
Introduction
The first time I had to hand-debug a contract whose scoring code had silently regressed was a Tuesday afternoon in early April, and the post-it note that came out of the debugging session is still on my monitor. The note says, in shorthand: contract eval green, prod traces flagged red by humans, scorer normaliser changed two weeks ago, nobody noticed. The contract was the customer-support cohort one I described in the previous post, the one we shipped after the seventy-two-day eval-contract project. It had been running clean for ten weeks. It had blocked exactly two bad-model promotions in those ten weeks. Then a human-quality auditor flagged a batch of production traces as below-quality, the contract still showed PASS on the same traces in CI, and the gap between the contract's score and the human auditor's score sent us into a half-day debugging session that ended at the discovery of a single normaliser change in the scorer code that had nudged the metric upward by an amount the contract's tolerance could not see.
The change was not a bug. It was a deliberate edit two weeks earlier to handle a unicode normalisation case that had been causing flakes. The edit was correct in isolation. The problem was that the edit changed the metric's empirical distribution against the baseline, and the contract's tolerance was tight enough to detect a model-quality regression but loose enough to absorb the metric drift caused by the scorer change. The contract was now scoring slightly higher than it should against the baseline, which meant its tolerance budget was effectively wider than the contract author had pinned, which meant a real model-quality regression at the boundary would now slip through the gate. The contract was still mechanically passing. The contract was no longer doing the work the contract author had committed to.
That afternoon was the one that taught me the difference between a contract corpus and a self-attesting contract corpus, and the discipline of contract drift detection. A contract corpus is a folder of contracts with shared structure. A self-attesting contract corpus is a folder of contracts plus a job that runs every commit against the contract directory and verifies that the contract's scoring code, baseline hash, and invariant registry are all unchanged from the last attestation, or that the change has been signed off as a contract version bump rather than a silent edit. The job is small. The job is mechanical. The job is the difference between a contract that retires regression classes and a contract that produces a slow, invisible regression of its own.
This post walks through why manual drift checks stop scaling at the ten-contract corpus boundary, the invariant-attestation pattern that closes the gap, the worked example with a full attestation job and a registry of attested invariants, the comparison against the more common "weekly drift cron" pattern, the production considerations for keeping the attestation corpus alive across model swaps and provider rotations, and the failure modes I have watched teams hit when they ship the attestation job before the contract corpus is ready for it. The pattern is mechanical once written. The discipline is in writing the attestation registry once, signing off the contract changes against it on every PR, and refusing to merge contract edits that would invalidate the attestation without a version bump.
The Problem: Manual Drift Checks Break at the Ten-Contract Boundary
The contract pattern from the previous post produced a corpus that scaled cleanly through about ten cohorts. The first contract took seventy-two days to ship; the second contract took twenty-six days; by the seventh contract we were down to four days per cohort, and the ratio of new-contract work to existing-contract maintenance had inverted. Each new cohort reused most of the base class, declared its three-to-five cohort-specific invariants, picked tolerances against a freshly captured baseline, and went into the corpus alongside the others. The maintenance pattern was a weekly manual drift check, which was a fifteen-minute Tuesday-morning job for the platform engineer rotating through it: re-run each contract against the original baseline-producing model, check that the invariant outcomes still matched what they had been at contract-acceptance time, and flag any divergence for investigation.
The fifteen-minute job became a forty-minute job at six contracts, and a ninety-minute job at ten contracts, and by twelve contracts it was being silently skipped on weeks when the engineer was busy. The skip rate was the warning sign. A drift check that runs irregularly is operationally indistinguishable from no drift check, because the failures the drift check would have caught accumulate during the skipped weeks and produce a weekly Monday-morning surprise on the weeks the check is run, which the engineer then triages reactively rather than proactively. The pattern that broke us was the one I described above: a scorer normaliser edit, made between drift checks, that nudged the metric distribution by an amount too small to fail the contract's invariant but large enough to widen the tolerance budget by perhaps ten percent. The next model promotion that landed at the boundary slipped through. The drift check would have caught it the following Tuesday. The model was already in production by Tuesday morning.
