Level: Intermediate
Topic: Voice AI, STT

Speech-to-text is the front door of every voice AI system. If your transcription is wrong, everything downstream -- the LLM's understanding, the response, the user experience -- falls apart. Getting STT right is non-negotiable.
But the STT landscape in 2026 looks radically different from even a year ago. OpenAI has added GPT-4o-powered transcription alongside Whisper. NVIDIA's Canary model hit #1 on the Open ASR leaderboard with a hybrid ASR-LLM architecture. Deepgram Nova-3 claims 53% lower error rates than competitors. And the gap between academic benchmarks and real-world production performance remains a critical trap for teams that don't test on their own data.
In this post, we'll compare the major STT solutions head-to-head with real benchmark numbers, production latency profiles, and cost analysis at scale. We'll cover Whisper, Deepgram, Google, AssemblyAI, and the new challengers -- then give you a decision framework for your specific use case.
The Contenders
| Solution | Type | Model | Best For |
|---|---|---|---|
| Whisper | Open-source / API | Large v3 Turbo | Accuracy, offline use, self-hosted |
| GPT-4o Transcribe | Commercial API | GPT-4o architecture | Context-aware transcription |
| Deepgram | Commercial API | Nova-3 | Real-time streaming, low latency |
| Google Speech | Commercial API | Chirp 3 | Enterprise, massive language support |
| AssemblyAI | Commercial API | Universal-2 | Best streaming accuracy, rich features |
| NVIDIA Canary | Open-source | Canary-Qwen-2.5B | Highest benchmark accuracy |
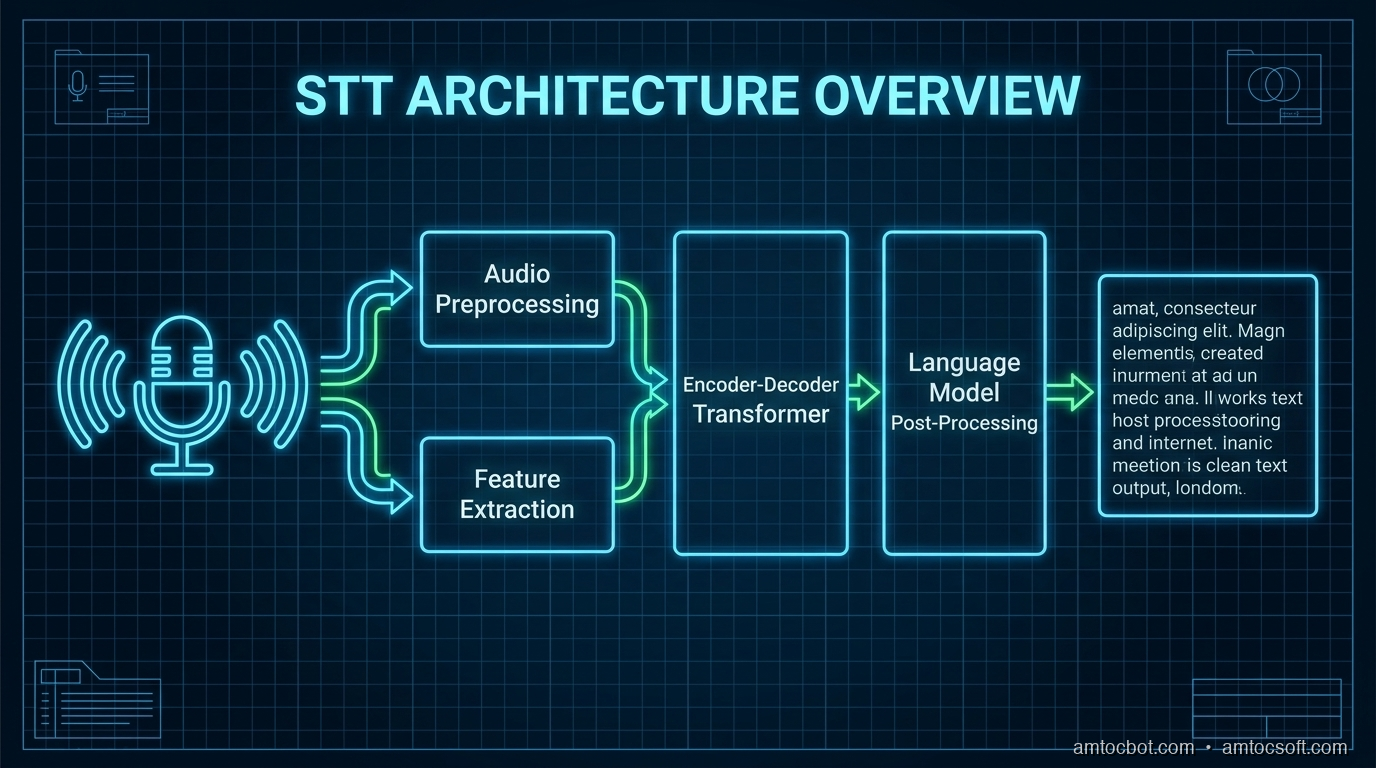
How Modern STT Works
Before diving into comparisons, let's understand the two dominant STT architectures in 2026:
Encoder-Decoder (Whisper, NVIDIA Canary)
Audio is converted to a mel spectrogram, processed by a conformer/transformer encoder, then decoded into text tokens. The model processes audio in chunks (typically 30 seconds for Whisper).
