
Introduction
The first time the term eval contract came out of my mouth was in a follow-up meeting after a cohort-quality drop incident in early March, and it came out half-formed because I was trying to explain something I had not yet seen written down. We had finished triaging the incident two weeks earlier. The contributing-factor tag had landed in the postmortem as eval-gap-tool-call-distribution, the same tag that had appeared in five other postmortems over the previous quarter. The runbook diff had merged. The metric threshold had moved. The eval that should have caught the regression on the canary had run, returned a green score, and let the bad model promotion through, because the eval was a single average over a thousand sampled queries and the regression was a tail-shape change in the tool-call distribution that an average could not see. Each individual postmortem had named the gap; none of them had fixed the eval. The fix kept landing one layer too low.
The retrospective that quarter was the one I described in the previous post, and the second-priority architecture commitment that came out of it was the one I am writing about here. The commitment said, in the retrospective's terse format: PLAT-1148, eval-contract base class for cohort regressions, owner @kvm, due 2026-06-22, shipped in 72 days. The brief behind the commitment was three paragraphs long. The first paragraph said that the team had shipped six different ad-hoc cohort evals over the previous year, each one written in response to a specific incident, each one parameterised by hand, none of them sharing a base class or a contract. The second paragraph said that the recurring tool-call-distribution regression kept landing because the eval the canary used was the average-quality eval, and nobody had codified what quality actually meant for the cohort beyond the average. The third paragraph said the fix was to write the eval contract, freeze a baseline cohort against it, and gate canary promotion on the contract's invariants rather than on a single average.
That commitment turned into the eval-contract pattern this post describes. It took seventy-two days to ship because the move from ad-hoc evals to contract-driven evals is not a refactor, it is a redefinition of what the team means by an eval, and the redefinition has to land at the platform layer where every cohort eval is rewritten against the new base class. The work was real. The outcome, in the next quarter's retrospective, was that the eval-gap-tool-call-distribution tag dropped from six occurrences to zero, and a different recurring factor moved up to take its place. That is the right outcome. The eval contract retired one regression class entirely; the next retrospective gets to fight the next class.
