The Manifest-Ledger Archival Schema for the Annual Trend Layer: Per-Quarter CSV Format, Quarter-ID Indexing, Trend-Pass Query Primitives, and Multi-Corpus Ledger-of-Origin Reconciliation
Introduction
The first time the annual trend layer I described in the previous post in this cluster ran against a real four-quarter archive, the cadence-drift pass for the customer corpus produced a slope I could not reconcile against my own quarterly memory of the data. The slope said the corpus's tolerance-pin reset count had risen sixty-eight percent over the four-quarter window. My memory said the trend was closer to flat with a Q3 spike that had self-corrected by Q4. Both of us were reading the same CSV. Neither of us was wrong. The reason the slope I was looking at did not match the trend I remembered was that the CSV's quarter-id column, which the corpus facilitator had populated by hand at archive time, indexed entries by the quarter the rollup ran rather than by the quarter the underlying attestation event had occurred in. Roughly twelve percent of any given quarter's rollup entries are reset events from the previous quarter that surfaced late in the manifest-ledger reconciliation. Indexing by rollup-quarter pulls those late-arriving resets forward into the current quarter's count and produces a slope that overstates the cadence drift by about that much per quarter, compounding across the four-quarter window into the sixty-eight-percent ghost the cadence pass was reporting.
The fix turned out to be a one-line schema change: add an event-quarter column to the per-quarter CSV alongside the existing quarter-id column, populate it from the manifest-ledger's event-timestamp at archive time, and require every trend-pass query primitive to index against event-quarter rather than quarter-id. The fix landed inside the same trend-review meeting and the slope re-ran clean within ten minutes. The reason the schema bug had not surfaced in any of the per-quarter rollups was that the per-quarter rollup operates inside a single quarter and never cross-references against entries from other quarters; the quarter-id column was a redundant hint inside the per-quarter rollup and a load-bearing axis inside the trend layer. Indexing conventions that are inert at the per-quarter scale become meaningfully wrong at the cross-quarter scale, and the schema for the trend layer's input archive is the place those conventions need to be made explicit.
