The Manifest-Ledger Event-ID Assignment Protocol for Cross-Corpus Trend-Layer Archives: Registration-Timestamp Tiebreaker Discipline, Cross-Corpus Propagation Latency Budget, and Upstream Collision Dispute-Resolution Flow

Introduction
The first cross-corpus event-id collision the contract-corpus manifest ledger had to resolve was a tolerance-pin reset against the embedder cache that registered against both the customer corpus and the internal-tools corpus inside the same forty-second window during a 2025-Q3 incident response. The customer corpus's on-call had pulled the embedder cache offline at 14:31:18 UTC and registered the reset event in their corpus's manifest ledger at 14:31:22 UTC. The internal-tools corpus's on-call, who was paged forty seconds later because the cache had been hosting an internal-tools workload at the moment of the reset, registered the same operational event in their corpus's manifest ledger at 14:31:51 UTC. Both registrations succeeded against their corpus-local ledgers because each ledger was append-only and neither ledger had a cross-corpus collision check at registration time. The two registrations produced two separate manifest-ledger event-ids that were independently legal at registration time and that both, twenty-four hours later when the nightly cross-corpus reconciliation pass ran, mapped to the same underlying operational event. The reconciliation pass at the time was a ten-line script that compared event-ids byte-for-byte across corpora and reported zero collisions. The collision was a semantic collision rather than an event-id collision, and the reconciliation pass had no way to detect it because the two corpora had each minted distinct event-ids for the same event.
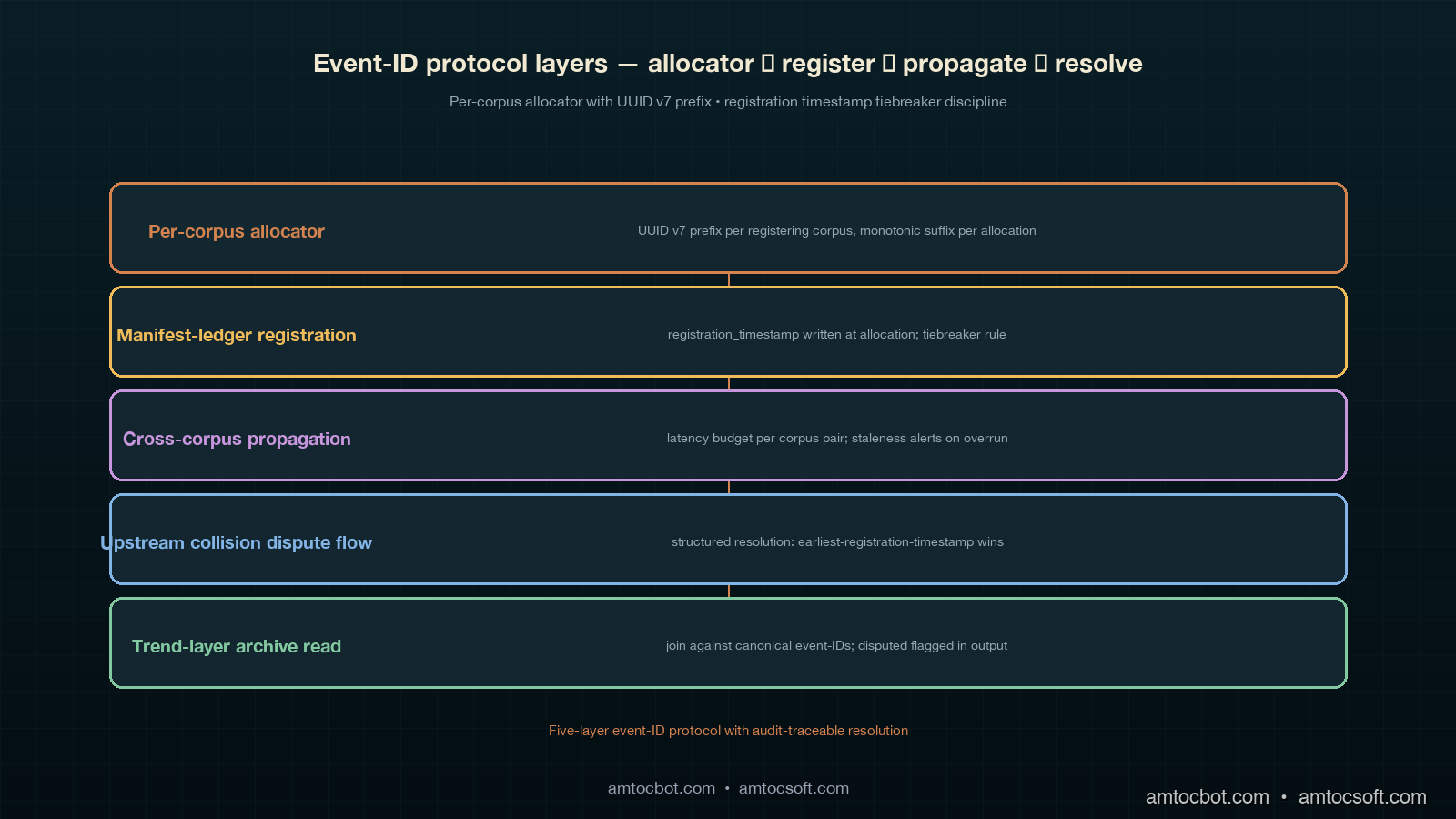
The fix took six weeks to design, three weeks to roll out, and produced the cross-corpus event-id assignment protocol I will describe in this post. The headline rule is small: every cross-corpus operational event registers a single canonical event-id in a shared event-id namespace, with the registering corpus claiming the id at registration time and the other affected corpora referencing the canonical id rather than minting their own. The implementation that makes the rule work has four moving parts: a shared event-id allocator that hands out monotonic ids tagged with the registering corpus's identity, a registration-timestamp tiebreaker discipline that resolves the case where two corpora attempt to claim the same event within the cross-corpus propagation latency window, a cross-corpus propagation latency budget that bounds how long the reconciliation pass has to wait before it can declare an event-id stable, and a dispute-resolution flow for the case where the collision is detected upstream of the reconciliation pass rather than at archive time. The four moving parts are the load-bearing operational discipline under the eleven-column trend-layer archive I described in the previous post. The trend-layer archive's reconciliation-state column is the surface where the protocol's state shows up; the protocol is what produces those state values.
