
GraphRAG vs Traditional RAG: When Relationships Matter
Traditional RAG is powerful. You chunk documents, embed them, and retrieve the most semantically similar passages. For most use cases, it works beautifully.
But there's a class of questions where traditional RAG completely falls apart: questions that require understanding relationships between entities.
"Which executives at Company X have connections to Board Members at Company Y?" "What's the chain of dependencies between these microservices?" "How does this drug interact with medications prescribed by the patient's other doctors?"
These questions don't live in any single document chunk. The answers are scattered across dozens of passages, connected by relationships that vector similarity alone cannot capture. This is exactly where GraphRAG enters the picture.
The Fundamental Limitation of Vector RAG
Traditional RAG works by proximity in embedding space. When you ask a question, it finds the chunks whose meaning is closest to your query. This is brilliant for factual lookups and topical retrieval.
But consider this scenario. You have 10,000 internal documents about your organization. You ask: "What are the main themes across our Q1 customer feedback?"
Traditional RAG will retrieve the top-K chunks most similar to "Q1 customer feedback." Maybe it grabs 5-10 passages. But the real answer requires synthesizing patterns across hundreds of feedback entries, understanding which themes connect to which products, which complaints link to which departments.
Vector search gives you local relevance. GraphRAG gives you global understanding.
graph TB Q["Query"] --> T["Traditional RAG Path"] Q --> G["GraphRAG Path"] T -->|embed| VS["Vector Search"] VS -->|retrieve| CH["Text Chunks"] CH -->|augment| LLM1["LLM"] G -->|traverse| GT["Graph Traversal"] GT -->|extract| ER["Entities + Relations"] ER -->|summarize| CS["Community Summaries"] CS -->|augment| LLM2["LLM"]
How GraphRAG Works
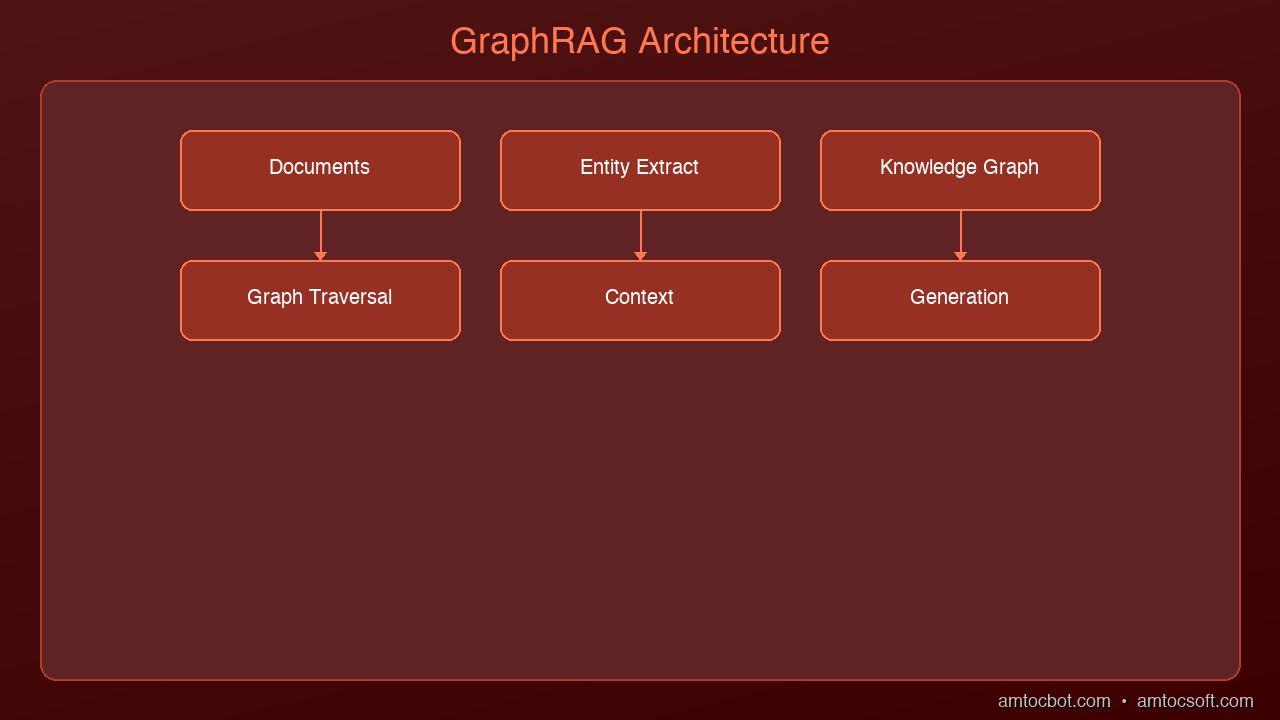
GraphRAG, pioneered by Microsoft Research in 2024, adds a knowledge graph layer on top of traditional retrieval. The process has two phases:
Phase 1: Indexing (Building the Graph)
Documents → Chunk → Extract Entities & Relationships → Build Knowledge Graph → Detect Communities → Generate Community Summaries
-
Entity Extraction: An LLM reads each chunk and extracts named entities (people, organizations, concepts, technologies) and the relationships between them.