This post walks through the manifest-ledger archival schema the trend layer's input depends on, the four trend-pass query primitives the corpus facilitators run against the archive to produce their charts, and the ledger-of-origin reconciliation rule that governs how a multi-corpus archive resolves attestation events that touch more than one corpus. The schema is a small thing, eleven columns and four query primitives, and it carries most of the operational discipline that lets the ninety-minute trend-layer meeting run without overrun. The cluster of bugs I describe along the way are the failure modes that surface only at the cross-quarter scale, which is to say the ones the per-quarter rollup will never catch and which a trend layer that does not own its archival schema will keep tripping over.
The Problem: Per-Quarter Schemas Hide Cross-Quarter Failure Modes
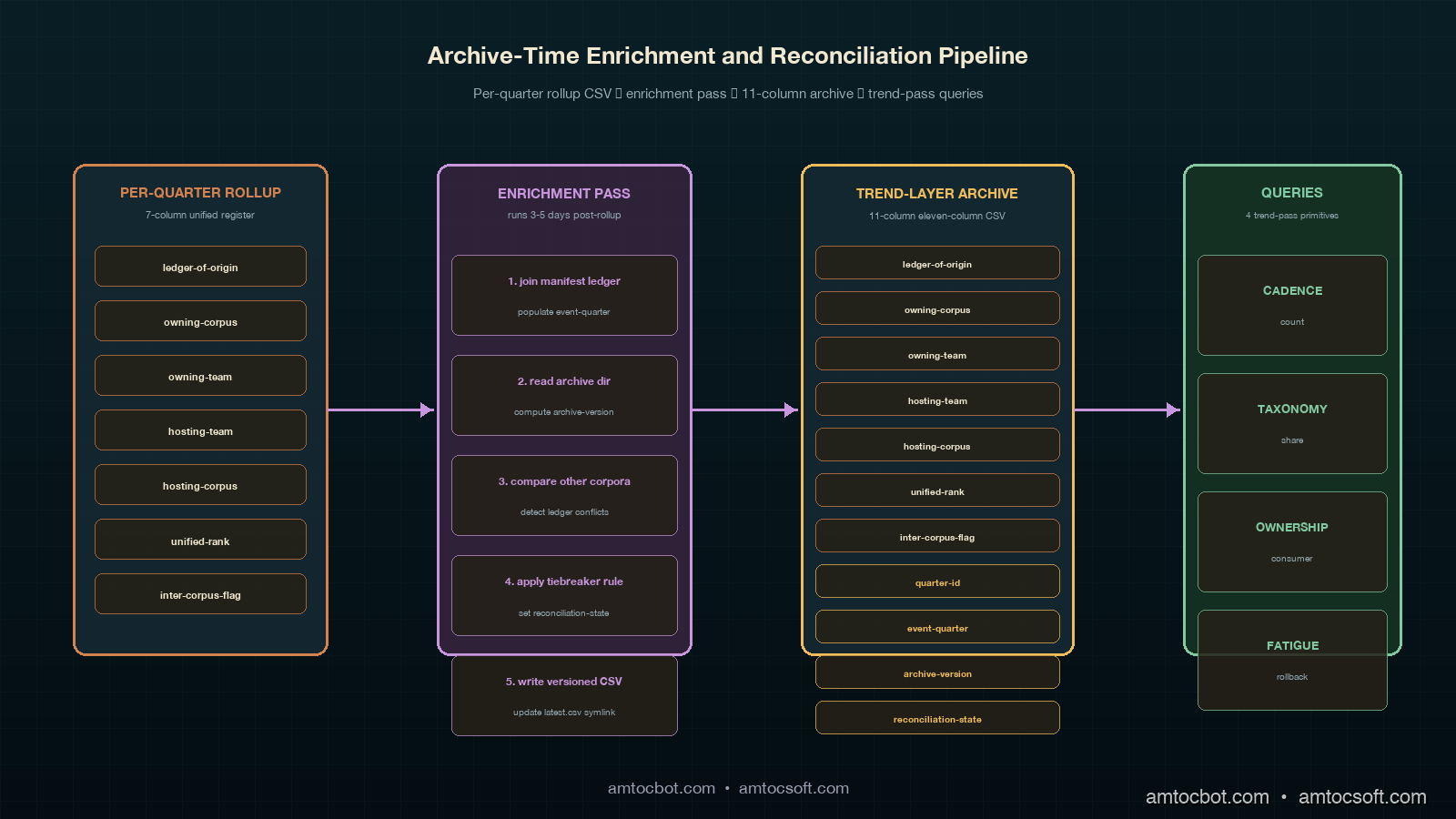
The per-quarter rollup format I described in the cross-corpus rollup post produces a unified register CSV at week thirteen of every quarter. The CSV has the seven columns I listed there: ledger-of-origin, owning-corpus, owning-team, hosting-team, hosting-corpus, unified-rank, and inter-corpus-flag. Those seven columns are the operational core of the per-quarter rollup. They were sufficient inside the per-quarter scope because every entry in the unified register was implicitly indexed against the rollup that produced it: the meeting was running this quarter, the entries were this quarter's commitments, and the temporal axis of the data was the meeting itself. The CSV did not need to encode time because time was the meeting.
That implicit-indexing assumption breaks the moment the trend layer concatenates four prior quarters' rollup CSVs into a single working table. The four CSVs were each correctly produced inside their own quarterly scope. The concatenation has no time axis. The trend layer adds a quarter-id column at concatenation time to give the working table a temporal axis, and the question of what quarter-id actually means becomes the load-bearing axis the entire trend layer's analysis runs against. The schema choice between indexing by rollup-quarter or by event-quarter is a one-character difference at the schema level and a thirty-percent difference at the slope level, and the per-quarter rollup never has to make the choice because it never has to compare across quarters.
