
The first digital twin I worked on was a rooftop HVAC system for a mid-size office building. The pitch was straightforward: a live model of the chiller loop, fed by sensor data, used to predict when compressors would need maintenance. It took three months to get to a working prototype. It took another six months to get the model to actually agree with reality, because nobody warned me that two of the four sensors were averaging their readings over 15 minutes, while the other two were reporting once per second. The "twin" was a sophisticated time machine confused by its own clock. That experience is the origin of the skepticism I bring to every digital-twin project I see pitched today.
What if you could crash your entire production infrastructure — on purpose — without breaking anything real? What if you could test a new traffic signal pattern across Manhattan at 3 AM, see exactly how it affects congestion, and roll it back before anyone noticed? What if you could predict a factory machine failure three weeks before it happens, based on nothing but vibration data and temperature readings?
This is the promise of digital twins — and in 2026, that promise is being cashed in at enormous scale. From Singapore's city-wide simulation to BMW's virtual production lines, digital twins have moved from research novelty to industrial backbone. Gartner estimates that 85% of enterprise IoT platforms will include some form of twinning capability by 2027. The global market is projected to hit $110 billion by 2028.
But what actually is a digital twin, and more importantly, how do developers build and use them? This post breaks down the technology from first principles, walks through real implementations, and shows you where the architecture gets genuinely interesting.
The Problem Digital Twins Solve
Before digital twins, the standard approach to understanding a complex physical system was to either:
- Instrument it heavily — attach sensors everywhere, collect logs, and analyze after the fact
- Build static models — create a CAD design or a spreadsheet simulation that you update manually
- Learn by breaking things — run experiments on the real system and accept the consequences
None of these are satisfying. Post-hoc analysis tells you what happened, not what will happen. Static models go stale the moment the first bolt gets tightened. And running live experiments on a hospital's HVAC system or a nuclear plant's cooling loop is obviously not an option.
The core problem is the gap between the physical and the digital. Your physical asset changes continuously — machines wear down, traffic patterns shift, a data center's cooling load fluctuates with every new workload. But your model of that asset is a frozen snapshot from last quarter.
Digital twins close that gap by creating a living, continuously updated simulation that ingests real sensor data and reflects the current state of the physical asset at all times. The twin isn't just a model — it's a synchronized mirror.
Three Layers That Define a Digital Twin
A properly designed digital twin has three distinct layers that work together:
The Physical Layer — The real-world asset with embedded sensors, actuators, PLCs (programmable logic controllers), or IoT devices. This is the source of truth. Everything flows from here.
The Data Integration Layer — The pipeline that moves data from the physical layer into the simulation: MQTT brokers, time-series databases (InfluxDB, TimescaleDB), stream processors (Kafka, Azure Event Hubs), and the protocols that stitch them together (OPC-UA for industrial systems, REST or WebSockets for lighter integrations).
The Simulation Layer — The virtual representation itself: physics models, ML-based behavioral models, 3D spatial environments, and the reasoning engine that can run "what-if" scenarios.
Most failed digital twin projects fail at layer two. Connecting a sensor to a database is easy. Ensuring that data arrives with consistent timestamps, correct units, and appropriate frequency across 50,000 sensors from 12 different vendors is an engineering challenge that deserves its own post.