This post walks through why ad-hoc cohort evals keep producing the same gap, the eval-contract pattern that closes it, the worked example with a full base class and a tool-call-distribution invariant, the comparison against the more common one-off eval pattern, the CI integration that makes the contract pageable when an invariant moves, and the production considerations for keeping the contract corpus alive across model swaps and provider rotations. The pattern is mechanical once written. The discipline is in writing the invariants once instead of writing six similar evals six times.
The Problem: Ad-Hoc Cohort Evals Are a Folder of Snowflakes
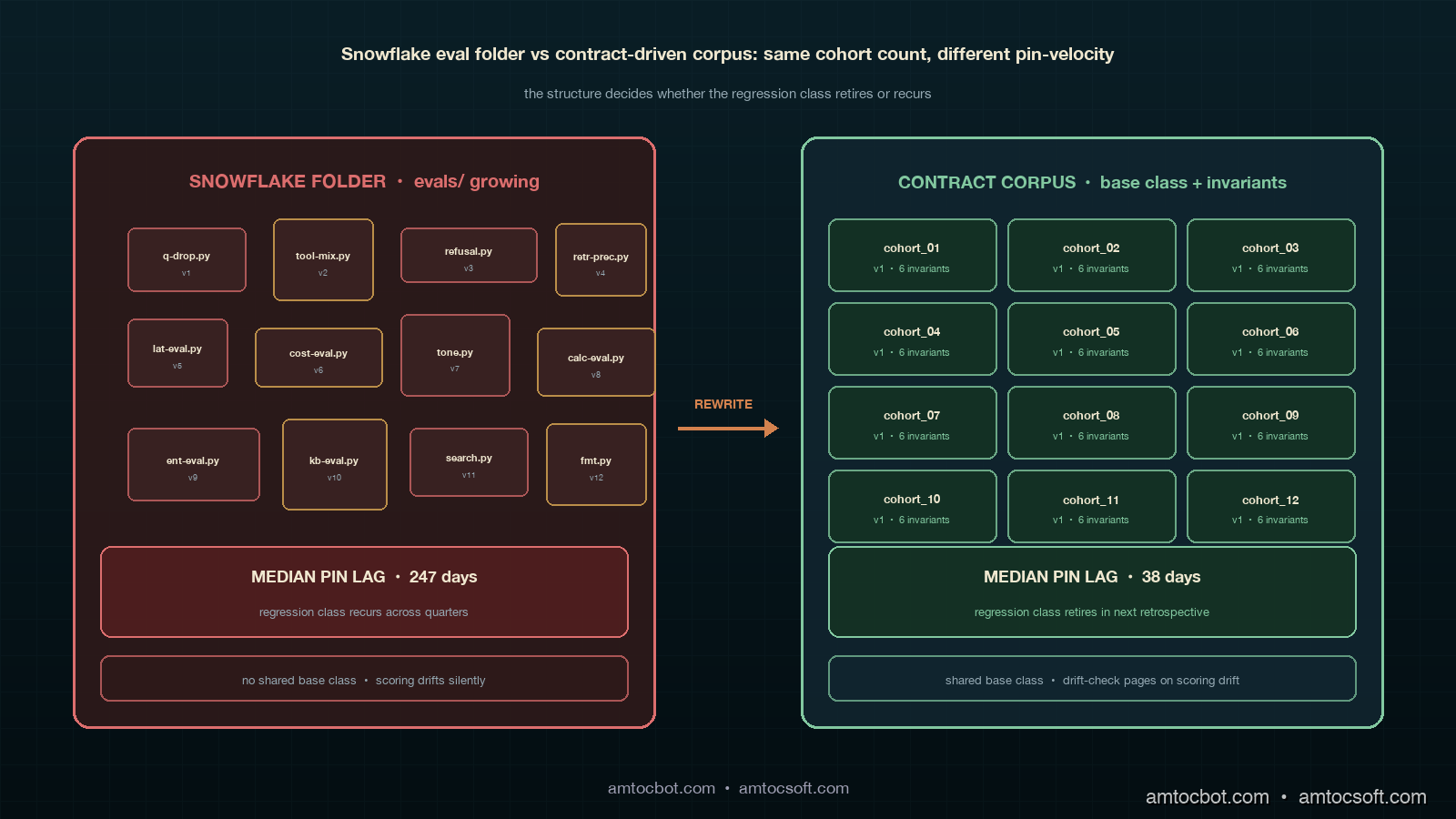
The pattern most agent platforms end up in by month six of running serious LLM workloads is what I will call the snowflake eval folder. It looks like a directory called evals/ with twenty Python files in it, each one named after the incident or feature that produced it, each one structured slightly differently, each one parameterised by hand, and each one quietly diverging from the others as the codebase ages. The cohort-quality eval that the canary runs is one of those files. The tool-call-distribution eval that one engineer wrote during the March incident is another. The retrieval-precision eval that landed three months ago is a third. The folder grows by one or two files per quarter, which feels manageable, until somebody asks the platform team what quality means and the answer is "go read the evals folder," which is the right answer if the folder is a contract and the wrong answer if it is a folder of snowflakes.
The empirical pattern that makes this concrete is the one the LangChain State of Agent Engineering report from April 2026 captured cleanly. LangChain reports that among teams running production agent workloads, 64 percent said their canary promotion gate was a single eval scoring against a single threshold, 23 percent reported a small set of evals scoring against independent thresholds, and only 13 percent reported a contract-style eval pattern with declared invariants and frozen baselines. The same report found that platforms in the 13-percent group had a 72-percent lower rate of user-caught production regressions instead of CI-caught regressions over the prior six months. The gap is large, the pattern is mechanical, and the move from the 64-percent pattern to the 13-percent pattern is the move this post is about.