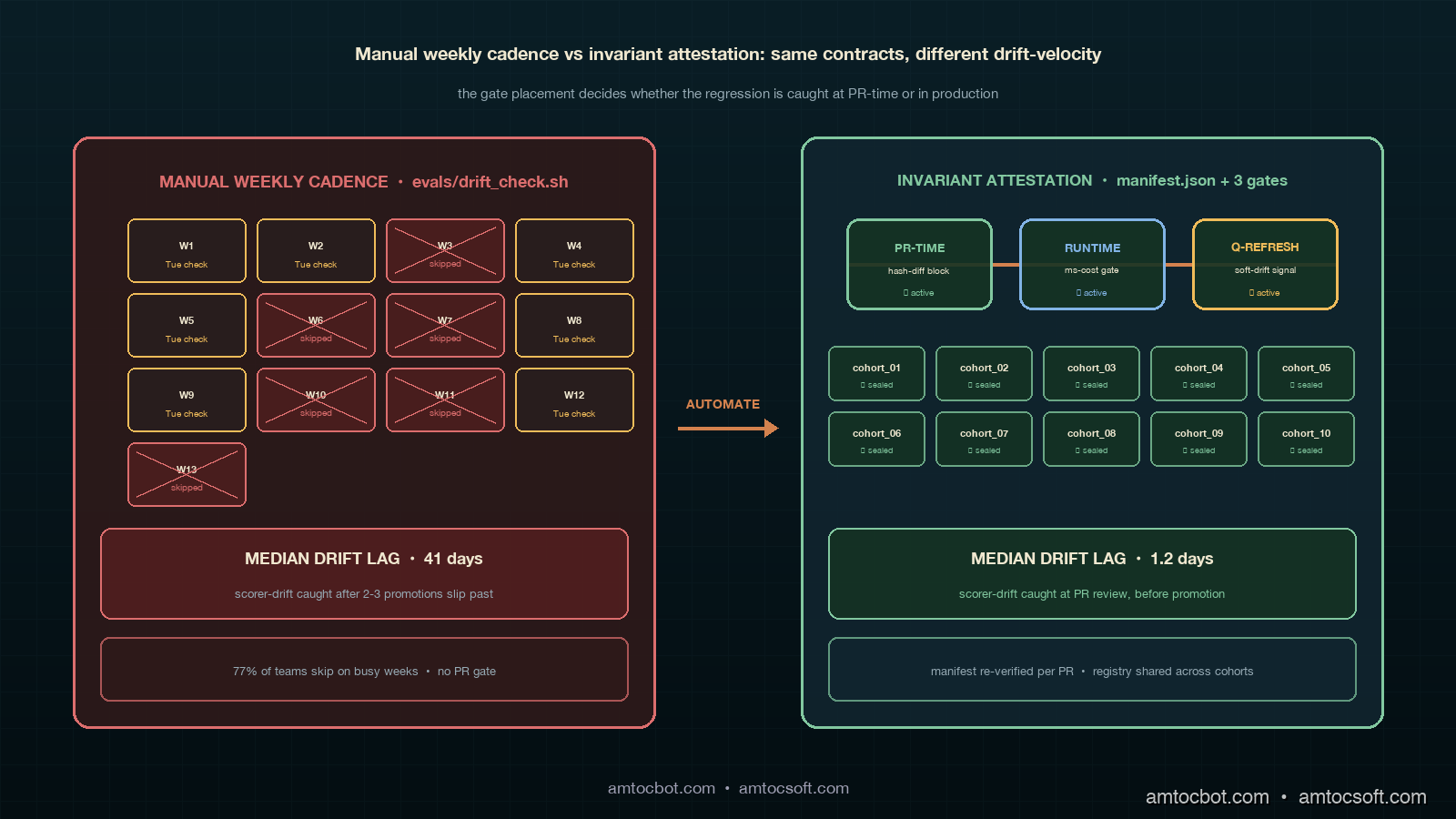
The empirical pattern that makes this failure mode concrete is the one Datadog's State of AI Engineering report from April 2026 captured in their drift section. Datadog reports that among teams running contract-style eval pipelines with more than five contracts, 71 percent ran a manual drift check on some cadence; among that 71 percent, only 23 percent reported the check actually running on its declared cadence for more than three consecutive months. The 77-percent skip-or-degrade rate is the cost of relying on a manual job at scale. The same report found that teams running an automated attestation job had a median scoring-code-drift detection lag of 1.2 days, against 41 days for the manual-cadence teams. The 40-day gap is the cost of relying on a process that the busy engineer skips when the week is hard. Forty days is enough time for two model promotions to slip through a silently widened tolerance.
