Introduction
The first time the cross-team retrospective syndication format I described in the previous post ran into a wall was not when the third product team joined the platform team's syndication pass. It was when the second corpus came online. The platform team had spent three quarters running the retrospective syndication on a single contract corpus, the customer-facing one, with the recommender team and the transactions team as the two adjacent product teams. The format worked. The cross-team register stayed honest, the consultation requirement caught two cache changes that would otherwise have surprise-paged adjacent on-call rotations, and the manager review converged in fifty minutes flat. Then the internal-tools team finished their own contract corpus, the one that backs the developer-facing internal RAG endpoint plus the support-ticket summariser plus the meeting-notes agent, and asked to plug into the same syndication pass. We did not realise at the time that plugging a second corpus into a syndication format designed for one corpus was a different operation from adding a third team to the existing syndication.
The Tuesday morning the second-corpus syndication went off the rails was easy to recognise from where I was sitting. The platform team's three-team syndication pass had been running for forty-five minutes when the internal-tools tech lead joined the call to present his team's cross-team candidates list. By the time he had presented his eight candidates, the meeting had been running an hour and twenty minutes. The categorical pass was clean enough. The topology pass was workable. The routing pass was where the format collapsed: the syndication facilitator was supposed to write each candidate into the cross-team register with owning-team and hosting-team columns, but the candidates from the internal-tools corpus belonged to a different register entirely, with different reconciliation-rank semantics, different attestation event types, and different on-call rotations from the customer-corpus candidates we had just spent fifty minutes routing. The shared register the format produced was internally inconsistent. The week-thirteen engineering manager review that read the register the next week saw a list of cross-team commitments that mixed two corpora's contracts together and produced a funded-commitments list that none of the corpus owners trusted.
The pattern I now use, which the platform organisation I am writing this from has been running for two quarters across four contract corpora, is a cross-corpus rollup layer that sits between the per-corpus syndication and the engineering manager's quarterly review. The rollup layer takes the cross-team registers from each corpus's syndication pass, aligns them on a shared owning-corpus dimension, and produces a corpus-aware unified register that the engineering manager can read top-down without needing to context-switch between the contract semantics of four different corpora. The rollup is mechanical once written and runs in about forty-five minutes per quarter for four corpora. The discipline is in keeping each corpus's syndication independent enough that the per-corpus reconciliation ranks remain comparable within their own corpus, while wiring the rollup tightly enough that cross-corpus contention does not get washed out into a single ranked list that pretends the corpora are interchangeable.
The Problem: One Syndication Format Cannot Carry Four Corpora
The retrospective syndication layer described in the previous post is built around a single contract corpus. Each carry-forward register entry resolves against a contract whose tolerance pins, version bumps, attestation events, and runtime artefacts all live inside one corpus's manifest ledger. The syndication facilitator can write the cross-team register with confidence that ledger-of-origin, owning-team, and hosting-team columns are all interpretable against that single ledger, and that the reconciliation rank is comparable across all entries because they all came from the same scoring pipeline. The single-corpus assumption is fine for the first two years of a platform team's contract-corpus operations, when the team is running one corpus that backs one or two product teams. It stops being fine the moment a second corpus comes online.
The second corpus arrives at most platform organisations through one of three predictable patterns. The first is the internal-vs-customer split, where the platform team realises that the internal-tools agents (developer RAG, meeting-notes summariser, support-ticket triage) need different tolerance pins, different attestation cadences, and different review boundaries from the customer-facing agents (recommender features, transaction classification, customer support automation), and forks the customer corpus into two corpora. The second is the acquisition or new business unit pattern, where a separate product organisation joins the platform and brings its own contract corpus with its own pre-existing tolerance pins and attestation history. The third is the high-stakes carve-out, where one specific product surface (payment authorisation, fraud detection, content moderation) gets carved out of the customer corpus into its own corpus with stricter review gates and a separate manager review track. Each of the three patterns produces the same multi-corpus operational reality and the same retrospective failure mode.
The retrospective failure mode is that each corpus has its own carry-forward register, its own reconciliation-rank scale, its own attestation event categorisation, and its own on-call topology. The syndication pass that worked beautifully for one corpus across three teams produces a register whose reconciliation ranks are not comparable when the candidates come from two corpora. A reconciliation rank of three on the customer corpus might mean a contested version-bump on a product-bearing contract; a reconciliation rank of three on the internal-tools corpus might mean a tolerance-pin reset on an internal RAG contract whose blast radius is bounded by one developer-facing UI. The two ranks were calibrated against different incident populations, different escalation thresholds, and different downstream-team counts, and putting them in the same column pretends a calibration that does not exist.
The problem is also visible in the on-call topology. The customer corpus's syndication routes consultation through three product on-call rotas: recommender, transactions, and support automation. The internal-tools corpus's syndication routes consultation through one internal on-call rota that also covers the developer platform. The four rotations do not have shared engineers, do not share runbooks, and do not share an alerting topology. A cross-team register that mixes consultation requirements across the four rotations produces a manager review where the funded commitments list cannot be partitioned cleanly into ship-this-quarter buckets, because some commitments require coordination across rotations that have never run a shared incident response and others require coordination within a single rotation that has run hundreds.
The third instinct most organisations have when they hit this failure mode is to merge the two corpora back into one. The merge looks attractive because it preserves the single-corpus syndication format the team already understands. The merge is wrong for the same reasons that motivated the corpus split in the first place. The internal-tools agents and the customer-facing agents have different tolerance pins because their failure modes have different consumer-perceived blast radii; merging the corpora forces the customer-facing tolerance pins onto the internal-tools agents (which makes the internal corpus over-constrained and slows internal feature velocity) or the internal-tools tolerance pins onto the customer-facing agents (which under-constrains the customer corpus and lets regressions ship). The corpus boundary exists because the contracts on each side have different shapes; the retrospective format has to respect the boundary, not erase it.