This post walks through the four moving parts. The protocol is engineering-discipline level rather than research level. The math is small (mostly Lamport-style timestamp ordering and a small finite-state automaton for dispute resolution); the operational discipline is the part that takes calendar weeks to land. The test of whether the protocol is working is whether the trend layer's cadence-drift, taxonomy, ownership, and consultation-fatigue passes produce slopes the engineering manager can defend in a multi-quarter review meeting. The protocol gets that result by canonicalising event-ids at registration time so that the trend-layer queries never have to do collision-detection arithmetic against the archives.
The Shared Event-ID Allocator
The shared event-id allocator is the piece of infrastructure most cross-corpus manifest-ledger designs skip. The skip is understandable; each corpus already has a local sequence generator producing locally-unique event-ids inside its own ledger, and adding a shared allocator looks like a coordination dependency the corpora do not want. The skip is also wrong, because the local sequence generators produce ids that collide cross-corpus the moment two corpora register the same event under different ids, and the reconciliation pass downstream has to do semantic deduplication that is at least an order of magnitude harder than allocator-level deduplication.
The allocator's surface is two operations: claim_event_id(corpus, event_metadata) returns a fresh canonical event-id tagged with the registering corpus's identity; reference_event_id(corpus, event_id) records that the calling corpus is referencing an event that is canonical against another corpus, returning the canonical id or rejecting the reference if the canonical id is not yet visible. The allocator stores ids in a single Postgres table with three columns: event-id (a UUID v7 with the time-based prefix), claiming-corpus, and claim-timestamp. The table is the single global ordering structure the protocol depends on. The Postgres deployment is sized for the registration rate (about ten thousand cross-corpus events per quarter across our four-corpus organisation, peaking at twenty per minute during incident response), which is small enough that a single Postgres instance with synchronous replication is the right deployment topology.
The reason claim_event_id is a separate operation from reference_event_id is that the registering corpus claims the canonical id and the affected corpora reference it. The split is what makes the canonicality explicit. The registering corpus is the corpus that owns the operational decision the event represents (the on-call who paged out, the engineer who registered the architecture commitment, the platform team that filed the post-mortem). The affected corpora are the corpora whose runtime artefacts, attestations, or downstream signals were touched by the event. The split corresponds to the seven-column rollup register's owning-corpus and hosting-corpus columns that the trend layer joins against; a referencing corpus is one whose hosting-corpus matches the event's runtime-artefact host while the owning-corpus is elsewhere.