End-to-End Streaming (Deepgram, Google, AssemblyAI)
Audio is processed as a continuous stream. The model outputs interim transcripts as audio arrives and refines them into final transcripts when the speaker pauses.
The key trade-off: encoder-decoder models like Whisper tend to be more accurate (they see the full context before decoding), while streaming models prioritize low latency (they output text as audio arrives). In 2026, hybrid architectures like NVIDIA's SALM are starting to combine both advantages.
OpenAI Whisper
Whisper changed the STT landscape when OpenAI released it as open-source in 2022. By 2026, Whisper Large v3 and its Turbo variant remain among the most accurate transcription models available -- and you can run them on your own hardware for free.
Models Available
| Model | Decoder Layers | VRAM | WER (LibriSpeech Clean) | Speed |
|---|---|---|---|---|
| Large v3 | 32 | ~10 GB | 2.1% | Baseline |
| Large v3 Turbo | 4 | ~6 GB | ~3.1% | 216x real-time |
| GPT-4o Transcribe | - | API only | Improved | API only |
| GPT-4o Mini Transcribe | - | API only | Good | API only |
The Large v3 Turbo is the sweet spot for most use cases: it prunes 28 of 32 decoder layers (keeping only 4), which reduces VRAM from 10 GB to 6 GB and increases speed dramatically, with only about 1% higher WER than the full model.
GPT-4o Transcribe is OpenAI's newest addition -- it uses the GPT-4o architecture for context-aware transcription that better handles ambiguous audio, domain-specific terms, and code-switching between languages.
How Whisper Works
Whisper is an encoder-decoder transformer trained on 680,000 hours of multilingual audio from the web. It processes audio in 30-second chunks, converting mel spectrograms into text tokens. The model handles transcription, translation, language detection, and timestamp generation in a single pass.
Strengths
- Accuracy: Among the best word error rates across languages and conditions (2.1% WER on clean English)
- Open-source: Run it anywhere -- your laptop, your server, an air-gapped facility
- Multilingual: Supports 100+ languages out of the box
- Zero cost: No per-minute API charges when self-hosted
- Robust: Handles background noise, accents, and poor audio quality well
- Ecosystem: faster-whisper, whisper.cpp, insanely-fast-whisper, and dozens of optimization tools
Weaknesses
- Not real-time by default: Designed for batch processing, not streaming
- GPU-hungry: Large v3 needs a beefy GPU for fast inference
- No built-in streaming: Requires additional frameworks (faster-whisper, whisper-streaming) for real-time use
- 30-second chunking: Can cause issues at chunk boundaries (mid-word splits)
- No built-in diarization: Need separate models for speaker identification
Code Example
# Using faster-whisper for optimized inference (4x faster than original)
from faster_whisper import WhisperModel
# Load model -- uses CTranslate2 for massive speedup
model = WhisperModel("large-v3-turbo", device="cuda", compute_type="float16")
# Transcribe a file with VAD filtering
segments, info = model.transcribe(
"audio.wav",
beam_size=5,
language="en",
vad_filter=True, # Skip silence -- reduces processing time
vad_parameters=dict(
min_silence_duration_ms=500
)
)
print(f"Detected language: {info.language} ({info.language_probability:.0%})")
for segment in segments:
print(f"[{segment.start:.2f}s -> {segment.end:.2f}s] {segment.text}")
# Using the OpenAI API (GPT-4o Transcribe -- newest model)
from openai import OpenAI
client = OpenAI(api_key="your-api-key")
with open("audio.wav", "rb") as audio_file:
# GPT-4o Transcribe: context-aware, handles domain jargon better
transcript = client.audio.transcriptions.create(
model="gpt-4o-transcribe",
file=audio_file,
response_format="verbose_json",
timestamp_granularities=["word"]
)
print(transcript.text)
for word in transcript.words:
print(f" {word.word} ({word.start:.2f}s - {word.end:.2f}s)")
Performance Benchmarks
| Configuration | Speed | Notes |
|---|---|---|
| Large v3 Turbo, RTX 4090 | 216x real-time | 60-min file in ~17 seconds |
| Large v3 Turbo, RTX 3080 | ~50x real-time | 60-min file in ~1.2 minutes |
| insanely-fast-whisper + Flash Attention 2, RTX 4090 | 70-100x real-time | 10-min file in <8 seconds |
