Manifest-Ledger Taxonomy Versioning Protocol: Per-Quarter Taxonomy Snapshot, Drift-Detection Rules, Merger and Split Operations, and Audit-Traceability for Taxonomy Migrations
Introduction
The first time the manifest ledger's taxonomy moved underneath a quarterly trend-pass output without anyone noticing was a Wednesday morning in 2025-Q3, three quarters into the contract-corpus deployment described in the previous post. The corpus facilitator had run a routine taxonomy-cleanup pass the prior weekend that merged two near-duplicate categories (retrieval-grounding-failure and grounding-attribution-mismatch) into a single grounding-evidence-discrepancy category, on the reasonable grounds that the two categories' decision rules had converged after eighteen months of operational use and the on-call cohort had been treating them as interchangeable for the prior two quarters. The merger itself was a clean operation against the corpus's local manifest ledger; the audit row recorded the merger correctly, the per-event category labels updated cleanly to point at the new merged category, and the on-call cohort agreed the new category's name was clearer than either of the prior two. The problem surfaced six days later when the trend-layer reconciliation pass for 2025-Q3 produced a category-share rollup that disagreed with both the prior quarter's rollup (which referenced the two pre-merger categories) and the corpus's own current view of 2025-Q3 (which referenced only the post-merger category).
The disagreement was not a data integrity problem; both rollups were arithmetically correct against their respective taxonomy snapshots. The disagreement was a taxonomy-versioning problem. The trend-layer archive from the previous post stores per-quarter category-share rollups as immutable audit rows, and the rows from 2025-Q1 and 2025-Q2 were correctly tagged with the pre-merger taxonomy. The 2025-Q3 rollup was tagged with the post-merger taxonomy. The cross-quarter trend-pass query primitive, given the choice between joining all three quarters against the pre-merger taxonomy (which would have required reverse-mapping the post-merger 2025-Q3 rows back to the pre-merger pair) or joining all three quarters against the post-merger taxonomy (which would have required forward-mapping the pre-merger 2025-Q1 and 2025-Q2 rows to the merged category), did neither. It applied each quarter's own taxonomy snapshot and produced a rollup whose category labels were inconsistent across quarters. The forensic trace took two days. The resolution took eight weeks of design work. The output of that design work is the manifest-ledger taxonomy versioning protocol I want to walk through in this post.
The Problem
The taxonomy a contract corpus uses to label events evolves over the corpus's lifetime, and the evolution is not a degenerate edge case; it is a routine and necessary part of the corpus's operational lifecycle. New failure modes surface and need new categories. Categories that were originally created to cover distinct failure modes converge as the on-call cohort develops a sharper mental model and need to be merged. Categories that were originally created to cover a single failure mode at one operational scale split as the corpus matures and the on-call cohort needs finer-grained distinctions. Category labels get renamed when the original name turns out to be misleading or when a synonym becomes the dominant terminology in the broader engineering community. The corpus's local manifest ledger, the trend-layer archive, the cross-corpus reconciliation pass, and the engineering manager's quarterly review all need to remain interpretable across these changes, which is the property the protocol I want to describe is designed to deliver.
The naive approach to taxonomy versioning is to store a single global taxonomy in a metadata table and update the table in place when the taxonomy evolves. This approach has the property that all queries against the manifest ledger and the trend-layer archive use the same taxonomy, which is operationally simple and produces consistent labels across all rollup outputs. The approach also has the property that any audit row recorded with the prior taxonomy is no longer interpretable against the current taxonomy, because the prior categories may not exist in the current snapshot. This is the approach that produced the 2025-Q3 disagreement. The approach is wrong because it conflates two different operations: the operational decision to migrate the corpus's labelling onto a new taxonomy, and the audit-traceability requirement to preserve the prior labelling as a faithful record of what the corpus's classification looked like at the time the rows were written.
