
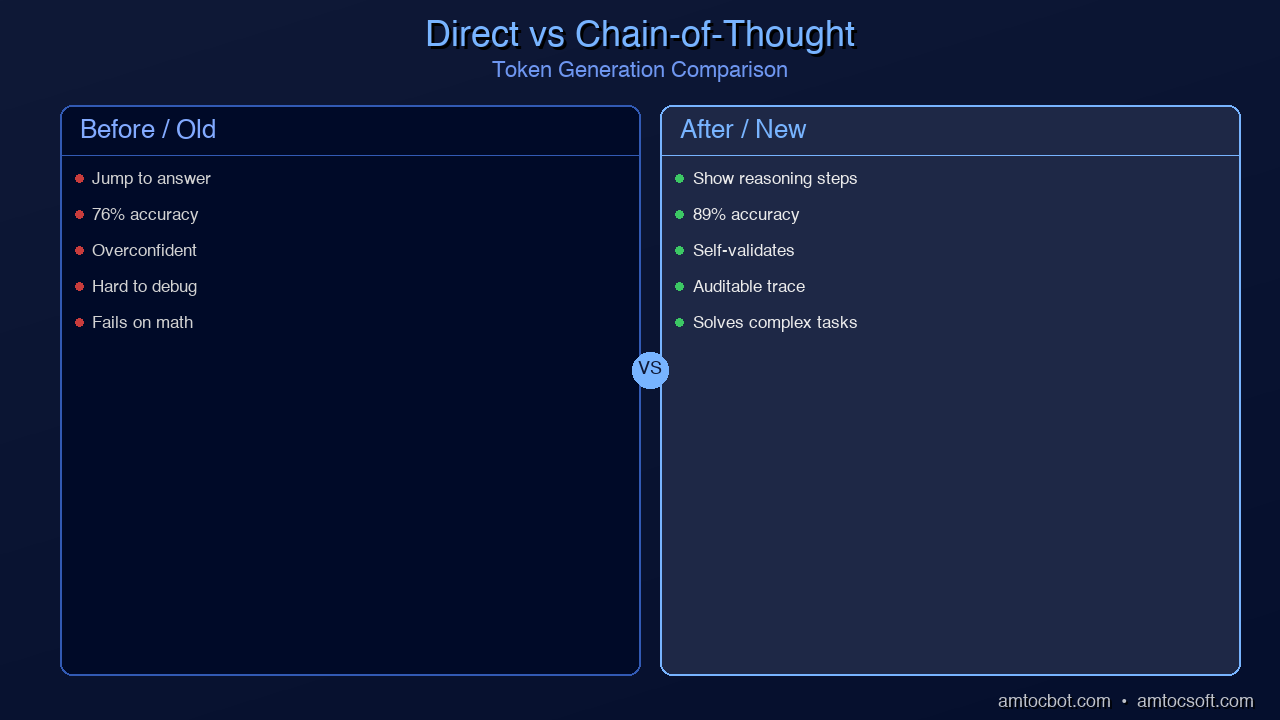
Ask an LLM "What is 47 times 83?" and it might get the wrong answer. Ask it "What is 47 times 83? Think through this step by step" and it almost always gets it right. That four-word addition — "think through this step by step" — is one of the most important discoveries in prompt engineering history.
This technique is called Chain-of-Thought (CoT) prompting, and it works because it forces the model to generate intermediate reasoning steps before arriving at a final answer. Instead of jumping straight from question to conclusion, the model "shows its work," and those intermediate tokens actually improve the quality of the final output.
Chain-of-Thought prompting transformed what LLMs can do. Problems that seemed beyond the reach of language models — multi-step math, logical reasoning, complex code debugging, strategic planning — became solvable when researchers at Google discovered that simply asking for step-by-step reasoning could improve accuracy by 30-70% on reasoning benchmarks.
In this second part of our Prompt Engineering Deep-Dive series, we'll explore how Chain-of-Thought prompting works, when to use it (and when NOT to), and how to implement it effectively in your applications.
The Problem: Why LLMs Struggle with Reasoning
Language models generate text by predicting the next token based on all previous tokens. This works brilliantly for many tasks — summarization, translation, creative writing, code generation. But it creates a fundamental limitation for reasoning tasks.
