Level: Advanced
Topic: Voice AI, TTS, STT
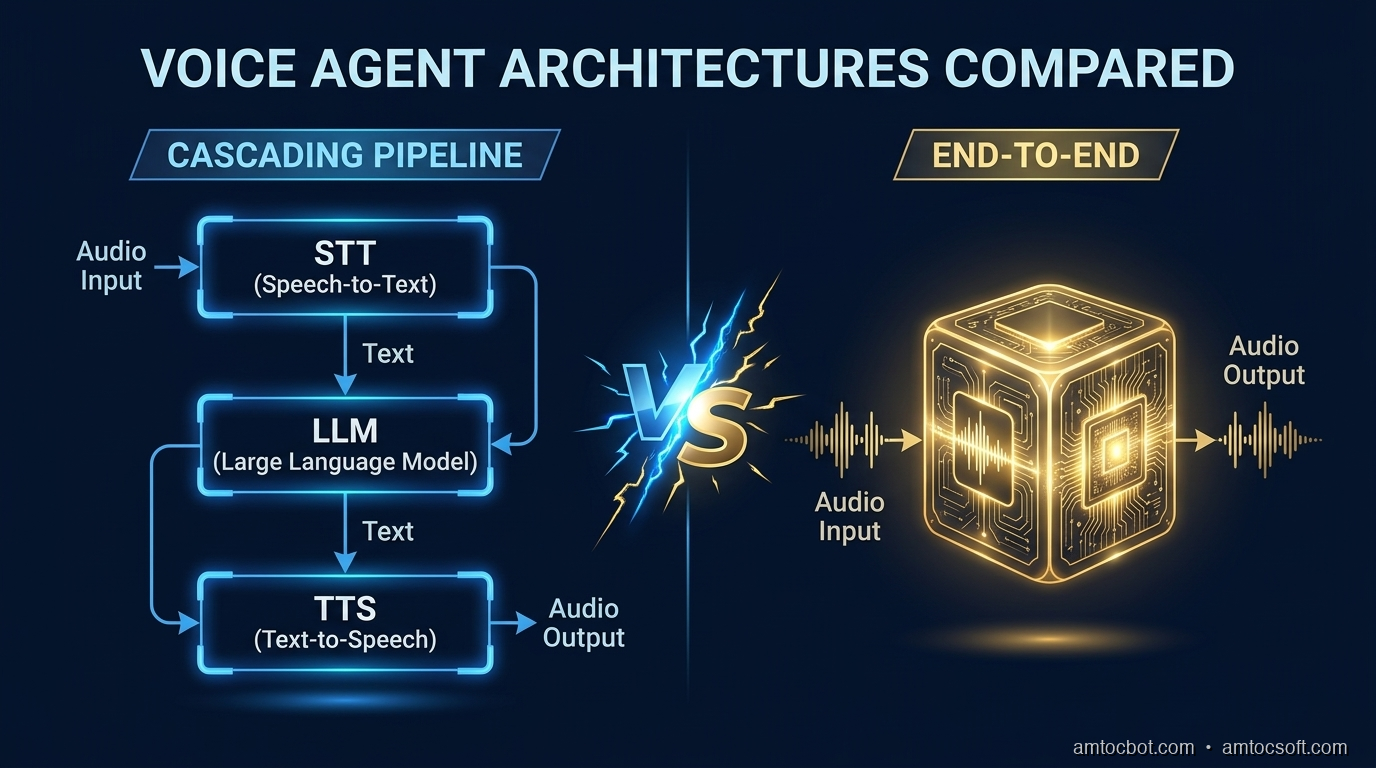
If you've built a voice agent using the pipeline approach from our previous tutorial -- STT into LLM into TTS -- you've already seen it work. But you've probably also noticed the latency. Every stage adds time, and the stages are sequential. The industry median for voice agent response time is 1.4-1.7 seconds -- five times slower than the 300ms natural pause in human conversation.
Is there a better way?