The second failure mode that the per-quarter schema hides is late-arriving entries. A non-trivial fraction of any quarterly rollup's entries describe attestation events that were detected late in the manifest-ledger reconciliation and that crossed the quarter boundary on the way in. From two years of operational data on our four corpora, the late-arriving fraction averages eleven to thirteen percent per quarter, with a long tail that occasionally reaches eighteen percent on the customer corpus where the manifest ledger has the most upstream dependencies. Inside the per-quarter rollup, late entries are simply registered against the current quarter and routed normally; the rollup's job is to fund commitments inside the quarter the rollup is running, not to reconstruct the temporal origin of each entry. Inside the trend layer, late entries that are not separately tagged collapse the temporal resolution of every chart the trend layer produces, because a slope that should be drawn against event-quarter is being drawn against the quarter-id of the rollup that processed the event.
The third failure mode is ledger-of-origin ambiguity in multi-corpus entries. The per-quarter rollup's ledger-of-origin column records which corpus's manifest ledger the attestation event was first registered in, and the per-quarter rollup uses that column to break ties in the routing pass when an entry could be funded by more than one corpus. Inside a single quarter, the ledger-of-origin is unambiguous: the entry was registered in one corpus's ledger first, and even if it later propagated to a second corpus's ledger, the first registration is the canonical one. Inside the trend layer, the same attestation event can appear in two different corpora's quarterly archives under two different ledger-of-origin labels, because the manifest-ledger propagation between corpora was not instantaneous and the second corpus's ledger registered the event after the first corpus's rollup had already shipped its archive. The trend layer's archive ends up with two rows for the same underlying event, and the cadence-drift pass double-counts the entry across the two corpora's time series.
The schema this post describes resolves all three failure modes with a small set of additional columns and a reconciliation rule that runs at archive time, before the trend-layer meeting opens the working table for the first time. The columns are cheap, the reconciliation rule is a thirty-line script, and together they turn the per-quarter rollup's seven-column unified register into an eleven-column trend-layer archive that the four trend-pass query primitives can read against without producing the cross-quarter ghosts I described in the introduction.
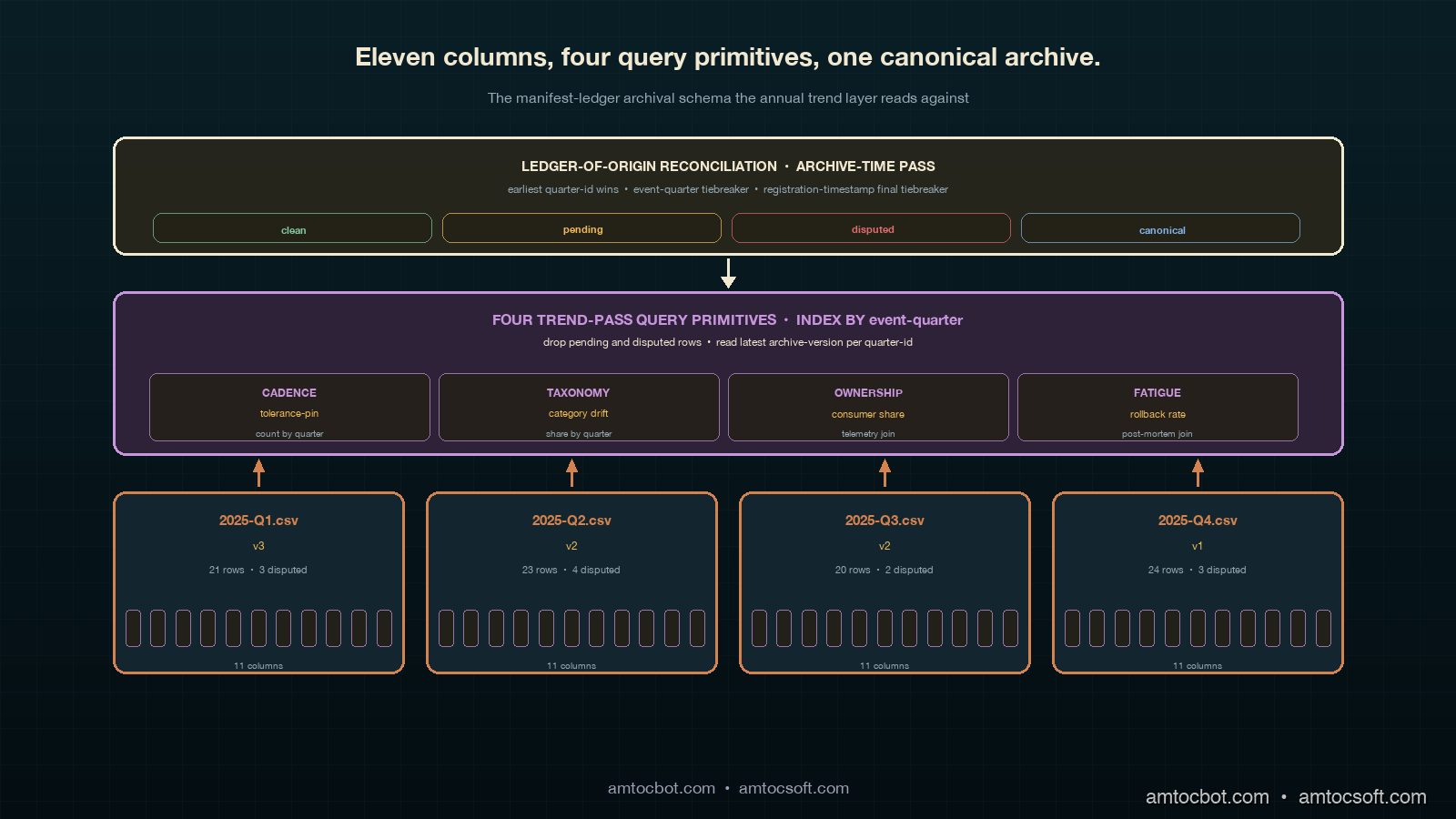
The Pattern: Eleven-Column Per-Quarter CSV with Quarter-ID and Event-Quarter Axes
