
Introduction
The first time a platform team's quarterly retrospective produced an architecture commitment that landed in an adjacent product team's on-call rota was a Tuesday in February, and nobody on the platform side had warned the recommender on-call engineer that a runtime cache change was about to ship into her week. I watched the page fire at three in the morning her time, watched her open the runbook, watched the runbook explain a cache layer she had not been on the architecture commitment list for, and watched her ping the platform team's slack channel with a polite but noticeably tired sentence asking what had changed. The platform team had run a perfectly clean attestation-aware retrospective, had made the runtime cache refactor commitment with two-channel evidence as I described in the previous post, and had shipped the refactor on the right cadence. The recommender team had been carrying the on-call rota for three contracts that lived inside the cache layer's blast radius, had been on a different retrospective cycle, and had had no input into the commitment that was now firing alerts on her phone. The cache refactor was a good change. The way it crossed team boundaries was not.
The Tuesday morning produced a follow-up meeting that ran for ninety minutes between the platform tech lead and the recommender team's on-call manager, and the meeting concluded with a question I had not yet seen anyone in the cluster ask in writing: when a single platform team's quarterly retrospective produces architecture commitments whose blast radius crosses into adjacent product teams' on-call rotations, what is the meeting format that surfaces the cross-team carry-forward and routes it through both teams' decision processes? The platform team had been running a clean retrospective. The recommender team had been running a clean retrospective. Neither retrospective format had a slot for signals from another team's quarterly review that will affect this team's on-call rota in the next quarter. The two-channel evidence model from the attestation-aware retrospective had been correct for one team's review of one corpus. The three-team review of two corpora and four on-call rotations had no formal layer in the schedule.
The pattern I now use, which the cluster of three teams I work with has been running for two quarters, is a retrospective syndication layer that sits above the per-team retrospective and below the engineering manager's quarterly review. The syndication layer takes carry-forward register entries from each team's retrospective, identifies the entries whose blast radius crosses into adjacent teams' on-call rotations, and routes them into a shared cross-team register with explicit owning-team and hosting-team columns. The shared register feeds back into each team's next-quarter retrospective with a cross-team prefix, and each team's on-call manager reviews the cross-team entries before the team's next quarterly window opens. The syndication is mechanical once written. The discipline is in keeping the per-team retrospectives independent enough that they continue to surface single-team contributing factors with full fidelity, while wiring the cross-team layer in tightly enough that the architecture commitments do not surprise adjacent teams' on-call engineers at three in the morning.
The Problem: The Quarterly Retrospective Was Single-Team by Default
The retrospective format I built up across the prior posts in this cluster, from postmortem retrospectives in post 188 through attestation-aware retrospectives in post 191, assumed a single team running a single retrospective on a single corpus. The assumption is fine for the first year of contract corpus operations, when the platform team is the only team that knows what a contract is, the only team running the attestation job, and the only team carrying any on-call responsibility for the corpus. Once the corpus has been live for two quarters and the contract's blast radius has expanded to cover features owned by adjacent product teams, the single-team assumption stops being correct, and the failure mode I described in the introduction starts firing.
The blast-radius expansion happens slowly enough that the platform team usually does not notice it. The first contract is for a feature the platform team owns end to end: a research-summarisation tool, a developer-facing internal agent, an internal RAG endpoint. The next two or three contracts are for features the platform team co-owns with one product team: a recommender-feature LLM scorer, a transaction-classification agent, an internal support summariser. By the time the corpus has eleven contracts, four of them are sitting on top of features that two or three product teams use, and any architecture change to the contract layer or the runtime artefact layer has a blast radius that crosses team boundaries even when the change is mechanically small. The platform team's retrospective surfaces the change as a clean, well-scoped commitment with two-channel evidence; the on-call engineers on the receiving teams find out about the change when their pager fires.
The reason the failure mode is hard to catch from inside the platform team's retrospective is that the retrospective is correctly scoped to the corpus it owns, and the corpus is correctly scoped to the contracts that fall within the platform team's review boundary. The cross-team blast radius is invisible at the corpus level because the corpus does not know which downstream features sit inside it. The blast radius lives in the on-call topology, which is owned by each product team's on-call manager, and which the platform team's retrospective does not see. The platform team's retrospective is reasoning about contracts; the on-call engineer is reasoning about pages. The two reasoning layers converge only when a page fires for a change that came out of a retrospective the on-call engineer was not invited to.
The first instinct most teams have when they hit this failure mode is to invite the adjacent product teams' on-call managers to the platform team's retrospective. This works once. It does not scale. By the time three product teams have on-call responsibility on top of the corpus, the platform team's retrospective has eleven attendees including one tech lead, two senior engineers, three product-team on-call managers, two SRE representatives, and three observers from adjacent platform teams who want to learn the format. The room cannot run a contributing-factor pass with eleven people in it; the meeting either becomes a status update or becomes a one-hour discussion of a single hot-button item that drowns out the rest of the carry-forward register. The single-team retrospective format is the wrong format for the cross-team review, even when all the right people are in the room.