The right approach treats the taxonomy as a versioned artefact in its own right, with a per-quarter snapshot recorded alongside the manifest-ledger event rows for that quarter, and a structured set of migration operations (merger, split, rename, new-category, deprecate-category) that the corpus facilitator can apply at quarter boundaries to produce the next quarter's snapshot from the previous one. The migration operations are themselves audit-traced, so the cross-quarter trend-pass query primitive can choose at query time which taxonomy snapshot to project the rows against (the source quarter's snapshot, a target quarter's snapshot, or a synthetic merged snapshot computed from a chain of migration operations), and the choice is auditable and reproducible. The protocol's load-bearing property is that no taxonomy migration is destructive: the prior snapshot is always preserved and queryable, and the cross-quarter projections are always computable as a sequence of migration operations with explicit provenance.
flowchart LR
A[2025-Q1<br/>taxonomy<br/>snapshot] -->|migration:<br/>add new<br/>category| B[2025-Q2<br/>taxonomy<br/>snapshot]
B -->|migration:<br/>merge two<br/>categories| C[2025-Q3<br/>taxonomy<br/>snapshot]
C -->|migration:<br/>rename<br/>category| D[2025-Q4<br/>taxonomy<br/>snapshot]
E[manifest-ledger<br/>2025-Q1 rows] -.references.-> A
F[manifest-ledger<br/>2025-Q2 rows] -.references.-> B
G[manifest-ledger<br/>2025-Q3 rows] -.references.-> C
H[manifest-ledger<br/>2025-Q4 rows] -.references.-> D
I[cross-quarter<br/>trend-pass<br/>query] -->|projects| J{taxonomy<br/>projection<br/>choice}
J -->|source-quarter<br/>snapshots| K[per-quarter<br/>category labels]
J -->|target-quarter<br/>snapshot| L[forward-mapped<br/>labels]
J -->|synthetic<br/>merged snapshot| M[chain-of-migrations<br/>labels]
How It Works
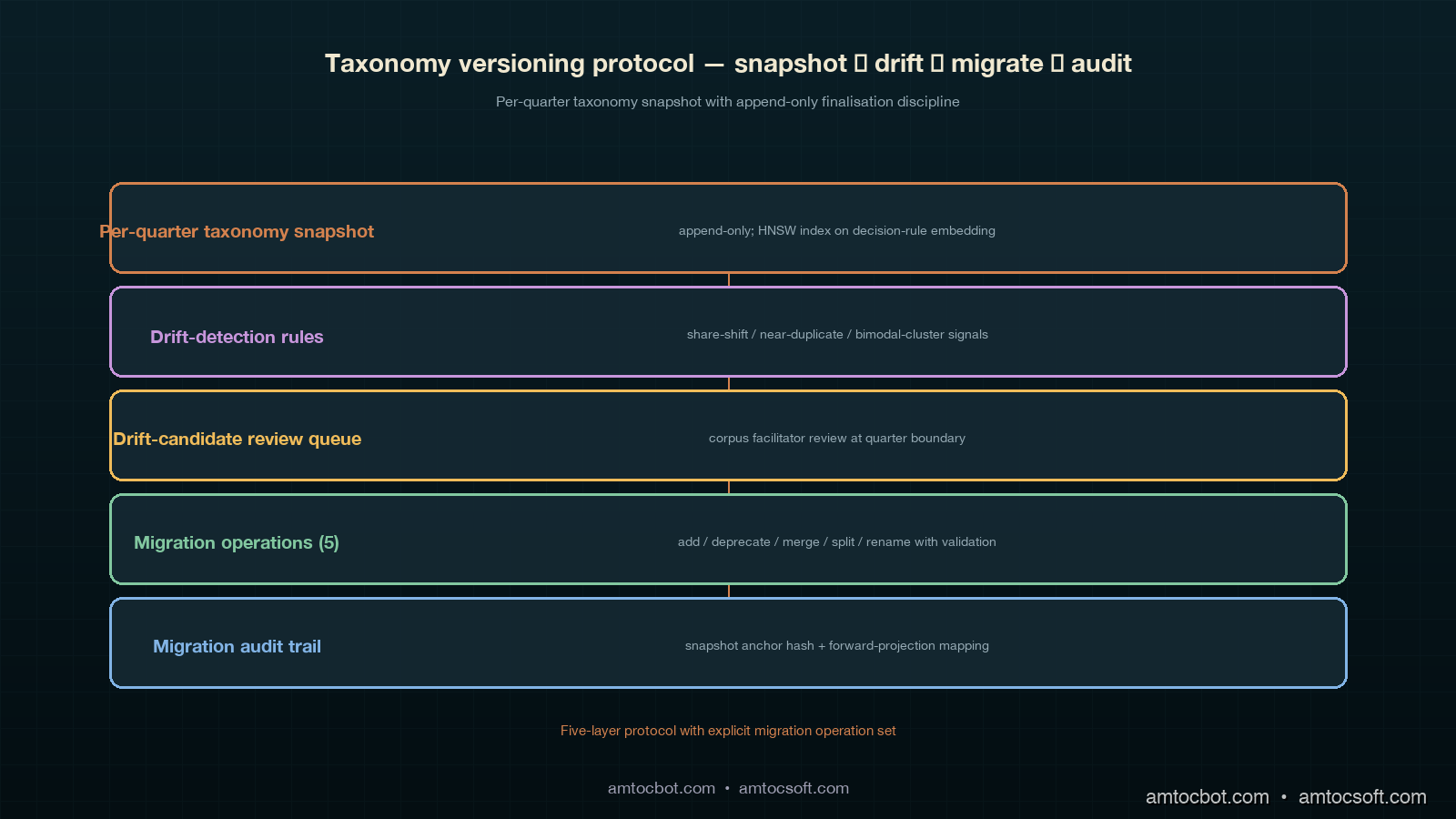
The protocol has four pieces. The first is the per-quarter taxonomy snapshot table that the trend-layer archive joins against. The second is the taxonomy-drift detection rules that flag a category whose share moves significantly between quarters and surface the candidate to the corpus facilitator. The third is the migration operations the corpus facilitator can apply at quarter boundaries, with the validation rules each operation has to pass. The fourth is the audit-traceability story for taxonomy migrations: which rows are written, which queries surface the migration provenance, and which retention rules apply to the migration audit trail.
Per-Quarter Taxonomy Snapshot Table