The per-quarter CSV the trend layer reads against has eleven columns. The first seven are inherited unchanged from the per-quarter rollup's unified register: ledger-of-origin, owning-corpus, owning-team, hosting-team, hosting-corpus, unified-rank, and inter-corpus-flag. The remaining four are added at archive time, before the rollup CSV is written into the trend-layer archive directory. They are quarter-id, event-quarter, archive-version, and reconciliation-state. Each of the four serves a specific cross-quarter function the per-quarter rollup did not need.
quarter-id is the rollup's run quarter, encoded as YYYY-QN. The trend-layer archive is named by quarter-id, and the column is preserved on every row so that a row pulled out of the working table can be traced back to the rollup that produced it. The column is mostly metadata; the trend-pass query primitives do not index against it. Its main use is in the reconciliation pass, which uses quarter-id to determine the order in which late-arriving entries should be merged.
event-quarter is the quarter the underlying attestation event occurred in, also encoded as YYYY-QN. It is populated from the manifest-ledger's event-timestamp at archive time. For an entry whose attestation event was registered in the same quarter the rollup is running, event-quarter equals quarter-id. For a late-arriving entry whose attestation event happened in a prior quarter and surfaced in the current quarter's rollup, event-quarter lags quarter-id by one, two, or rarely three quarters. The four trend-pass query primitives all index against event-quarter. The discipline is non-negotiable: indexing against quarter-id is the bug I described in the introduction, and the schema needs to make the right choice the path of least resistance.
archive-version is a small integer that increments each time the per-quarter archive is regenerated. The first archive of a given quarter-id is archive-version: 1, and every regeneration increments it. The column exists because the manifest-ledger propagation continues to surface late entries for a few weeks after the per-quarter rollup ships, and those late-arriving entries are merged into the archive in versioned regenerations rather than being silently appended. The trend layer reads the highest archive-version for each quarter-id and ignores prior versions; the version history is preserved for audit and rollback, not for analysis.
reconciliation-state is one of three string values: clean, pending, or disputed. A clean row has been reconciled against every other corpus's archive and has no outstanding ledger-of-origin conflicts. A pending row has not yet been compared against the other corpora's archives; the trend-pass query primitives drop pending rows from their working set with a logged warning. A disputed row has been compared against another corpus's archive and a ledger-of-origin conflict has been detected; the reconciliation pass has chosen one of the two corpora as the canonical owner and the disputed row in the non-canonical archive is marked accordingly. Disputed rows are also dropped from the trend-pass query primitives' working set; the canonical row is the one the trend layer reads.