In 2026, three competing architectural paradigms are battling for dominance: the cascading pipeline (what we built), the end-to-end speech-to-speech model (what OpenAI and Google are pushing), and the managed platform (what Retell, VAPI, and Bland are selling). Each has profound trade-offs in latency, flexibility, cost, and capability.
This post goes deep on all three, compares the major platforms with real pricing and performance data, and helps you choose the right architecture for your use case.
Architecture 1: The Cascading Pipeline
The pipeline approach chains three independent models together:
Whisper
Google Chirp] -.-> B C1[GPT-4o
Claude Sonnet
Llama 3.3] -.-> C D1[ElevenLabs
OpenAI TTS
Cartesia
Kokoro] -.-> D style A fill:#4CAF50,color:#fff style E fill:#2196F3,color:#fff style B fill:#FF9800,color:#fff style C fill:#FF9800,color:#fff style D fill:#FF9800,color:#fff
How It Works
- Raw audio from the microphone flows into the STT engine
- STT produces a text transcription
- The text goes to an LLM as a user message
- The LLM generates a text response (with optional function calling)
- The text response goes to a TTS engine
- TTS produces audio that plays through the speaker
Each component is independent, replaceable, and debuggable.
Latency Breakdown (Production Reality)
Every stage adds latency. Here's a realistic breakdown based on production systems:
User finishes speaking
|
+-- VAD end-of-speech detect: 50ms (P50) / 100ms (P99)
|
+-- STT finalization: 100ms (P50) / 250ms (P99)
|
+-- Network to LLM: 10ms (P50) / 30ms (P99)
|
+-- LLM time-to-first-token: 150ms (P50) / 400ms (P99)
| (accounts for 70% of total latency)
|
+-- Network to TTS: 10ms (P50) / 30ms (P99)
|
+-- TTS time-to-first-byte: 100ms (P50) / 250ms (P99)
|
+-- Audio buffer + playback: 50ms (P50) / 100ms (P99)
|
= Total: 470ms (P50) / 1160ms (P99)
The LLM is the bottleneck. It accounts for roughly 70% of total latency. This is why swapping GPT-4o-mini for GPT-4o can shave 100-200ms off every response.
Streaming Optimization
The key to making pipelines fast is streaming overlap -- don't wait for one stage to finish before starting the next:
- Start LLM inference as soon as STT produces a final transcript
- Start TTS as soon as the LLM produces the first sentence (not the full response)
- Start audio playback as soon as TTS produces the first audio chunk
- Keep persistent API connections to eliminate handshake latency
With full streaming optimization, a pipeline can hit 400-600ms P50 consistently -- acceptable for most conversational use cases.
Advantages
- Flexibility: Swap any component independently. Don't like ElevenLabs? Switch to Kokoro. Want Claude instead of GPT-4o? Change one line of code.
- Debuggability: Inspect text between stages. Log every transcript, every LLM response, every TTS input. When something goes wrong, you know exactly which stage failed.
- Best-of-breed: Use the best STT (Deepgram for streaming), the best LLM (GPT-4o for reasoning), and the best TTS (ElevenLabs for quality) -- they don't have to come from the same vendor.
- Text-based tools: The LLM operates on text, so all existing function-calling, RAG, and prompt engineering techniques work without modification.
- Cost control: Price each component independently. Use a cheap LLM for simple queries, expensive one for complex ones.
Disadvantages
- Cumulative latency: Three serial stages = three sets of latency stacked
- Lost audio information: STT converts speech to text, losing tone, emotion, hesitation, emphasis. The LLM never hears how you said something.
- Error propagation: STT mistakes cascade. "I need to book a flight" transcribed as "I need to cook a flight" gives the LLM garbage input.
- Turn-taking complexity: Detecting when the user has finished speaking requires separate VAD tuning.