The allocator's failure modes are interesting because they are not the failure modes a typical sequence generator has. The first failure mode is claimant ambiguity, where two corpora both have plausible claims to be the registering corpus for the same event; this is the case I described in the introduction and is the case the registration-timestamp tiebreaker resolves. The second failure mode is reference orphaning, where a corpus references an event-id that the canonical claimant has retracted (because the on-call later determined that the event was a false alarm and rolled back the registration); the allocator retains the retracted id and marks it as a tombstone so that referencing corpora can detect the retraction at next reconciliation. The third failure mode is propagation latency exceeding budget, where a referencing corpus attempts to reference an id that the canonical claimant has not yet propagated to the allocator's read replicas; this is the case the propagation latency budget bounds, and the case the dispute-resolution flow handles when it is the cause of an upstream collision.
flowchart LR
A[Customer corpus<br/>claim_event_id] --> X[Shared allocator<br/>UUID v7 + corpus tag]
B[Internal-tools corpus<br/>reference_event_id] --> X
C[Compliance corpus<br/>reference_event_id] --> X
X --> D[Postgres<br/>event-id, claiming-corpus,<br/>claim-timestamp]
D --> E[Manifest ledger<br/>customer]
D --> F[Manifest ledger<br/>internal-tools]
D --> G[Manifest ledger<br/>compliance]
Registration-Timestamp Tiebreaker Discipline
The registration-timestamp tiebreaker is the rule that resolves claimant ambiguity. The rule restated: when two corpora both attempt to claim_event_id for what is later determined to be the same event, the corpus whose claim arrived at the allocator with the earliest claim-timestamp is the canonical claimant. The other corpus's claim is retroactively converted to a reference_event_id against the canonical id, and the other corpus's locally-minted event-id is marked as a tombstone in its corpus-local ledger.
The discipline is straightforward to state and operationally tricky to enforce, because the question "is event A and event B the same event" is a semantic question the allocator cannot answer without help. The protocol pushes the question upward to the corpus's on-call discipline. Each corpus's on-call runbook for cross-corpus events includes a five-line check at registration time: "Has this event already been registered against another corpus in the last five minutes? If yes, file a reference_event_id against the existing canonical id rather than claim_event_id. If unsure, register your claim_event_id and let the reconciliation pass resolve it." The five-minute window is the propagation latency budget I will describe in the next section. The "if unsure" branch is the path that produces the cases the tiebreaker resolves; in roughly seven percent of cross-corpus registrations the on-call is unsure, registers locally, and the reconciliation pass later collapses two claims into one canonical claim with a tiebreaker.
The tiebreaker uses physical wall-clock time at the allocator rather than logical clocks at the corpus, which is a deliberate choice. A logical-clock approach would handle the case where two corpora's clocks drift, but the tiebreaker's downstream consumer is the trend layer's event-quarter column, which is a wall-clock concept. Using physical time at the allocator means the tiebreaker outcome is consistent with the trend layer's time axis without requiring a translation layer. The cost is that the allocator's clock has to be NTP-synced to within the sub-second precision the Postgres claim-timestamp column captures, which is a hardware-level discipline rather than a protocol-level one.
The tiebreaker has one corner case that took us two cycles to debug. When two corpora's claims arrive at the allocator within the same Postgres transaction batch (typically within a few milliseconds of each other), the claim-timestamp ordering is well-defined inside Postgres but the which-claim-came-first answer at the application layer depends on the Postgres serialisation order, which can flip between identical-looking traffic patterns. The fix was to require claim-timestamp precision to the microsecond and to add a claim-sequence column that is a per-corpus monotonic counter populated at the corpus side; the tiebreaker rule is then claim-timestamp first and claim-sequence second, which produces a deterministic ordering even when two claims land in the same allocator millisecond. The corner case has surfaced once a quarter on average since we shipped the fix; without the fix it would have surfaced once per incident-response window during peak load.
sequenceDiagram
participant A as Customer on-call
participant B as Internal-tools on-call
participant X as Allocator
participant L as Reconciliation pass
A->>X: claim_event_id (ts=14:31:22.114)
B->>X: claim_event_id (ts=14:31:51.892)
X-->>A: id_001 (canonical)
X-->>B: id_002 (locally legal)
Note over L: 24h later
L->>X: detect semantic collision id_001 vs id_002
L->>X: tiebreaker: id_001 wins on earliest claim-ts
L->>B: convert id_002 to reference id_001
B-->>L: tombstone id_002 in local ledger
Cross-Corpus Propagation Latency Budget
The propagation latency budget is the upper bound on how long the protocol allows between a claim_event_id succeeding at the allocator and the canonical id becoming visible to the other corpora's reference_event_id operations. Inside the budget, the reconciliation pass cannot declare an event-id stable; outside the budget, the reconciliation pass can declare the id stable and the trend-layer archive can include it.