The second instinct is to run a single shared retrospective across the platform team and all adjacent product teams. This works for organisations of about six engineers in total. It does not work past that scale, because the contributing-factor pass requires each attendee to have read the postmortems and attestation events being reviewed, and the cross-organisational read budget exceeds anyone's available time before the meeting starts. The shared retrospective also produces a contributing-factor count that is biased toward whichever team has shipped the most postmortems in the quarter, because the count is dominated by tag volume and the team with the highest incident rate has the highest tag volume. The bias produces architecture commitments that flow toward the highest-incident team's problems, even when an adjacent team has a smaller-but-systemic issue that would have surfaced cleanly in a per-team retrospective.
The third instinct, which is the one that has worked across the three teams I am writing this post from, is to keep the per-team retrospectives independent and to add a syndication layer above them. The syndication layer reviews only the carry-forward entries that have a cross-team blast radius, takes about thirty minutes per quarter, and runs after each team has completed its own retrospective. The format is described in detail below.
The Pattern: Three-Layer Retrospective With a Syndication Pass
The retrospective syndication format has three layers. The bottom layer is the per-team retrospective, in either the postmortem-only format from post 188 or the attestation-aware format from post 191, depending on whether the team has shipped contracts and an attestation job. The middle layer is the syndication pass, which reviews carry-forward entries with cross-team blast radius and produces a cross-team register. The top layer is the engineering manager's quarterly review, which reads the cross-team register and decides which architecture commitments to fund across teams. The three layers are temporally separated in the quarterly window: per-team retrospectives run in week eleven of the quarter, the syndication pass runs in week twelve, and the engineering manager's review runs in week thirteen. The week-twelve syndication pass is the new layer.
The input to the syndication pass is the cross-team candidates list that each team's retrospective produces alongside its standard carry-forward register. The cross-team candidates list is a subset of the carry-forward register, filtered by a deterministic rule on the carry-forward entry's contract scope field. Every contract in the corpus has a scope tag that records which downstream features depend on the contract; the scope tag is set when the contract is created and updated when a new feature integrates with the contract. The deterministic rule is that any carry-forward entry tied to a contract whose scope tag references more than one team produces a cross-team candidate; entries tied to single-team contracts stay in the per-team carry-forward register and do not enter syndication.
The syndication pass meeting has a fixed agenda. The first ten minutes are a categorical pass: each team's tech lead presents their team's cross-team candidates list, with no debate, just the items themselves and the contracts they tie to. The second ten minutes are a topology pass: the on-call managers from the affected teams identify which candidates would land in their team's on-call rota and how soon. The third ten minutes are a routing pass: the syndication facilitator (usually one of the senior platform engineers) writes each candidate into the cross-team register with explicit owning-team and hosting-team columns, where the owning team is the team that surfaced the candidate and the hosting team is the team whose on-call rota would receive the resulting page if the architecture commitment ships and a regression follows. The total meeting runs thirty minutes. There is no contributing-factor pass and no architecture commitment vote in the syndication meeting; both are deferred to the engineering manager's review the following week.