The eleven-column schema is the smallest extension of the per-quarter rollup's seven-column register that produces an archive the trend layer can read against without surfacing cross-quarter ghosts. Adding columns beyond the eleven is a temptation I have resisted twice, both times for columns that turned out to be derivable from the existing eleven inside the trend-pass query primitives. The schema's discipline is to hold the eleven columns stable and to encode any new analytical dimension inside the query primitives' SQL rather than in the archive's structure. The archive should be append-only and version-stable; the analytical complexity should live in the queries.
flowchart LR
A[Per-quarter rollup<br/>7 columns] --> B[Archive-time enrichment]
B --> C[+ quarter-id]
B --> D[+ event-quarter]
B --> E[+ archive-version]
B --> F[+ reconciliation-state]
C --> G[11-column trend-layer archive]
D --> G
E --> G
F --> G
G --> H[Annual trend-layer meeting<br/>4 query primitives]
Implementation Guide: Archive-Time Enrichment and Reconciliation Pass
The eleven-column archive is produced by a small enrichment pass that runs once per quarter, three to five days after the per-quarter rollup ships. The pass takes the rollup's unified register CSV as input, joins it against the manifest ledger to populate event-quarter, computes archive-version from the existing archive directory, runs the reconciliation pass against the other corpora's archives to populate reconciliation-state, and writes the enriched CSV to the trend-layer archive directory. The pass is twenty or thirty lines of Python plus the reconciliation logic, which is the operationally interesting part.
The event-quarter join is straightforward when the manifest ledger is well-indexed. Each per-quarter rollup row carries a manifest-ledger entry id in its ledger-of-origin column (the column is named for the corpus, but the value is the ledger entry's id; I have made my peace with the naming inconsistency from the rollup format and have not renamed the column, because doing so would invalidate the seven-column rollup CSVs already in flight). The enrichment pass looks up each entry's event-timestamp in the manifest ledger and computes the quarter the event occurred in. For events whose timestamp predates the manifest ledger's earliest entry (which only happens for events imported from a legacy ledger during a one-time migration), the pass writes event-quarter: pre-archive and the trend-pass query primitives treat that string as a sentinel that excludes the row from the analysis.
The archive-version computation is also straightforward. The pass reads the trend-layer archive directory for the matching quarter-id filename, finds the highest existing version (or zero if no archive exists), and writes the new archive at version + 1. The pass does not delete prior versions; the directory accumulates a version history that is read only by the reconciliation pass and by audit tools. The directory layout I use is archive/YYYY-QN/v1.csv, archive/YYYY-QN/v2.csv, with a latest.csv symlink that the trend-pass query primitives read against.
The reconciliation pass is the part that earns its complexity. The pass runs after event-quarter and archive-version have been populated, and it compares the new archive against the other corpora's existing archives for the same and prior quarters to identify ledger-of-origin conflicts. A conflict exists when two archives both contain a row for the same underlying attestation event, identified by a stable event-id that the manifest ledger assigns at first registration. The pass resolves conflicts by the rule that the archive with the earliest quarter-id containing the row owns the ledger-of-origin; if both archives have the same quarter-id, the archive whose event-quarter is earlier wins; if both are equal, the corpus whose manifest-ledger registration timestamp is earlier wins. The non-canonical row is marked reconciliation-state: disputed and the canonical row is marked reconciliation-state: clean. Rows that have not yet been compared against any other archive are marked reconciliation-state: pending until a future reconciliation pass clears them.