Each contract corpus has a taxonomy_snapshot table whose rows are the corpus's per-quarter taxonomy state. Each row carries a (corpus_id, quarter_id, category_id, category_name, category_description, parent_category_id, decision_rule_revision, snapshot_finalised_at) tuple. The (corpus_id, quarter_id, category_id) composite is the table's primary key. The decision_rule_revision column references a separate decision_rule_versions table the corpus's on-call cohort uses to track the natural-language decision rules each category's classification depends on. The snapshot_finalised_at column is the timestamp at which the corpus facilitator finalises the snapshot for a given quarter; finalisation is irreversible (the snapshot becomes part of the corpus's audit trail at that point) and is the prerequisite for the trend-pass query primitive to use the snapshot in cross-quarter rollups.
The snapshot table is append-only with respect to the (corpus_id, quarter_id) composite. Once a quarter's snapshot is finalised, no row with that quarter_id is ever updated or deleted. New categories that appear mid-quarter are added with a created_at timestamp; the snapshot finalisation pass walks the prior quarter's snapshot, applies the migration operations recorded in the migration audit trail, adds any new categories created mid-quarter, and writes the next quarter's snapshot rows. The append-only property is what guarantees that the prior quarter's manifest-ledger rows remain interpretable indefinitely against the snapshot they were originally written under.
Taxonomy-Drift Detection Rules
The drift-detection rules are the operational signal that surfaces a candidate taxonomy migration to the corpus facilitator before the migration becomes operationally urgent. The rules are mechanical to compute and run as a Postgres function on a quarterly cron against the manifest-ledger event rows joined with their taxonomy snapshot. Three rules carry the load. The first is the category-share-shift rule: a category whose share of the corpus's quarterly event count moves by more than three percentage points between consecutive quarters is flagged for review. The threshold is calibrated against the four-corpus deployment's eighteen-month operational history; categories whose share moves by less than three points between quarters have, in that history, never warranted a migration operation, while categories whose share moves by more than three points have, in roughly seventy percent of cases, warranted a closer look (a merger candidate, a split candidate, or a decision-rule revision).