week 11"] --> B["Cross-team candidates
(per team)"] B --> C["Syndication pass
week 12, 30 min"] C --> D["Categorical pass
10 min"] C --> E["Topology pass
10 min"] C --> F["Routing pass
10 min"] D --> G["Cross-team register"] E --> G F --> G G --> H["Engineering manager
review week 13"] H --> I["Funded commitments
by team"] H --> J["Cross-team carry-forward
register"]
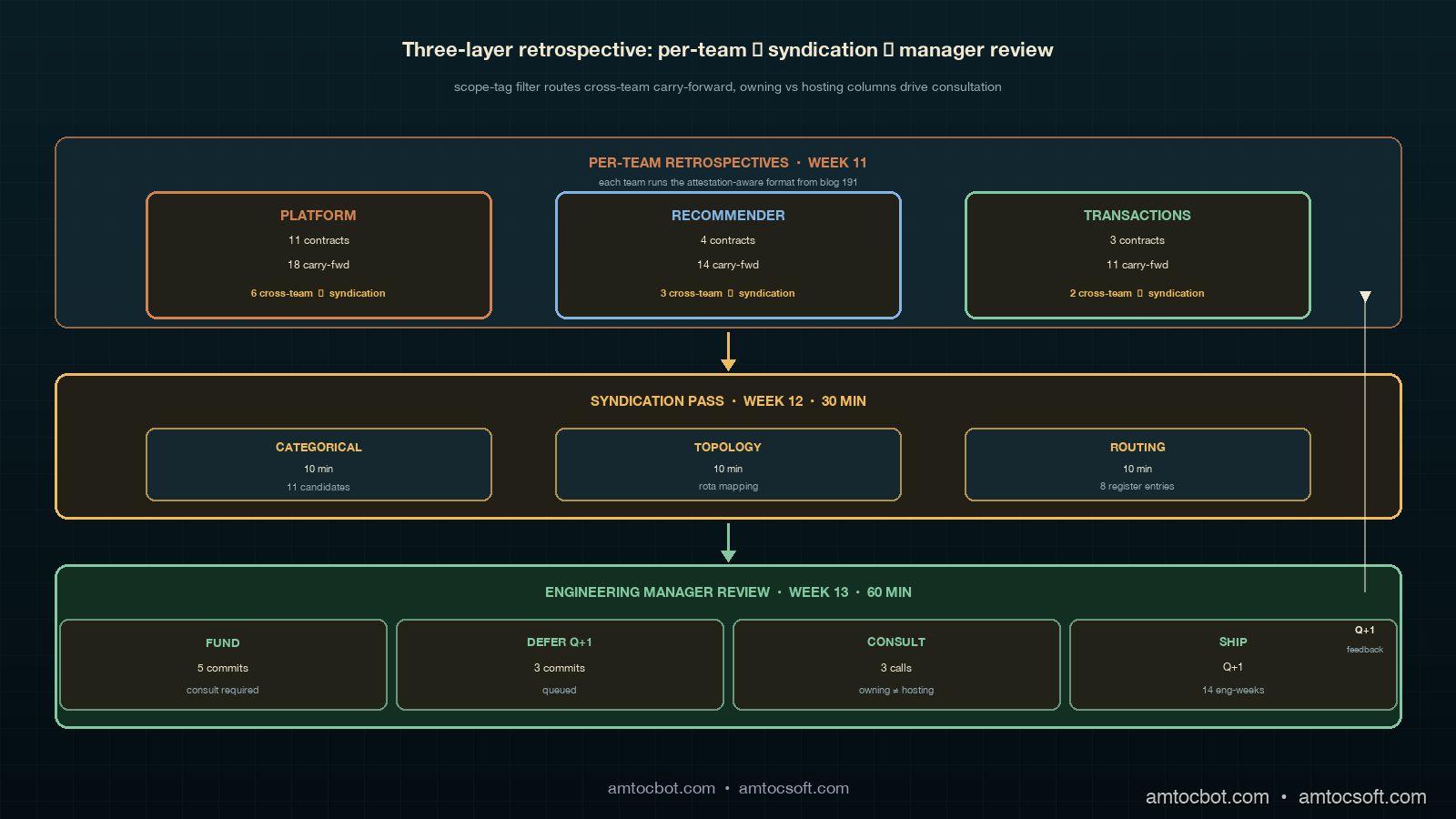
The cross-team register grows the per-team carry-forward register's two columns, ledger-of-origin and reconciliation-rank, into four columns: ledger-of-origin, owning-team, hosting-team, and reconciliation-rank. The owning-team and hosting-team columns are the new columns that make the syndication layer work. Items where owning-team equals hosting-team flow back into the owning team's next-quarter retrospective as standard cross-team-prefixed entries. Items where owning-team differs from hosting-team flow into both teams' next-quarter retrospectives, with the entry visible in both teams' registers and the reconciliation rank shared across the two views.
The week-thirteen engineering manager review is where architecture commitments are voted on. Each cross-team register entry has been pre-rated by reconciliation rank, and the manager's review walks the register top-down, voting on each entry as a fund-this-quarter, defer-to-next-quarter, or close-out decision. The commitments that get funded are assigned an owning-team plus a hosting-team consultation requirement, so that the hosting team's on-call manager has explicit warning before the commitment ships. The manager review takes about an hour for a three-team cluster with eight to twelve cross-team register entries. The total quarterly retrospective overhead, summed across per-team plus syndication plus manager review, is about two hours per team plus thirty minutes for the syndication and one hour for the manager review, or roughly seven engineering-hours per quarter for a three-team cluster of six to ten engineers per team.
Worked Example: A Single Cross-Team Syndication Pass
The example I have been using to teach this pattern is the first syndication pass our three-team cluster ran, in week twelve of Q1 2026. The three teams were the platform team (six engineers, eleven contracts, fifteen postmortems and twenty-one attestation events for the quarter), the recommender team (eight engineers, four contracts they co-own, ten postmortems and twelve attestation events), and the transactions team (seven engineers, three contracts they co-own, six postmortems and eight attestation events). The per-team retrospectives ran in week eleven and produced three independent carry-forward registers with combined eighteen-plus-fourteen-plus-eleven, or forty-three, total entries across the three teams.