-
Knowledge Graph Construction: Entities become nodes, relationships become edges. "Claude" →
DEVELOPED_BY→ "Anthropic" becomes a directed edge in the graph. -
Community Detection: Algorithms like Leiden clustering group tightly connected entities into communities. A cluster of related security concepts forms one community; a cluster of AI framework entities forms another.
-
Community Summaries: An LLM generates natural language summaries for each community, capturing the high-level themes and relationships within that cluster.
Phase 2: Querying
When a user asks a question, GraphRAG can use two strategies:
Local Search — Similar to traditional RAG but graph-enhanced:
- Find relevant entities in the graph
- Traverse their relationships to gather connected context
- Retrieve the original text chunks associated with those entities
- Feed everything to the LLM
Global Search — The game-changer:
- Use community summaries to answer high-level questions
- The LLM reads across community summaries to synthesize a global answer
- No single chunk needs to contain the full answer
The Architecture Difference
Traditional RAG:
Query → Embed → Vector Search → Top-K Chunks → LLM → Answer
GraphRAG (Local):
Query → Entity Recognition → Graph Traversal → Related Chunks + Relationships → LLM → Answer
GraphRAG (Global):
Query → Community Map → Relevant Summaries → LLM Synthesis → Answer
When to Use Which
| Scenario | Traditional RAG | GraphRAG |
|---|---|---|
| "What is our refund policy?" | Best choice | Overkill |
| "Summarize themes across 500 support tickets" | Poor — retrieves fragments | Excellent — uses community summaries |
| "How are Team A's projects connected to Team B's roadmap?" | Cannot connect across docs | Built for this — graph traversal |
| "Find the definition of Term X" | Best choice | Unnecessary |
| "What are the indirect dependencies of Service Y?" | Misses transitive relationships | Follows the dependency chain |
| "Which topics come up together in customer complaints?" | Retrieves individual complaints | Identifies co-occurring themes |
Rule of thumb: If the answer lives in a single passage, use traditional RAG. If the answer requires connecting information across multiple documents, use GraphRAG.
Building a Minimal GraphRAG Pipeline
Here's a simplified implementation using NetworkX and Claude:
import networkx as nx
import anthropic
from typing import List, Dict, Tuple
client = anthropic.Anthropic()
def extract_entities_and_relations(chunk: str) -> List[Dict]:
"""Use an LLM to extract entities and relationships from a text chunk."""
response = client.messages.create(
model="claude-sonnet-4-6-20250514",
max_tokens=1024,
messages=[{
"role": "user",
"content": f"""Extract entities and relationships from this text.
Return JSON array of objects with: source, relation, target
Text: {chunk}
Return only valid JSON."""
}]
)
import json
return json.loads(response.content[0].text)
def build_knowledge_graph(chunks: List[str]) -> nx.DiGraph:
"""Build a knowledge graph from document chunks."""
G = nx.DiGraph()
for i, chunk in enumerate(chunks):
triples = extract_entities_and_relations(chunk)
for triple in triples:
G.add_edge(
triple["source"],
triple["target"],
relation=triple["relation"],
source_chunk=i
)
return G
def local_search(G: nx.DiGraph, query_entities: List[str],
chunks: List[str], hops: int = 2) -> str:
"""Graph-enhanced local search: find entities, traverse, gather context."""
relevant_chunks = set()
for entity in query_entities:
if entity in G:
# Get neighbors within N hops
for neighbor in nx.single_source_shortest_path(G, entity, cutoff=hops):
# Collect chunks associated with edges to this neighbor
for _, _, data in G.edges(neighbor, data=True):
relevant_chunks.add(data.get("source_chunk"))
# Build context from related chunks
context = "\n---\n".join(chunks[i] for i in relevant_chunks if i < len(chunks))
return context
# Usage
chunks = [...] # Your document chunks
G = build_knowledge_graph(chunks)
# Query with graph-enhanced retrieval
context = local_search(G, ["Claude", "MCP"], chunks, hops=2)
response = client.messages.create(
model="claude-sonnet-4-6-20250514",
max_tokens=2048,
messages=[{
"role": "user",
"content": f"Context:\n{context}\n\nQuestion: How does Claude use MCP?"
