
Level: Advanced | Topic: AI / ML Architecture | Read Time: 15 min
If you have used ChatGPT, Claude, Gemini, or any modern language model, you have interacted with a Transformer. Introduced in the 2017 paper "Attention Is All You Need" by Vaswani et al., the Transformer architecture replaced recurrent neural networks as the dominant approach for sequence modeling — and then escaped the boundaries of natural language processing entirely. Today, the same architectural principles power image generation, protein folding predictions, code completion, and multimodal reasoning across text, images, and audio simultaneously.
This article goes deep. It covers the core components, the historical evolution that brought the architecture to where it is today, the critical distinction between how Transformers train versus how they generate at inference time, the modern variants that extend the original design, and the genuine limitations that researchers are still working to overcome.
The Problem Transformers Solved
To understand why the Transformer was a breakthrough, you need to understand what it replaced.
Before Transformers, the dominant architecture for sequence modeling was the LSTM (Long Short-Term Memory network). LSTMs processed sequences token by token, left to right. The model maintained a hidden state — a compressed vector representing everything it had learned so far — and updated it with each new token.
This sequential design had two fundamental problems.
Problem 1: Long-range dependencies. A word at position 500 in a document had to maintain its influence through 499 sequential updates to the hidden state. By the time the model reached the end of a long document, early context had been diluted or overwritten. Subject-verb agreement across clauses, thematic coherence across paragraphs, and cross-document references were all difficult to capture.
Problem 2: No parallelization. Because each token's state depended on the previous token's computation, training was inherently sequential. You couldn't split the workload across GPUs and compute all positions simultaneously. As training datasets grew into the billions of tokens, LSTM training became the bottleneck before model quality did.
Transformers solved both problems with a single mechanism: self-attention. Instead of processing tokens sequentially, a Transformer processes all positions in the sequence simultaneously. And instead of a hidden state that degrades over distance, self-attention computes a direct relationship between every pair of tokens — position 1 and position 500 have the same direct access to each other regardless of the distance between them.
Nine Years of Evolution: From "Attention Is All You Need" to 2026
The Transformer's dominance didn't happen overnight. Understanding the progression explains both how the architecture works and why frontier models look the way they do today.
2017 — The Original Architecture. Vaswani et al. at Google Brain built a model for machine translation with an encoder that reads the input sentence and a decoder that generates the output sentence. The key innovation: replacing recurrence with self-attention throughout. The model trained faster and matched or exceeded state-of-the-art translation quality.
2018 — The Pre-Training Paradigm. BERT (Bidirectional Encoder Representations from Transformers) and GPT-1 demonstrated that a Transformer pre-trained on large text corpora could be fine-tuned on downstream tasks with much less data than training from scratch. This is the pre-training / fine-tuning paradigm that all modern LLMs follow. Pre-train on huge unlabeled data; fine-tune on task-specific labeled data. The two models also established two different architectural directions: BERT's bidirectional encoder (useful for understanding/classification tasks) and GPT's unidirectional decoder (useful for generation tasks).
2020 — Emergent Scale. GPT-3's 175 billion parameters produced a qualitative shift: the model demonstrated in-context learning, performing new tasks from a few examples in the prompt without any gradient updates. Simultaneously, Kaplan et al.'s scaling laws paper showed that model performance scales predictably with compute, data, and parameters — providing a roadmap for continued improvement.
2021-2022 — Beyond Language. Vision Transformers (ViT) showed that the same architecture could process image patches as a sequence, matching or beating convolutional networks on image classification. Codex applied GPT to code. DALL-E combined text and image understanding. The architecture became architecture-agnostic to the modality.
2023-2026 — The Frontier. Open-weight models (LLaMA, Mistral) made research-quality models accessible. Context windows expanded from 4K to 1M+ tokens. Multimodal models (GPT-4V, Gemini, Claude 3 Sonnet) processed images, code, and text together. Architecture variants like Mixture of Experts (MoE) scaled model capacity without proportional compute cost.