| Large v3 Turbo, Apple Silicon (CoreML) | ~1.23s for short clips | Encoder on Apple Neural Engine |
| Large v3, CPU (16-core) | ~1-2x real-time | Usable for batch, not real-time |
API Pricing
| Model | Per Minute | Per Hour |
|---|---|---|
| Whisper-1 | $0.006 | $0.36 |
| GPT-4o Transcribe | $0.006 | $0.36 |
| GPT-4o Mini Transcribe | $0.003 | $0.18 |
Deepgram Nova-3
Deepgram built their business on speed. Nova-3 (GA February 2025, multilingual GA April 2025) is designed from the ground up for real-time streaming transcription with minimal latency. If you're building a voice agent that needs instant transcription, Deepgram is the first place to look.
How It Works
Deepgram uses a proprietary end-to-end deep learning architecture optimized for streaming. Unlike Whisper's chunk-based approach, Deepgram processes audio as a continuous stream, outputting interim and final transcripts with minimal delay.
Key Claims (Deepgram's Own Benchmarks)
- 53.4% WER reduction on streaming vs competitors
- 47.4% WER reduction on batch vs competitors
- Up to 36% lower WER than OpenAI Whisper on select datasets
- Up to 40x faster than competing diarization-enabled models
Independent Benchmarks
- 88-92% accuracy on clear English audio
- ~18% WER on mixed real-world datasets (AA-WER benchmarks)
- Sub-300ms transcript delivery for streaming
Strengths
- Streaming-first: Built for real-time, sub-300ms latency on final results
- Speed: Fastest commercial STT for real-time applications
- Smart features: Built-in diarization, topic detection, sentiment, summarization
- Real-time redaction: Automatically redact up to 50 entity types (SSN, credit cards, etc.)
- Word-level timestamps: Precise alignment for subtitle generation
- Custom vocabulary: Boost recognition of domain-specific terms
- Endpointing: Excellent at detecting when a speaker has finished talking
Weaknesses
- Cost at scale: More expensive than self-hosted Whisper
- Proprietary: No self-hosting option, API-only
- English-centric: Best performance in English, other languages lag
- Independent benchmarks differ from claims: Deepgram's own benchmarks show much better results than independent tests
Code Example
import asyncio
from deepgram import DeepgramClient, LiveTranscriptionEvents, LiveOptions
async def transcribe_stream():
deepgram = DeepgramClient(api_key="your-api-key")
# Create a live transcription connection
connection = deepgram.listen.live.v("1")
# Configure options
options = LiveOptions(
model="nova-3",
language="en-US",
smart_format=True, # Punctuation, casing, numbers
interim_results=True, # Get partial results as user speaks
utterance_end_ms=1000, # Detect end of utterance
vad_events=True, # Voice activity detection
endpointing=300, # 300ms silence = end of speech
diarize=True, # Speaker identification
redact=["pci", "ssn"] # Auto-redact sensitive info
)
# Handle transcription events
@connection.on(LiveTranscriptionEvents.Transcript)
def on_transcript(self, result, **kwargs):
transcript = result.channel.alternatives[0]
if transcript.transcript:
prefix = "INTERIM" if not result.is_final else "FINAL"
print(f"[{prefix}] {transcript.transcript}")
@connection.on(LiveTranscriptionEvents.UtteranceEnd)
def on_utterance_end(self, utterance_end, **kwargs):
print("--- Speaker finished ---")
# Start connection
await connection.start(options)
# Stream audio from microphone or file
with open("audio.wav", "rb") as audio:
while chunk := audio.read(4096):
await connection.send(chunk)
await asyncio.sleep(0.01) # Pace the stream
await connection.finish()
asyncio.run(transcribe_stream())
Pricing
| Plan | Streaming | Batch | Notes |
|---|---|---|---|
| Pay-as-you-go | $0.0077/min | $0.0043/min | No commitment |
| Growth | $0.0065/min | ~$0.004/min | Volume discounts |
| Enterprise | Custom | Custom | Dedicated support |
Latency
| Mode | Latency |
|---|---|
| Interim results | 100-200ms |
| Final results | 300-500ms |
| Endpointing | Configurable (100-2000ms) |
Google Cloud Speech-to-Text
Google's Speech-to-Text API now runs on Chirp 3 (GA), their latest universal speech model. It's the enterprise choice with the widest language support and the deepest integration with Google Cloud services.