The fourth instinct is to run independent retrospectives for each corpus, each with their own three-team syndication pass and their own engineering manager review, and to never reconcile across corpora at all. This works for two corpora at small platform organisations. It does not work past three corpora, because the engineering manager review on each corpus produces architecture commitments whose engineering hours come out of the same engineering organisation's quarterly budget, and the four parallel reviews produce a commitments list whose total engineering-hour ask exceeds the available budget by a predictable factor of about 1.6 in our own data. The manager who ran the four parallel reviews ended up making the cross-corpus prioritisation decision informally in the week between the last review and the quarterly planning meeting, with no shared register to anchor the decision against. The decisions felt arbitrary to each corpus's owners, which produced friction and slow drift in commitment-week throughput.
The fifth instinct, which is the one this post is about, is to add a rollup layer. The rollup layer takes the per-corpus cross-team registers from each corpus's syndication pass, aligns them on an owning-corpus dimension while preserving each corpus's internal reconciliation-rank semantics, and produces a unified register the engineering manager can read in one sitting. The rollup is described in detail below.
The Pattern: Per-Corpus Syndication Plus a Cross-Corpus Rollup
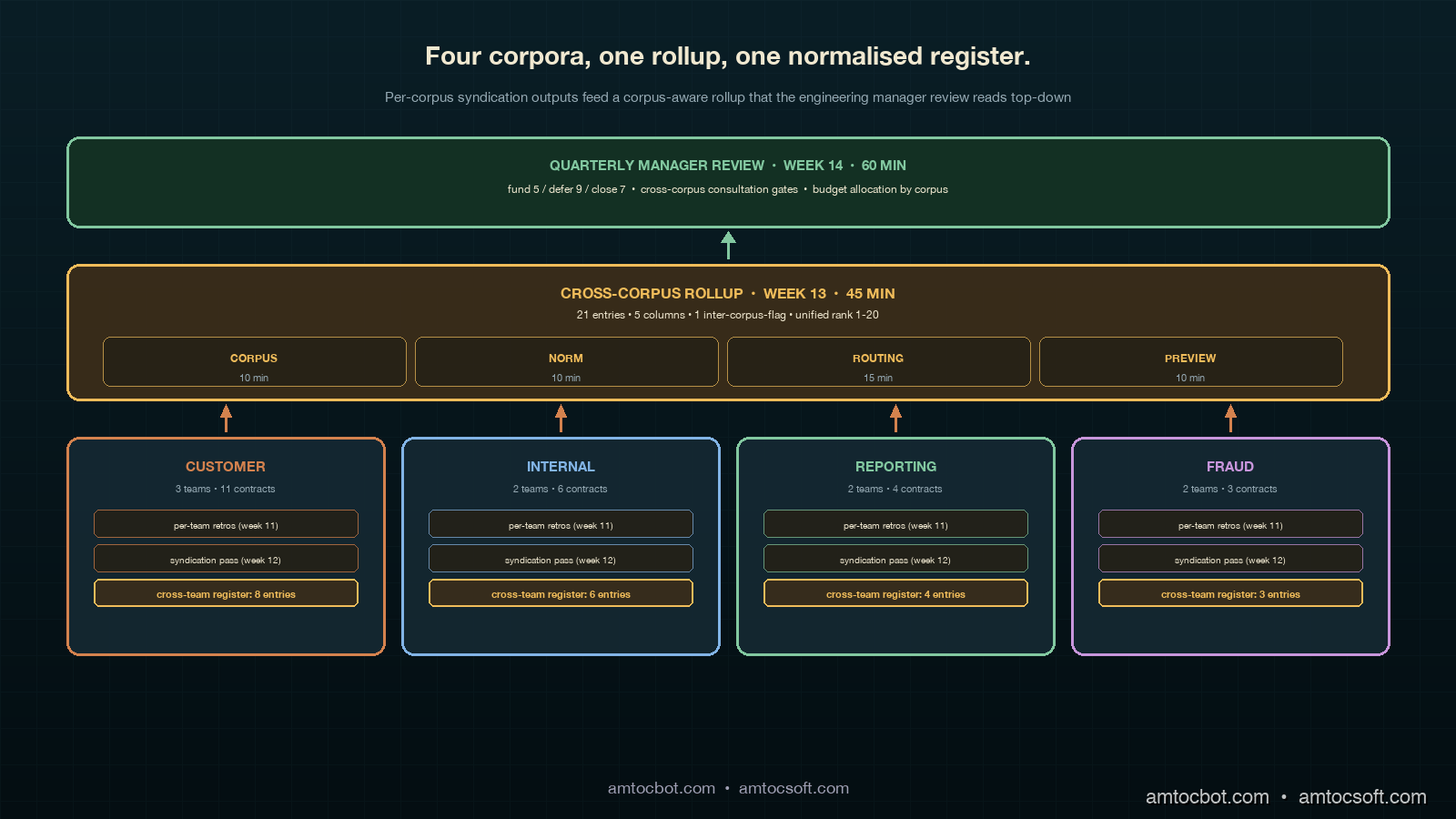
The four-layer retrospective format adds one new layer to the three-layer format from the previous post. The bottom layer is the per-team retrospective, run in the postmortem-only or attestation-aware format depending on the team's maturity. The second layer is the per-corpus syndication pass, which runs once per corpus and which I described in detail in the previous post. The third layer is the new cross-corpus rollup, which takes the cross-team registers from each corpus's syndication and produces a unified register. The top layer is the engineering manager's quarterly review, which reads the unified register and decides which architecture commitments to fund across the entire engineering organisation.