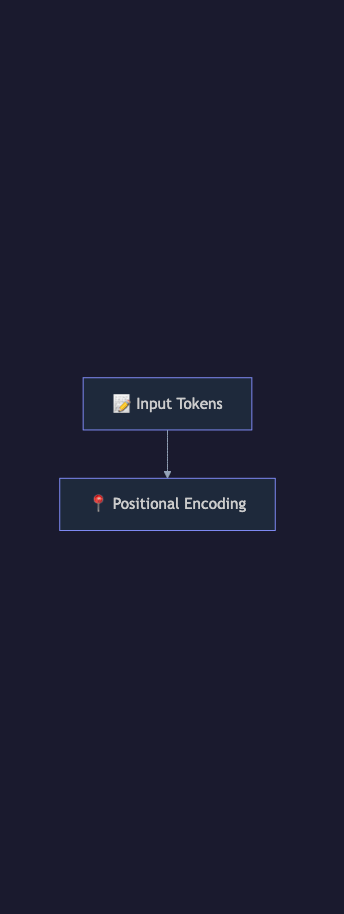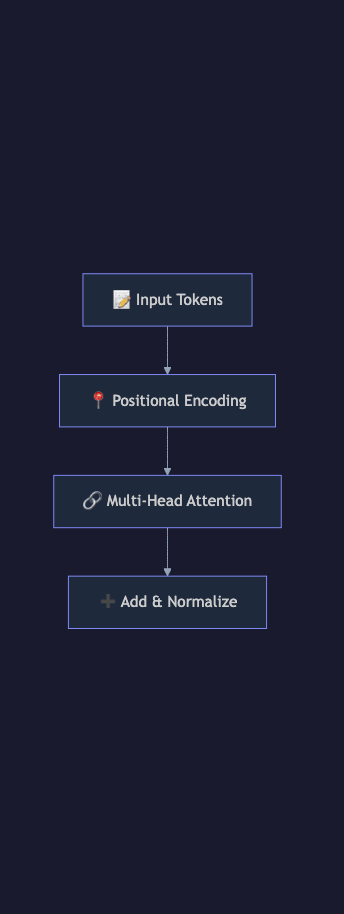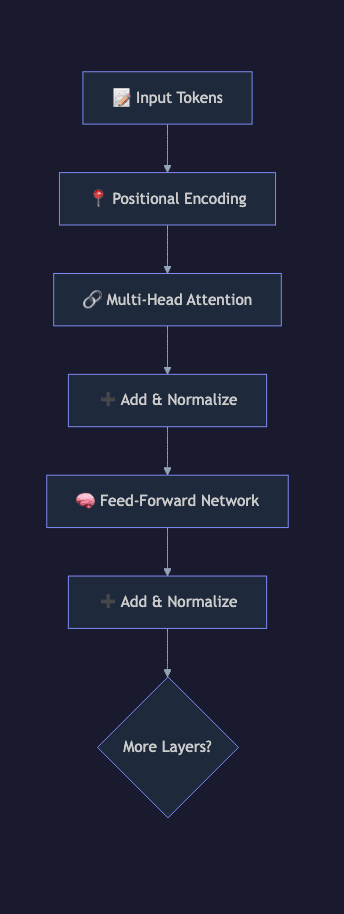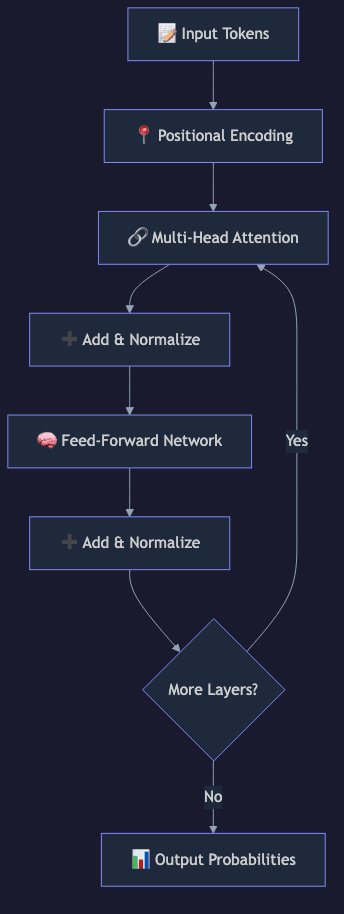
Core Architecture: The Six Components
+ Positional Encoding"] B --> C["Multi-Head Self-Attention"] C --> D["Add & Layer Norm"] D --> E["Feed-Forward Network"] E --> F["Add & Layer Norm"] F --> G{"N layers?"} G -->|"Repeat N times"| C G -->|"Done"| H["Final Layer Norm"] H --> I["Linear Projection"] I --> J["Softmax → Token Probabilities"] style C fill:#4c6ef5,color:#fff style E fill:#7950f2,color:#fff style J fill:#51cf66
1. Input Embeddings and Positional Encoding
The Transformer converts each input token into a dense vector (embedding) of fixed dimension — typically 768 to 8,192 dimensions depending on model size. These embeddings are learned during training: similar tokens end up in similar vector positions.