Consider this problem:
A store sells apples for $2 each and oranges for $3 each. Sarah buys 4 apples and 3 oranges. She pays with a $20 bill. How much change does she get?
Without Chain-of-Thought:
Answer: $3
With Chain-of-Thought:
Let me work through this step by step:
1. Cost of apples: 4 × $2 = $8
2. Cost of oranges: 3 × $3 = $9
3. Total cost: $8 + $9 = $17
4. Change from $20: $20 - $17 = $3
Answer: $3
Both arrive at $3 in this simple case. But as problem complexity increases, the non-CoT approach fails rapidly while CoT maintains accuracy. This is because the model needs those intermediate calculations to exist as tokens it can reference when generating subsequent steps.
The key insight: LLMs don't have a hidden "scratchpad" for computation. The only working memory available is the sequence of tokens already generated. Chain-of-Thought prompting creates that scratchpad explicitly in the output.
(often wrong)"] D1 --> D2 --> D3 end subgraph COT ["Chain-of-Thought Prompting"] direction TB C1["Input: Complex problem
+ 'Think step by step'"] C2["Step 1: Identify variables"] C3["Step 2: Apply operations"] C4["Step 3: Check logic"] C5["Output: Final answer
(usually correct)"] C1 --> C2 --> C3 --> C4 --> C5 end style D1 fill:#3498db,stroke:#2980b9,color:#fff style D2 fill:#e74c3c,stroke:#c0392b,color:#fff style D3 fill:#e74c3c,stroke:#c0392b,color:#fff style C1 fill:#3498db,stroke:#2980b9,color:#fff style C2 fill:#2ecc71,stroke:#27ae60,color:#fff style C3 fill:#2ecc71,stroke:#27ae60,color:#fff style C4 fill:#2ecc71,stroke:#27ae60,color:#fff style C5 fill:#2ecc71,stroke:#27ae60,color:#fff style DIRECT fill:#1a1a2e,stroke:#e74c3c,color:#fff style COT fill:#1a1a2e,stroke:#2ecc71,color:#fff
How Chain-of-Thought Prompting Works
There are three primary variants of CoT prompting, each with different tradeoffs:
1. Zero-Shot CoT
The simplest form. Just append "Let's think step by step" (or similar) to your prompt.
Prompt: "A developer pushes code that passes all unit tests but
breaks integration tests in staging. The error log shows a timeout
on database connections. What's the most likely cause and how would
you debug it? Let's think through this step by step."
When to use: Quick one-off questions, situations where you don't have examples.
Effectiveness: Improves reasoning accuracy by 20-40% on most tasks compared to direct prompting.
2. Few-Shot CoT
Provide examples that demonstrate the reasoning process before asking your actual question.
Example 1:
Q: A REST API returns 200 but the response body is empty.
The endpoint worked yesterday. What happened?
A: Let me think through possible causes:
1. The data source: Something changed in the database —
records deleted, table renamed, query returning empty results
2. The code path: A recent deployment changed the serialization
logic — maybe a null check now returns early
3. The API layer: Caching layer returning stale/empty response
4. Most likely: Recent deployment changed a query or filter
condition. Check git log for changes to this endpoint in
the last 24 hours, then check database directly.
Now your question:
Q: A microservice is responding with 503 errors intermittently —
about 10% of requests fail. CPU and memory look normal.
What's happening?
When to use: When you need consistent reasoning quality and have representative examples.
Effectiveness: Improves accuracy by 40-70% on complex reasoning tasks — significantly better than zero-shot.
3. Automatic CoT (Auto-CoT)
For production applications, you can build CoT into your system prompt so every response includes reasoning:
System prompt: "You are a debugging assistant. For every problem
presented:
1. List the known facts
2. Identify what's missing or unclear
3. Generate 3 hypotheses ranked by likelihood
4. For the top hypothesis, outline the debugging steps
5. State your conclusion with confidence level
Always show your reasoning before giving a final answer."
When to use: Applications where consistent reasoning format is required.
Effectiveness: Varies, but ensures every response includes explicit reasoning.
The Science Behind Why CoT Works
The 2022 paper "Chain-of-Thought Prompting Elicits Reasoning in Large Language Models" by Wei et al. at Google Brain demonstrated the effect across multiple benchmarks. But why does it actually work?