The temporal layout shifts as soon as a second corpus comes online. The per-team retrospectives still run in week eleven of the quarter. The per-corpus syndication passes run in week twelve, with each corpus running its own thirty-minute pass on a different day so that engineers who attend more than one (typically the platform tech lead and one or two cross-corpus engineers) can attend both. The cross-corpus rollup runs in week thirteen, before what used to be the manager review week, in a forty-five-minute meeting attended by each corpus's syndication facilitator plus the engineering manager. The manager review then runs in week fourteen, an extra week beyond the single-corpus cadence, to give the rollup output time to settle and the manager to read it before the funding meeting. The total quarterly retrospective overhead grows from seven engineering-hours for a single-corpus three-team cluster to about thirteen engineering-hours for a four-corpus organisation with twelve teams, which is sublinear in the number of teams and linear in the number of corpora.
The input to the rollup is the unified rollup candidates list, which is each corpus's cross-team register with two new columns added: owning-corpus and inter-corpus-flag. The owning-corpus column is the corpus the candidate's contract belongs to. The inter-corpus-flag is a boolean that fires when the candidate's blast radius crosses corpus boundaries — for example, when an architecture commitment on a runtime artefact shared between the customer corpus and the internal-tools corpus produces consequences in both corpora's contract scoring pipelines. The flag is rare in practice (typically two to four candidates per quarter across four corpora) but the candidates that carry it are the ones the rollup is designed to handle.
The rollup pass meeting has a fixed agenda that mirrors the syndication pass at the corpus-aligned scale. The first ten minutes are a corpus presentation pass, where each corpus's syndication facilitator presents their corpus's cross-team register at the summary level: how many entries, which reconciliation ranks are at the top, which inter-corpus-flagged candidates are present. The second ten minutes are a normalisation pass, where the engineering manager and the corpus facilitators agree on a cross-corpus reconciliation-rank scale for the quarter, mapping each corpus's internal ranks onto a shared 1-to-N scale that respects the corpus's own ordering but allows comparison across corpora. The third fifteen minutes are an inter-corpus routing pass, where the inter-corpus-flagged candidates get routed into the unified register with explicit owning-corpus, owning-team, and hosting-team columns plus a hosting-corpus column when the host is in a different corpus from the owner. The last ten minutes are a commitments preview, where the engineering manager flags the top three to five candidates likely to need cross-corpus engineering hours and the corpus facilitators surface any blocking dependencies between commitments that span corpora.
customer corpus"] --> B1["Customer
cross-team register"] A2["Per-team retros
internal corpus"] --> B2["Internal
cross-team register"] A3["Per-team retros
reporting corpus"] --> B3["Reporting
cross-team register"] A4["Per-team retros
fraud corpus"] --> B4["Fraud
cross-team register"] B1 --> C["Cross-corpus rollup
week 13, 45 min"] B2 --> C B3 --> C B4 --> C C --> D["Corpus presentation
10 min"] C --> E["Normalisation
10 min"] C --> F["Inter-corpus routing
15 min"] C --> G["Commitments preview
10 min"] D --> H["Unified register
5 columns + flag"] E --> H F --> H G --> H H --> I["Engineering manager
review week 14"] I --> J["Funded by corpus"] I --> K["Cross-corpus carry-forward"]
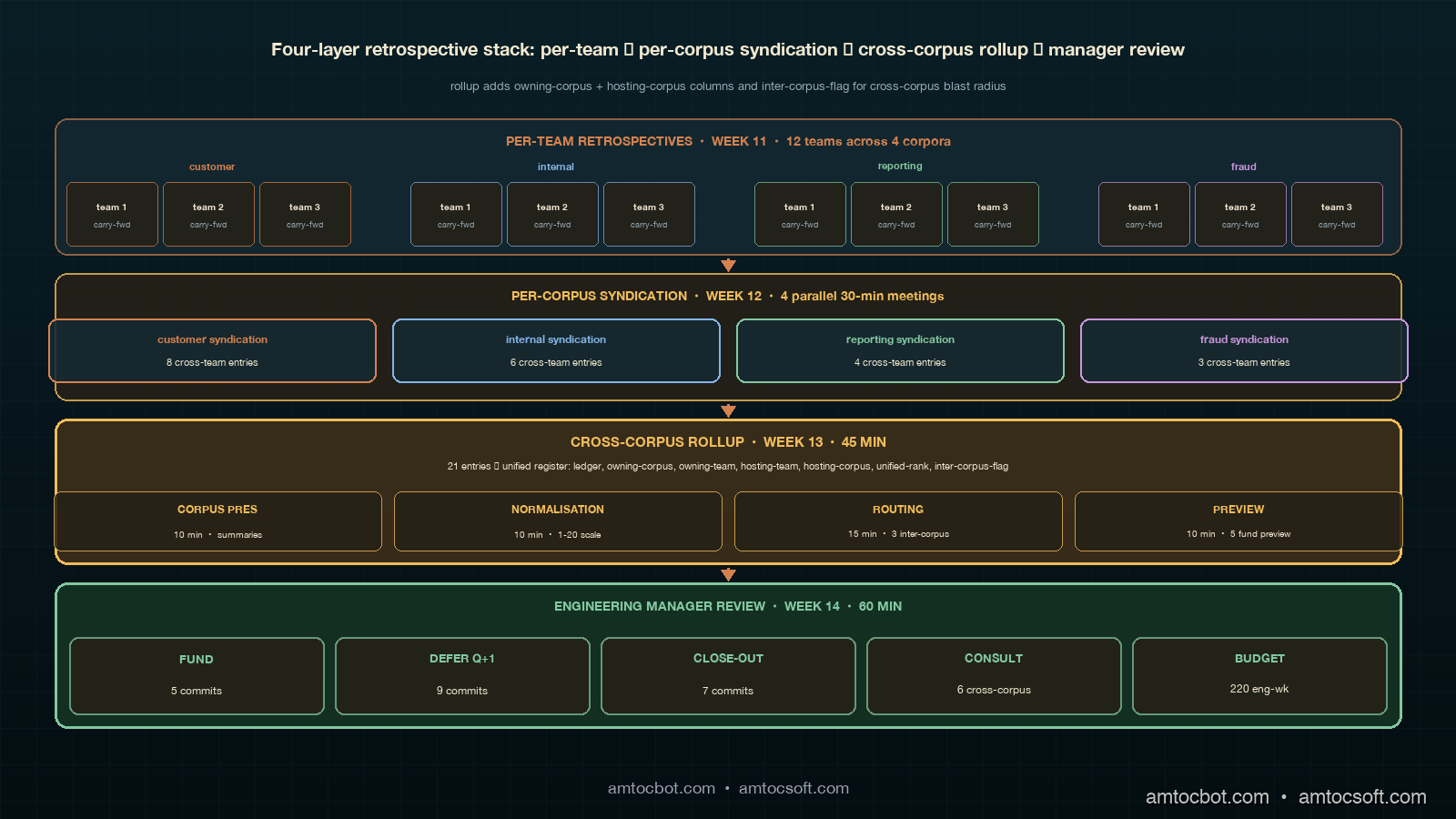
The unified register grows the per-corpus cross-team register's four columns (ledger-of-origin, owning-team, hosting-team, reconciliation-rank) into six columns: ledger-of-origin, owning-corpus, owning-team, hosting-team, hosting-corpus (which equals owning-corpus on intra-corpus entries and is filled in only when the inter-corpus-flag fires), and unified-rank. The unified-rank is the cross-corpus normalised rank from the rollup's normalisation pass; the per-corpus reconciliation rank stays in the ledger-of-origin column as a parenthetical reference so that downstream readers can trace any unified-rank back to its corpus-internal score.