Because the architecture processes all positions simultaneously, it has no inherent sense of order. Positional encodings are added to token embeddings to inject position information. The original paper used sinusoidal functions. Modern models like LLaMA use Rotary Position Embeddings (RoPE), which encode relative position information and handle sequences longer than those seen during training more gracefully.
2. Self-Attention (The Core Innovation)
For each token, the model computes three vectors from its embedding by multiplying through three learned weight matrices:
- Query (Q): "what am I looking for?"
- Key (K): "what information do I represent?"
- Value (V): "what information do I provide if attended to?"
The attention score between token i and token j is computed as the dot product of Q_i and K_j, scaled by √d_k (the key dimension), then passed through softmax. This produces a probability distribution over all positions — how much attention token i should pay to every other token j.
The output for each position is the weighted sum of all Value vectors, where weights are the attention scores:
Attention(Q, K, V) = softmax(QK^T / √d_k) × V
This allows the model to dynamically focus on the most relevant parts of the input for each position, regardless of distance.
3. Multi-Head Attention
Rather than computing one attention function, Transformers run multiple attention operations — "heads" — in parallel, each learning to attend to different types of relationships. One head might learn syntactic relationships (subject → verb), another semantic similarity (synonyms), another positional proximity (nearby tokens).
Each head operates on a lower-dimensional projection of Q, K, V. All head outputs are concatenated and projected through a linear layer. In GPT-3, there are 96 attention heads per layer, each operating on 128 dimensions of the 12,288-dimensional model.
4. Feed-Forward Network
After the attention layer, each position's vector passes through a two-layer feed-forward network (FFN) with a non-linear activation (GELU is standard). The FFN is applied independently and identically to each position — it doesn't see other positions at this stage.
Research suggests the FFN layers function as key-value memory, with individual neurons activating for specific concepts, facts, or patterns learned during training. The FFN is where much of the model's "knowledge" is stored, while attention layers primarily handle routing and relationship reasoning.
5. Layer Normalization and Residual Connections
Every sub-layer (attention and FFN) is wrapped in two ways:
- Residual connections add the input to the output of each sub-layer. This allows gradients to flow directly through the network, enabling very deep models (GPT-4 likely exceeds 100 layers). Without residuals, training deep networks is numerically unstable.
- Layer normalization normalizes activations to zero mean and unit variance. Modern implementations use "pre-norm" — normalization before the sub-layer — which is more stable at scale than the original paper's "post-norm" design.
6. Output Projection
After all N layers, the final hidden state for each position is projected through a linear layer to a vector of size equal to the vocabulary (typically 32,000 to 128,000 tokens). Softmax converts these logits into a probability distribution over the next token.
During inference, the model samples from this distribution to generate the next token. During training, the loss is the negative log-likelihood of the correct next token.