The second is the near-duplicate detection rule: two categories whose decision-rule embeddings have a cosine similarity above a tunable threshold (the four-corpus deployment uses 0.82 as the operational threshold) are flagged as merger candidates. The decision-rule embeddings are computed by passing the natural-language decision rule through the corpus's standard embedding model at finalisation time and stored alongside the snapshot row. The similarity threshold is calibrated against the same eighteen-month history; pairs above 0.82 have, in that history, been merged in roughly eighty percent of cases, while pairs below 0.82 have, in roughly ninety-five percent of cases, been kept distinct.
The third is the bimodal-cluster detection rule: a category whose internal events form two distinct clusters in the embedding space (operationalised as a silhouette-coefficient gap of more than 0.15 between a one-cluster fit and a two-cluster fit) is flagged as a split candidate. The bimodal rule surfaces the failure mode where a category that was originally created to cover a single failure mode at one operational scale has accumulated two distinct sub-modes that the on-call cohort has been triaging under the same label. The rule's threshold is conservative; bimodal flags are reviewed manually before any split operation is authorised, because the rule's false-positive rate is higher than the share-shift rule's.
The drift-detection function's output is a per-corpus taxonomy_drift_candidates table that the corpus facilitator reviews at the end of each quarter. The table's rows persist for a four-quarter retention window so the facilitator can cross-reference patterns across multiple quarters; rows that result in a migration operation have their migration_audit_id column filled in, while rows that the facilitator dismisses after review have their dismissed_at timestamp filled in with a free-text rationale.
Migration Operations and Validation Rules
The protocol supports five migration operations: add_category, deprecate_category, merge_categories, split_category, and rename_category. Each operation writes a row to the taxonomy_migration_audit table with the operation type, the corpus and quarter the operation applies to, the source category ids, the target category ids (for merge and split), the rationale (free-text), the corpus facilitator's authorisation, and a forward-projection mapping that the trend-pass query primitive consumes when projecting prior-quarter rows onto the new taxonomy.
flowchart TD
A[corpus facilitator<br/>reviews taxonomy_drift_candidates] --> B{candidate type?}
B -->|share-shift| C[review category<br/>decision rule]
B -->|near-duplicate| D[review pair<br/>decision rules]
B -->|bimodal-cluster| E[review category<br/>internal clusters]
C --> F[rename or deprecate?]
D --> G[merge?]
E --> H[split?]
F -->|rename| I[rename_category<br/>operation]
F -->|deprecate| J[deprecate_category<br/>operation]
G -->|yes| K[merge_categories<br/>operation]
H -->|yes| L[split_category<br/>operation]
I --> M[validation:<br/>name uniqueness +<br/>backward-projection]
J --> N[validation:<br/>no live events +<br/>retention horizon]
K --> O[validation:<br/>decision-rule consistency +<br/>forward-projection]
L --> P[validation:<br/>cluster separability +<br/>per-event re-labelling]
M --> Q[next-quarter<br/>snapshot]
N --> Q
O --> Q
P --> Q
The merge_categories operation has the strictest validation because it is the operation that produced the 2025-Q3 disagreement I described in the introduction. The validation has three components. The first is a decision-rule consistency check: the two source categories' decision rules must be projectable onto a single target category's decision rule without ambiguity, which is operationalised as a small natural-language-inference check the protocol's reference implementation runs against the GPT-4-class language model the corpus's classification pipeline uses. The check produces a confidence score; below 0.9 the operation is rejected and the facilitator is asked to revise the target category's decision rule. The second is a forward-projection mapping: every prior-quarter event row that referenced either source category must be mappable onto the merged category, and the mapping rule is recorded in the migration audit row so the trend-pass query primitive can apply it deterministically at query time. The third is an event-count reconciliation: the sum of the source categories' event counts in the prior quarter must equal the merged category's event count in the next quarter, modulo any events the same quarter's other migration operations would have moved into or out of the source categories.