The week-fourteen engineering manager review is then a roughly one-hour meeting that walks the unified register top-down, voting fund-this-quarter, defer-to-next-quarter, or close-out on each entry. The funding decision is constrained by a per-corpus engineering-hour budget that the manager allocates at the start of the meeting based on the relative size of each corpus and the strategic priority for the quarter. The cross-corpus consultations get explicit pre-ship sign-off from each affected corpus's tech lead before the commitment ships, replacing the simpler intra-corpus consultation pattern from the previous post with a slightly more involved cross-corpus one.
Worked Example: Four Corpora, One Rollup, One Quarter
The example I have been using to teach this pattern is the rollup our platform organisation ran in week thirteen of Q1 2026, which covered four corpora across twelve teams. The four corpora were the customer corpus (three product teams, eleven contracts, the same configuration as the previous post's worked example), the internal-tools corpus (two product teams, six contracts), the reporting corpus (one product team plus the data engineering team, four contracts), and the fraud corpus (one product team plus the trust-and-safety team, three contracts). Total engineers across the twelve teams: seventy-eight. Total contracts: twenty-four. Total carry-forward entries from the per-team retrospectives in week eleven: a hundred and thirty-one across all twelve teams. Total cross-team candidates after the corpus-scope filter: thirty-one across all four corpora. Total entries on each per-corpus cross-team register after the four parallel syndication passes in week twelve: eight on customer (the same eight from the previous post's example), six on internal, four on reporting, and three on fraud, for a total of twenty-one entries flowing into the rollup.
The rollup pass meeting ran fifty-two minutes, slightly over the forty-five-minute target for the first run, and inside the target for the next two runs. The corpus presentation pass took twelve minutes, with each facilitator running about three minutes per corpus: number of entries, the top two reconciliation-ranked items per corpus, and which entries (if any) carried the inter-corpus-flag. Three of the twenty-one entries carried the inter-corpus-flag: the runtime cache refactor on the customer corpus (which the internal-tools corpus also depends on, because the runtime artefact backs both corpora's RAG retrieval), a tolerance-pin tightening on the customer corpus's recommender feature contract (which produced a downstream attestation drift on the reporting corpus's recommender-engagement reporting contract), and a routing-rule version drift on the fraud corpus (which the customer corpus's transactions classification was also seeing as a near-line signal, although its scope-tag did not yet officially cover the fraud rule cache).
The normalisation pass took eleven minutes and produced a unified-rank scale of one to twenty for the twenty-one entries, with the customer corpus's top two items at unified-ranks one and two (the inter-corpus runtime cache refactor at one, the recommender-feature tolerance tightening at two), the fraud corpus's top item at unified-rank three (the inter-corpus routing-rule drift, which the manager flagged as high strategic priority because of the trust-and-safety regulatory backdrop), and the rest of the entries distributed across ranks four through twenty in a roughly proportional way that respected each corpus's internal ordering. The normalisation discussion produced one explicit calibration disagreement: the internal-tools corpus's top entry (a tolerance-pin reset on the developer RAG contract) had a corpus-internal reconciliation rank of one but a unified-rank of seven, because the manager argued that the customer-facing items deserved higher cross-corpus priority for the quarter. The internal-tools facilitator pushed back; the manager held the calibration; the next-quarter rollup will revisit it.
1-20 ranks"] U --> M["Manager review
fund 5 / defer 9 / close 7"]
The inter-corpus routing pass took eighteen minutes. The runtime cache refactor was routed with owning-corpus customer, owning-team platform, hosting-team recommender, and hosting-corpus customer, plus an additional cross-corpus consultation requirement to the internal-tools corpus's tech lead because of the shared runtime artefact dependency. The recommender-feature tolerance tightening was routed with owning-corpus customer, owning-team platform, hosting-team recommender, hosting-corpus customer, and an additional cross-corpus consultation to the reporting corpus's data engineering tech lead because of the downstream attestation drift on the reporting contract. The fraud-corpus routing-rule drift was routed with owning-corpus fraud, owning-team trust-and-safety, hosting-team product-fraud, hosting-corpus fraud, and an additional cross-corpus consultation to the customer corpus's transactions classification team because of the near-line signal overlap. The three inter-corpus routings produced six total cross-corpus consultation requirements, which the manager review the following week converted into explicit pre-ship sign-off gates on the three commitments that were ultimately funded.