Open-Source Pipeline Frameworks
Pipecat (~1,872 GitHub stars):
- Created by Daily.co, Python-only
- 60+ provider integrations (the most of any framework)
- Client SDKs: JavaScript, React, React Native, iOS, Android, C++
- Pipecat Cloud for managed hosting
- Best for: Teams wanting maximum provider flexibility
LiveKit Agents (~9,900 GitHub stars):
- Open-source WebRTC platform + agent framework
- Python and Node.js SDKs
- Semantic turn detection (transformer-based, more sophisticated than VAD alone)
- Multi-agent handoff, MCP support
- Agent Builder for no-code prototyping
- Best for: Teams already using LiveKit, or wanting WebRTC infrastructure
Vocode (open-source, community-maintained):
- Python library + enterprise API
- Looking for community maintainers (signal of reduced commercial investment)
- Zoom integration
- Best for: Simple use cases, Zoom-focused deployments
Architecture 2: End-to-End Speech-to-Speech Models
End-to-end models process audio directly -- no separate STT/TTS stages. The model receives audio waveforms as input and produces audio waveforms as output.
Understands speech natively
Reasons about content + tone] C --> D[Audio Decoder] D --> E[Audio Out] F[Paralinguistic Features
Tone, emotion, hesitation
emphasis, sarcasm] -.->|Preserved| C G[Tool Calling
Function execution
Data retrieval] -.->|Supported| C style A fill:#4CAF50,color:#fff style E fill:#2196F3,color:#fff style C fill:#9C27B0,color:#fff
How It Works
Instead of converting audio to text and back, an end-to-end model:
- Encodes the input audio into a latent representation
- Processes that representation through a language model that understands audio natively
- Generates an output audio representation
- Decodes it back to a waveform
The model never creates an intermediate text representation (or if it does, it's internal and includes audio features like tone and emotion alongside the text).
Examples in 2026
OpenAI Realtime API (GPT-4o Voice):
- Natively multimodal -- processes audio input directly
- Supports streaming audio I/O, automatic interruption handling, VAD, function calling while speaking
- Pricing: ~$0.30/minute for a two-way conversation ($32/1M audio input tokens, $64/1M audio output tokens)
- 2025 improvements: ~35% lower WER on Common Voice and FLEURS benchmarks
- gpt-realtime-mini: Cheaper variant with +18.6pp instruction-following accuracy improvement
Google Gemini 2.5 Flash Native Audio (Live API):
- Single model processes audio, text, and visual modalities natively
- Low-latency bidirectional streaming
- Understands acoustic cues (pitch, pace, emotion), processes interruptions mid-sentence
- Can see and discuss visual data (charts, live video, diagrams) simultaneously
- Available on Google Cloud Vertex AI
Moshi by Kyutai (Open Source):
- First real-time full-duplex spoken LLM -- both parties can talk simultaneously
- 160ms theoretical latency, 200ms practical
- Uses Mimi: streaming neural audio codec
- English only (multilingual checkpoint targeted Q1 2026)
- License: CC-BY 4.0
- Related: Kyutai Pocket TTS (100M params, runs on CPU in real-time)
Ultravox by Fixie.ai:
- Multimodal projector converts audio directly into LLM's high-dimensional space
- Default model: GLM 4.6 (replaced Llama 3.3 70B in Dec 2025) -- superior instruction following and tool calling
- 42 languages (expanded from 15), 60% improvement in transcription accuracy
- Current: Audio in, streaming text out (audio output planned for future)
Latency Profile
User finishes speaking
|
+-- Audio encoding: 30ms (P50) / 50ms (P99)
|
+-- Model inference: 250ms (P50) / 500ms (P99)
| (single pass: understand + reason + generate speech)
|
+-- Audio decoding: 30ms (P50) / 50ms (P99)
|
+-- Network round trip: 50ms (P50) / 100ms (P99)
|
+-- Audio buffer + playback: 50ms (P50) / 100ms (P99)
|
= Total: 410ms (P50) / 800ms (P99)
Advantages
- Lower latency: One model, one inference pass -- eliminates serial pipeline overhead
- Preserved audio features: The model hears how you say things -- sarcasm, urgency, confusion, excitement. It can respond with appropriate vocal emotion.
- Natural turn-taking: Handles conversational dynamics natively. Moshi even supports full-duplex (simultaneous speech).
- Simpler architecture: One model to deploy and monitor instead of three separate services.