The other failure mode is more subtle and harder to name. Call it eval drift. A cohort eval written against a particular baseline will, over time, drift away from the baseline as the eval's own scoring code, prompt scaffolding, or tool-call simulator changes. The eval still runs; the score still lands above the threshold; the pass-fail signal still reads green; but the eval is no longer comparing the model's behaviour against the baseline the original incident was about. The drift is invisible because the eval's pass-fail signal does not change shape. The platform team only finds out the eval has drifted when a new incident lands and somebody runs the eval against an obviously-bad model and watches it return a passing score. By that point the eval has been silently broken for an unknown number of weeks.
The third failure mode is the one that motivated the eval-contract work directly, which is what I will call invariant erosion under tool-call-distribution shifts. A model swap, even a same-family minor-version bump from a provider, can produce a model whose average task quality is statistically indistinguishable from the previous model, but whose tool-call distribution has shifted in a way that breaks downstream agent behaviour. The classic 2025 example was a same-family minor version that increased the rate at which the model called the search tool first instead of the calculator tool, which produced a flat average-quality score but blew up the per-step latency budget on workflows that depended on the calculator-first ordering. An average-quality eval cannot see this. A tool-call-distribution invariant, declared once and pinned to a baseline, can.

The Eval Contract: Six Components, Fixed Order
The eval contract has six components, in fixed order, every cohort. The components are baseline, prompt set, invariants, scoring, threshold pinning, and drift detection. The same six-and-fixed-order discipline that the postmortem template uses works here for the same reason: predictable structure makes the artefact reviewable in a single pass, and the predictability is what lets the platform team accumulate a corpus of cohort contracts that all read the same way. A team running ten cohorts in production should have ten contract files that look identical in shape and differ only in the cohort-specific parts. If the files do not look identical, the contract has not been imposed; the folder is still a folder of snowflakes.
The baseline component is a frozen cohort of prompt-trace pairs, captured at a known point in time, version-controlled, and never edited after capture. The capture point matters because the baseline is the artefact that anchors every invariant; if the baseline drifts, the invariants drift, and the contract has nothing to compare against. The pattern that has worked is to capture the baseline at the point where the cohort first stabilises, write its hash into the contract file, and treat any change to the baseline as a contract version bump rather than as an in-place edit. A contract version bump is a real event that the change-management cadence has to approve, which keeps the baseline boring on purpose. Boring baselines are what make the rest of the contract trustworthy.
The prompt set component is the live set of prompts the cohort will run against, which differs from the baseline because the prompts are allowed to evolve as the cohort's production scope grows. The contract names the prompt set's source, the sampling rule, and the minimum size. The sampling rule is the one detail people get wrong; the rule has to be deterministic and seed-pinned so that the same contract run on the same model produces the same prompt set, which is what makes the eval results comparable across runs. A non-deterministic prompt set produces a contract whose pass-fail signal moves under random noise, which is operationally worse than no contract at all because the noise teaches the on-call engineer to ignore the gate.
The invariants component is the heart of the contract. It is a list of declared properties of the cohort's behaviour that must hold against the baseline. Each invariant has a name, a metric, a comparison rule, and a pinned threshold. The comparison rule is what makes the invariant work; a threshold floor only says average quality must be above 0.8, which is not enough to define an invariant. A real invariant says average quality must stay within two percent of the baseline at the same prompt-set sampling seed. The two-percent tolerance is pinned to the baseline; the absolute number is not. A new model that scores 0.78 on the cohort can pass the invariant if the baseline scored 0.79; an old model that scores 0.81 can fail the invariant if the baseline scored 0.84. The contract is about change, not about level.
The scoring component is the implementation detail of how each invariant's metric is computed. It is the part of the contract that lives in code, and it is the part that has to be unit-tested separately, because a contract whose scoring code is broken produces silent green-passing regressions exactly the way the snowflake eval folder did. The scoring code lives in a single module per metric, gets a unit test that runs against a known input and a known output, and gets reviewed at the same cadence as the contract itself. The unit test is what guards against the eval-drift failure mode I described earlier; if the scoring code changes, the unit test catches it, and the contract version bumps to acknowledge the scoring change.