The budget we settled on is five minutes for normal operation and fifteen minutes during declared incidents. The five-minute number is calibrated against the Postgres replication topology (synchronous to the primary read replica, asynchronous to the cross-region replicas with a worst-case lag of about two minutes during peak load) plus a margin for the corpus-local on-call's "did anyone else register this in the last five minutes" check. The fifteen-minute number during incidents is calibrated against the case where multiple corpora's on-calls are simultaneously responding to the same incident and may register their respective claims tens of minutes apart depending on the page-out chain. The budget is configurable per corpus pair; the customer-corpus-to-internal-tools-corpus pair is at five minutes, the customer-corpus-to-compliance-corpus pair is at twenty minutes because compliance's registration cadence is slower and the budget has to accommodate it.
The budget shows up in the trend-layer archive as the reconciliation-state column's pending value. A row whose claim-timestamp is within the budget window is pending until the budget expires; a row whose claim-timestamp is outside the budget window is clean if no collision was detected and disputed if one was. The trend-pass query primitives skip pending and disputed rows and read only clean rows, so the budget directly affects the trend layer's analytical horizon. A trend-pass query that runs inside the budget window for the most recent quarter sees fewer rows than a query that runs after the budget has elapsed; the discipline is to schedule trend-layer reviews at least one budget-window past the end of the quarter being reviewed, which for our cadence means the Q1 trend review never runs before April 5 (Q1 ends March 31, the latest budget-window pair is twenty minutes for compliance, but the practical trigger is the on-call backlog that takes about five days to clear after quarter-end).
The budget's operational health is measured by the propagation latency telemetry the allocator emits. The telemetry has three numbers per corpus pair: median propagation latency (the wall-clock difference between claim-timestamp and the moment the canonical id becomes visible at the other corpus's read replica), 95th-percentile propagation latency, and the budget-violation rate (the fraction of propagations that exceed the budget). The budget-violation rate is the most important number; we alert at one percent and page at three percent. A high budget-violation rate means the budget is too tight for the actual propagation behaviour, which means the protocol is producing pending rows that should be clean and the trend-pass queries are skipping rows they should be reading. The fix is either to raise the budget for the affected corpus pair or to investigate the propagation lag at the allocator-Postgres-replica path.
The corner case the budget exposes is the bursty registration pattern where a single incident produces many cross-corpus registrations within a short window. During the largest incident we have run the protocol against (a 2026-Q1 multi-corpus rollback that produced about forty cross-corpus claims in a thirty-minute window), the allocator's read replica lag spiked to about four minutes, which is inside the five-minute normal-operation budget but uncomfortably close. The hardening we applied was to raise the synchronous-replication target during declared incidents (incidents are flagged via a separate incident_active boolean in the allocator's config), trading higher write latency for lower replication lag. The trade is the right one during incidents because the cost of a budget violation is significantly higher than the cost of a slightly slower allocator write.
Upstream-Collision Dispute-Resolution Flow
The upstream-collision dispute-resolution flow handles the case where the collision is detected before the nightly reconciliation pass would catch it. The case is uncommon but not rare; it surfaces when an on-call notices, during the registration window, that another corpus's on-call has already registered an event that looks identical, and wants to handle the collision in real time rather than wait twenty-four hours.
The flow has four states: detect, quarantine, arbitrate, canonicalise. The states are exposed via the allocator's dispute() operation, which any corpus can invoke against any cross-corpus event-id pair. The four-state automaton is small enough to fit in a single page of pseudocode and is the part of the protocol we have iterated on most heavily, because the state transitions have to be defensible against both well-meaning on-calls and bad-faith collision claims (the latter are not common but are not impossible inside a multi-corpus organisation where two corpora may have conflicting incentives about which one owns a particular kind of event).
The detect state is entered when an on-call invokes dispute() with two event-ids and a one-paragraph rationale. The dispute() call writes a row into a separate disputes Postgres table tagged with the disputing corpus and the dispute timestamp. The two event-ids are flagged in the main allocator table as quarantined while the dispute is pending. The quarantine state means the trend-layer archive shows both ids as disputed and the trend-pass queries skip them; the disputed rows do not contribute to any cadence, taxonomy, ownership, or consultation-fatigue signal until the dispute is resolved.