}]
)
The Cost-Quality Tradeoff
GraphRAG is significantly more expensive than traditional RAG:
| Dimension | Traditional RAG | GraphRAG |
|---|---|---|
| Indexing cost | Embedding API calls only | LLM calls for entity extraction + embeddings |
| Indexing time | Minutes for 10K docs | Hours for 10K docs (LLM-intensive) |
| Storage | Vector DB | Vector DB + Graph DB |
| Query latency | 100-500ms | 500ms-5s (graph traversal + LLM) |
| Query cost | 1 LLM call | 1-3 LLM calls (entity extraction + synthesis) |
| Global queries | Poor quality | High quality |
| Local queries | Good quality | Slightly better quality |
Microsoft's research showed GraphRAG outperformed traditional RAG by 30-70% on global sensemaking queries, but the indexing cost was 10-100x higher.
Real-World Applications
Corporate Knowledge Management: "What are the recurring themes across our last 12 months of board meeting minutes?" GraphRAG builds entity graphs across all meetings, identifies theme communities, and synthesizes a coherent answer no single document contains.
Biomedical Research: "What proteins interact with Drug X, and which of those are also targets of Drug Y?" The knowledge graph captures protein-drug-gene relationships across thousands of papers.
Supply Chain Analysis: "If Supplier A goes offline, what's the cascading impact on our product lines?" GraphRAG traces the dependency chain through the supply graph.
Legal Discovery: "Find all communications between these 5 people that reference Project Z." Graph search connects person nodes through communication edges filtered by topic.
Current Tools and Frameworks
| Tool | Type | Best For |
|---|---|---|
| Microsoft GraphRAG | Full framework (Python) | Production-ready, well-documented |
| LlamaIndex | Property graph support | Integration with existing LlamaIndex pipelines |
| Neo4j + LangChain | Graph DB + framework | When you already use Neo4j |
| LightRAG | Lightweight alternative | Faster indexing, simpler setup |
| nano-graphrag | Minimal implementation | Learning and prototyping |
Start here: If you're exploring, try nano-graphrag to understand the concepts. For production, Microsoft's GraphRAG or LlamaIndex's property graph module.
The Hybrid Approach
The smartest teams don't choose one or the other. They use a routing layer that analyzes the query and decides which retrieval strategy to use:
def route_query(query: str) -> str:
"""Determine whether to use vector RAG or GraphRAG."""
response = client.messages.create(
model="claude-haiku-3-20250514",
max_tokens=50,
messages=[{
"role": "user",
"content": f"""Classify this query:
- "local" if it asks about a specific fact, definition, or passage
- "global" if it asks about themes, patterns, relationships, or summaries across multiple sources
Query: {query}
Classification:"""
}]
)
return response.content[0].text.strip().lower()
# Route to appropriate strategy
if route_query(user_question) == "global":
answer = graphrag_global_search(user_question)
else:
answer = traditional_vector_search(user_question)
What's Next
GraphRAG is still evolving rapidly. The next frontier is dynamic graphs — knowledge graphs that update incrementally as new documents arrive, rather than requiring full reindexing. Combined with agentic RAG patterns (where an AI agent decides what to retrieve, from where, and when), we're moving toward retrieval systems that truly understand the structure of knowledge, not just the surface meaning of text.
If you're already running traditional RAG in production, the question isn't whether to switch — it's whether your users are asking questions that require connecting dots across documents. If they are, GraphRAG is worth the investment.
Sources & References:
1. Microsoft Research — "GraphRAG: Unlocking LLM Discovery on Narrative Private Data" (2024) — https://arxiv.org/abs/2404.16130
2. Microsoft — "GraphRAG GitHub Repository" — https://github.com/microsoft/graphrag
3. Lewis et al. — "Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks" (2020) — https://arxiv.org/abs/2005.11401
Part of the RAG & Retrieval Systems series on AmtocSoft. Follow us on LinkedIn and X for daily AI engineering insights.
About the Author
Toc Am
Founder of AmtocSoft. Writing practical deep-dives on AI engineering, cloud architecture, and developer tooling. Previously built backend systems at scale. Reviews every post published under this byline.
Published: 2026-04-02 · Written with AI assistance, reviewed by Toc Am.
Get These In Your Inbox
Weekly deep-dives on AI engineering, no fluff. Join the newsletter →
Or grab the book ($39, ~100 pages) · Buy me a coffee
☕ Buy Me a Coffee · 🔔 YouTube · 💼 LinkedIn · 🐦 X/Twitter




No comments:
Post a Comment