The threshold-pinning component is the discipline that says every invariant's tolerance is checked into the contract file with a one-line rationale and a git-history justification. A tolerance change is a real event that requires a PR, a reviewer, and a written reason. The reason matters because tolerances drift toward looser thresholds over time as a natural response to flaky CI, and a tolerance change without a written reason is the operational signature that the team got tired of the alert and loosened the threshold. Pinning the threshold with a rationale forces the conversation to happen at PR time rather than at incident time, which is the conversation the contract is designed to provoke.
The drift-detection component is the failsafe that watches the baseline and the invariants for the kind of silent breakage that produced the eval-drift failure mode. The pattern that has worked is a weekly job that re-runs the contract against the baseline-producing model, the model that produced the baseline cohort in the first place, and pages if any invariant fails. The baseline-producing model has not changed; the baseline has not changed; the contract code may have changed; if the invariant fails against the baseline-producing model, the contract code has drifted and the failure is real. A drift-detection failure is an operational event, not a quality event, and it is the eval contract's way of self-testing.
1000 prompt-trace pairs"] --> B["Contract file
6 components"] B --> C["Invariant 1
avg-quality Δ<2%"] B --> D["Invariant 2
tool-call-dist KL<0.05"] B --> E["Invariant 3
retrieval-precision
Δ<3%"] B --> F["Invariant 4
latency-p95
Δ<10%"] B --> G["Invariant 5
cost-per-task
Δ<8%"] B --> H["Invariant 6
refusal-rate
Δ<1%"] C --> I{"All invariants
pass?"} D --> I E --> I F --> I G --> I H --> I I -- "yes" --> J["Promote canary
to production"] I -- "no" --> K["Block promotion
page on-call"]
Worked Example: The Tool-Call-Distribution Contract
The worked example I want to walk through is the one that retired the eval-gap-tool-call-distribution recurring factor in our retrospective. The cohort is a customer-support agent that has access to four tools: a search tool, a calculator tool, a calendar-lookup tool, and a knowledge-base retriever. The baseline cohort was captured in early February 2026 against the production model at that time, ran for one thousand customer-support prompts sampled from the live traffic at a fixed seed, and produced a tool-call distribution of approximately fifty percent search, twenty percent calculator, fifteen percent calendar-lookup, and fifteen percent knowledge-base. The contract for this cohort declares six invariants, but the one that did the work is the tool-call-distribution invariant. The implementation is the one shown below.
# evals/contracts/customer_support.py
from __future__ import annotations
import json
from collections import Counter
from pathlib import Path
from evals.base import EvalContract, Invariant
from evals.metrics import kl_divergence
BASELINE = Path("evals/baselines/customer_support_2026_02_03.jsonl")
PROMPT_SET = Path("evals/prompts/customer_support_live_seed_42.jsonl")
def tool_call_distribution(traces: list[dict]) -> dict[str, float]:
counts: Counter[str] = Counter()
for t in traces:
for call in t.get("tool_calls", []):
counts[call["tool"]] += 1
total = sum(counts.values()) or 1
return {tool: n / total for tool, n in counts.items()}
def avg_quality(traces: list[dict]) -> float:
scores = [t["quality"] for t in traces if "quality" in t]
return sum(scores) / len(scores) if scores else 0.0
CUSTOMER_SUPPORT = EvalContract(
name="customer_support",
baseline=BASELINE,
prompt_set=PROMPT_SET,
invariants=[
Invariant(
name="avg-quality-delta",
metric=avg_quality,
compare="delta_percent",
tolerance=2.0,
rationale="2% loss is below the per-incident threshold from PM-2026-01-04.",
),
Invariant(
name="tool-call-dist-kl",
metric=tool_call_distribution,
compare="kl_divergence",
tolerance=0.05,
rationale="0.05 KL is the tolerance that would have caught the March cohort drop.",
),
Invariant(
name="refusal-rate-delta",
metric=lambda ts: sum(t.get("refused", False) for t in ts) / len(ts),
compare="delta_absolute",
tolerance=0.01,
rationale="1pp absolute refusal rate change has paged on-call three times.",
),
],