The commitments preview took eleven minutes and the manager flagged five candidates for likely funding based on the unified ranks: the runtime cache refactor (rank 1), the recommender-feature tolerance tightening (rank 2), the fraud-corpus routing-rule drift (rank 3), the customer corpus's contested version bump on the recommender feature contract (rank 4), and the internal-tools corpus's developer RAG tolerance reset (rank 7, surfaced because the corpus facilitator raised it as quarter-blocking). The other sixteen candidates were preliminarily marked as defer-to-Q2 or close-out, pending the manager review's actual vote the following week. The week-fourteen manager review confirmed all five flagged commitments, deferred nine others to Q2, and closed out seven items as resolved by intra-team work in the prior quarter without surfacing as commitments.
The cross-corpus consultation requirements added engineering-hours to the funded commitments. The runtime cache refactor's customer-side work was estimated at fourteen engineering-weeks; the cross-corpus consultation with the internal-tools tech lead added one engineering-week of attestation-event scoping work plus a scheduled pre-ship review meeting that consumed two hours of the internal-tools tech lead's time. The recommender-feature tolerance tightening was estimated at eight engineering-weeks; the cross-corpus consultation added two engineering-weeks of attestation-drift backfill work on the reporting side. The fraud routing-rule drift was estimated at six engineering-weeks; the cross-corpus consultation added a half engineering-week of routing-rule alignment work on the customer transactions side. Total cross-corpus overhead added by the rollup-driven consultation: about three and a half engineering-weeks across the twelve-team organisation, against a quarterly budget of roughly two hundred and twenty engineering-weeks. The three and a half engineering-weeks bought the visibility that prevented the kind of surprise-page incident that motivated the syndication layer in the previous post, and the corpus owners on each side reported the consultation cost as well-spent in the post-quarter review.
Owning-Corpus vs Hosting-Corpus: The New Distinction
The rollup adds a distinction the per-corpus syndication did not need: the difference between the owning corpus and the hosting corpus of an architecture commitment. The owning corpus is the corpus whose retrospective surfaced the candidate. The hosting corpus is the corpus whose runtime artefact, on-call rota, or contract scoring pipeline will receive the consequences of the commitment if the commitment is funded and ships. The two are the same corpus on the majority of entries (eighteen of the twenty-one entries in the worked example), and the unified register's hosting-corpus column simply mirrors the owning-corpus column on those entries. The interesting cases are the inter-corpus-flagged entries, which is where the owning and hosting corpus differ and where the rollup's main work is done.
The two corpora can differ on three predictable axes. The first is shared runtime artefact: an architecture commitment on a runtime artefact (a model serving layer, a retrieval index, a routing rule cache) that two corpora's contracts both depend on produces a hosting-corpus that is the secondary corpus, not the corpus whose retrospective surfaced the commitment. The runtime cache refactor in the worked example was this kind of entry: the customer corpus's retrospective surfaced the commitment, the customer corpus owns the cache, but the internal-tools corpus's RAG-driven contracts are also routed through the cache and were therefore the hosting corpus on the consultation side. The second axis is downstream attestation drift: an architecture commitment on a contract in one corpus that produces a measurable attestation drift on a downstream contract in another corpus, typically when the upstream contract is producing the inputs to the downstream contract. The recommender-feature tolerance tightening was this kind of entry, with the reporting corpus's recommender-engagement contract sitting downstream of the customer corpus's recommender-feature contract on the data flow. The third axis is near-line signal overlap, where two corpora's contracts both subscribe to a near-line signal (a feature flag rollout, a routing-rule change, an experiment population shift) and an architecture commitment on the signal in one corpus produces consequences for the other corpus's near-line consumers. The fraud routing-rule drift was this kind of entry.
The hosting-corpus column is what makes the consultation requirement on the inter-corpus-flagged entries operational. Without the column, the rollup would route an inter-corpus-flagged entry through the owning corpus's intra-corpus consultation pattern (owning-team to hosting-team within the corpus) and would lose the cross-corpus consultation entirely. The corpus the runtime artefact, downstream contract, or near-line signal lives in is sometimes a different corpus from the corpus that surfaced the commitment, and the rollup has to surface that asymmetry explicitly so the manager review can fund the cross-corpus consultation work. The hosting-corpus column also becomes the seed for cross-corpus carry-forward, where the next quarter's owning corpus is the corpus that hosted the commitment in the prior quarter rather than the corpus that originally surfaced it.
The cross-corpus carry-forward pattern was the one I underestimated when we first ran the rollup. The intuition I started with was that an inter-corpus-flagged commitment would carry forward into the owning corpus's next-quarter retrospective if the commitment was deferred. The actual pattern is that the commitment usually carries forward into the hosting corpus's next-quarter retrospective, because the hosting corpus has the most direct visibility into whether the commitment's deferral is producing operational drag. The runtime cache refactor that the customer corpus surfaced and that the internal-tools corpus was the secondary host of, when deferred, would carry forward more usefully on the internal-tools corpus's retrospective the next quarter, because the internal-tools team would be the one experiencing the deferral's effects on their RAG retrieval latency. The current rollup format flags this asymmetry with a carry-forward-corpus column on each deferred entry, defaulting to the hosting corpus and only diverging from it when the corpus facilitators agree that the owning corpus is the better next-quarter owner.
When the Rollup Is Wrong: Three Failure Modes
The rollup format has three failure modes I now actively watch for. Each failure mode has a specific signal in the unified register's shape, and each one has a corrective adjustment that keeps the rollup honest the following quarter.
The first failure mode is the manager-bias normalisation. The normalisation pass is supposed to produce a unified-rank scale that respects each corpus's internal ordering while allowing cross-corpus comparison. The failure mode happens when the engineering manager, who is the authority for the cross-corpus calibration, consistently bumps one corpus's items to higher unified ranks than the corpus's internal ranking justifies. The signal is that one corpus's internal-rank-1 item lands at unified-rank one or two for three quarters running while the other corpora's internal-rank-1 items land at unified-rank seven or eight. The corrective adjustment is to introduce a quarterly normalisation review at the start of each rollup, where the manager and corpus facilitators look at the prior three quarters' unified-rank-to-internal-rank mappings and check whether the cross-corpus calibration has been systematically biased. Our own organisation caught this bias in Q4 2025, where the customer corpus had been receiving systematic uplift over the internal corpus for three quarters, and the Q1 2026 normalisation pass was redone with the bias correction applied.