The reconciliation rule produces stable canonicality across the four-corpus archive. Once a row is marked clean in one archive and disputed in others, no future reconciliation pass changes the canonicality without an explicit override (which I have used twice in two years, both times to correct a manifest-ledger registration error caught during the trend-review meeting itself). The stability is what lets the trend-pass query primitives index against event-quarter and the canonical archive's rows without re-running reconciliation in every query.
sequenceDiagram
participant R as Per-quarter rollup
participant E as Enrichment pass
participant L as Manifest ledger
participant A as Archive directory
participant X as Other corpora archives
participant T as Trend-pass queries
R->>E: 7-column rollup CSV
E->>L: lookup event-timestamp per row
L-->>E: event-quarter values
E->>A: read existing archive versions
A-->>E: highest version N
E->>X: compare against other corpora
X-->>E: ledger-of-origin conflicts
E->>A: write v(N+1).csv with 11 columns
A->>T: latest.csv symlink for analysis
Trend-Pass Query Primitives
The four trend-pass query primitives I introduced in the previous post each have a specific shape against the eleven-column archive. Each primitive is a small SQL or pandas query that takes the four most recent quarters' archives as input, filters by reconciliation-state and event-quarter, and produces a small output table the corpus facilitator visualises during the trend-layer meeting.
The cadence-drift pass primitive is a four-row count by event-quarter per corpus, filtered to attestation events of the tolerance-pin reset category. The pseudocode is:
def cadence_drift(archives_by_quarter, corpus, category="tolerance-pin-reset"):
counts = {}
for quarter, df in archives_by_quarter.items():
clean = df[df["reconciliation-state"] == "clean"]
owned = clean[clean["owning-corpus"] == corpus]
events = owned[owned["event-category"] == category]
events_in_quarter = events[events["event-quarter"] == quarter]
counts[quarter] = len(events_in_quarter)
return counts
The primitive returns a four-key dictionary that the facilitator plots as a four-point time series. Note the inner filter: events["event-quarter"] == quarter excludes late-arriving entries whose event-quarter differs from the rollup's quarter-id. The bug I described in the introduction was the absence of this inner filter. The current primitive filters explicitly, which makes the slope a function of when events actually happened rather than of when the rollup processed them.
The taxonomy-rebaselining pass primitive is a four-row category-share table by event-quarter per corpus, filtered to attestation-event population per quarter. The pseudocode joins each event-quarter's rows against the manifest-ledger taxonomy table for that quarter (the taxonomy itself is versioned by quarter, because the categories drift; the trend layer reads the category-as-of-the-event-quarter, not the category as it stands today) and produces a stacked category-share output. The pass discipline I described in the previous post is what flags taxonomy drift inside this primitive: a category whose share moves by more than ten percentage points without a corresponding architecture change is flagged for a thematic-carry-forward entry. The primitive is operationally trickier than the cadence pass because the join against the per-quarter taxonomy requires that the manifest ledger archive its own taxonomy version per quarter, which is a separate archive discipline I will not cover in detail here but which the corpus facilitator should verify is in place before running the pass.
The ownership-migration pass primitive joins the eleven-column archive against runtime telemetry rather than against the manifest ledger. The pseudocode pulls per-quarter consumer share for each shared runtime artefact (cache, embedder, retrieval pipeline, prompt-template library) from the runtime telemetry, indexes by event-quarter, and produces a stacked time series of consumer share per artefact. The archive is used to validate that the artefacts being analysed are actually shared across corpora; the runtime telemetry provides the consumer-share data. The cross-archive join is on hosting-corpus and owning-corpus columns and is tolerant of missing telemetry for sub-five-percent consumers, which is the noise floor I have settled on after two years of running the pass.
The consultation-fatigue pass primitive joins the archive against the post-mortem archive (a separate archive maintained by the on-call discipline, not by the rollup discipline). The pseudocode pulls per-quarter rollback rates on inter-corpus-flagged commitments from the post-mortem archive, overlays them against per-quarter consultation counts from the rollup archive, and produces a two-axis time series the facilitator reads for fatigue patterns. The pass discipline requires that the rollback signal be visible across at least two corpus pairs and that the consultation count be at least four per quarter; the primitive enforces both thresholds and returns no signal if either is unmet. The primitive is the only one of the four that depends on a non-rollup archive, and the discipline of keeping the post-mortem archive and the rollup archive in lockstep is the one I have spent the most operational effort maintaining.