drift_check_model="baseline_producer_v3",
)
# evals/base.py
from __future__ import annotations
from dataclasses import dataclass, field
from pathlib import Path
from typing import Callable, Any
@dataclass
class Invariant:
name: str
metric: Callable[[list[dict]], Any]
compare: str # "delta_percent" | "delta_absolute" | "kl_divergence"
tolerance: float
rationale: str
@dataclass
class EvalContract:
name: str
baseline: Path
prompt_set: Path
invariants: list[Invariant]
drift_check_model: str
version: int = 1
def baseline_traces(self) -> list[dict]:
return [json.loads(line) for line in self.baseline.read_text().splitlines()]
def evaluate(self, candidate_traces: list[dict]) -> list[dict]:
results = []
baseline_traces = self.baseline_traces()
for inv in self.invariants:
base_value = inv.metric(baseline_traces)
cand_value = inv.metric(candidate_traces)
passed, delta = self._compare(inv, base_value, cand_value)
results.append(dict(name=inv.name, passed=passed, delta=delta,
tolerance=inv.tolerance, rationale=inv.rationale))
return results
def _compare(self, inv: Invariant, base: Any, cand: Any) -> tuple[bool, float]:
if inv.compare == "delta_percent":
delta = abs(cand - base) / base * 100.0
return delta <= inv.tolerance, delta
if inv.compare == "delta_absolute":
delta = abs(cand - base)
return delta <= inv.tolerance, delta
if inv.compare == "kl_divergence":
from .metrics import kl_divergence
delta = kl_divergence(base, cand)
return delta <= inv.tolerance, delta
raise ValueError(f"unknown compare rule: {inv.compare}")
$ python -m evals.run customer_support --candidate models/sonnet_5_1.jsonl
contract=customer_support version=1
avg-quality-delta PASS delta=0.83% tolerance=2.0%
tool-call-dist-kl FAIL delta=0.073 tolerance=0.05
refusal-rate-delta PASS delta=0.004 tolerance=0.01
result=FAIL blocked promotion of models/sonnet_5_1.jsonl
The terminal output above is the one that mattered. The tool-call-dist-kl invariant flagged the candidate model's tool-call distribution as having drifted 0.073 KL from the baseline, against a 0.05 tolerance. The avg-quality invariant passed; the refusal-rate invariant passed; an old-style snowflake eval that scored only on average quality would have green-lit the promotion. The contract caught it because the tool-call-distribution invariant is declared, pinned, and gated. The block was correct. We dug into the trace data and found that the candidate model had shifted six percentage points of search-tool calls toward the knowledge-base tool, which on this cohort produced workflows that exceeded the per-step latency budget downstream. That is exactly the regression class the snowflake-eval pattern had been missing for six quarters.
Comparison: Snowflake Evals vs Contract Evals
The contrast worth drawing explicitly is between the snowflake eval folder and the contract-driven eval pattern. Both produce passing or failing scores; both run in CI; both gate canary promotion. The difference is in what the gate actually means, and the difference compounds over a year of cohort additions. A snowflake folder grows by one file per cohort, each file a slightly different shape, each scoring a slightly different metric, none of them sharing a baseline contract. A contract corpus grows by one file per cohort, each file the same shape, each declaring its invariants against the same base class, all of them comparable to each other and reviewable in a single afternoon at the quarterly retrospective.
The fix-velocity difference is what makes the move worth the seventy-two days of work. The LangChain report's longitudinal data on this is striking: among teams that adopted a contract-style eval pattern, the median time from "regression class first appears in production" to "regression class is invariant-pinned" was 38 days; among teams running snowflake evals, the same lag was 247 days. The 209-day gap is the cost of relitigating the same regression class six times because each new incident produces a new ad-hoc eval rather than a new invariant on an existing contract. The 38-day number is the cost of writing the invariant once, declaring its tolerance, getting it through PR review, and pinning it into the contract corpus. Both cost real engineering time; the contract pattern amortises the cost across the cohort's lifetime instead of paying it again per incident.