Encoder vs. Decoder: Two Different Architectures for Two Different Tasks
The original Transformer had both an encoder and a decoder. Modern models specialize in one or the other.
| Architecture | Examples | Attention Type | Use Case |
|---|---|---|---|
| Encoder-only | BERT, RoBERTa, DeBERTa | Bidirectional (all tokens see all tokens) | Classification, embeddings, named entity recognition |
| Decoder-only | GPT-4, LLaMA, Claude, Gemini | Causal (each token sees only previous tokens) | Text generation, code, chat |
| Encoder-decoder | T5, BART, mT5 | Bidirectional encoder + causal decoder | Translation, summarization, question answering |
Why causal attention for generation? When generating text, the model should not be able to "see" future tokens — that would be cheating. Causal masking is implemented by masking the attention scores for future positions to -∞ before the softmax. This forces each position's output to depend only on past context.
Why bidirectional attention for encoding? When producing embeddings for retrieval or classification, you want the model to consider full context in both directions — "bank" means different things in "river bank" vs "bank account," and you need both sides to disambiguate.
← bidirectional →"] A2 --> A3["Embedding
(captures full context)"] end subgraph "Decoder-only (GPT/Claude)" B1["Token 1"] --> B2["Token 2
sees tokens 1-2 only"] B2 --> B3["Token 3
sees tokens 1-3 only"] B3 --> B4["...generates token N"] end style A2 fill:#4c6ef5,color:#fff style B4 fill:#51cf66
Training vs. Inference: What the Model Is Actually Doing
These are two fundamentally different operations on the same architecture.
Pre-Training
During pre-training, the model learns from massive amounts of unlabeled text. For decoder-only models (GPT, LLaMA), the objective is next-token prediction: given all tokens before position i, predict the token at position i. This is computed for all positions simultaneously in a single forward pass using causal masking.
The loss is averaged over all positions in the batch. Gradients flow back through the network via backpropagation, and weights are updated. At GPT-3 scale, this training used roughly 300 billion tokens and cost millions of dollars in compute.
For BERT-style encoders, the objective is masked language modeling: randomly mask 15% of input tokens and predict the masked values. This forces the model to understand context from both directions.
Fine-Tuning and Alignment
After pre-training, raw models respond to inputs in statistically likely ways — not necessarily helpful ways. Instruction fine-tuning (SFT) trains the model on examples of the behavior you want. RLHF or DPO alignment further shapes the model to be helpful, harmless, and honest based on human preference signals.
Inference (Generation)
At inference time, the model generates one token per forward pass. The output token is appended to the input, and the model runs again for the next token. This is autoregressive generation.
The key datastructure: the KV cache. During inference, the model computes key and value vectors for every token in the context. Since the context grows by one token each step, recomputing everything would be wasteful. The KV cache stores previously computed K and V tensors and reuses them. This is why KV cache management is the central challenge of production LLM serving.
Modern Architectural Variants
The basic Transformer has been extended in numerous ways since 2017. These are the most impactful:
Flash Attention
Standard attention computes QK^T for all n positions, requiring O(n²) memory in the GPU's high-bandwidth memory (HBM). For a 128K context window with a large model, this becomes a practical bottleneck.
Flash Attention (Dao et al., 2022) computes attention in tiles, keeping intermediate results in GPU SRAM rather than HBM. Memory usage drops from O(n²) to O(n), and throughput improves 2-4× because SRAM bandwidth is dramatically higher than HBM bandwidth. Flash Attention 2 and 3 have further improved efficiency. It is now the default attention implementation in virtually every serious training and serving stack.
Vision Transformers (ViT)
ViT treats images as sequences of patches. A 224×224 image is split into 16×16 patches, each flattened into a vector and embedded. The sequence of patch embeddings is processed by a standard Transformer encoder. Positional embeddings encode spatial position.
ViT matches or exceeds ResNet-style CNNs on image classification at large scale. Its success enabled multimodal models: GPT-4V, Claude 3, and Gemini all process image patches and text tokens through shared attention layers.