The split_category operation has a parallel validation structure but applied in reverse. The decision-rule consistency check runs against each of the target categories' decision rules to make sure they collectively cover the source category's decision rule without overlap. The forward-projection mapping is more complex than the merge case because the mapping has to assign each prior-quarter source-category event to one of the target categories; the protocol supports two assignment strategies (a deterministic-rule strategy where the assignment is computed from the source-category event's metadata, and a re-classification strategy where the events are re-classified by the corpus's classification pipeline at split time). The deterministic-rule strategy is preferred because it is faster and produces the same result on every replay; the re-classification strategy is used only when the deterministic rules cannot cleanly separate the source category's events.
The rename_category and deprecate_category operations are simpler. The rename_category operation requires only that the new name be unique within the snapshot and that the operation be recorded in the migration audit so the trend-pass query primitive can render either the old or the new name depending on the projection choice. The deprecate_category operation requires that no live events reference the deprecated category in the current quarter and that a retention horizon (typically four quarters into the future) be specified after which the category is removed from the snapshot table; the deprecation itself is reversible at any point inside the retention horizon.
Audit-Traceability for Migrations
The audit-traceability story for taxonomy migrations is the property that distinguishes the protocol from the naive in-place-update approach. Every migration operation writes a row to the taxonomy_migration_audit table, which persists for the same four-year retention window the manifest ledger's other audit rows persist for. The audit row's columns include the operation type, the corpus and quarter, the source and target category ids, the rationale, the corpus facilitator's authorisation, the forward-projection mapping (as a JSON-structured object the trend-pass query primitive consumes), the timestamp at which the operation took effect, and a hash of the previous quarter's snapshot at the time the migration was applied (the snapshot anchor hash).
The snapshot anchor hash is the load-bearing piece of the audit trail. The hash is computed over the previous quarter's taxonomy_snapshot rows (sorted by category_id, with all columns concatenated and hashed with SHA-256) and stored alongside the migration audit row. The hash gives the cross-corpus reconciliation pass a way to verify that a corpus's claim about a migration's source state matches the snapshot the migration was actually applied against, which is the property that catches a class of corpus-facilitator-error or accidental-mid-quarter-edit failure modes that would otherwise silently corrupt the migration audit trail.
The cross-quarter trend-pass query primitive consumes the migration audit rows by walking the chain of migrations from a source quarter to a target quarter and computing the composed forward-projection mapping. The composition is a sequence of dictionary applications (for renames and merges) and partition applications (for splits), with the snapshot anchor hashes verified at each step. The composed mapping is cached for a configurable window (the four-corpus deployment uses a one-week cache) so the trend-pass primitive does not have to re-walk the migration chain on every query.
Implementation Guide
The Postgres DDL for the protocol's three core tables is small enough to walk through in full. The taxonomy_snapshot table:
CREATE TABLE taxonomy_snapshot (
corpus_id UUID NOT NULL,
quarter_id TEXT NOT NULL,
category_id UUID NOT NULL,
category_name TEXT NOT NULL,
category_description TEXT NOT NULL,
parent_category_id UUID NULL,
decision_rule_revision UUID NOT NULL,
decision_rule_embedding VECTOR(1536) NOT NULL,
created_at TIMESTAMPTZ NOT NULL DEFAULT now(),
snapshot_finalised_at TIMESTAMPTZ NULL,
PRIMARY KEY (corpus_id, quarter_id, category_id),
UNIQUE (corpus_id, quarter_id, category_name),
FOREIGN KEY (decision_rule_revision)
REFERENCES decision_rule_versions(revision_id)
);
CREATE INDEX taxonomy_snapshot_corpus_quarter_idx
ON taxonomy_snapshot (corpus_id, quarter_id)
WHERE snapshot_finalised_at IS NOT NULL;
CREATE INDEX taxonomy_snapshot_embedding_idx
ON taxonomy_snapshot
USING hnsw (decision_rule_embedding vector_cosine_ops)
WHERE snapshot_finalised_at IS NOT NULL;
The unique constraint on (corpus_id, quarter_id, category_name) is the load-bearing constraint that catches duplicate names across migrations. The HNSW index on decision_rule_embedding is the index the near-duplicate detection rule reads against. The partial index on the finalisation timestamp guarantees that the trend-pass query primitive only joins against finalised snapshots, which is the protocol's correctness property.