The cross-team candidates list filtered the forty-three entries by the contract-scope rule and produced eleven candidates: six from the platform team, three from the recommender team, two from the transactions team. The platform team's six were the runtime cache refactor, the routing rule freshness item, the tone-stability soft-drift item, the contested version-bump on the recommender feature contract, the contested version-bump on the transaction classification contract, and the joint-runtime-cache-skew cross-ledger promotion from the attestation-aware reconciliation. The recommender team's three were a retrieval-precision long-tail item that depended on the platform team's RAG corpus, an on-call alert-fatigue pattern that touched two of the platform team's contracts, and a tool-call-latency item that the recommender team had been blamed for in their own retrospective but that actually traced to a platform-side caching layer. The transactions team's two were both routing-related: a routing-rule version drift between the platform corpus and the transactions team's downstream rule cache, and a contested version bump on the transaction-classification contract that the transactions team was carrying in their own register but that was structurally the same item the platform team was carrying.
The syndication pass meeting ran thirty-five minutes, slightly over budget for the first run but inside budget for runs two through five. The categorical pass surfaced the eleven candidates as listed above. The topology pass identified that two of the six platform-team candidates would land in the recommender on-call rota (the runtime cache refactor and the joint-runtime-cache-skew item, because both touched the cache layer that backed the recommender contracts) and one would land in the transactions on-call rota (the routing rule freshness item). The recommender's three candidates would all land in the platform on-call rota for the regression case but would land in the recommender rota for the immediate page case; the cross-team registration captured the dual-routing. The transactions team's two candidates were both shared with the platform team and were de-duplicated: the routing-rule version drift item was the same root signal as the platform team's routing-rule freshness item, and the contested version bump was the same item the platform team was already carrying.
across 3 teams"] --> B["Cross-team filter
contract-scope > 1 team"] B --> C["11 candidates"] C --> D["Categorical pass"] D --> E["Topology pass"] E --> F["Routing pass"] F --> G["8 unique entries
after dedup"] G --> H["3 owning=hosting"] G --> I["5 owning != hosting"] H --> J["Single-team flow-back"] I --> K["Dual-team flow-back"] K --> L["Both registers updated"]
The de-duplication step in the routing pass collapsed eleven candidates into eight unique cross-team register entries: the runtime cache refactor (platform owning, recommender hosting), the routing rule freshness item (platform owning, transactions hosting, with the transactions-side drift item folded in as supporting evidence), the tone-stability soft-drift (platform owning, platform hosting since it touched no other team's rota), the contested recommender contract bump (joint owning between platform and recommender, hosting on the platform side because the platform team carried the merge authority), the contested transaction contract bump (joint owning, hosting platform), the joint-runtime-cache-skew cross-ledger promotion (platform owning, recommender hosting), the recommender retrieval-precision item (recommender owning, platform hosting since the underlying RAG corpus was platform-owned), and the recommender alert-fatigue item (recommender owning, platform hosting). The eight entries went into the cross-team register with reconciliation ranks carried over from the per-team retrospectives.
The week-thirteen engineering manager review funded five of the eight entries for Q2: the runtime cache refactor with mandatory recommender-side consultation, the routing rule freshness item with transactions-side consultation, the joint-runtime-cache-skew item folded into the runtime cache refactor scope, the recommender retrieval-precision item with platform-side scoping help, and the recommender alert-fatigue item as a quick-fix three-day platform task. The remaining three entries were deferred to Q3 with explicit reasons recorded in the register. The five funded commitments produced fourteen engineering-weeks of work across the three teams, with the runtime cache refactor consuming seven of those weeks alone. The post-syndication on-call experience over Q2 was visibly different from the pre-syndication baseline of Q1: zero pages in the recommender or transactions rotations were attributed to surprise platform changes, against four pages in Q1.
The Cross-Team Register: Owning vs Hosting and the Routing Discipline
The cross-team register's value comes from the owning-team and hosting-team columns, and the discipline that goes with them. The owning team is the team that carries the architecture commitment and signs off on the engineering work; the hosting team is the team whose on-call rota receives any pages generated by the commitment in production. The two are often different, and the difference is the part most teams new to the format get wrong on the first three iterations.