Mixture of Experts (MoE)
In a standard Transformer, every token passes through every FFN neuron on every layer. MoE replaces each FFN layer with multiple "expert" FFN networks (8, 64, or more). A learned router selects 1-2 experts for each token per layer.
MoE allows scaling total parameter count without proportionally scaling compute — only the activated experts are computed. GPT-4 is widely believed to be an MoE model. Mistral's Mixtral 8×7B demonstrated that a 46.7B total parameter model activates only 12.9B parameters per token, performing comparably to much larger dense models.
Grouped Query Attention (GQA)
Standard multi-head attention maintains separate K and V projections for every head. GQA groups multiple query heads to share the same K/V pairs. This reduces KV cache size significantly — critical for serving with long contexts — while preserving most quality. LLaMA 3 and many 2024+ models use GQA.
Major Models: A Comparison
| Model | Organization | Params | Context | Architecture | Open Weights |
|---|---|---|---|---|---|
| GPT-4o | OpenAI | ~200B (est.) | 128K | Decoder (MoE?) | No |
| Claude 4 Sonnet | Anthropic | Unknown | 200K | Decoder | No |
| Gemini 1.5 Pro | Google | Unknown | 1M | Decoder (MoE?) | No |
| LLaMA 3.3 70B | Meta | 70B | 128K | Decoder (GQA) | Yes |
| Mistral Large | Mistral AI | ~123B | 128K | Decoder | No |
| DeepSeek-V3 | DeepSeek | 671B total / 37B active | 128K | Decoder (MoE) | Yes |
All of these models are Transformer-based decoder stacks. The differences are in scale, training data, fine-tuning methodology, alignment approach, and architectural details (MoE vs dense, GQA vs MHA, positional encoding scheme) — not in the fundamental architecture.
Limitations and Ongoing Challenges
The Transformer's dominance doesn't mean it's the final architecture. Several real limitations are actively driving research.
Quadratic Attention Complexity
Standard attention is O(n²) in compute with sequence length n. Doubling the context window quadruples the attention computation. Flash Attention reduces memory to O(n) but the compute cost remains O(n²). At 1M tokens, this is a genuine constraint that requires specialized infrastructure (tensor parallelism, Ulysses sequence parallelism).
Linear attention variants attempt to reduce this to O(n), but most sacrifice quality significantly. This is an active research area.
Computational and Energy Cost
Training frontier models requires tens of thousands of H100 GPUs running for months. GPT-4's training was estimated at over $100 million in compute. This concentrates frontier model development in a handful of well-funded organizations. The inference cost of running these models at scale is also substantial — this is why KV cache optimization (PagedAttention, speculative decoding) is a major engineering focus.
Reasoning vs. Pattern Matching
A consistent critique from the research community: Transformers are fundamentally doing sophisticated pattern matching over their training distribution, not the kind of abstract causal reasoning humans perform. Performance drops on out-of-distribution problems, on multi-step mathematical proofs requiring exact logical chains, and on tasks requiring genuine novelty not approximated in training data.
Whether this is a fundamental architectural limitation or a training/scale issue is actively debated. Models like OpenAI's o-series use extended chain-of-thought reasoning as a workaround, effectively giving the model more "thinking time" through additional tokens.
Alternative Architectures
State Space Models (SSMs), particularly Mamba (Gu & Dao, 2023), offer O(n) computation and fixed-size recurrent state — in theory, better asymptotic efficiency than Transformers for very long sequences. Some benchmarks show competitive quality at moderate scale with much lower inference cost.
Hybrid architectures (Jamba, Zamba, Falcon Mamba) combine Transformer attention layers with SSM layers, attempting to get the best of both: attention's quality on reasoning tasks, SSM's efficiency on long sequence processing.
Whether Transformers retain dominance at the frontier through 2030 or get displaced by hybrid or SSM architectures is genuinely open. The current consensus: Transformers will remain dominant in the near term, but may be complemented or partially replaced in specific workloads as hardware and training methods evolve.
Why This Architecture Matters for Practitioners
Understanding Transformer internals shapes practical decisions across the stack.