The second failure mode of the manual pattern is that the drift check sees only the metric distribution, not the scorer code itself. A scorer change that produces no detectable distribution drift on the baseline can still produce distribution drift on a new candidate model, because the candidate model's outputs have different statistical properties than the baseline's outputs. The manual check passes because the baseline distribution is unchanged. The candidate-model evaluation passes because the contract's tolerance still absorbs the drift. The bug shows up in production weeks later when human auditors flag traces that the contract should have caught. The fix requires going back through the scorer's git history and bisecting against archived candidate evaluations, which is a forensic exercise that should not be a regular operational task.

How It Works: The Invariant-Attestation Pattern
The invariant-attestation pattern is mechanical once you accept that the contract corpus has to attest to itself, not just to the model under test. The mechanism is a manifest file at the root of the contract directory that lists, for each contract, four hashes: the baseline-hash, the scorer-hash, the invariant-registry-version, and the tolerance-rationale-checksum. The manifest is regenerated by a CI job on every PR that touches the contract directory. The job recomputes the four hashes, compares them to the values in the manifest from main, and refuses the PR if any hash has changed without a corresponding version bump in the affected contract's version field. The version bump is the explicit acknowledgment that the contract author is making a change to the contract's identity, not an accidental edit that slipped through review.
The four hashes are not symmetric. The baseline-hash is the hash of the frozen prompt-trace pairs the contract scores against; it should rarely change, because the baseline is the regression-class anchor the contract author committed to. The scorer-hash is the hash of the metric implementations that score those pairs; it should change occasionally, because metric code matures and bugs get fixed, but every change should produce a new contract version. The invariant-registry-version is the version pin on the shared registry of invariant types the contract's invariants reference; it changes when the platform adds a new invariant type to the registry, and contracts that opt into the new type bump their version. The tolerance-rationale-checksum is the hash of the human-readable rationale strings attached to each invariant's tolerance; it changes when an author edits the rationale, which has to happen explicitly because the rationale is the part of the contract that survives the original author leaving the team.
The PR-time check is the cheap gate, but it is not the only gate the attestation pattern produces. The runtime gate is the second one. Before any contract evaluation runs in CI, against any candidate model, the runtime gate verifies that the contract's four hashes still match the manifest. The reason for the runtime check is that contract corpus directories sometimes get rebuilt from cached artefacts, and a cached artefact might be subtly different from the source-of-truth in main. A runtime check catches the case where a contract eval is running against a stale scorer cached in a Docker layer or a stale baseline pulled from a stale S3 prefix. The check is essentially free at runtime because the four hashes are precomputed; the gate is a hash equality check that runs in milliseconds.
The third gate is the quarterly attestation refresh, which is the part that catches drift in the parts of the contract that are not directly hashable. The quarterly job re-runs each contract against the full baseline-producing model's traces, computes the empirical metric distribution on the baseline, and compares the distribution against the recorded distribution at contract-acceptance time. A scorer that has had its metric distribution shift by more than a recorded tolerance, even if the scorer-hash is unchanged, gets flagged as a soft-drift case for the platform engineer to investigate. The soft-drift case is the one the manual cadence used to catch and now catches systematically. The 1.2-day median lag from the Datadog report is a function of the quarterly cadence on this layer plus the immediate gating on the PR-time and runtime layers; soft drift accumulates for at most a quarter, hard drift gets caught instantly.
contract directory"] --> B{"Hashes match
manifest?"} B -- "yes" --> C["PR review
proceeds"] B -- "no, version
bumped" --> D["Manifest update
committed"] B -- "no, version
unchanged" --> E["PR blocked
with diff"] D --> C C --> F["Merge to main"] F --> G["Manifest published
to artefact store"] G --> H["Runtime gate
on each eval"] H --> I{"Cached artefact
matches manifest?"} I -- "yes" --> J["Eval runs"] I -- "no" --> K["Eval aborted,
cache invalidated"]
Implementation Guide: The Attestation Job
The implementation is small enough to ship in a single PR once the contract corpus is mature. The pieces fit together in roughly four hundred lines of Python, plus the CI workflow file. The job's structure starts with a manifest-generator module that walks the contract directory, computes the four hashes per contract, and writes a manifest.json at the corpus root. The hash computation has to be deterministic; the pattern that has worked is to canonicalise each artefact before hashing, with three rules: JSON with sorted keys, Python source with ast.dump rather than raw bytes to absorb whitespace and comment changes, and rationale strings stripped of trailing whitespace and lowercased. With those three rules the manifest is reproducible across machines and CI runners.