Chirp 3 Features
- 85+ languages and locales
- Speaker diarization and automatic language detection
- Built-in denoiser for noisy audio
- Real-time streaming transcription
- Speech adaptation for custom vocabularies
- Trained on millions of hours of audio + 28 billion text sentences across 100+ languages
Strengths
- Language support: 85+ languages and variants -- the most extensive coverage
- Enterprise features: Speaker diarization, content filtering, data logging controls, HIPAA compliance
- Medical/Legal models: Specialized models for domain-specific vocabulary
- Global infrastructure: Low-latency endpoints worldwide
- Built-in denoiser: Hardware-level noise reduction
- Dynamic Batch: 75% discount for non-urgent transcription (results within 24 hours)
- Multi-channel: Process stereo audio with per-channel recognition
Weaknesses
- Pricing: Most expensive standard pricing among major providers ($0.016/min standard)
- Complexity: More configuration and boilerplate than competitors
- API verbosity: V2 API is significantly more complex than V1
- Independent accuracy: ~11.6% WER on mixed benchmarks -- behind Whisper and specialized providers
Code Example
from google.cloud import speech_v2 as speech
def transcribe_streaming(audio_file: str, project_id: str):
"""Stream audio to Google Chirp 3 for real-time transcription."""
client = speech.SpeechClient()
# Configure Chirp 3 recognition
config = speech.RecognitionConfig(
auto_decoding_config=speech.AutoDetectDecodingConfig(),
language_codes=["en-US"],
model="chirp_3",
features=speech.RecognitionFeatures(
enable_automatic_punctuation=True,
enable_word_time_offsets=True,
enable_spoken_punctuation=True,
diarization_config=speech.SpeechAdaptation.DiarizationConfig(
min_speaker_count=2,
max_speaker_count=6
)
)
)
recognizer = f"projects/{project_id}/locations/global/recognizers/_"
def stream_generator():
yield speech.StreamingRecognizeRequest(
recognizer=recognizer,
streaming_config=speech.StreamingRecognitionConfig(
config=config,
streaming_features=speech.StreamingRecognitionFeatures(
interim_results=True
)
)
)
# Stream audio in 100ms chunks (Google's recommendation)
with open(audio_file, "rb") as f:
while chunk := f.read(3200): # 100ms at 16kHz, 16-bit
yield speech.StreamingRecognizeRequest(audio=chunk)
responses = client.streaming_recognize(requests=stream_generator())
for response in responses:
for result in response.results:
status = "FINAL" if result.is_final else "INTERIM"
print(f"[{status}] {result.alternatives[0].transcript}")
transcribe_streaming("audio.wav", "your-gcp-project")
Pricing
| Model | Per Minute | Dynamic Batch | Notes |
|---|---|---|---|
| Standard | $0.016 | $0.004 | General purpose |
| Enhanced (phone/video) | $0.036 | - | Optimized for telephony |
| Medical dictation | $0.078 | - | Specialized vocabulary |
AssemblyAI Universal-2
AssemblyAI has quietly become one of the most feature-rich STT providers. Universal-2 supports 99 languages with built-in features that competitors charge extra for -- diarization, sentiment analysis, topic detection, and more.