The on-call experience differs too. A snowflake eval failing at 02:00 produces a single Slack message that says the eval scored below the threshold, and the on-call engineer has to reverse-engineer which property of the model's behaviour actually changed. A contract eval failing at 02:00 produces a list of six invariant outcomes, five of them passing, one of them failing, and the failing one names exactly the property that regressed: tool-call-distribution KL divergence, 0.073 against a 0.05 tolerance. The on-call engineer can act on the second message without thinking. The first message produces a forty-minute investigation that ends with the engineer rolling back the model and writing a Slack thread asking somebody more senior whether the rollback was correct. The contract pattern produces an actionable signal; the snowflake pattern produces an ambiguous one.
The third difference, which is the one that pays off most quietly, is the cross-cohort invariant reuse. A platform with ten contract-driven cohorts can declare a tool-call-distribution invariant once in the base class and reuse it across all ten cohorts with cohort-specific tolerances. A platform with ten snowflake cohorts has the same invariant implemented ten different ways across ten files, with ten different tolerance constants, and any improvement to the invariant requires editing all ten files. The contract pattern's reuse is the part that produces compounding returns. The first contract is the same cost as the first snowflake; the tenth contract is roughly half the cost of the tenth snowflake because the invariants compose.
appears in production"] --> B{"Eval pattern
in place?"} B -- "Snowflake folder" --> C["Write new ad-hoc eval
file in evals/"] B -- "Contract corpus" --> D["Add invariant to
existing contract"] C --> E["Reviewer guesses
at threshold"] D --> F["Reviewer pins
tolerance with rationale"] E --> G["Eval drifts
silently"] F --> H["Drift check
catches breakage"] G --> I["Median 247 days
to pin"] H --> J["Median 38 days
to pin"] I --> K["Class recurs
in next quarter"] J --> L["Class retired
in next retrospective"]
CI Integration: Making the Contract Pageable
The CI integration is what turns the contract from a documentation artefact into an operational gate. The pattern that has worked is to wire the contract evaluation into the canary promotion pipeline as a blocking step, with the contract's invariant outcomes posted to the deployment Slack channel as a structured message and to the on-call rotation if any invariant fails. The Slack message is the one the on-call engineer reads at 02:00; the structured format is what makes the message readable without context. A contract that produces a one-line "FAIL" message at 02:00 is half a contract; the full contract produces the six-line breakdown the engineer can act on.
The wiring detail that matters is the ordering of the contract evaluation against the rest of the canary gate. The pattern that has worked is to run the contract before the integration smoke tests, not after. The reason is that contract failures are model-quality failures and integration smoke failures are infrastructure failures, and the on-call engineer's response to each is different: a contract failure means roll back the model, an integration failure means roll back the deployment. Surfacing the contract failure first lets the engineer make the model-vs-deployment call cleanly. The mistake teams make is running the integration tests first because they are faster, which produces a sequence where the engineer fixes the deployment issue, retries, and only then sees the contract failure, which adds twenty minutes to every incident.
The second wiring detail is the timeout discipline on the contract evaluation. A contract that runs for forty-five minutes against the canary's prompt set is operationally too expensive to run on every promotion; a contract that runs in under five minutes is cheap enough to run on every commit to the eval directory and every promotion gate. The pattern that has worked is to keep the prompt set at a thousand prompts, parallelise the model calls aggressively, and aim for a five-minute end-to-end runtime. Larger prompt sets do not improve the contract's signal in proportion to the runtime cost; the variance reduction from going from one thousand to five thousand prompts is small, and the cost is a five-times longer feedback loop, which is operationally bad.
The third wiring detail is the relationship between the contract and the model rollback path. A contract that fails has to produce an unambiguous signal that triggers an automatic rollback or a paged human decision; the worst outcome is a contract that fails and produces a Slack message that nobody owns. The pattern that has worked is to have the contract failure post to a channel the on-call rotation watches, page the on-call engineer if the failure is on a high-severity invariant like average-quality or refusal-rate, and auto-rollback if the contract was running on a production-traffic-mirroring canary rather than a synthetic one. The auto-rollback rule is the one most platforms hesitate to adopt because it feels aggressive; in practice, the auto-rollback rule retires the most expensive class of incidents inside one quarter, because the model never reaches enough live traffic to do real damage.