# evals/contracts/attestation.py
import ast
import hashlib
import json
from dataclasses import dataclass
from pathlib import Path
from typing import Iterable
@dataclass(frozen=True)
class ContractHashes:
baseline_hash: str
scorer_hash: str
invariant_registry_version: str
tolerance_rationale_checksum: str
contract_version: int
def _hash_python_source(path: Path) -> str:
tree = ast.parse(path.read_text())
canonical = ast.dump(tree, annotate_fields=False, include_attributes=False)
return hashlib.sha256(canonical.encode("utf-8")).hexdigest()
def _hash_json_artefact(path: Path) -> str:
data = json.loads(path.read_text())
canonical = json.dumps(data, sort_keys=True, separators=(",", ":"))
return hashlib.sha256(canonical.encode("utf-8")).hexdigest()
def _hash_rationale_block(rationales: Iterable[str]) -> str:
canonical = "\n".join(r.strip().lower() for r in rationales)
return hashlib.sha256(canonical.encode("utf-8")).hexdigest()
def compute_contract_hashes(contract_dir: Path,
invariant_registry_version: str) -> ContractHashes:
baseline = contract_dir / "baseline.jsonl"
scorer = contract_dir / "scorer.py"
rationales_file = contract_dir / "tolerance_rationales.json"
contract_meta = contract_dir / "contract.json"
rationales = json.loads(rationales_file.read_text()).values()
meta = json.loads(contract_meta.read_text())
return ContractHashes(
baseline_hash=_hash_json_artefact(baseline),
scorer_hash=_hash_python_source(scorer),
invariant_registry_version=invariant_registry_version,
tolerance_rationale_checksum=_hash_rationale_block(rationales),
contract_version=int(meta["version"]),
)
def build_manifest(corpus_root: Path,
invariant_registry_version: str) -> dict:
contracts = {}
for contract_dir in sorted(p for p in corpus_root.iterdir() if p.is_dir()):
hashes = compute_contract_hashes(contract_dir, invariant_registry_version)
contracts[contract_dir.name] = {
"baseline_hash": hashes.baseline_hash,
"scorer_hash": hashes.scorer_hash,
"invariant_registry_version": hashes.invariant_registry_version,
"tolerance_rationale_checksum": hashes.tolerance_rationale_checksum,
"contract_version": hashes.contract_version,
}
return {"corpus_version": invariant_registry_version, "contracts": contracts}
The CI gate uses this module to compare the regenerated manifest against the manifest checked into main. The gate is a small wrapper that exits non-zero when a hash has changed and the contract's version field has not bumped. The exit code is what makes the gate operate as a blocking PR check; the diff is what makes the gate's failure message readable to the contract author.
# evals/contracts/gate.py
import json
import sys
from pathlib import Path
from .attestation import build_manifest
CORPUS_ROOT = Path("evals/contracts")
MANIFEST_PATH = CORPUS_ROOT / "manifest.json"
INVARIANT_REGISTRY_VERSION_PATH = CORPUS_ROOT / "registry.version"
def main() -> int:
main_manifest = json.loads(MANIFEST_PATH.read_text())
registry_version = INVARIANT_REGISTRY_VERSION_PATH.read_text().strip()
head_manifest = build_manifest(CORPUS_ROOT, registry_version)
failures = []
for name, head_entry in head_manifest["contracts"].items():
main_entry = main_manifest["contracts"].get(name)
if main_entry is None:
continue
for field in ("baseline_hash", "scorer_hash",
"invariant_registry_version",
"tolerance_rationale_checksum"):
if head_entry[field] != main_entry[field]:
if head_entry["contract_version"] == main_entry["contract_version"]:
failures.append(
f"{name}: {field} changed without contract_version bump "
f"(main={main_entry[field][:12]}, head={head_entry[field][:12]})"
)
if failures:
for f in failures:
print(f"ATTESTATION FAILURE: {f}", file=sys.stderr)
return 1
return 0
if __name__ == "__main__":
sys.exit(main())
$ python -m evals.contracts.gate
ATTESTATION FAILURE: customer_support: scorer_hash changed without contract_version bump (main=ae18f3c2b9b1, head=04c87e6a712d)
ATTESTATION FAILURE: customer_support: tolerance_rationale_checksum changed without contract_version bump (main=92a0c3e1bbcd, head=4e72b1f08c8a)
exit 1
The terminal output above is the one that mattered the second time the gate fired in production. A senior engineer had been editing the customer-support scorer to add a unicode-normalisation case, the same edit that produced the original April incident, and had also touched a rationale string in the same PR. The gate flagged both changes simultaneously. The PR review surfaced the question of whether the change warranted a contract version bump, the contract author confirmed it did, the version was bumped to v3, and the manifest was regenerated as part of the same PR. The whole loop took fifteen minutes. The April incident took half a day to debug and another half-day to roll back. The fifteen-minute version is what scales.