Disadvantages
- Black box: Can't inspect what the model "heard" or "decided to say" in text form. Debugging is harder.
- Cost: OpenAI Realtime API is ~$0.30/minute -- significantly more than an optimized pipeline (~$0.05-0.15/minute).
- Limited tool calling: Improving rapidly, but still less mature than text-based function calling.
- Vendor lock-in: Can't swap the "STT part" of GPT-4o Voice Mode.
- Fewer options: Much smaller market than individual STT/LLM/TTS components.
- Hallucinated audio: Can generate artifacts, nonsense sounds, or inconsistent voices.
- GPT-4o Voice limitations: No custom GPT actions, no image generation/file uploads, safety mechanisms block speaker identification.
Architecture 3: Managed Platforms (Build vs Buy)
Managed platforms abstract away the infrastructure entirely. You configure your agent through a dashboard or API, and the platform handles STT, LLM routing, TTS, telephony, and scaling.
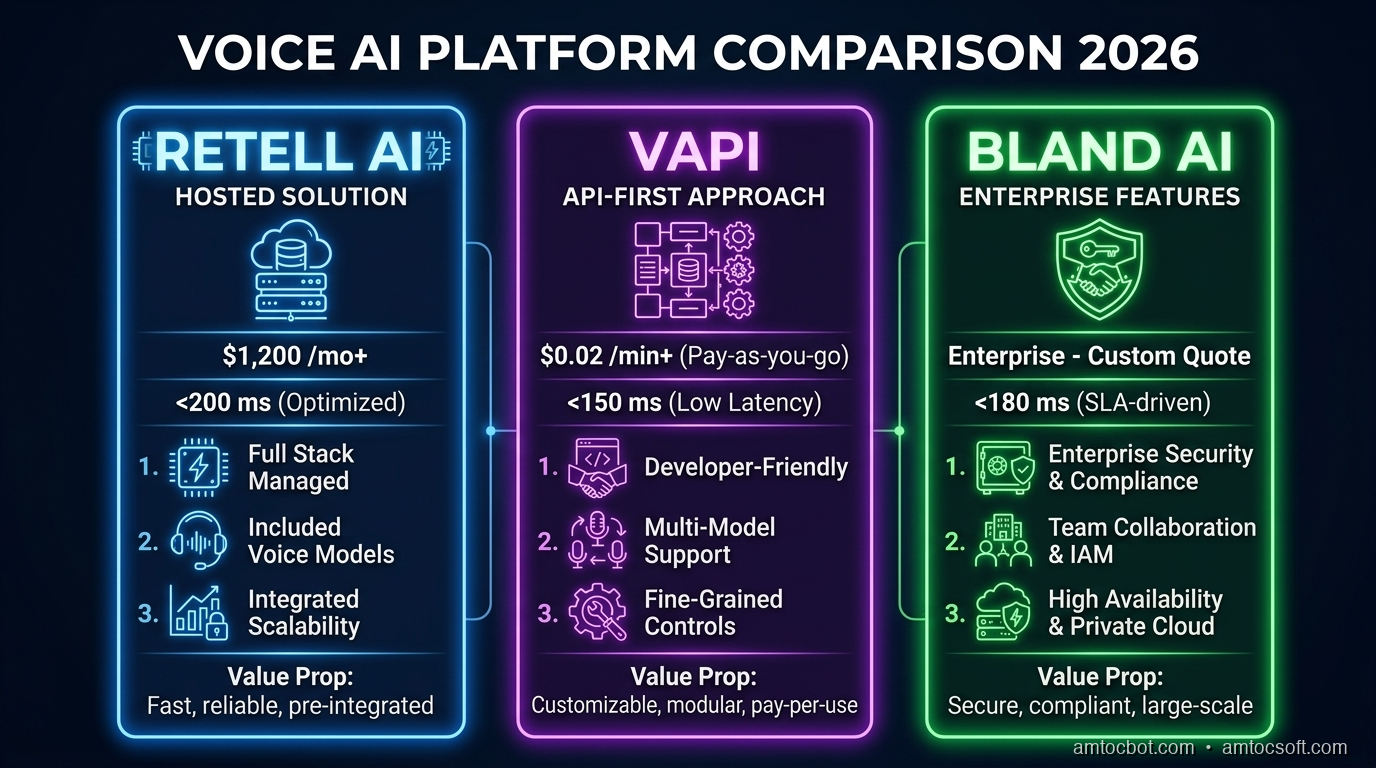
Retell AI
Architecture: Managed pipeline (abstracted)
Hosting: Fully managed (Retell's infrastructure)
STT: Retell's optimized engine
LLM: OpenAI, Anthropic, custom LLM via API
TTS: ElevenLabs, OpenAI, Play.ht, Retell's voices
Transport: WebSocket, Twilio, Vonage
Telephony: Built-in phone number provisioning
Pricing: Pay-as-you-go, no platform fees
- Typical cost: $0.13-$0.31/minute (depends on voice model + LLM)
- Enterprise: Volume discounts down to ~$0.05/minute
- Free tier: $10 credits (~60 minutes), 20 concurrent calls
Best for: Teams shipping fast without managing infrastructure. Great for call centers and telephony.