Key Improvements Over Predecessor
- 24% improvement in rare word recognition (names, brands, locations)
- 15% improvement in transcript structure (punctuation, casing)
- 21% improvement on numerical data (phone numbers, zip codes)
- 64% fewer speaker counting errors
Strengths
- Streaming accuracy: ~14.5% WER on independent streaming benchmarks -- among the best
- 99 languages: Including automatic code-switching (mid-sentence language switching)
- Rich features included: Diarization, sentiment, topics, PII redaction, summarization
- Custom vocabulary: Boost up to 200 key terms for domain-specific recognition
- Pricing: Cheapest base rate at $0.0025/min ($0.15/hour)
Weaknesses
- Add-on costs: Base pricing is cheap, but features stack up (diarization +$0.02/hr, PII redaction +$0.08/hr)
- Smaller brand: Less enterprise recognition than Google or AWS
- API-only: No self-hosting option
Code Example
import assemblyai as aai
aai.settings.api_key = "your-api-key"
# Real-time streaming transcription
transcriber = aai.RealtimeTranscriber(
sample_rate=16000,
word_boost=["AmtocSoft", "Pipecat", "LiveKit"], # Boost domain terms
encoding=aai.AudioEncoding.pcm_s16le,
on_data=lambda transcript: print(
f"[{'FINAL' if transcript.message_type == 'FinalTranscript' else 'PARTIAL'}] "
f"{transcript.text}"
),
on_error=lambda error: print(f"Error: {error}")
)
transcriber.connect()
# Stream audio chunks...
# transcriber.stream(audio_bytes)
transcriber.close()
# Batch transcription with all features
config = aai.TranscriptionConfig(
speech_model=aai.SpeechModel.best,
speaker_labels=True, # Diarization
sentiment_analysis=True, # Per-utterance sentiment
entity_detection=True, # Named entities
auto_chapters=True, # Auto-chapter generation
summarization=True, # Meeting summary
language_detection=True # Auto-detect language
)
transcript = aai.Transcriber().transcribe("audio.wav", config)
for utterance in transcript.utterances:
print(f"Speaker {utterance.speaker}: {utterance.text}")
if transcript.summary:
print(f"\nSummary: {transcript.summary}")
Pricing
| Feature | Cost |
|---|---|
| Base transcription | $0.15/hr ($0.0025/min) |
| Speaker diarization | +$0.02/hr |
| Sentiment analysis | +$0.02/hr |
| PII redaction | +$0.08/hr |
| Summarization | +$0.03/hr |
| All features combined | ~$0.30/hr |
NVIDIA Canary-Qwen-2.5B (The New #1)
NVIDIA's Canary model hit #1 on the Hugging Face Open ASR Leaderboard in July 2025 and has held the position since. It represents a new breed of STT: a hybrid ASR-LLM architecture that combines a FastConformer encoder with a Qwen3-1.7B language model decoder.
Architecture: SALM (Speech-Augmented Language Model)
- Encoder: FastConformer (audio processing)
- Decoder: Qwen3-1.7B LLM with LoRA adapters
- Total parameters: 2.5B
- Training data: 234,000 hours of public speech data
- License: CC-BY-4.0 (open-source)
Key Stats
- 418x real-time factor -- extremely fast inference
- Average WER: 5.63% across all benchmarks
- LibriSpeech Clean: 1.6% WER (best-in-class)
- LibriSpeech Other: 3.1% WER
Why It Matters
Canary proves that combining ASR with LLM reasoning produces fundamentally better transcription. The LLM decoder can use linguistic context to resolve ambiguous audio -- "their" vs "there" vs "they're" becomes trivial when the model understands grammar.
Other Notable NVIDIA Models
- Canary-1b-v2: 25 languages, comparable to models 3x larger, up to 10x faster
- Parakeet-tdt-0.6b-v3: Transcribes 24-minute audio in a single inference pass
Accuracy Comparison: Word Error Rate
Word Error Rate (WER) is the standard metric for STT accuracy. Lower is better. But there's a critical caveat: academic benchmarks and production performance are very different things.
Academic Benchmarks (Clean Audio)
| Model | LibriSpeech Clean | LibriSpeech Other |
|---|---|---|
| NVIDIA Canary-Qwen-2.5B | 1.6% | 3.1% |
| Whisper Large v3 | 2.1% | ~4.5% |
| Whisper Large v3 Turbo | ~3.1% | ~5.5% |
| Soniox | ~2.5% | ~5.0% |
Independent Real-World Benchmarks (Mixed Audio)
| Model | WER (mixed real-world) | Notes |
|---|---|---|
| Soniox | ~6.5% | English-focused |
| Speechmatics | ~9.3% | Enterprise |
| Google Chirp 3 (batch) | ~11.6% | Broad language support |
| AssemblyAI Universal-2 (streaming) | ~14.5% | Best streaming accuracy |
| Deepgram Nova-3 (mixed) | ~18% | Optimized for speed |
The Academic-Production Gap
Critical caveat: Academic benchmarks (LibriSpeech) show 95%+ accuracy. But production performance with background noise, overlapping speakers, accents, and domain jargon often drops to 70-85%. A model with 2% WER on LibriSpeech might have 15-20% WER on your actual call center audio.