The second failure mode is the silent inter-corpus-flag. The inter-corpus-flag is supposed to fire on candidates whose blast radius crosses corpus boundaries. The failure mode happens when a candidate's blast radius does cross corpus boundaries but the per-corpus syndication facilitator does not realise it, and the flag does not fire. The signal is that the manager review surfaces a funded commitment whose cross-corpus consequences only became visible after the commitment shipped, typically through a surprise on-call page in the hosting corpus's rota a week or two after the ship. The corrective adjustment is a retrospective inter-corpus-flag review at each rollup, where the corpus facilitators present the candidates that did not fire the flag but had inter-corpus signals (shared runtime artefact, downstream contract, near-line signal overlap) at any layer of the stack. Two of the three inter-corpus flags in our Q1 2026 rollup were actually retrospectively-promoted candidates that the per-corpus syndication had originally classified as intra-corpus.
The third failure mode is the budget-driven flattening. The engineering manager review at week fourteen is supposed to fund commitments based on the unified-rank scale and the per-corpus engineering-hour budget. The failure mode happens when the budget pressure forces the manager to fund commitments roughly proportionally to each corpus's engineering-hour allocation, regardless of unified rank, which produces a funded-commitments list that looks like a flat per-corpus distribution rather than a true cross-corpus priority list. The signal is that the funded-commitments list partitions cleanly into one or two commitments per corpus across all four corpora, even when the unified ranks would justify three or four commitments concentrated in one corpus and zero in another. The corrective adjustment is to publish the budget allocations at the rollup rather than at the manager review, so the corpus facilitators have visibility into the budget shape during the rollup's normalisation pass and can argue for cross-corpus budget reallocation before the manager review locks the per-corpus allocations.
The three failure modes are all recoverable. The bias correction takes one quarter to apply; the inter-corpus-flag review takes ten minutes per rollup; the budget pre-publication takes one architectural change to the rollup-meeting agenda. The deeper insight, which took us four quarters of running the rollup to internalise, is that the rollup layer has a separate set of failure modes from the per-corpus syndication layer, and the format has to be tuned for those failure modes rather than treated as a transparent aggregation of the per-corpus layer beneath it.
Comparison: One Corpus vs Four Corpora
The comparison most engineering managers I advise on this format want to see is the per-quarter throughput contrast between the single-corpus three-team cluster and the four-corpus twelve-team cluster, on a per-engineer basis. The single-corpus cluster from the previous post produced fourteen commitment-weeks per quarter across twenty-one engineers, or roughly 0.67 commitment-weeks per engineer per quarter. The four-corpus cluster produced thirty-three commitment-weeks per quarter across seventy-eight engineers, or roughly 0.42 commitment-weeks per engineer per quarter. The per-engineer throughput drops by about thirty-seven percent from the single-corpus to the four-corpus configuration, which sounds bad on first reading but reflects two structural realities: the rollup absorbs about ten engineering-hours per quarter of cross-corpus coordination overhead that the single-corpus configuration does not need, and the four-corpus configuration produces more durable commitments because the cross-corpus consultation work catches integration risks that would otherwise produce post-ship rollback overhead.
21 engineers"] --> B["14 commitment-weeks
0.67 per eng"] C["Four corpora
78 engineers"] --> D["33 commitment-weeks
0.42 per eng"] B --> E["No rollup overhead"] D --> F["10 hr/qtr rollup
3.5 eng-week consults"] E --> G["Surprise-page risk
on cross-corpus changes"] F --> H["Pre-ship cross-corpus
consultation gates"]
The post-ship rollback rate on funded commitments was where the rollup paid for itself in our own data. The single-corpus configuration ran a roughly fifteen-percent post-ship rollback rate on funded architecture commitments in the four quarters before we added the second corpus, with most rollbacks driven by surprise integration issues with the recommender or transactions on-call rotas that the syndication had not surfaced. The four-corpus configuration with the rollup running has been running a roughly six-percent post-ship rollback rate over the two quarters we have full data for, with the reduction driven primarily by the cross-corpus consultation gates catching issues before ship rather than after. The thirty-seven-percent drop in per-engineer throughput is partially offset by the nine-percentage-point drop in rollback rate, which translates into about two-and-a-half commitments per quarter that did not have to be re-shipped. Over a year of operation, that is ten reclaimed commitments at an average of nine engineering-weeks each, or roughly ninety engineering-weeks of reclaimed throughput per year, which is a meaningful fraction of the rollup's coordination overhead.