Context window design. The quadratic cost of attention is why context windows have historically been limited — and why extending them requires careful engineering. If you're building RAG pipelines, understanding that more context isn't always better (attention dilutes across longer sequences, earlier tokens receive less attention weight) informs chunk sizing and retrieval strategy.
Embedding quality and vector search. When you use a Transformer encoder to create embeddings for semantic search, you're capturing the model's internal representation of meaning — the high-dimensional space where similar concepts cluster together. The quality of your vector database's similarity search directly reflects the quality of the encoder's attention patterns. This is why model choice for embedding matters as much as vector index choice.
Fine-tuning and adaptation. LoRA (Low-Rank Adaptation) works by decomposing weight updates into low-rank matrices during fine-tuning. Its efficiency is partly justified by the observation that attention heads in large models already exhibit low-rank structure — the actual dimensionality of useful weight updates is much lower than the full matrix dimensions suggest.
System prompt and in-context learning. When you write a system prompt, you're injecting tokens into the attention mechanism that influence every subsequent token's generation through attention scores. The model's "following instructions" behavior is the attention patterns across those instruction tokens shaping all subsequent FFN and attention computations.
KV cache in production serving. For production inference, the KV cache is not an implementation detail — it's the central resource that limits how many concurrent users a serving system can handle. Every engineering decision in LLM serving (PagedAttention in vLLM, continuous batching, speculative decoding) exists to manage KV cache more efficiently.
Conclusion
The Transformer architecture introduced in 2017 has proven to be one of the most consequential innovations in software history. What started as a machine translation model has become the foundation for every frontier AI system: language models, image generators, code assistants, multimodal reasoning systems, and protein structure predictors.
The core insight — replace sequential recurrence with parallel self-attention — solved two fundamental problems simultaneously and proved to scale with compute in ways recurrent networks couldn't. Nine years of refinements (pre-training paradigms, RLHF alignment, Flash Attention, MoE, extended context) have extended the original design without changing its fundamental character.
Understanding this architecture at the level described here — not just that attention exists, but what it computes, how training differs from inference, why causal masking matters for generation, what the KV cache is doing in production — is the foundation for building serious AI systems. Every practical decision downstream of "use an LLM" makes more sense with this grounding.
Revision History
| Date | Summary | Old Version |
|------|---------|-------------|
| 2026-04-14 | Expanded from ~800 to 3000+ words. Added historical timeline (2017-2026), encoder vs decoder architectural distinction, training vs inference section, modern variants (Flash Attention, ViT, MoE, GQA), major model comparison table, limitations section (quadratic complexity, reasoning critique, SSM alternatives), and expanded practitioner implications. | [View original](../revisions/003-how-transformers-work-2026-03-31.md) |
Sources & References
1. Vaswani et al. — "Attention Is All You Need" — https://arxiv.org/abs/1706.03762
2. Devlin et al. — "BERT: Pre-training of Deep Bidirectional Transformers" — https://arxiv.org/abs/1810.04805
3. Brown et al. — "Language Models are Few-Shot Learners (GPT-3)" — https://arxiv.org/abs/2005.14165
4. Dosovitskiy et al. — "An Image is Worth 16x16 Words: ViT" — https://arxiv.org/abs/2010.11929
5. Dao et al. — "FlashAttention-2: Faster Attention with Better Parallelism" — https://arxiv.org/abs/2307.08691
6. Gu & Dao — "Mamba: Linear-Time Sequence Modeling with Selective State Spaces" — https://arxiv.org/abs/2312.00752
7. Shazeer et al. — "Outrageously Large Neural Networks: The Sparsely-Gated MoE Layer" — https://arxiv.org/abs/1701.06538
8. Jay Alammar — "The Illustrated Transformer" — https://jalammar.github.io/illustrated-transformer/
Enjoyed this post? Follow AmtocSoft for AI tutorials from beginner to professional.
☕ Buy Me a Coffee | 🔔 YouTube | 💼 LinkedIn | 🐦 X/Twitter




No comments:
Post a Comment