VAPI
Architecture: Managed pipeline
Hosting: Fully managed
STT: Deepgram, Talkscriber
LLM: OpenAI, Anthropic, Groq, custom
TTS: ElevenLabs, OpenAI, PlayHT, Cartesia
Transport: WebSocket, SIP/PSTN
Telephony: Built-in
Pricing: $0.05/minute platform fee + provider costs
- Real deployment cost: $0.15-$0.50+/minute
- Monthly plans start at $500/month
- HIPAA add-on: $1,000/month flat
- SIP lines: $10/line/month
Pain points: Production requires contracts with 4-6 providers. Charged for silence/hold time. Sub-600ms response time claimed but variable.
Best for: API-first developers who want managed voice agents with good documentation.
Bland AI
Architecture: Fully managed (all-inclusive)
Hosting: Fully managed
Scale: Up to 1M concurrent calls
Customers: 250+ enterprise
Calls made: 60M+ AI phone calls
Pricing: $0.09/connected minute (billed by the second), $0.015 minimum per outbound attempt
- All-inclusive -- no separate API keys needed
- Enterprise volume pricing available
New product (March 2026): "Norm" -- AI assistant that builds production-ready voice agents from a single prompt.
Best for: High-volume telephony. The simplest pricing model (flat per-minute, everything included).
Platform Comparison
| Retell | VAPI | Bland | Pipecat | LiveKit | |
|---|---|---|---|---|---|
| Type | Managed | Managed | Managed | Open-source | Open-source |
| Pricing | $0.13-0.31/min | $0.15-0.50/min | $0.09/min | Free + API costs | $0.01/min sessions |
| Telephony | Built-in | Built-in | Built-in | Via Daily/Twilio | Via Twilio |
| Self-host | No | No | No | Yes | Yes |
| Max concurrency | 20 (free) | Limited | 1M | Unlimited | Unlimited |
| Custom LLM | Yes (via API) | Yes | Via pathways | Yes (60+ providers) | Yes |
| Tool calling | Yes | Yes | Pathways | Yes | Yes |
Hybrid Architectures (The Emerging Pattern)
In practice, the most sophisticated production systems don't pick one architecture exclusively. They combine elements from each.
Audio-Aware Pipeline
Preserve the pipeline's debuggability while recovering paralinguistic information:
Audio In
|
v
+-------------------+
| STT + Features | Transcribes AND extracts audio features
| Audio -> Text | (emotion, speaker ID, language, intent)
| + Metadata |
+-------------------+
|
v
+-------------------+
| LLM | Receives text + audio metadata
| Text -> Text | "User said X with frustrated tone"
+-------------------+
|
v
+-------------------+
| Expressive TTS | Generates speech with appropriate emotion
| Text -> Audio | based on LLM's emotional direction
+-------------------+
|
v
Audio Out
Parallel Transcription + Understanding
Feed audio to both traditional STT (for tools and logging) and an audio encoder (for richer understanding):
Audio In ----+
|
+---> [STT] -> Text transcript (for logging, tools, compliance)
|
+---> [Audio Encoder] -> Audio embeddings (for emotional understanding)
|
v
[Multimodal LLM] -- gets both text and audio features
|
v
[TTS] -> Audio Out
Adaptive Routing
Route conversations to different architectures based on complexity:
class AdaptiveRouter:
"""Route to optimal architecture based on conversation context."""