The most common mistake is to set owning-team equal to whichever team surfaced the carry-forward entry in their per-team retrospective, regardless of which team will host the pages. This is sometimes correct (when the surfacing team is the team that will hold the merge authority on the change) and sometimes wrong (when the surfacing team is downstream of the actual code change and the engineering work needs to be done on a corpus owned by an upstream team). The rule that has worked is to set owning-team to the team that will actually do the engineering work, regardless of which team surfaced the item, and to use the hosting-team column to record where the on-call signal will land. A recommender-team retrospective surfacing a retrieval-precision item that requires platform-side RAG corpus changes produces a register entry with platform owning-team and recommender hosting-team. A platform-team retrospective surfacing a runtime cache refactor that affects a recommender feature produces an entry with platform owning-team and recommender hosting-team, exactly the same shape but for a different reason.
The hosting-team column produces the consultation requirement that is the visible payoff of running the syndication layer. Any commitment funded in the manager's review where hosting-team differs from owning-team carries a mandatory pre-ship consultation: the owning team's tech lead schedules a thirty-minute meeting with the hosting team's on-call manager before the commitment ships, walks the on-call manager through the change, the rollback plan, the alert configuration, and the runbook update. The consultation is a calendar invite plus a thirty-minute meeting plus a runbook diff; it is mechanical work, not negotiation work. The hosting-team's on-call manager has no authority to block the commitment, but does have the authority to require a runbook update, an alert-threshold tweak, or a rollback rehearsal before the commitment ships. The mechanical-not-negotiation framing is what keeps the consultation from becoming a second-vote layer that slows down the funded commitments.
The reconciliation-rank column on the cross-team register is the same column from the per-team carry-forward register, with one addition: cross-team entries with two-channel evidence across teams (an item visible in two teams' per-team carry-forward registers under different prefixes that resolves to the same root cause in the routing pass) get a joint-cross-team- prefix and a top-of-shortlist promotion in the manager's review. The promotion rule is the same rule from the within-team attestation-aware reconciliation in the prior post, generalised to the cross-team layer: items with two-channel evidence get higher conviction than items with single-channel evidence, regardless of whether the channels are within-team or cross-team.
The aging-out asymmetry from the per-team carry-forward register also applies at the cross-team layer, with one twist. Cross-team entries age out at the rate of the fastest-aging of the contributing per-team entries; an entry that ties a postmortem-derived item from team A (four-quarter age-out) to a manifest-derived item from team B (two-quarter age-out) inherits the two-quarter age-out. The asymmetry inheritance is intentional: cross-team manifest signals are the ones most likely to drift out of relevance fastest, and the cross-team register is the right place to retire them aggressively rather than letting them carry forward into a fourth or fifth quarter on the strength of a slower-aging counterpart entry.
hosting?"} B -- "yes" --> C["Single-team commit"] B -- "no" --> D["Mandatory consult
(30 min, pre-ship)"] C --> E["Standard rank"] D --> F{"two-channel
evidence?"} F -- "yes" --> G["joint-cross-team-
prefix, top of shortlist"] F -- "no" --> H["Standard rank"] G --> I["Q+1 funding
conversation"] H --> I E --> I
Comparison: Single-Team vs Three-Team Cluster Retrospective Cadence
The contrast worth drawing explicitly is between the single-team retrospective cadence (one retrospective per quarter, no syndication, no cross-team register) and the three-team cluster cadence (per-team retrospectives plus syndication plus manager review). Both produce architecture commitments; both maintain carry-forward registers; both run on a quarterly cadence. The differences are the surface-area of evidence, the meeting overhead, and the on-call experience.
The surface-area difference is the part that produced the most pushback when the three-team cluster first considered the format. The per-team retrospectives surface contributing-factor counts independently; the cross-team register surfaces only the items with cross-team blast radius; the manager's review funds a subset of the cross-team items plus all the within-team items the per-team retrospectives have already produced. The total surface area is larger than the single-team format by the size of the cross-team register, which in our cluster has averaged eight entries per quarter against a per-team-summed forty-three entries per quarter. The cross-team register is roughly twenty per cent of the total review volume, which is the right proportion for the format to surface the systemic items without drowning in the detail of the within-team items.
The meeting overhead difference is real but smaller than the pushback usually anticipates. A single-team retrospective at the eight-incident-plus-eight-reviewable-attestation-event level runs about one hundred and ten minutes after the team has settled into the format. A three-team cluster runs three of those one-hundred-and-ten-minute retrospectives in week eleven, plus the thirty-minute syndication pass in week twelve, plus the one-hour manager review in week thirteen, for a total of five hours and thirty minutes per quarter at the cluster level. The single-team total is one hour and fifty minutes per quarter at the team level. The cluster overhead per team is therefore one hour and fifty minutes plus a share of the syndication and manager review, or about two hours and forty minutes per team per quarter, or roughly fifty minutes more per team per quarter than the single-team baseline. The fifty minutes is the price of the syndication; in the cluster I work with, the price has paid for itself in the first quarter of operation by removing the surprise on-call pages that the pre-syndication baseline was producing.