Theory 1: Computational Depth
Without CoT, the model must solve the entire problem in a single "forward pass" through the transformer network. The number of sequential computation steps is fixed by the model's depth (number of layers). CoT effectively allows the model to perform multiple sequential forward passes — each generated token feeds back as context, creating an unbounded computation loop.
Theory 2: Decomposition
Complex problems require decomposing into sub-problems. By generating intermediate steps, the model converts one hard problem into several easy ones. Each step is a simple enough task that the model can solve it accurately with a single forward pass.
Theory 3: Error Correction
When reasoning is explicit, the model can "see" its own intermediate results and correct them. If step 2 produces a value that contradicts step 1, the model can catch and fix the inconsistency — but only if both steps are visible in the token sequence.
= additional compute step"] DD1 -->|"CoT unlocks"| DD2 end subgraph DECOMP ["Problem Decomposition"] DC1["1 hard problem"] DC2["N easy sub-problems"] DC1 -->|"CoT breaks into"| DC2 end subgraph CORRECT ["Error Visibility"] EC1["Hidden reasoning
= hidden errors"] EC2["Visible reasoning
= catchable errors"] EC1 -->|"CoT surfaces"| EC2 end end DEPTH --> RESULT["Higher accuracy on
reasoning tasks"] DECOMP --> RESULT CORRECT --> RESULT style DD1 fill:#e74c3c,stroke:#c0392b,color:#fff style DD2 fill:#2ecc71,stroke:#27ae60,color:#fff style DC1 fill:#e74c3c,stroke:#c0392b,color:#fff style DC2 fill:#2ecc71,stroke:#27ae60,color:#fff style EC1 fill:#e74c3c,stroke:#c0392b,color:#fff style EC2 fill:#2ecc71,stroke:#27ae60,color:#fff style RESULT fill:#6C63FF,stroke:#8B83FF,color:#fff style DEPTH fill:#16213e,stroke:#6C63FF,color:#fff style DECOMP fill:#16213e,stroke:#6C63FF,color:#fff style CORRECT fill:#16213e,stroke:#6C63FF,color:#fff style WHY fill:#1a1a2e,stroke:#6C63FF,color:#fff
When Chain-of-Thought Helps (and When It Doesn't)
CoT is not universally beneficial. Understanding when it helps — and when it hurts — is critical for using it effectively.
CoT Helps Most With:
| Task Type | Improvement | Example |
|---|---|---|
| Multi-step math | 40-70% | Word problems, calculations |
| Logical reasoning | 30-60% | Syllogisms, constraint satisfaction |
| Code debugging | 25-50% | Finding bugs, trace analysis |
| Strategic planning | 20-40% | Architecture decisions, tradeoff analysis |
| Complex classification | 15-30% | Multi-factor decisions, edge cases |
CoT Doesn't Help (or Hurts) With:
| Task Type | Impact | Why |
|---|---|---|
| Simple factual recall | No change / negative | "What's the capital of France?" doesn't need reasoning steps |
| Creative writing | Negative | Step-by-step reasoning makes creative output formulaic |
| Translation | No change | Direct mapping doesn't benefit from decomposition |
| Simple classification | Negative | Binary yes/no decisions get overthought |
| Summarization | No change | Compression isn't a reasoning task |
Rule of thumb: If a task requires combining multiple pieces of information or applying multiple logical steps, CoT helps. If it's a direct lookup or a creative task, skip it.
Implementing CoT in Production
Pattern 1: Hidden CoT (Think Then Answer)
In many applications, you want the reasoning but don't want to show it to the user. Structure your prompt to separate thinking from response:
system_prompt = """You are a customer support classifier.
For each message:
1. THINKING (not shown to user):
- Identify the customer's emotion (angry, confused, neutral, happy)
- Determine the issue category
- Assess urgency (low, medium, high, critical)
- Check if escalation is needed
2. RESPONSE (shown to user):
Return JSON only:
{"category": "...", "urgency": "...", "escalate": bool,
"suggested_response": "..."}
"""
# In your application code, extract only the JSON from the response
import re
def extract_response(model_output: str) -> dict:
json_match = re.search(r'\{.*\}', model_output, re.DOTALL)
if json_match:
return json.loads(json_match.group())
Some APIs support this natively. Anthropic's Claude has an "extended thinking" feature where the model reasons in a separate, dedicated thinking block before generating its response — you get the accuracy benefits of CoT without the reasoning tokens cluttering the output.