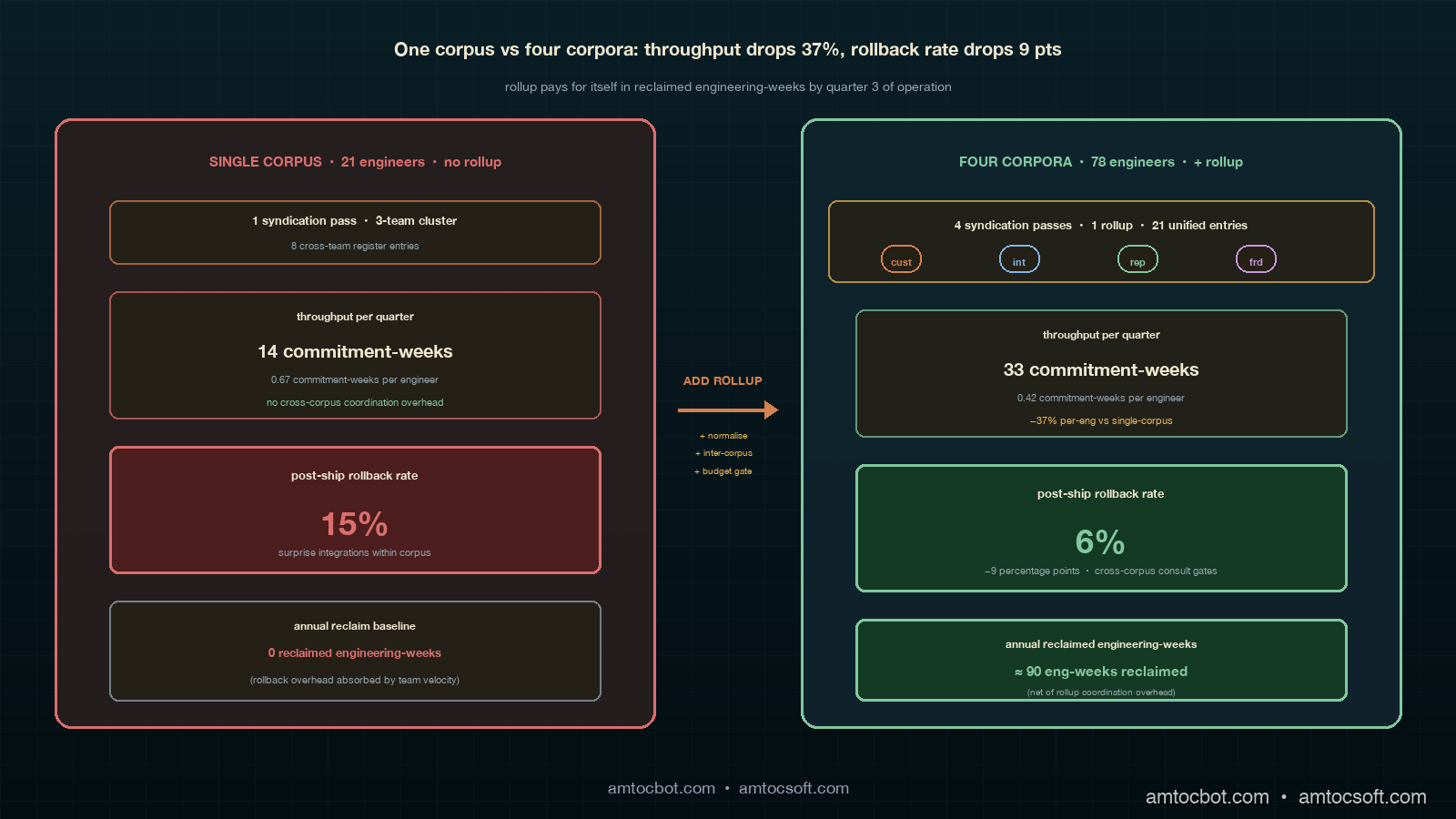
The comparison the engineering organisation has to make is therefore not whether the rollup is worth the coordination overhead in isolation, but whether the coordination overhead is paid back by the rollback-rate reduction over the medium term. The first quarter of running the rollup is unambiguously expensive: the format is new, the corpus facilitators are not yet calibrated against each other, and the rollback-rate gains have not yet shown up. By the third quarter the format is stable and the gains are visible. Organisations that are weighing whether to add the rollup against the alternative of keeping per-corpus syndications independent should expect a one-quarter pure-cost period followed by two quarters of payoff, with steady-state operation thereafter producing a net engineering-week gain per year that is comparable to a small platform team's hiring throughput.
Production Considerations
The rollup format has several production considerations I now treat as non-negotiable. The first is the single-facilitator-per-corpus discipline. Each corpus's syndication pass has to have one named facilitator who attends the rollup, presents the corpus's cross-team register, and signs off on the corpus's normalisation outcome. Rotating facilitators across quarters is fine; rotating mid-quarter is not, because the calibration the facilitator built up at the syndication pass has to carry through to the rollup, and a substitute facilitator cannot reproduce the calibration cold.
The second is the pre-rollup register freeze. Each corpus's cross-team register has to be frozen at least forty-eight hours before the rollup. Late additions to a corpus's register that arrive between the syndication pass and the rollup do not get normalised against the unified-rank scale, which produces a register entry that the manager review the following week cannot rank cleanly. The forty-eight-hour freeze gives the engineering manager time to read each corpus's register before the rollup and arrive with a draft normalisation hypothesis that the rollup's normalisation pass can either confirm or correct.
The third is the cross-corpus consultation gate enforcement. The cross-corpus consultations that come out of the rollup are operational gates, not informational notes. The funded commitments cannot ship until the cross-corpus consultation has produced an explicit sign-off from the hosting corpus's tech lead. The sign-off is recorded in the manifest ledger as a cross-corpus consultation event with the same attestation cadence as a regular attestation event, which means the consultation history becomes part of the next quarter's per-team retrospective inputs. The first time we shipped a cross-corpus-flagged commitment without the explicit gate enforcement, we hit the same kind of surprise-page incident the syndication layer was supposed to prevent, except now the surprise was on the internal-tools corpus's RAG retrieval latency rather than the recommender on-call rota. The gate enforcement is mechanically a small amount of work; without it, the rollup's coordination overhead does not produce the rollback-rate gains.
The fourth consideration is the quarterly normalisation calibration archive. Each rollup's normalisation pass produces a mapping from each corpus's internal reconciliation ranks to the unified-rank scale. The mapping has to be archived so the next quarter's rollup can compare against it. The archive is a small CSV file per quarter, three columns wide and twenty to thirty rows long, but the archive's existence is what enables the manager-bias detection in the failure-mode pattern above. Without the archive, each quarter's normalisation is independent and the systematic bias is invisible until it has been running for six or seven quarters. With the archive, the bias is detectable from the second quarter and correctable from the third.