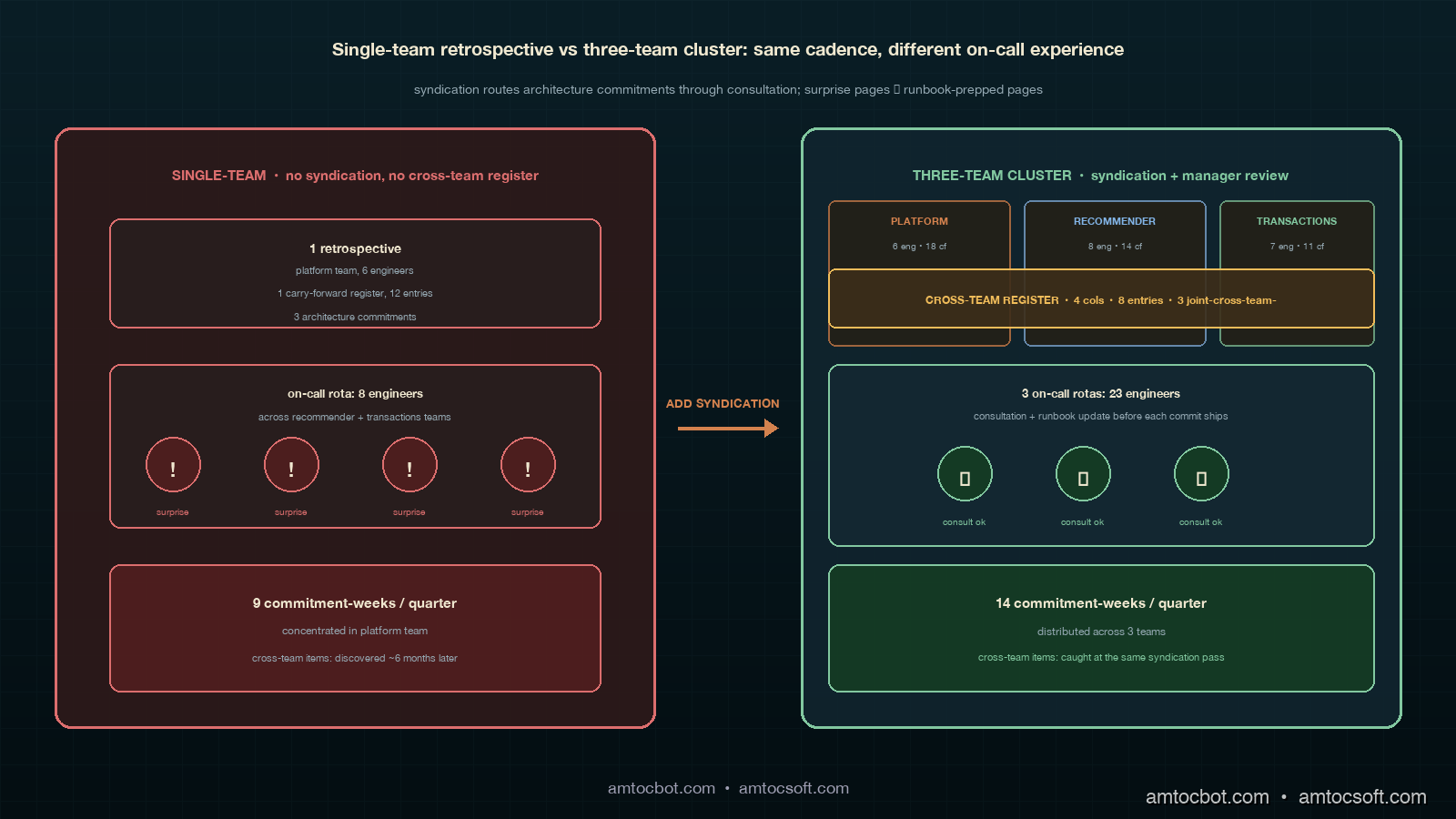
The on-call experience difference is the part the format is built for. The single-team format produces an on-call rota where most pages are about the team's own contracts and where surprise pages from upstream architecture changes are a recurring frustration. The three-team cluster format produces on-call rotas where the cross-team register has already routed any upstream change through a consultation requirement before the change ships, and where the runbook is updated as part of the consultation. The pages that fire after a cross-team architecture commitment ships are pages the on-call engineer has been briefed about, has a runbook for, and can resolve inside the alert's normal SLA. The platform team's tech lead is no longer woken up at three in the morning by a recommender on-call engineer asking what changed; the recommender on-call engineer is woken up by an alert she had been told would fire if the change misbehaved, and the runbook tells her how to resolve it.