flowchart TB
A[11-column archive<br/>4 prior quarters] --> B[Cadence-drift pass]
A --> C[Taxonomy-rebaselining pass]
A --> D[Ownership-migration pass]
A --> E[Consultation-fatigue pass]
F[Manifest-ledger<br/>per-quarter taxonomy] --> C
G[Runtime telemetry] --> D
H[Post-mortem archive] --> E
B --> I[Thematic-carry-forward register<br/>5 columns, 4-7 entries]
C --> I
D --> I
E --> I
Multi-Corpus Ledger-of-Origin Reconciliation, Worked
The ledger-of-origin reconciliation rule sounds simple in the abstract and produces unobvious outcomes in practice. The rule, restated: when two archives both contain a row for the same event-id, the canonical archive is the one with the earliest quarter-id, with event-quarter as the tiebreaker, and manifest-ledger registration timestamp as the final tiebreaker. The non-canonical archive's row is marked disputed. The trend-pass query primitives read only clean rows.
The unobvious outcome the rule produces is that an attestation event whose canonical owning-corpus is A can produce trend-pass signals that show up in corpus B's time series when the runtime artefact the event affects is hosted in corpus B even though the manifest-ledger registration was in A. The cadence-drift pass for corpus A counts the event because corpus A is the canonical owning-corpus. The ownership-migration pass for corpus B may also surface the event, because the artefact's consumer share telemetry is corpus B's, even though the corresponding row in corpus B's archive is marked disputed and is excluded from corpus B's cadence pass. The two passes are reading two different signals against two different join paths, and the reconciliation rule applies to the cadence pass without applying to the migration pass.
This is correct behaviour, and the discipline is to surface it in the meeting rather than to obscure it. The corpus facilitators read each pass against the canonical archive for ownership-attributed signals and against the runtime telemetry for artefact-attributed signals. The two attributions are different by design, because the question "whose ledger registered this event" is different from the question "whose runtime artefact is consuming the resource." A trend-layer review that conflates the two attributions produces escalation candidates that route to the wrong owner, which is the operational symptom that the reconciliation rule has been silently shortcutted somewhere upstream.
A worked example from our archive: in 2025-Q3 the customer corpus's manifest ledger registered a tolerance-pin reset against the embedder cache, and in 2025-Q4 the internal-tools corpus's archive contained a row referencing the same event-id (because the embedder cache had migrated from the customer corpus to the internal-tools corpus during 2025-Q3-Q4 and the migration's downstream attestations propagated). The reconciliation rule canonicalised the customer corpus's row (earliest quarter-id) and marked the internal-tools corpus's row disputed. The cadence-drift pass for the customer corpus correctly counted the event in 2025-Q3 (its event-quarter). The ownership-migration pass for the embedder cache correctly surfaced the migration as a 2025-Q4 signal because the consumer-share telemetry showed corpus B becoming the primary consumer in that quarter. Both signals were correct; both routed to different thematic-carry-forward entries; and neither double-counted the event because the disputed row was excluded from the cadence pass while still being available to the migration pass via runtime telemetry.
Production Considerations: Archive Versioning, Retention, and Audit
The trend-layer archive grows at about one hundred entries per corpus per quarter, which works out to four hundred entries per year for a four-corpus organisation, or about one and a half thousand entries over the four-year retention window I recommend. The size is tractable in a single pandas DataFrame on a workstation, which is the deployment target I have settled on after trying a small Postgres deployment and finding the operational overhead disproportionate to the analytical benefit. The CSV-on-disk layout is the right one for this scale; I would revisit the choice at ten times the corpus count or at five times the per-corpus rate, neither of which is on our roadmap.
The retention window is four years for two reasons. The first is that the trend layer's analytical horizon is a single year and the meeting reads four quarters of archive; carrying four prior years means the trend layer can produce a year-over-year comparison if the engineering manager requests one, without needing a separate archival tier. The second is that the manifest ledger itself is retained for four years for audit reasons, and the trend-layer archive is downstream of the manifest ledger; aligning the retention windows is the path of least operational complexity. Older archives are moved to a cold-storage tier and are not read by the trend-pass query primitives.