Pattern 2: Structured CoT for Consistency
When you need consistent reasoning across many inputs, enforce a specific reasoning structure:
system_prompt = """You are a code review assistant.
For each code change, follow this exact reasoning process:
## Analysis Framework
1. **UNDERSTAND**: What does this code do? (1-2 sentences)
2. **SECURITY**: Any injection, auth, or data exposure risks?
Check against OWASP Top 10.
3. **PERFORMANCE**: Any O(n²) loops, missing indexes, N+1 queries?
4. **CORRECTNESS**: Any logic errors, off-by-one, null handling issues?
5. **VERDICT**: APPROVE, REQUEST_CHANGES, or NEEDS_DISCUSSION
Show your reasoning for each step, then give the verdict.
"""
Pattern 3: CoT with Self-Verification
Add a verification step where the model checks its own reasoning:
After completing your analysis, perform a self-check:
- Re-read your reasoning. Does each step logically follow
from the previous one?
- Does your conclusion match your intermediate findings?
- Are there any assumptions you made that should be stated
explicitly?
- Rate your confidence: HIGH (>90%), MEDIUM (60-90%),
LOW (<60%)
If confidence is LOW, explain what additional information
would increase it.
This catches a surprising number of errors. The model frequently corrects itself during the verification step — sometimes catching mistakes that would have been invisible in a direct response.
CoT Anti-Patterns to Avoid
Anti-Pattern 1: Forcing CoT on Simple Tasks
# DON'T do this
prompt = "What programming language is this file written in? " \
"Think step by step and analyze the syntax carefully."
# The file has a .py extension and "import pandas" on line 1.
# CoT here just wastes tokens.
# DO this instead
prompt = "What programming language is this file written in?"
Anti-Pattern 2: Unconstrained Reasoning
# DON'T do this
prompt = "Debug this error. Think about all possible causes."
# The model will generate 2,000 words exploring every
# conceivable scenario.
# DO this instead
prompt = "Debug this error. List the 3 most likely causes, " \
"ranked by probability. For the top cause, provide " \
"the fix."
Anti-Pattern 3: CoT Without Structure
# DON'T do this
prompt = "Think step by step about whether we should use " \
"microservices or a monolith."
# You'll get a wandering essay with no clear conclusion.
# DO this instead
prompt = """Evaluate microservices vs monolith for our use case.
Structure your analysis:
1. List our constraints: [team size: 4, traffic: 1K req/s,
deployment: weekly]
2. Score each option (1-10) on: development speed,
operational complexity, scalability, team fit
3. Recommend one option with the decisive factor.
"""
Advanced CoT Techniques
Self-Consistency (CoT-SC)
Generate multiple Chain-of-Thought paths for the same problem and take the majority vote. This reduces the impact of any single reasoning chain going wrong.
import collections
def cot_self_consistency(prompt: str, n: int = 5) -> str:
"""Run CoT multiple times and take majority answer."""
answers = []
for _ in range(n):
response = call_llm(
prompt + "\nThink step by step.",
temperature=0.7 # Higher temp for diversity
)
answer = extract_final_answer(response)
answers.append(answer)
# Return most common answer
counter = collections.Counter(answers)
return counter.most_common(1)[0][0]
Self-consistency typically improves accuracy by another 5-15% over single CoT, at the cost of N times the API calls.
Least-to-Most Prompting
For problems that are too complex for a single CoT chain, decompose explicitly:
Problem: Design a rate limiter that handles 100K requests/second
across 50 servers with sub-millisecond overhead.
Step 1: What are the sub-problems?
- Token bucket or sliding window algorithm selection
- Distributed state synchronization
- Sub-millisecond latency constraint
- Failure handling when nodes go down
Step 2: Solve each sub-problem independently.
Step 3: Combine solutions and resolve conflicts.
CoT with Tool Use
The most powerful pattern: combine CoT reasoning with actual tool execution. The model thinks about what information it needs, calls tools to get it, reasons about the results, and continues.
system_prompt = """You are a debugging agent. When investigating
issues:
1. THINK: What information do I need? What's my hypothesis?
2. ACT: Call the appropriate tool (read_logs, query_db,
check_metrics)
3. OBSERVE: What did the tool return? Does it confirm or
deny my hypothesis?
4. REPEAT or CONCLUDE: Either gather more info or state
your finding.