3 teams"] --> B{"Format?"} B -- "Single-team" --> C["3 independent
retrospectives"] B -- "Cluster + syndication" --> D["3 retros + syndication
+ manager review"] C --> E["3 carry-forward
registers (no merge)"] D --> F["3 registers + 1 cross-team
register"] E --> G["Architecture commits ship
via individual teams"] F --> H["Architecture commits ship
via consultation requirement"] G --> I["Q+1: surprise pages
across team rotas"] H --> J["Q+1: zero surprise pages
runbook-prepped on-call"]
Production Considerations
The first production consideration is the discipline of keeping the per-team retrospectives independent. The temptation, after the syndication pass has run for two quarters, is to start collapsing the per-team retrospectives into a single shared retrospective on the grounds that the syndication pass is doing all the cross-team work anyway. The collapse is the failure mode I described in the introduction's second instinct: a single shared retrospective at the three-team scale produces a contributing-factor count biased toward the highest-incident team, and the cluster ends up with architecture commitments that flow toward the loudest team's problems rather than the systemic items. The discipline is to keep the per-team retrospectives independent, to constrain the syndication pass to cross-team blast-radius items only, and to accept that the cross-team layer is a second meeting on top of the per-team meetings rather than a replacement for them.
The second consideration is the scope-tag discipline on the contracts themselves. The cross-team filter rule depends on contract scope tags being accurate and up to date; a contract that has expanded into a third team's feature without the scope tag being updated will not appear in the cross-team candidates list and will produce the surprise-page failure mode the syndication is meant to prevent. The hygiene that has worked is to require the scope tag to be updated as part of any new feature integration's contract review, with the integration's PR blocked if the tag has not been touched. The tag update is a one-line code change and a thirty-second review, and the discipline catches the slow-creep blast-radius expansion before the next quarter's syndication pass runs.
The third consideration is the consultation requirement's calendar load. A cluster that funds five cross-team commitments per quarter, three of which have hosting-team different from owning-team, will produce three consultation meetings of thirty minutes each, or one and a half hours of meeting time across three tech leads and three on-call managers per quarter. The load is not large, but it is concentrated in the week before the architecture commitments start shipping, which is also the week the engineering work is ramping up. The pattern that has worked is to schedule the three consultations in the same week as the manager's review, in the calendar week between week thirteen of the prior quarter and week one of the current quarter, so that the consultations precede the engineering work rather than running concurrently with it.
The fourth consideration is the cross-team register's persistence across quarters. The register is a markdown file in the same retrospectives/ directory as the per-team registers, with the four-column shape described above plus a fifth column for the quarter the entry was first seen. Entries persist in the register until they are funded, deferred to a future quarter, or aged out by the asymmetry rule. The persistence rule that has worked is to keep the cross-team register as a single rolling file rather than producing a new file each quarter, with closed entries struck through rather than deleted, so that the manager's review can read across quarters in a single document. The rolling format makes the multi-quarter picture visible at a glance and produces a register that is partly self-prioritising in the same sense the per-team carry-forward register is.
The fifth consideration is the boundary between cross-team retrospective syndication and cross-team incident response. The two are different layers and should not be conflated. Incident response runs in real time during an incident; the cross-team retrospective layer runs in quarterly review windows and produces architecture commitments. An incident that crosses team boundaries triggers an incident-response process that produces a postmortem in each affected team's per-team retrospective; the cross-team retrospective layer reviews the postmortems' carry-forward signals against the cross-team blast-radius filter. The two layers feed each other but do not replace each other: the incident-response layer produces the artefacts that the retrospective layer reviews; the retrospective layer produces the architecture commitments that reduce the future incident-response load. Keeping the layers separate keeps the syndication meeting from turning into an incident review and keeps the incident response from waiting on a quarterly cadence.
Monetizing Cross-Team Reliability
Cross-team syndication becomes commercially useful when it turns a messy organizational risk into a visible reliability control. A customer buying an agent workflow that spans recommendations, transactions, and platform infrastructure does not care which internal team owns the cache layer. They care that changes with cross-team blast radius are routed before they reach the pager. The cross-team register gives the business a concrete artefact for that promise: every funded commitment has an owning team, a hosting team, a consultation requirement, and a carry-forward status.
The packaging boundary should follow the on-call topology. Standard customers benefit from the shared syndication layer without custom reporting. SLA-bound customers get a quarterly reliability note that lists cross-team commitments affecting their workflows, the consultation status, and whether the relevant runbooks were updated before rollout. Strategic accounts can get a dedicated blast-radius appendix when their workflows depend on multiple internal teams or multiple contract corpora. That appendix should stay factual: which contracts are in scope, which teams host pages, which commitments were funded, and which entries aged out.