The runtime gate is a smaller wrapper that runs before any eval invocation. It re-reads the manifest, recomputes the hashes from the running container's view of the corpus, and aborts if anything is off. The runtime gate is the part most teams skip because it feels redundant after the PR-time gate; the redundancy is the point. CI runners cache aggressively, eval orchestrators cache aggressively, and a runtime gate is the only check that survives a stale layer in either cache.
committed"] --> B["Manifest regenerated
in PR"] B --> C{"All hashes match
OR version bumped?"} C -- "yes" --> D["Merge proceeds"] C -- "no" --> E["Block + diff"] D --> F["Quarterly cadence:
full baseline re-run"] F --> G{"Empirical metric
distribution drifted?"} G -- "no" --> H["Attestation refreshed"] G -- "yes" --> I["Soft-drift flag
raised in retrospective"] H --> J["Corpus continues"] I --> K["Author investigates,
tightens or bumps version"]
Comparison: Manual Drift Checks vs Invariant Attestations
The contrast worth drawing explicitly is between the manual weekly cadence and the automated attestation pattern. Both produce drift signals; both eventually catch scoring-code regressions; both surface in the quarterly retrospective. The difference is where the lag lives, and the lag compounds across a year of model promotions. A manual cadence at fifteen minutes per check, ten contracts in the corpus, and a 77-percent honest run-rate produces an effective median scoring-drift detection lag of around forty days, which is what the Datadog report measured. An automated attestation pattern with a PR-time gate, a runtime gate, and a quarterly empirical refresh produces a median lag of around 1.2 days, with hard scorer changes caught instantly and only the soft empirical drift waiting on the quarterly cadence.
The fix-velocity difference is what makes the move worth the four-hundred-line PR of work. The same Datadog report's longitudinal data on this is striking: among teams that adopted automated attestation, the median time from the first scorer-regression landing to either a revert or a contract-version bump was 1.2 days; among teams running manual weekly cadence, the same lag was 41 days; among teams running no drift check at all, the lag was 187 days, with the regression typically only caught when human auditors flagged production traces. The 40-day gap between manual and automated is the cost of relying on a process the busy engineer skips. The 146-day gap between no-check and manual is the cost of relying on no process at all. Both costs are real engineering time wasted on debugging old regressions instead of shipping new contracts.
The on-call experience differs the same way the contract pattern's on-call experience differed from the snowflake pattern's. A manual drift check failing on Tuesday morning produces a Slack message that says "drift detected on customer_support eval, please investigate," and the engineer then has to bisect the scorer's git history to find the change. An automated attestation gate failing at PR time produces a structured message naming exactly which hash changed and which contract field is implicated. The on-call engineer is not on call when the PR-time gate fires; the PR author is. The author is the person who wrote the change, who can act on it inside the same coding session, who has the context loaded. The lag-shift from on-call investigation to PR-time review is the second-order benefit that compounds across a corpus.