The audit story is the part most engineering organisations miss when they first build a trend layer. The eleven-column schema, with archive-version, quarter-id, event-quarter, and reconciliation-state all explicit, is auditable in the sense that any thematic-carry-forward register entry can be traced back to a specific row in a specific archive version, and that row can be traced back to a specific manifest-ledger event registration. The trace path is what an external auditor (or, more often, a future engineering manager who is reviewing why an architecture commitment was funded against a particular signal) needs to reconstruct the analytical chain. A schema that is not audit-traceable is one where the analytical chain breaks somewhere between the manifest ledger and the trend-layer register, and the place the chain typically breaks is exactly the cross-quarter indexing convention I described in the introduction.
The failure mode I have not yet covered, but which I will mention briefly so that future readers can recognise it, is the taxonomy-version drift between archive and ledger. The archive's event-category value is captured at archive time against the manifest-ledger taxonomy as it existed at archive time. The ledger's taxonomy continues to evolve, sometimes splitting categories or merging them. The trend-layer query primitives that join against the per-quarter taxonomy version do this correctly, but the archive-time category is preserved unmodified, which means a query that ignores the per-quarter taxonomy join can produce a signal that contradicts the per-quarter join. The discipline is to require all trend-pass primitives to either join against the per-quarter taxonomy or to treat the archive-time category as a sentinel that cannot be aggregated across quarters. I have seen this failure mode three times in two years and it has caused two of the three thematic-carry-forward register revisions the engineering manager has asked me to redo.
Conclusion
The eleven-column manifest-ledger archival schema is the load-bearing artefact under the annual trend layer. The seven columns inherited from the per-quarter rollup carry the cross-team ownership and routing information; the four added columns carry the temporal axis, the version history, and the cross-corpus reconciliation state the trend layer reads against. The four trend-pass query primitives index against event-quarter, drop pending and disputed rows, and read the highest archive-version per quarter-id. The ledger-of-origin reconciliation rule resolves cross-corpus conflicts at archive time and produces a stable canonicality the trend layer can rely on across multi-year windows.
The next post in this cluster will walk through the manifest-ledger event-id assignment protocol the reconciliation rule depends on, including the registration-timestamp tiebreaker discipline, the cross-corpus propagation latency budget, and the dispute-resolution flow when an event-id collision is detected upstream rather than at archive time. The companion repo's adlc-eval-contracts/manifest-ledger/ directory contains the eleven-column schema definition, the enrichment-pass and reconciliation-pass scripts, the four trend-pass query primitives in pandas form, and a small worked-example dataset drawn from the cadence-drift and ownership-migration cases described in this post.

Sources
- LangChain. State of Agent Engineering. April 2026. https://www.langchain.com/state-of-agent-engineering
- Datadog. State of AI Engineering Report 2026. April 2026. https://www.datadoghq.com/state-of-ai-engineering/
- Google SRE Workbook. Postmortem Culture: Learning from Failure. https://sre.google/workbook/postmortem-culture/
- Martin Fowler. Event Sourcing. https://martinfowler.com/eaaDev/EventSourcing.html
- Confluent. Schema Evolution and Compatibility. https://docs.confluent.io/platform/current/schema-registry/avro.html
- HumanLoop. Drift Detection in LLM Eval Pipelines. https://humanloop.com/blog/eval-drift-detection
- PostgreSQL Documentation. Append-Only Tables and Versioned Schemas. https://www.postgresql.org/docs/current/ddl-partitioning.html
- Anthropic. Engineering Operations at Scale. 2026. https://www.anthropic.com/engineering
- Atlassian. Long-Range Engineering Planning Cycles. 2025. https://www.atlassian.com/engineering/long-range-planning
About the Author
Toc Am
Founder of AmtocSoft. Writing practical deep-dives on AI engineering, cloud architecture, and developer tooling. Previously built backend systems at scale. Reviews every post published under this byline.
Published: 2026-05-08 · Written with AI assistance, reviewed by Toc Am.
☕ Buy Me a Coffee · 🔔 YouTube · 💼 LinkedIn · 🐦 X/Twitter



Comments
Post a Comment