Production Considerations
The first production consideration is contract versioning, which deserves its own discipline because contracts version through their lifetime and the versioning has to be rigorous. The pattern that has worked is to store contract versions in the contract file's version field, increment it on any change to baseline, scoring code, or invariant tolerances, and keep the previous version's contract file in the git history. The previous version is what lets you reproduce a failed eval from six months ago; the version increment is what lets you tell whether two failed eval runs are comparable. A contract corpus without versioning is operationally indistinguishable from a snowflake folder, because every contract is its own implicit version and you cannot tell which versions are comparable.
The second consideration is what happens when the baseline-producing model is deprecated by the provider. The drift-detection check relies on being able to re-run the contract against the original baseline-producing model, and provider deprecation breaks that ability. The pattern that has worked is to maintain a fallback drift-check using a frozen artefact of the baseline-producing model's outputs against the prompt set, captured at baseline-creation time. The fallback is not a perfect drift check; it cannot catch scoring-code drift the same way the live re-run can. But it is good enough for ninety percent of drift cases and is the only path that survives provider deprecation. The discipline is to capture the fallback artefact at the same time as the baseline, not after the deprecation announcement when it is too late.
The third consideration is the cohort-vs-traffic-class boundary. The temptation when introducing the contract pattern is to write one contract per traffic class, which produces a small contract corpus that misses important sub-cohort regressions. The discipline that has worked is one contract per behavioural cohort, where a behavioural cohort is a slice of traffic with a coherent expected tool-call distribution and a coherent expected quality target. A traffic class might split into three behavioural cohorts: customer-support free-tier, customer-support paid-tier, and customer-support enterprise-tier, each with its own tool mix and its own latency budget. Three contracts per traffic class is roughly the number that produces the right granularity; one contract per traffic class is too coarse, ten contracts per traffic class is too fine.
The fourth consideration is the carry-forward register from the retrospective layer. A contract that catches a regression and blocks a promotion does not retire the regression class on its own; the architecture commitment that produced the contract has to be marked as shipped in the carry-forward register, and the next retrospective has to verify that the contributing-factor tag for that class drops to zero in the next quarter's postmortem corpus. If the tag does not drop, the contract is not actually retiring the class, which means either the invariant tolerance is too loose or the contract is missing an invariant that the regression slipped past. Either way, the next retrospective has to act on the data and tighten the contract. The carry-forward register is what makes the retrospective and the contract corpus into a closed loop instead of two parallel artefacts.
The fifth consideration is the cost of running the contract corpus continuously. A platform with ten cohort contracts, each running on every promotion against a thousand-prompt set, produces a non-trivial inference bill. The pattern that has worked is to run the contracts on the canary against the candidate model only, run drift-detection weekly against the baseline-producing model, and run a full corpus refresh quarterly at the retrospective. The quarterly refresh is what catches contracts that have silently drifted out of usefulness because the cohort itself has evolved away from the original baseline. The cost is bounded because the cadence is fixed; a platform that runs the full corpus on every commit will spend more on evals than on production traffic, which is operationally absurd.
Monetizing Eval-Contract Discipline
Eval contracts are not only an engineering hygiene move; they are a customer-trust artefact that can be packaged without turning reliability into theatre. A buyer does not need to read the full invariant implementation to value it. They need to know that a paid agent cannot be promoted without declared regression checks for the behaviours that matter to their workflow. The commercial promise is not that the model will never regress. The credible promise is that regressions are checked structurally before promotion, that the checks are versioned, and that exceptions leave an audit trail.
The packaging line I would draw is simple. Standard customers get contract-backed canary gates for shared cohorts. SLA-bound customers get invariant summaries in the reliability report, including which behavioural cohorts were checked, when the last baseline refreshed, and whether any promotion was blocked. Strategic accounts get cohort-specific regression guarantees when their traffic has enough volume to justify a dedicated behavioural cohort. This keeps the offer grounded in actual platform work rather than a vague quality claim. It also gives customer success a concrete answer when a buyer asks how agent quality is controlled after launch.