def route(self, user_input: str, conversation_state: dict) -> str:
# Simple queries -> fast pipeline (GPT-4o-mini + tts-1)
if conversation_state["turn_count"] < 3 and len(user_input) < 50:
return "fast_pipeline"
# Complex queries needing tools -> full pipeline (GPT-4o + tools)
if conversation_state["needs_tools"]:
return "tool_pipeline"
# Emotional/sensitive conversations -> end-to-end (GPT-4o Realtime)
if conversation_state["detected_emotion"] in ["frustrated", "upset"]:
return "end_to_end"
return "standard_pipeline"
GPT-4o-mini + tts-1
Cost: $0.03/min
Latency: 300ms] B -->|Needs Tools| D[Full Pipeline
GPT-4o + Function Calling
Cost: $0.08/min
Latency: 500ms] B -->|Emotional/Complex| E[End-to-End
GPT-4o Realtime
Cost: $0.30/min
Latency: 400ms] B -->|High Volume Call Center| F[Managed Platform
Bland AI / Retell
Cost: $0.09-0.15/min
Latency: 500-800ms] C --> G[Audio Out] D --> G E --> G F --> G style A fill:#9C27B0,color:#fff style C fill:#4CAF50,color:#fff style D fill:#2196F3,color:#fff style E fill:#FF9800,color:#fff style F fill:#f44336,color:#fff
Cost Comparison at Scale
Per-Minute Costs by Architecture
| Architecture | Cost/Min | 10K Min/Month | Notes |
|---|---|---|---|
| Budget Pipeline (Deepgram + GPT-4o-mini + OpenAI TTS) | ~$0.05 | $500 | Good quality, fastest |
| Standard Pipeline (Deepgram + GPT-4o + ElevenLabs) | ~$0.25 | $2,500 | Best quality pipeline |
| OpenAI Realtime API | ~$0.30 | $3,000 | End-to-end, simplest |
| Bland AI (managed) | $0.09 | $900 | All-inclusive, telephony |
| Retell AI (managed) | $0.13-0.31 | $1,300-3,100 | Flexible, pay-as-you-go |
| VAPI (managed) | $0.15-0.50 | $1,500-5,000 | $0.05 platform fee + providers |
| Self-hosted (Whisper + Llama + Kokoro) | ~$0.01-0.02 | $100-200 | Requires GPU infrastructure |
The Self-Hosting Break-Even
Self-hosting a complete voice agent stack (faster-whisper + Llama 70B quantized + Kokoro TTS) costs roughly $10,000/month in GPU infrastructure. This handles approximately 500,000 minutes of conversation -- $0.02/minute.
Break-even vs. managed platforms:
- vs. Bland AI ($0.09/min): Break-even at ~143,000 minutes/month
- vs. Retell ($0.15/min): Break-even at ~77,000 minutes/month
- vs. OpenAI Realtime ($0.30/min): Break-even at ~36,000 minutes/month
Below these volumes, use managed services. Above them, self-hosting saves 5-15x.