Always benchmark on your own data before choosing a provider.
All models perform well] B -->|No| D{Phone/Compressed?} D -->|Yes| E[WER 6-12%
Deepgram excels here] D -->|No| F{Noisy Environment?} F -->|Yes| G[WER 10-20%
Pre-process with denoiser] F -->|No| H{Heavy Accent?} H -->|Yes| I[WER 8-15%
Whisper best for accents] H -->|No| J{Multi-language?} J -->|Yes| K[WER 10-20%
Google Chirp or Whisper] J -->|No| L[WER 5-10%
Standard use case] style A fill:#9C27B0,color:#fff style C fill:#4CAF50,color:#fff style E fill:#2196F3,color:#fff style G fill:#FF9800,color:#fff style I fill:#FF9800,color:#fff style K fill:#FF9800,color:#fff style L fill:#4CAF50,color:#fff
Streaming vs Batch: Why It Matters
The biggest architectural decision in STT is whether you need real-time streaming or batch processing. This choice affects accuracy, cost, and infrastructure.
Batch Processing
Process a complete audio file after recording. Best for:
- Transcribing meetings after they end
- Processing podcast episodes and generating subtitles
- Analyzing call center recordings
- Generating training data for fine-tuning
All solutions handle batch well. Self-hosted Whisper is the cost winner. Google Dynamic Batch offers 75% discounts for non-urgent jobs.
Real-Time Streaming
Process audio as it arrives, generating text with minimal delay. Required for:
- Voice agents and chatbots (the 300ms rule)
- Live captioning and accessibility
- Real-time translation
- Voice-controlled interfaces
For streaming, the ranking: Deepgram > AssemblyAI > Google > Whisper. Deepgram was purpose-built for streaming. AssemblyAI has the best streaming accuracy. Google has solid enterprise streaming. Whisper requires additional tooling and still can't match native streaming latency.
The 300ms Rule
Human conversation has a natural pause of about 300ms between turns. When voice AI response time exceeds this threshold, it triggers neurological stress in users -- the conversation feels "off." Industry median reality is 1.4-1.7 seconds, which is 5x slower than the human expectation. Getting STT latency down is critical because it's the first link in the chain.
Handling the Hard Cases
Background Noise
- Pre-process audio with noise reduction (RNNoise, Demucs, Google's built-in denoiser)
- Use Voice Activity Detection (VAD) to skip silence and noise-only segments
- Chirp 3's built-in denoiser handles this automatically
Domain-Specific Vocabulary
# Deepgram: Boost specific keywords
options = LiveOptions(
model="nova-3",
keywords=["AmtocSoft:2", "Pipecat:2", "LiveKit:1.5", "WebRTC:2"]
# Numbers are boost weights (higher = stronger bias)
)