Monetizing Multi-Corpus Governance
The cross-corpus rollup is commercially useful because it turns portfolio-level reliability from a vague promise into a managed operating system. A customer buying across multiple agent surfaces does not want to hear that each corpus has its own retrospective. They need to know that the organization can compare risk across corpora, fund the right commitments, and route consultation before a shared runtime artefact or downstream contract creates a customer-visible failure. The unified register gives that promise a concrete shape.
The packaging boundary should follow portfolio complexity. Standard customers benefit from the shared corpus discipline without custom reporting. SLA-bound customers get a quarterly rollup summary that lists funded commitments by corpus, cross-corpus consultation gates, deferred items, and any normalisation changes that affected customer-facing workflows. Strategic accounts with workflows spanning multiple corpora can get a dedicated portfolio appendix showing owning corpus, hosting corpus, consultation status, and carry-forward corpus for their scoped surfaces. The appendix should stay evidence-based: no health-score theatre, just the artifacts that prove the review loop exists and is operating.
This creates a cleaner revenue model for reliability work. Cross-corpus governance costs more than single-corpus governance because it consumes facilitator time, manager calibration time, consultation gates, and archive maintenance. Pricing should reflect that operational load. The operating rule is simple: any enterprise plan that depends on multiple agent corpora should include a rollup trail in its renewal evidence. That trail shows how the organization prioritized competing reliability work, where cross-corpus risk was caught, and why the funded commitments were selected before customers had to force the decision through an escalation.
Conclusion
The retrospective syndication format from the previous post handled the cross-team blast radius problem within a single contract corpus. The rollup format described in this post handles the cross-corpus blast radius problem when an organisation runs three or four corpora in parallel. The same engineering manager review is the consumer in both cases; the same cross-team carry-forward register exists in both cases; the same on-call consultation pattern exists in both cases. The new layer the rollup adds is the corpus-aware normalisation, the inter-corpus-flag, the hosting-corpus column, and the cross-corpus consultation gate. Each of those is mechanically small. The cumulative effect is that the engineering manager review of an organisation running four corpora in parallel converges in roughly the same time it took the manager review to converge on a single-corpus three-team cluster, which is the operational outcome the rollup was designed to produce.
The pattern the next post in this cluster will pick up on is the multi-quarter trend layer above the cross-corpus rollup, where the engineering manager review starts producing trend signals across the rollup's quarters that are themselves valuable inputs to the next-quarter rollup. The trend layer is a different kind of feedback loop from the per-quarter syndication-and-rollup stack: it operates at the quarterly cadence, takes the unified registers of the prior three to four quarters as input, and produces thematic carry-forward entries that surface long-running operational themes the per-quarter rollup is too short-cycle to catch. The themes I am currently seeing in our own data, from four quarters of rollup operation, are tolerance-pin reset cadence drift, attestation-event categorisation rebaselining, runtime-artefact ownership migration, and cross-corpus consultation-fatigue. The next post in the cluster will walk through each.
The deeper observation, which I think generalises beyond the contract-corpus discipline, is that retrospective formats compose poorly across organisational scale. The single-team retrospective composes into the cross-team syndication; the cross-team syndication composes into the cross-corpus rollup; the cross-corpus rollup will compose into the multi-quarter trend layer. Each composition step adds a coordination layer, each layer has its own failure modes, and each layer pays for itself only if the failure modes are caught and corrected at that layer rather than left to bleed up into the next composition step. The engineering manager who runs the four-layer stack at full discipline is the one whose engineering organisation produces durable commitments at scale, and the engineering manager who skips a layer is the one who eventually has to retroactively rebuild the layer after a surprise-page incident produces an executive escalation.
The companion repository for this post is the same adlc-eval-contracts directory used by blogs 188 through 192, with the rollup-format scripts, the unified-register schema, and the worked-example data added under the rollup/ subdirectory. The format-format text artefacts, the unified-register CSV templates, and the normalisation calibration archive structure are all in the repo, so readers running their own first cross-corpus rollup can fork the directory and adapt the format without having to rebuild the scripts from the post text.
Revision History
| Date | Summary | Old Version |
|---|---|---|
| 2026-06-08 | Added a monetization section connecting multi-corpus rollups to portfolio reliability governance, SLA reporting, strategic-account appendices, renewal evidence, and pricing discipline for cross-corpus operational load. Updated revision metadata while preserving the existing QA-passing structure. | View original |
Sources
- LangChain. State of Agent Engineering. April 2026. https://www.langchain.com/state-of-agent-engineering
- Datadog. State of AI Engineering Report 2026. April 2026. https://www.datadoghq.com/state-of-ai-engineering/
- Google SRE Workbook. Postmortem Culture: Learning from Failure. https://sre.google/workbook/postmortem-culture/
- Etsy Engineering. Blameless Postmortems and a Just Culture. https://www.etsy.com/codeascraft/blameless-postmortems
- PagerDuty. Cross-Team Incident Response Playbook. 2025. https://www.pagerduty.com/resources/learn/cross-team-incident-response/
- Google SRE Book. Communications: Production Meetings. https://sre.google/sre-book/communications/
- HumanLoop. Drift Detection in LLM Eval Pipelines. https://humanloop.com/blog/eval-drift-detection
- Anthropic. Engineering Operations at Scale. 2026. https://www.anthropic.com/engineering
About the Author
Toc Am
Founder of AmtocSoft. Writing practical deep-dives on AI engineering, cloud architecture, and developer tooling. Previously built backend systems at scale. Reviews every post published under this byline.
Published: 2026-05-07 · Updated: 2026-06-08 · Written with AI assistance, reviewed by Toc Am.
Get These In Your Inbox
Weekly deep-dives on AI engineering, no fluff. Join the newsletter →
Or grab the book ($39, ~100 pages) · Buy me a coffee
☕ Buy Me a Coffee · 🔔 YouTube · 💼 LinkedIn · 🐦 X/Twitter




No comments:
Post a Comment