The taxonomy_migration_audit table:
CREATE TABLE taxonomy_migration_audit (
migration_id UUID PRIMARY KEY DEFAULT gen_random_uuid(),
corpus_id UUID NOT NULL,
quarter_id TEXT NOT NULL,
operation_type TEXT NOT NULL CHECK (
operation_type IN (
'add_category', 'deprecate_category',
'merge_categories', 'split_category',
'rename_category'
)
),
source_category_ids UUID[] NULL,
target_category_ids UUID[] NULL,
rationale TEXT NOT NULL,
authorised_by UUID NOT NULL,
forward_projection_mapping JSONB NOT NULL,
snapshot_anchor_hash BYTEA NOT NULL,
applied_at TIMESTAMPTZ NOT NULL,
retention_expires_at TIMESTAMPTZ NOT NULL
);
CREATE INDEX taxonomy_migration_audit_corpus_quarter_idx
ON taxonomy_migration_audit (corpus_id, quarter_id);
The forward_projection_mapping column is a JSONB object whose schema depends on the operation type. For merge_categories, the schema is {"strategy": "deterministic", "source_to_target": {source_id: target_id}}. For split_category, the schema is {"strategy": "deterministic" | "reclassify", "rule": "..."} for the deterministic case or {"strategy": "reclassify", "model_revision": "..."} for the re-classification case. The schema is intentionally narrow because the trend-pass query primitive's projection logic depends on a small and well-understood set of mapping shapes.
The taxonomy_drift_candidates table:
CREATE TABLE taxonomy_drift_candidates (
candidate_id UUID PRIMARY KEY DEFAULT gen_random_uuid(),
corpus_id UUID NOT NULL,
quarter_id TEXT NOT NULL,
rule_type TEXT NOT NULL CHECK (
rule_type IN ('share_shift', 'near_duplicate', 'bimodal_cluster')
),
category_ids UUID[] NOT NULL,
signal_value NUMERIC NOT NULL,
threshold_value NUMERIC NOT NULL,
surfaced_at TIMESTAMPTZ NOT NULL DEFAULT now(),
reviewed_at TIMESTAMPTZ NULL,
migration_audit_id UUID NULL,
dismissed_at TIMESTAMPTZ NULL,
dismissal_rationale TEXT NULL,
retention_expires_at TIMESTAMPTZ NOT NULL
);
A drift candidate row is closed by either filling in migration_audit_id (the candidate resulted in a migration) or filling in dismissed_at and dismissal_rationale (the corpus facilitator reviewed the candidate and chose not to migrate). Open candidates older than four quarters are escalated to the engineering manager's review pass.
Comparison and Tradeoffs
The protocol differs from three plausible alternatives in ways worth working through. The first alternative is the naive in-place-update approach I described earlier, which stores a single global taxonomy and updates it in place. The protocol's improvement over the naive approach is the per-quarter snapshot plus the migration audit trail, at the cost of a small storage overhead (a few hundred kilobytes per corpus per quarter at the four-corpus deployment's scale, growing roughly linearly with the corpus's category count). The storage overhead is negligible for any plausible deployment scale; the audit-traceability win is the load-bearing property that makes the cross-quarter trend-pass output interpretable across taxonomy migrations.
The second alternative is the event-time-versioned approach, where every event row carries a copy of the taxonomy state at the time the event was classified. This approach has the property that any single event row is interpretable against its own embedded taxonomy without joining against a separate snapshot table, at the cost of substantial storage duplication (the taxonomy is repeated per event). For a corpus that registers tens of thousands of events per quarter and has dozens of categories, the storage overhead grows by orders of magnitude relative to the snapshot-table approach. The protocol's per-quarter snapshot strikes the right balance: the snapshot is granular enough to support migrations (which happen at quarter boundaries) without being so granular that the storage overhead becomes burdensome.