Decision Framework
Choose the Pipeline Architecture When:
- You need maximum flexibility to swap components
- Debugging and observability are critical (regulated industries, healthcare, finance)
- You need text-based tool calling with existing function-calling infrastructure
- Cost optimization matters -- choose cheaper components for non-critical paths
- You need to run on-premise or in specific cloud regions for data residency
Choose End-to-End (Realtime API / Gemini Live) When:
- Latency is your top priority and you need consistent sub-500ms responses
- The agent needs to understand tone, emotion, and vocal nuance
- You want natural turn-taking without complex VAD configuration
- The use case is primarily conversational without heavy tool calling
- You're willing to pay a premium for simplicity and performance
Choose a Managed Platform (Retell, VAPI, Bland) When:
- You need to ship in days, not weeks
- Your use case is telephony-focused (call centers, appointment booking, outbound sales)
- Your team doesn't have real-time systems expertise
- You want built-in analytics, call recording, and compliance features
- Per-minute pricing works for your volume (<100K minutes/month)
Choose Self-Hosted (Pipecat, LiveKit) When:
- You need full control over the pipeline and data
- Data privacy requirements prohibit external APIs (HIPAA, GDPR, air-gapped)
- You have engineering capacity to maintain real-time infrastructure
- Your volume exceeds 100K minutes/month where self-hosting saves significantly
- You need custom processors in the pipeline (sentiment analysis, content filtering, etc.)
Where Things Are Headed
Convergence Is Coming
The three architectures are merging:
Pipeline systems are getting smarter:
- Audio feature extraction added to STT outputs (emotion metadata alongside text)
- Adaptive routing -- fast/cheap components for simple queries, powerful components for complex ones
- LiveKit's semantic turn detection uses transformers instead of simple VAD
End-to-end models are getting more capable:
- Ultravox v0.6 supports 42 languages with 60% better accuracy
- GPT-4o Realtime mini improved tool-calling accuracy by 12.9 percentage points
- Moshi demonstrates full-duplex conversation is possible in open-source
Managed platforms are opening up:
- Retell lets you bring your own LLM and telephony provider
- Bland's "Norm" product generates complete voice agents from a single prompt
- VAPI supports custom models and multi-agent squads
The Likely Future
The most sophisticated voice agents will use end-to-end models for the conversational core (understanding and generating speech) with pipeline components plugged in around the edges (tool calling, data retrieval, compliance logging).
For now, the pipeline architecture remains the most practical choice for production systems. It's proven, flexible, and debuggable. But keep an eye on end-to-end models -- the OpenAI Realtime API price has already dropped, and quality improves with every model update.
Compliance Is Getting Serious
The EU AI Act transparency obligations are fully enforced starting August 2, 2026. Voice agents must clearly inform users they're talking to AI. BIPA enforcement is expanding (Fireflies.AI was hit with a class action in December 2025 for biometric data violations with their AI meeting assistant). Any production voice agent needs a compliance strategy from day one -- and the penalties are significant: $1,000-$5,000 per violation under BIPA, up to 4% of global turnover under GDPR.
Open Source Is Winning the Infrastructure Layer
The infrastructure layer for voice agents is overwhelmingly open-source. Pipecat (60+ integrations), LiveKit (9,900+ GitHub stars), Whisper, Kokoro, and Moshi are all open-source and production-ready. The managed platforms (Retell, VAPI, Bland) build on top of these open-source components. This means the cost floor for voice AI infrastructure will continue to drop, and the competitive moats will shift from technology to execution -- who can build the best user experience on top of the shared infrastructure.
Sources & References:
1. Kyutai — "Moshi: Full-Duplex Voice AI" — https://github.com/kyutai-labs/moshi
2. Fixie AI — "Ultravox: Multimodal Voice Model" — https://github.com/fixie-ai/ultravox
3. Pipecat — "Pipeline Architecture" — https://github.com/pipecat-ai/pipecat
This is part 5 of the AmtocSoft Voice AI series. Next: taking your voice agent to production with scaling, monitoring, and cost optimization.
About the Author
Toc Am
Founder of AmtocSoft. Writing practical deep-dives on AI engineering, cloud architecture, and developer tooling. Previously built backend systems at scale. Reviews every post published under this byline.
Published: 2026-04-06 · Written with AI assistance, reviewed by Toc Am.
Get These In Your Inbox
Weekly deep-dives on AI engineering, no fluff. Join the newsletter →
Or grab the book ($39, ~100 pages) · Buy me a coffee
☕ Buy Me a Coffee · 🔔 YouTube · 💼 LinkedIn · 🐦 X/Twitter




No comments:
Post a Comment