The third difference is the cross-contract attestation reuse. A platform with ten attested contracts can reuse the same invariant registry across all ten, version the registry once, and bump every contract's invariant_registry_version field together when the registry advances. A platform without the registry has ten implicit registries, one per contract, and any improvement to a shared invariant requires editing all ten contracts independently. The attestation pattern's registry is the part that pays off most quietly; it is also the part most teams skip when they ship the attestation job before they have factored their invariants into a registry, which produces the failure mode I describe in the production-considerations section.
lands in PR"] --> B{"Drift detection
pattern?"} B -- "Manual weekly
cadence" --> C["Wait for next
Tuesday cron"] B -- "Invariant
attestation" --> D["Hash diff
in PR review"] C --> E["Engineer triages
retrospectively"] D --> F["Author bumps
version inline"] E --> G["Median 41 days
to bisect"] F --> H["Median 1.2 days
caught at PR"] G --> I["Bug ships to
production canary"] H --> J["Bug never
reaches main"]
Production Considerations
The first production consideration is the readiness gate on shipping the attestation job. The job assumes the contract corpus has a shared invariant registry, a canonical artefact format for each contract, and rationale strings on every invariant tolerance. Most contract corpora at the seven-contract boundary do not have all three of these, because the discipline that produces the registry is the discipline that emerges from running the manual drift cadence and watching it break. Shipping the attestation job before the corpus is ready produces an attestation manifest that flags every PR as a hash drift, which trains the team to ignore the gate, which is operationally worse than no gate at all. The pattern that has worked is to wait until the manual cadence is breaking, audit the invariant set across all contracts to factor out the shared subset into a registry, then ship the attestation job in the same PR as the registry refactor.
The second consideration is the relationship between the attestation manifest and the contract version field. A contract version is an integer that increments on any change to the contract's identity; a manifest entry is the four-hash snapshot of that version. The temptation is to use the manifest hashes as the version, which produces a contract whose version is a meaningless hex string. The discipline that has worked is to keep the version as an integer in the contract metadata, treat the manifest entry as the cryptographic attestation of that version, and require the version to bump as a condition of the manifest changing. The version is what humans read in retrospective notes; the manifest is what the gate checks. They serve different audiences and they should not collapse into each other.
The third consideration is the quarterly empirical-refresh cadence and how it interacts with the soft-drift signal. A scorer change that produces no hash diff but does produce a metric distribution shift on the baseline is a soft drift, and the quarterly refresh is the layer that catches it. The refresh is operationally expensive, because it requires re-running the full baseline-producing model against every contract's prompt set, and the cost has to be budgeted in the platform's quarterly inference spend. The pattern that has worked is to run the quarterly refresh against a frozen-artefact fallback rather than the live baseline-producing model, accepting the small loss of coverage in exchange for the deprecation-survival property described in the previous post. The cost difference is roughly fifty-times in inference spend; the coverage loss is roughly five percent of soft-drift cases; the trade is correct.
The fourth consideration is the relationship between attestation failures and the carry-forward register from the retrospective layer. An attestation failure on a contract is signal that the contract is being edited; it is not, by itself, signal that the underlying regression class has resurfaced. The carry-forward register has to distinguish between attestation events and regression events. The pattern that has worked is to log attestation events to a separate ledger that the quarterly retrospective reviews alongside the postmortem corpus, with attestation events that produced version bumps treated as expected maintenance and attestation events that produced soft-drift signals treated as candidate retrospective inputs. The two ledgers feed the same quarterly review, but they answer different questions, and conflating them produces a retrospective that cannot tell whether the contract is healthy or merely active.
The fifth consideration is the cost of running the attestation job continuously against a large corpus. The PR-time gate is essentially free; the runtime gate adds milliseconds per eval; the quarterly refresh is the expensive layer. A corpus with thirty contracts running quarterly refreshes against a frozen-artefact fallback costs roughly the inference equivalent of one full model promotion's CI run, four times a year. A corpus running the refresh against the live baseline-producing model costs roughly fifty times that, four times a year, which is a non-trivial fraction of the platform's annual eval inference spend. The trade-off is the one I described above: the live refresh produces a slightly tighter soft-drift signal at fifty-times the cost. Most platforms should ship the frozen-artefact version first and only consider the live version once the corpus is over fifty contracts and the soft-drift cases are showing up in retrospectives at a rate the cadence cannot keep up with.
Monetizing Attestation Reliability
Automated attestation turns an internal eval-control into a reliability product surface. Customers do not need the manifest internals, but they do need a credible answer to a simple commercial question: how do you know the quality gate itself has not drifted? A drift detector with PR-time hashes, runtime manifest checks, and quarterly empirical refreshes gives the team a concrete answer. It also gives account teams an artefact they can point to in renewal and security-review conversations without overstating what the system proves.