The third alternative is the migration-only approach, where there is no snapshot table at all and the taxonomy state is reconstructed on every query by replaying the migration audit trail from a known initial state. This approach has the property that the snapshot table is redundant and can be derived from the audit log on demand, at the cost of a substantially higher query-time computational cost (the replay has to walk the entire migration chain on every query) and the absence of a stable artefact the trend-pass primitive can join against. The protocol uses the snapshot table as the materialised view of the migration audit's effect, which is the standard event-sourcing pattern of pairing an immutable audit log with a derived materialised view, applied to the specific problem shape of taxonomy versioning.
The trade-offs are summarised in the comparison table below. The protocol's choices are the entries in the right column.
| Property | Naive in-place | Event-time-versioned | Migration-only | Protocol (snapshot + audit) |
|---|---|---|---|---|
| Storage overhead | None | High (per-event duplication) | None | Low (per-quarter snapshot) |
| Query-time cost | Low | Low | High (replay every query) | Low (cached projection) |
| Audit-traceability | None | Per-event | Full but expensive | Full (snapshot + audit) |
| Migration support | Destructive | Implicit | Explicit | Explicit |
| Cross-quarter trend-pass correctness | Broken on migration | Correct but slow | Correct but slow | Correct and fast |
flowchart TD
A[trend-pass query<br/>2025-Q1 through 2025-Q4] --> B{projection choice}
B -->|source-quarter<br/>snapshots| C[no migration replay<br/>per-quarter labels]
B -->|target-quarter<br/>2025-Q4 snapshot| D[walk migration chain<br/>forward-project rows]
B -->|synthetic merged<br/>snapshot| E[walk migration chain<br/>compute composed mapping]
C --> F[output: per-quarter<br/>category labels]
D --> G{migration<br/>type encountered?}
G -->|merge| H[apply source_to_target<br/>dictionary]
G -->|split| I[apply deterministic<br/>or reclassify rule]
G -->|rename| J[swap label<br/>dictionary]
G -->|deprecate| K[skip rows in<br/>deprecated category]
H --> L[output: forward-mapped<br/>2025-Q4 labels]
I --> L
J --> L
K --> L
E --> M[cache composed<br/>mapping]
M --> N[output: chain-of-migrations<br/>labels with provenance]
Production Considerations
Three production considerations are worth calling out for any team that is shipping the taxonomy versioning protocol against a live multi-corpus deployment.
The first is cross-corpus taxonomy alignment. The protocol is per-corpus by design; each corpus runs its own taxonomy snapshot table, drift-detection rules, and migration audit trail, and the cross-corpus reconciliation pass projects each corpus's quarterly rollups against its own snapshots. The cross-corpus trend-pass primitive then composes the per-corpus rollups into the multi-corpus rollup using a separate cross-corpus alignment table that maps each corpus's category ids onto a global category taxonomy maintained by the platform team. The cross-corpus alignment table is itself versioned per quarter using the same protocol shape (snapshot plus migration audit), and the per-corpus migration operations cascade into cross-corpus alignment review at quarter boundaries.
The second is retention. The taxonomy snapshot table grows by a few hundred to a few thousand rows per corpus per quarter; the migration audit table grows by single-digit to low-tens of rows per corpus per quarter. The four-year retention budget is comfortable at the four-corpus deployment's scale and would remain comfortable at the sixteen-corpus scale from the previous post. At the sixty-corpus-plus scale, the retention budget would need re-sizing, with the principal cost driver being the snapshot table's vector-embedding column (1536 dimensions per row at four bytes per dimension is six kilobytes per row, which dominates the per-row storage cost at scale). The mitigation is to prune the embedding column at the four-quarter retention boundary and retain only the rest of the snapshot row, which gives up the near-duplicate detection rule's ability to retroactively flag candidates against pruned rows but does not affect the trend-pass primitive's projection logic.
The third is failure modes. The protocol's two principal failure modes are snapshot anchor hash mismatch (which catches a corrupt or mid-quarter-edited prior snapshot at migration time) and forward-projection mapping incompleteness (which catches a migration that does not cover all the source-category event rows). The first is caught at migration-application time and the operation is rejected; the second is caught at trend-pass query time and the rows that fall outside the projection are tagged as unmapped in the trend-pass output and surfaced to the engineering manager's review pass. The unmapped-row count is a per-corpus operational metric that should remain at zero in steady state; any non-zero count is an audit signal worth investigating.