Always think before acting. Never call a tool without first
stating why you're calling it and what you expect to find.
"""
This Think-Act-Observe loop (also called ReAct) is the foundation of most modern AI agent frameworks. We'll cover it in depth in Part 5 of this series.
Measuring CoT Impact
Here's a practical framework for determining whether CoT improves your specific use case:
def evaluate_cot_impact(
test_cases: list[dict], # [{"input": ..., "expected": ...}]
system_prompt: str,
) -> dict:
"""Compare direct vs CoT prompting on a test set."""
results = {"direct": [], "cot": []}
for case in test_cases:
# Direct prompting
direct = call_llm(
system=system_prompt,
user=case["input"]
)
results["direct"].append(
score(direct, case["expected"])
)
# CoT prompting
cot = call_llm(
system=system_prompt,
user=case["input"] + "\nThink step by step."
)
results["cot"].append(
score(cot, case["expected"])
)
return {
"direct_accuracy": sum(results["direct"]) / len(test_cases),
"cot_accuracy": sum(results["cot"]) / len(test_cases),
"improvement": (
sum(results["cot"]) - sum(results["direct"])
) / len(test_cases),
}
Run this on at least 50 representative test cases before committing to CoT in production. If the improvement is less than 10%, the extra tokens probably aren't worth it.
Production Considerations
Cost Impact
CoT responses are typically 3-5x longer than direct responses. At scale:
| Approach | Avg Tokens/Response | Daily Cost (10K calls, GPT-4o) |
|---|---|---|
| Direct | 200 tokens | ~$6 |
| Zero-Shot CoT | 600 tokens | ~$18 |
| Few-Shot CoT | 800 tokens | ~$24 |
| Self-Consistency (5x) | 3,000 tokens | ~$90 |
Optimize by using CoT selectively — route simple queries to direct prompting and complex ones to CoT using a lightweight classifier.
Latency
More tokens = more time. For real-time applications:
- Use streaming to show results as they generate
- Consider hiding CoT reasoning (user sees only the final answer)
- Use faster models (GPT-4o-mini, Claude Haiku) for the CoT step if accuracy is sufficient
Debugging CoT Failures
When CoT produces wrong answers, the reasoning chain tells you exactly where it went wrong. This is a major advantage over direct prompting — with direct prompting, a wrong answer gives you no signal about why it failed.
Common CoT failure modes:
1. Correct reasoning, wrong conclusion — Model reasons correctly but makes an arithmetic error in the final step
2. Wrong assumption in step 1 — Everything downstream is logical but based on a false premise
3. Reasoning loop — Model goes in circles, restating the same step differently
4. Premature conclusion — Model arrives at an answer before considering all relevant factors
Conclusion
Chain-of-Thought prompting is the second most important technique in prompt engineering, right after system prompts. It works because it gives the model a scratchpad — intermediate tokens that serve as working memory for complex reasoning.
The key takeaways:
- Use CoT for reasoning tasks — math, logic, debugging, planning. Skip it for factual recall and creative tasks.
- Few-Shot CoT > Zero-Shot CoT — Examples of good reasoning dramatically improve output quality.
- Structure your chains — Don't just say "think step by step." Define the specific steps you want.
- Measure the impact — CoT costs 3-5x more tokens. Make sure the accuracy improvement justifies the cost.
- Debug via the chain — When CoT fails, the reasoning steps tell you exactly where and why.
In the next post, we'll explore Few-Shot Prompting — how to teach AI by example, and the surprisingly nuanced art of choosing the right examples.
This is Part 2 of the Prompt Engineering Deep-Dive series. Previous: System Prompts — The Hidden Layer. Next: Few-Shot Prompting — Teaching AI by Example.
About the Author
Toc Am
Founder of AmtocSoft. Writing practical deep-dives on AI engineering, cloud architecture, and developer tooling. Previously built backend systems at scale. Reviews every post published under this byline.
Published: 2026-04-09 · Written with AI assistance, reviewed by Toc Am.
Get These In Your Inbox
Weekly deep-dives on AI engineering, no fluff. Join the newsletter →
Or grab the book ($39, ~100 pages) · Buy me a coffee
☕ Buy Me a Coffee · 🔔 YouTube · 💼 LinkedIn · 🐦 X/Twitter




No comments:
Post a Comment