The cost-control argument matters as much as the revenue argument. A single invariant reused across cohorts prevents the team from rewriting the same ad-hoc eval after every incident. That makes reliability cheaper to maintain as the customer base grows. The operating rule is blunt: no paid agent promotion without a contract outcome attached. If the contract passes, the promotion record can be shown in renewal conversations. If the contract fails, the blocked promotion becomes proof that the reliability system is doing useful work before customers absorb the regression.
Conclusion
The eval contract is the part of the ADLC loop that decides whether the team's evals are doing system-level work or just incident-level work. A team that ships ad-hoc evals for a year against a folder of snowflakes will produce a quarterly retrospective full of eval-gap-* recurring factors that point at different cohort-quality slips, get a different proximate eval-fix shipped against each one, and recur in the next quarter's postmortems with the same proximate fix shipped again. The work is real; the loop closed at the wrong layer. A team that adopts the eval-contract pattern will see the eval-gap-* family of recurring factors drop to near zero inside two cycles, because the architecture commitment that the retrospective forces is the contract that retires the regression class. The discomfort of writing the first contract is exactly the discomfort of committing to a base class that every cohort eval has to conform to, and the conformance is the part that closes the system-level loop.
The next post in this cluster will work through contract drift detection at scale, which is the artefact the contract corpus needs once the corpus crosses ten or so contracts and the manual drift-check pattern no longer scales. Drift detection is the layer above the contract that catches the contract's own scoring code regressing without ceremony, and it deserves its own deep-dive because the move from manual drift checks to automated invariant attestations is the point where most agent platforms either stabilise the contract corpus or watch it drift into another folder of snowflakes. Postmortems fix individual incidents, retrospectives fix recurring contributing factors, eval contracts fix the regression class, and drift detection fixes the contract code itself. Each layer closes a different loop; together they close the system.
If you are starting from scratch, the order I recommend is: ship the cohort eval folder, then the contract base class, then convert one ad-hoc eval at a time into a contract, then add the drift-detection job, and only then introduce the carry-forward register linkage. The contract base class relies on baseline capture and prompt-set determinism, which the cohort eval folder produces; introducing the base class before the cohorts exist produces a contract with nothing to evaluate. The cadence layers from the bottom. Companion code for the eval-contract base class and the customer-support cohort example are in the adlc-eval-contracts directory of the amtocbot-examples repository.
Revision History
| Date | Summary | Old Version |
|---|---|---|
| 2026-06-08 | Added explicit attribution for the LangChain eval-pattern claim, converted direct quote phrasing into indirect wording, and added a monetization section connecting eval contracts to customer trust, reliability packaging, and regression-cost control. | View original |
Sources
- LangChain. State of Agent Engineering. April 2026. https://www.langchain.com/state-of-agent-engineering
- Datadog. State of AI Engineering Report 2026. April 2026. https://www.datadoghq.com/state-of-ai-engineering/
- Anthropic. Evaluating Frontier Models. https://www.anthropic.com/research/evaluating-models
- OpenAI. Evals: Best Practices for LLM Evaluation. https://github.com/openai/evals
- HumanLoop. Cohort-Based Evaluation for LLM Applications. https://humanloop.com/blog/cohort-evaluation
- Google SRE Workbook. Postmortem Action Items. https://sre.google/workbook/postmortem-culture/
About the Author
Toc Am
Founder of AmtocSoft. Writing practical deep-dives on AI engineering, cloud architecture, and developer tooling. Previously built backend systems at scale. Reviews every post published under this byline.
Published: 2026-05-06 · Updated: 2026-06-08 · Written with AI assistance, reviewed by Toc Am.
Get These In Your Inbox
Weekly deep-dives on AI engineering, no fluff. Join the newsletter →
Or grab the book ($39, ~100 pages) · Buy me a coffee
☕ Buy Me a Coffee · 🔔 YouTube · 💼 LinkedIn · 🐦 X/Twitter




No comments:
Post a Comment