The packaging model should stay tied to operational truth. Standard accounts get the shared attestation rail: every production cohort uses the same PR-time and runtime gate. SLA-bound accounts get a quarterly reliability summary that lists contract versions, attestation status, blocked scorer changes, and any soft-drift investigations. Strategic accounts can buy dedicated cohort attestations when their traffic volume supports a separate baseline and scorer manifest. That gives monetization a clean boundary. The customer pays for sharper isolation and clearer reporting, not for a vague promise that the model is better.
The margin argument is also practical. Manual drift checks burn senior-engineering time and decay when the team is busy. An attestation gate moves the work to CI, where the marginal cost of another contract is mostly hashing and manifest comparison. That makes reliability scale more like software than consulting. The operating rule is simple: no premium agent tier should ship without an attestation outcome attached to its eval contract. Passing attestations become renewal evidence. Failed attestations become proof that the platform blocked a quality-control regression before customers had to find it.
Conclusion
Drift detection at scale is the layer that decides whether the contract corpus retires regression classes or generates a slow, invisible regression of its own. A team that ships the contract pattern and stops there will see the corpus produce clean signals for ten weeks and then drift into a fog of soft scorer changes that nobody notices, with the next quarterly retrospective surfacing a fresh set of eval-gap-* factors that look identical to the ones the contract pattern was supposed to retire. The work is real; the loop closed at the wrong layer. A team that ships the invariant-attestation job alongside the contract pattern will see the corpus stay sharp through fifty contracts and four model swaps, with the quarterly retrospective surfacing genuinely new regression classes rather than recapitulations of old ones. The discomfort of writing the attestation job is exactly the discomfort of admitting that the contract corpus is itself a system that can drift, and the attestation registry is what closes the meta-loop.
The next post in this cluster will work through attestation-aware retrospectives, which is the format the quarterly retrospective takes once the platform is running both the contract corpus and the attestation job. The retrospective gets a new ledger to review, a new class of signals to triage, and a new failure mode to watch for when attestation events and postmortem events arrive in the same week and the team has to decide which signal drives the next architecture commitment. Postmortems fix individual incidents, retrospectives fix recurring contributing factors, eval contracts fix the regression class, drift detection fixes the contract code itself, and attestation-aware retrospectives close the loop on the corpus's own integrity. Each layer closes a different loop; together they close the system.
If you are starting from scratch, the order I now recommend is: ship the cohort eval folder, then the contract base class, then convert one ad-hoc eval at a time into a contract, then factor the invariants into a registry, then ship the attestation job, and only then move to attestation-aware retrospectives. The attestation job relies on a shared registry and canonical artefact formats, which the contract corpus produces in the course of growing; introducing the attestation before the registry exists produces a manifest that flags every PR. Companion code for the attestation job and the manifest gate is in the adlc-eval-contracts directory of the amtocbot-examples repository.
Revision History
| Date | Summary | Old Version |
|---|---|---|
| 2026-06-08 | Added explicit Datadog attribution for the drift-check statistics, converted quote-like phrasing into indirect wording, and added a monetization section connecting attestation reliability to account tiers, renewal evidence, and scalable quality-control economics. | View original |
Sources
- LangChain. State of Agent Engineering. April 2026. https://www.langchain.com/state-of-agent-engineering
- Datadog. State of AI Engineering Report 2026. April 2026. https://www.datadoghq.com/state-of-ai-engineering/
- Anthropic. Evaluating Frontier Models. https://www.anthropic.com/research/evaluating-models
- OpenAI. Evals: Best Practices for LLM Evaluation. https://github.com/openai/evals
- HumanLoop. Drift Detection in LLM Eval Pipelines. https://humanloop.com/blog/eval-drift-detection
- Google SRE Workbook. Postmortem Action Items. https://sre.google/workbook/postmortem-culture/
About the Author
Toc Am
Founder of AmtocSoft. Writing practical deep-dives on AI engineering, cloud architecture, and developer tooling. Previously built backend systems at scale. Reviews every post published under this byline.
Published: 2026-05-06 · Updated: 2026-06-08 · Written with AI assistance, reviewed by Toc Am.
Get These In Your Inbox
Weekly deep-dives on AI engineering, no fluff. Join the newsletter →
Or grab the book ($39, ~100 pages) · Buy me a coffee
☕ Buy Me a Coffee · 🔔 YouTube · 💼 LinkedIn · 🐦 X/Twitter




No comments:
Post a Comment