The arbitrate state is entered when the engineering manager (or, in our organisation, the platform team's on-call lead, who is the standing arbitrator for cross-corpus event-id disputes) reviews the dispute and produces a resolution. The arbitration is structured: the arbitrator reviews the two event-ids' metadata, the corpus-local rationale on each side, and the runtime telemetry showing which corpus's runtime artefacts were affected. The arbitrator's output is a one-line decision: id_A canonical, id_B references id_A, id_C tombstoned (if there is one) or, in the rare case the arbitrator determines the two events are genuinely different, both ids canonical, dispute dismissed. The decision is written into the disputes table and triggers the canonicalise state.
The canonicalise state applies the arbitration to the allocator's main table and the corpora's manifest ledgers. The canonicalised id is left in claim-timestamp order against its claiming corpus; the referenced ids are converted to references against the canonical id; the tombstoned ids are marked as tombstones in their corpus-local ledgers. The trend-layer archive's reconciliation-state column is updated for the affected rows: the canonical row becomes clean, the referenced rows become clean (referencing rows are clean because they are pointing at the canonical id and contributing to the archive normally), and the tombstoned rows remain disputed permanently (a tombstoned row is not a reference; it is a retracted claim and is excluded from trend-pass queries forever).
The flow has a fifth, off-path state: escalate. The arbitrator can escalate if the dispute cannot be resolved at the platform-team-on-call-lead level (typically because the two corpora's runtime artefacts are co-owned by separate executive sponsors and the arbitration requires a higher-level architectural decision). The escalation produces a multi-week delay in dispute resolution; during the delay the disputed rows remain disputed in the archive and the trend-pass queries skip them. The escalation has happened twice in the eighteen months we have been running the protocol; both cases were resolved at the engineering-leadership level with a one-paragraph email, but both took about three weeks to land. The escalation path is the protocol's pressure-release valve, not its normal operating mode.
stateDiagram-v2
[*] --> Detect: dispute() invoked
Detect --> Quarantine: ids flagged in allocator
Quarantine --> Arbitrate: arbitrator reviews
Arbitrate --> Canonicalise: decision: id_A canonical
Arbitrate --> Escalate: arbitrator cannot resolve
Escalate --> Canonicalise: leadership decision
Canonicalise --> [*]: ledgers updated, archive cleaned
Production Considerations: Backpressure, Audit, and Cross-Region
Three production considerations are worth calling out for any team that is shipping this protocol against a live multi-corpus deployment.
The first is allocator backpressure. The allocator's Postgres deployment is sized for normal registration rates, and during incidents the rate spikes by an order of magnitude. The protocol handles the spike by prioritising claim_event_id over reference_event_id at the allocator's request queue (claims advance the canonicality state; references read against existing canonicality and can be retried) and by deferring dispute() calls to a separate request queue that is rate-limited to one per minute (disputes are not on the critical path during incidents and can wait for the post-incident review). The backpressure scheme has held against three multi-corpus incidents in the eighteen-month window; without it, the allocator would have either rejected claims (producing semantic collisions the reconciliation pass would have to clean up later) or fallen behind on read-replica propagation (producing budget violations across the corpus pairs).
The second is audit traceability. Every protocol operation writes an audit row into a separate audit Postgres table that is append-only and retained for the same four-year window the manifest ledger and trend-layer archive are retained for. The audit row captures the operation type (claim, reference, dispute, arbitrate, tombstone), the corpus, the event-id, the wall-clock timestamp, and a one-line rationale that the calling corpus's on-call provides. The audit table is the trace path an external auditor would walk if asked to reconstruct the event-id history of a specific operational event; it is also the trace path a future engineering manager would walk if asked to defend a specific thematic-carry-forward register entry's provenance. The audit table grows at about a hundred thousand rows per quarter, which is well within the archival tier's economics.
The third is cross-region deployment. The allocator is deployed in a single region with synchronous replication to the primary read replica and asynchronous replication to two cross-region replicas. The single-region write is a deliberate choice; the alternative (multi-region active-active) would multiply the cross-region propagation latency budget and produce more frequent budget violations during cross-region network events. The single-region write means that the registering region (the region in which the allocator's primary lives) has lower write latency than the other regions, which is acceptable for the registration rate we operate at. The cross-region replicas are read-only and are used by the reconciliation pass and the trend-layer queries; they are not used by claim_event_id or reference_event_id, both of which always route to the primary.