# AssemblyAI: Word boost (up to 200 terms)
config = aai.TranscriptionConfig(
word_boost=["AmtocSoft", "Pipecat", "LiveKit", "WebRTC"],
boost_param=aai.WordBoost.high
)
# Google: Speech adaptation phrases
config = speech.RecognitionConfig(
adaptation=speech.SpeechAdaptation(
phrase_sets=[
speech.SpeechAdaptation.AdaptationPhraseSet(
inline_phrase_set=speech.PhraseSet(
phrases=[
speech.PhraseSet.Phrase(value="AmtocSoft", boost=10),
speech.PhraseSet.Phrase(value="Pipecat", boost=10),
]
)
)
]
)
)
Code-Switching (Multilingual Speakers)
When speakers switch between languages mid-sentence:
- AssemblyAI Universal-2: Built-in code-switching detection across 99 languages
- Whisper: Handles this well due to multilingual training on 680K hours
- Google Chirp 3: Automatic language detection, but less reliable on mid-sentence switches
- Deepgram: Requires specifying a single primary language
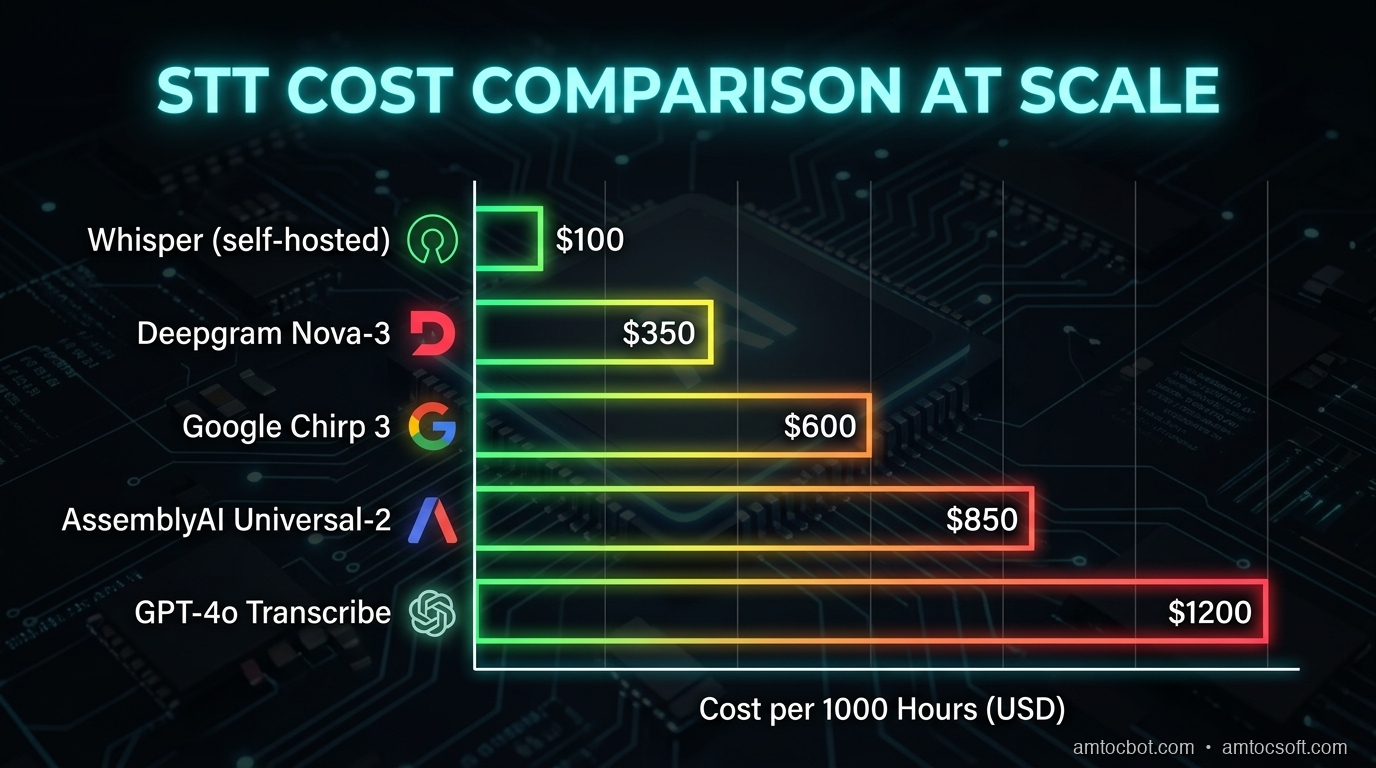
Cost Analysis at Scale
Let's model costs for realistic workloads:
Per-Minute Pricing Comparison
| Provider | Per Minute | Per Hour | 10K Hours/Month |
|---|---|---|---|
| AssemblyAI (base) | $0.0025 | $0.15 | $1,500 |
| GPT-4o Mini Transcribe | $0.003 | $0.18 | $1,800 |
| Google Dynamic Batch | $0.004 | $0.24 | $2,400 |
| Deepgram (batch) | $0.0043 | $0.26 | $2,580 |
| OpenAI Whisper-1 / GPT-4o Transcribe | $0.006 | $0.36 | $3,600 |
| Deepgram (streaming, Growth) | $0.0065 | $0.39 | $3,900 |
| Deepgram (streaming, PAYG) | $0.0077 | $0.46 | $4,620 |
| Google (standard) | $0.016 | $0.96 | $9,600 |
| Google (enhanced) | $0.036 | $2.16 | $21,600 |
Self-Hosted Whisper
For batch processing at massive scale, self-hosting Whisper is unbeatable:
- Salad Cloud benchmark: $5,110 for 1 million hours of transcription using distributed GPU compute
- Single RTX 4090 server: ~$150-300/month handles ~30,000 hours/month at 216x real-time
- Break-even point: Self-hosting beats API pricing above ~5,000 hours/month
Hidden Costs to Watch
- AssemblyAI add-ons: Base is cheap ($0.15/hr), but diarization + PII redaction + sentiment = $0.30/hr
- Google enhanced models: 2.25x the standard price
- Concurrency limits: Free/lower tiers cap concurrent streams -- production workloads need plan upgrades
- Deepgram streaming vs batch: Streaming costs nearly 2x batch pricing
The STT Decision Flow
Sub-300ms streaming] Q2 -->|Accuracy| ASSEMBLY[AssemblyAI Universal-2
Best streaming WER] Q1 -->|No - Batch| Q3{Budget priority?} Q3 -->|Minimum cost| Q4{Have GPU infrastructure?} Q4 -->|Yes| WHISPER[Self-hosted Whisper
$5K per 1M hours] Q4 -->|No| ASSEMBLY2[AssemblyAI
$0.0025/min base] Q3 -->|Best accuracy| CANARY[NVIDIA Canary