This also supports monetization without overpromising. Cross-team reliability is expensive because it consumes coordination time, manager review time, and on-call preparation time. Pricing should reflect the extra operational discipline rather than pretending the workflow is cheaper than it is. The operating rule is simple: any enterprise workflow sold as production-critical should have a syndication trail when its blast radius crosses team boundaries. That trail becomes renewal evidence, security-review evidence, and a practical way to explain why reliability work is funded before the next incident forces the same investment under pressure.
Conclusion
Cross-team retrospective syndication is the layer that closes the loop on the multi-team blast radius of a contract corpus. A platform team that ships the contract pattern, the attestation job, the postmortem retrospective, and the attestation-aware retrospective without thinking about how those artefacts cross into adjacent product teams' on-call rotations will produce architecture commitments that surprise the adjacent teams' on-call engineers, generate the three-in-the-morning page-the-platform-tech-lead pattern I described in the introduction, and quietly drift the multi-team relationship toward an adversarial posture rather than a collaborative one. A platform team that ships the syndication layer alongside its per-team retrospective format will produce a cross-team register with explicit owning-team and hosting-team columns, route every commitment through a consultation requirement before it ships, and convert the surprise-page pattern into a runbook-prepped page pattern that the on-call engineers can resolve inside the alert's normal SLA.
The cluster I have been writing across blogs 167 through 192 has been about closing successive loops on LLM platform quality. Postmortems fix individual incidents, retrospectives fix recurring contributing factors, eval contracts fix the regression class, drift detection fixes the contract code itself, attestation-aware retrospectives close the loop on the corpus's own integrity, and cross-team syndication closes the loop on the corpus's blast radius across team boundaries. Each layer closes a different loop; together they close the system at the multi-team scale that any production LLM platform reaches by its second year of operations. The next blog in the cluster will work through multi-corpus retrospective rollups, which is what happens when the same syndication format has to handle three or four contract corpora in parallel rather than three teams sharing one corpus. The pattern after that will be the multi-quarter trend layer, which is what the manager's review starts producing once enough quarterly cycles have accumulated to surface trend signals across the cross-team register itself.
If you are starting from scratch with this format, the order I now recommend is: ship the per-team retrospective first and let it stabilise for two quarters, then ship the attestation-aware format in the third quarter once the attestation job has produced a stable event stream, then introduce the cross-team syndication layer once a second team has on-call responsibility on top of any of the corpus's contracts. Introducing the syndication layer before a second team is actually carrying on-call load tends to produce a meeting with no agenda, because the cross-team candidates list will be empty until the blast radius has expanded. Introducing the syndication layer after the surprise-page pattern has already started firing tends to produce an adversarial first meeting, because the receiving team has already been burned and walks in defensive. The right time to ship the syndication layer is the quarter that the second team starts onboarding to one of the corpus's contracts, before any pages have fired and before the cross-team candidates list has more than three or four entries. Companion code for the cross-team register schema, the contract scope-tag discipline, and the consultation-requirement calendar template is in the adlc-eval-contracts directory of the amtocbot-examples repository.
Revision History
| Date | Summary | Old Version |
|---|---|---|
| 2026-06-08 | Added a monetization section connecting cross-team retrospective syndication to customer-facing reliability controls, SLA reporting, blast-radius appendices, renewal evidence, and production-critical workflow pricing discipline. Updated revision metadata while preserving the existing QA-passing structure. | View original |
Sources
- LangChain. State of Agent Engineering. April 2026. https://www.langchain.com/state-of-agent-engineering
- Datadog. State of AI Engineering Report 2026. April 2026. https://www.datadoghq.com/state-of-ai-engineering/
- Google SRE Workbook. Postmortem Culture: Learning from Failure. https://sre.google/workbook/postmortem-culture/
- Etsy Engineering. Blameless Postmortems and a Just Culture. https://www.etsy.com/codeascraft/blameless-postmortems
- PagerDuty. Cross-Team Incident Response Playbook. 2025. https://www.pagerduty.com/resources/learn/cross-team-incident-response/
- Google SRE Book. Communications: Production Meetings. https://sre.google/sre-book/communications/
- HumanLoop. Drift Detection in LLM Eval Pipelines. https://humanloop.com/blog/eval-drift-detection
About the Author
Toc Am
Founder of AmtocSoft. Writing practical deep-dives on AI engineering, cloud architecture, and developer tooling. Previously built backend systems at scale. Reviews every post published under this byline.
Published: 2026-05-07 · Updated: 2026-06-08 · Written with AI assistance, reviewed by Toc Am.
Get These In Your Inbox
Weekly deep-dives on AI engineering, no fluff. Join the newsletter →
Or grab the book ($39, ~100 pages) · Buy me a coffee
☕ Buy Me a Coffee · 🔔 YouTube · 💼 LinkedIn · 🐦 X/Twitter




No comments:
Post a Comment