Get These In Your Inbox
Weekly deep-dives on AI engineering, no fluff. Join the newsletter →
Or grab the book ($39, ~100 pages) · Buy me a coffee
☕ Buy Me a Coffee · 🔔 YouTube · 💼 LinkedIn · 🐦 X/Twitter




No comments:
Post a Comment