#1 on Open ASR] Q3 -->|Enterprise compliance| GOOGLE[Google Chirp 3
85+ languages, HIPAA] START --> Q5{Multilingual?} Q5 -->|99 languages| ASSEMBLY3[AssemblyAI Universal-2] Q5 -->|100+ languages| WHISPER2[Whisper Large v3] Q5 -->|85+ with enterprise| GOOGLE2[Google Chirp 3] style START fill:#9C27B0,color:#fff style DEEPGRAM fill:#4CAF50,color:#fff style ASSEMBLY fill:#4CAF50,color:#fff style WHISPER fill:#4CAF50,color:#fff style ASSEMBLY2 fill:#4CAF50,color:#fff style CANARY fill:#4CAF50,color:#fff style GOOGLE fill:#4CAF50,color:#fff style ASSEMBLY3 fill:#2196F3,color:#fff style WHISPER2 fill:#2196F3,color:#fff style GOOGLE2 fill:#2196F3,color:#fff
Recommendation Summary
| Use Case | Recommended | Why |
|---|---|---|
| Voice agent (real-time) | Deepgram Nova-3 | Lowest streaming latency, built for real-time |
| Voice agent (accuracy-first) | AssemblyAI Universal-2 | Best streaming WER at $0.0025/min |
| Meeting transcription (batch) | Whisper (self-hosted) | Zero API costs, excellent accuracy |
| Maximum accuracy (batch) | NVIDIA Canary (self-hosted) | #1 on Open ASR leaderboard |
| Multilingual (100+ languages) | Whisper Large v3 | Best multilingual coverage |
| Enterprise / compliance | Google Chirp 3 | HIPAA, global infrastructure, 85+ languages |
| Budget-constrained API | GPT-4o Mini Transcribe | $0.003/min, good quality |
| Offline / air-gapped | Whisper (self-hosted) | Fully self-contained |
The best approach for most voice AI projects: use Deepgram or AssemblyAI for real-time streaming (voice agents, live captioning) and self-hosted Whisper or NVIDIA Canary for batch processing (transcription, subtitles, analysis). This gives you the best of both worlds -- speed where it counts, cost savings where it doesn't.
Sources & References:
1. OpenAI — "Whisper" — https://openai.com/index/whisper/
2. Deepgram — "Nova-3 Speech-to-Text" — https://deepgram.com/
3. Hugging Face — "Open ASR Leaderboard" — https://huggingface.co/spaces/open-asr-leaderboard/open_asr_leaderboard
This is part 3 of the AmtocSoft Voice AI series. Next: build your first voice agent with Python and Pipecat.
About the Author
Toc Am
Founder of AmtocSoft. Writing practical deep-dives on AI engineering, cloud architecture, and developer tooling. Previously built backend systems at scale. Reviews every post published under this byline.
Published: 2026-04-06 · Written with AI assistance, reviewed by Toc Am.
Get These In Your Inbox
Weekly deep-dives on AI engineering, no fluff. Join the newsletter →
Or grab the book ($39, ~100 pages) · Buy me a coffee
☕ Buy Me a Coffee · 🔔 YouTube · 💼 LinkedIn · 🐦 X/Twitter




No comments:
Post a Comment