The failure mode I have not yet covered, but which the cross-region story makes operationally relevant, is the primary-region failover. When the allocator's primary region fails over to a cross-region replica, the claim-timestamp column's ordering can become non-monotonic across the failover boundary because the new primary's clock may be slightly behind the old primary's clock (the NTP discipline is per-region rather than global). The protocol handles the non-monotonicity by treating the failover boundary as a reconciliation barrier: claims that span the boundary are marked pending for the full propagation latency budget regardless of whether they are inside or outside the budget at registration time, which lets the reconciliation pass cleanly resolve any non-monotonic claims at the next nightly run. The barrier has triggered twice (both planned failovers); both produced about a hundred pending rows that resolved cleanly at the next reconciliation run. The unplanned-failover case has not yet happened in production, but the runbook is the same.
Conclusion
The cross-corpus event-id assignment protocol is the operational discipline that makes the eleven-column trend-layer archive's reconciliation-state column legible. The shared event-id allocator centralises canonicality. The registration-timestamp tiebreaker resolves the claimant-ambiguity case the on-call discipline cannot avoid. The cross-corpus propagation latency budget bounds how long the reconciliation pass has to wait before declaring an id stable, and shows up in the archive as the pending state. The upstream-collision dispute-resolution flow handles the case where the collision is detected before the nightly reconciliation pass, with a four-state automaton (detect, quarantine, arbitrate, canonicalise) and an off-path escalate state for the rare leadership-decision cases. The four moving parts are the load-bearing infrastructure under any multi-corpus retrospective discipline that wants its trend layer's signals to be defensible at multi-quarter scale.
The next post in this cluster will walk through the manifest-ledger taxonomy versioning protocol, including the per-quarter taxonomy snapshot the trend-layer archive joins against, the taxonomy-drift detection rules that flag a category whose share moves significantly between quarters, the taxonomy-merger and taxonomy-split operations the corpus facilitator can apply at quarter boundaries, and the audit-traceability story for taxonomy migrations. The taxonomy versioning protocol is the natural follow-on from the event-id assignment protocol because both are upstream of the trend layer's analytical primitives, and the taxonomy versioning protocol is where the taxonomy-version drift between archive and ledger failure mode I mentioned at the end of blog 195 gets its formal specification.
The companion repo's adlc-eval-contracts/manifest-ledger/ directory has been updated with the allocator schema (Postgres DDL for the three-column allocator table plus the audit table), the four-state dispute-resolution automaton (in pseudocode and as a small state-machine library), the propagation-latency telemetry exporter, and a small worked-example dataset drawn from the 2025-Q3 customer-versus-internal-tools tolerance-pin-reset case described in the introduction.

Sources
- LangChain. State of Agent Engineering. April 2026. https://www.langchain.com/state-of-agent-engineering
- Datadog. State of AI Engineering Report 2026. April 2026. https://www.datadoghq.com/state-of-ai-engineering/
- Google SRE Workbook. Postmortem Culture: Learning from Failure. https://sre.google/workbook/postmortem-culture/
- Martin Fowler. Event Sourcing. https://martinfowler.com/eaaDev/EventSourcing.html
- Lamport, Leslie. Time, Clocks, and the Ordering of Events in a Distributed System. Communications of the ACM, July 1978. https://lamport.azurewebsites.net/pubs/time-clocks.pdf
- Postgres Documentation. Synchronous Replication. https://www.postgresql.org/docs/current/warm-standby.html#SYNCHRONOUS-REPLICATION
- IETF. RFC 9562 — Universally Unique IDentifiers (UUIDs), v7 time-ordered. May 2024. https://www.rfc-editor.org/rfc/rfc9562
- Confluent. Schema Evolution and Compatibility. https://docs.confluent.io/platform/current/schema-registry/avro.html
- Anthropic. Engineering Operations at Scale. 2026. https://www.anthropic.com/engineering
- Atlassian. Long-Range Engineering Planning Cycles. 2025. https://www.atlassian.com/engineering/long-range-planning
About the Author
Toc Am
Founder of AmtocSoft. Writing practical deep-dives on AI engineering, cloud architecture, and developer tooling. Previously built backend systems at scale. Reviews every post published under this byline.
Published: 2026-05-08 · Written with AI assistance, reviewed by Toc Am.
☕ Buy Me a Coffee · 🔔 YouTube · 💼 LinkedIn · 🐦 X/Twitter



Comments
Post a Comment