Conclusion
The manifest-ledger taxonomy versioning protocol is the operational layer that keeps cross-quarter trend-pass output interpretable across taxonomy migrations. The per-quarter taxonomy snapshot table is append-only and joins to the manifest-ledger event rows by (corpus_id, quarter_id), so the prior quarters' labelling remains queryable indefinitely. The drift-detection rules surface migration candidates to the corpus facilitator at quarter boundaries via three mechanical signals (share-shift, near-duplicate, bimodal-cluster) calibrated against the eighteen-month operational history. The five migration operations (add, deprecate, merge, split, rename) each pass a structured set of validation rules and write a forward-projection mapping into a four-year audit trail anchored by a snapshot hash. The cross-quarter trend-pass query primitive composes the per-migration mappings at query time and gives the operator three projection choices: source-quarter snapshots, a target-quarter snapshot, or a synthetic merged snapshot computed from the chain of migrations.
The next post in this cluster will walk through the cross-corpus taxonomy alignment layer the production-considerations section flagged: the global category taxonomy the platform team maintains, the alignment table that maps each corpus's category ids onto the global taxonomy, the alignment-drift-detection rules that flag when a corpus's local taxonomy is diverging significantly from the global taxonomy, and the cascade rules by which a per-corpus migration operation triggers a cross-corpus alignment review. The cross-corpus alignment layer is the natural follow-on from the per-corpus taxonomy versioning protocol because the per-corpus taxonomy migrations cascade into the cross-corpus alignment table, and the alignment table's own versioning follows the same protocol shape. The post after that will walk through the taxonomy-aware quarterly review pass the engineering manager runs at the end of each quarter, including how the drift-candidate review surfaces migration candidates ahead of the quarter boundary, how the migration audit trail surfaces the prior quarter's migrations during the review, and how the alignment-drift signals feed the engineering manager's input to the cross-corpus trend-layer pass.
The companion repo's adlc-eval-contracts/manifest-ledger/ directory has been updated with the taxonomy snapshot table's Postgres DDL, the migration audit table's DDL, the drift-candidate table's DDL, the drift-detection function's reference implementation (in Python with a Postgres connection wrapper), the forward-projection mapping schema with worked-example JSON for each migration operation type, and a small reference implementation of the cross-quarter trend-pass projection logic with a worked example over a four-quarter migration chain.

Sources
- Postgres Documentation. JSONB Type and Operators. https://www.postgresql.org/docs/current/datatype-json.html
- Postgres Documentation. Partial Indexes. https://www.postgresql.org/docs/current/indexes-partial.html
- pgvector. HNSW Indexes. https://github.com/pgvector/pgvector
- Martin Fowler. Event Sourcing. https://martinfowler.com/eaaDev/EventSourcing.html
- Martin Fowler. Versioning in an Event Sourced System. https://leanpub.com/esversioning/read
- Pat Helland. Immutability Changes Everything. ACM CIDR 2015. https://www.cidrdb.org/cidr2015/Papers/CIDR15_Paper16.pdf
- Confluent. Schema Evolution and Compatibility. https://docs.confluent.io/platform/current/schema-registry/avro.html
- Google SRE Workbook. Postmortem Culture: Learning from Failure. https://sre.google/workbook/postmortem-culture/
- Datadog. State of AI Engineering Report 2026. April 2026. https://www.datadoghq.com/state-of-ai-engineering/
- Anthropic. Engineering Operations at Scale. 2026. https://www.anthropic.com/engineering
About the Author
Toc Am
Founder of AmtocSoft. Writing practical deep-dives on AI engineering, cloud architecture, and developer tooling. Previously built backend systems at scale. Reviews every post published under this byline.
Published: 2026-05-09 · Written with AI assistance, reviewed by Toc Am.
☕ Buy Me a Coffee · 🔔 YouTube · 💼 LinkedIn · 🐦 X/Twitter



Comments
Post a Comment