How It Works: The Architecture
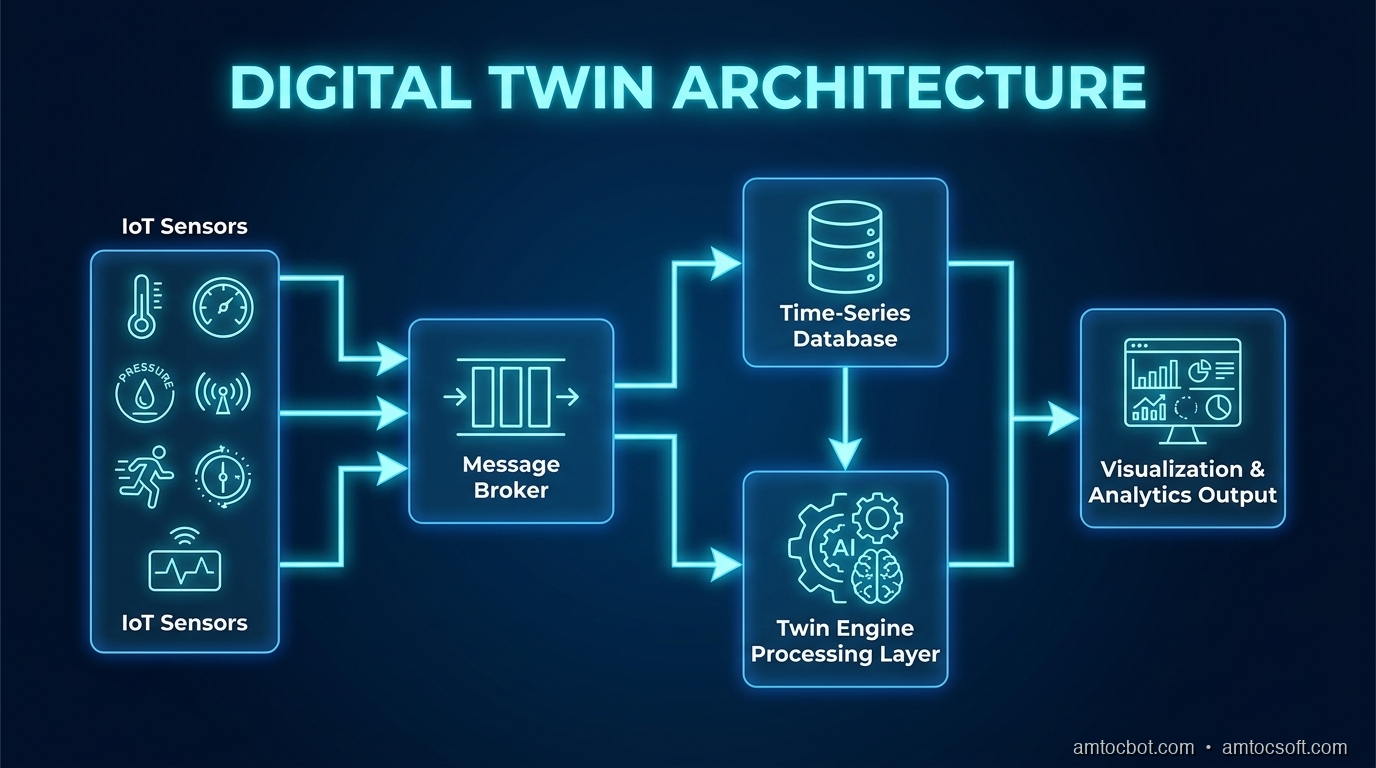
Let's trace the flow for a concrete example: a smart factory floor.
A BMW production line has robotic welding arms, conveyor systems, quality inspection cameras, and environmental sensors. Each device generates data continuously. Here's what the digital twin architecture looks like:
Physical Assets
├── Welding Robot (vibration, current draw, cycle time)
├── Conveyor Belt (speed, load, motor temp)
├── Inspection Camera (defect detection output)
└── Environmental (temperature, humidity, air pressure)
│
▼ (OPC-UA / MQTT)
Message Broker (Apache Kafka)
│
▼
Stream Processor (Apache Flink)
├── Deduplication
├── Unit normalization
├── Timestamp alignment
└── Anomaly pre-filtering
│
▼
Time-Series Database (InfluxDB / TimescaleDB)
│
├──► Twin Engine (Azure Digital Twins / AWS IoT TwinMaker)
│ ├── Asset graph (relationships between assets)
│ ├── Physics models (thermal, mechanical)
│ ├── ML models (predictive maintenance, anomaly detection)
│ └── Scenario simulator ("what if conveyor speed +20%?")
│
└──► Visualization (Unity / Unreal / custom web 3D)
The twin engine is where the magic lives. It maintains a graph of asset relationships — the welding robot is part of station 4, station 4 is connected to conveyor segment C, conveyor C feeds into quality inspection zone 2. This graph lets you do impact analysis: "If the motor on conveyor C degrades, which downstream processes are affected?"
Modern twin platforms like Azure Digital Twins use a modeling language called DTDL (Digital Twin Definition Language) — a JSON-based schema for describing asset types, properties, and relationships.
{
"@id": "dtmi:factory:WeldingRobot;1",
"@type": "Interface",
"displayName": "Welding Robot",
"contents": [
{
"@type": "Property",
"name": "cycleTimeMs",
"schema": "double"
},
{
"@type": "Telemetry",
"name": "vibrationG",
"schema": "double"
},
{
"@type": "Relationship",
"name": "locatedIn",
"target": "dtmi:factory:ProductionStation;1"
}
]
}
This schema-first approach forces you to be explicit about what your assets are before you start throwing data at them. It sounds bureaucratic, but it pays dividends when you need to query across asset types or propagate a status change through the relationship graph.
Implementation Guide
Let's get concrete. Here's how to build a minimal digital twin for a single machine using Python, InfluxDB, and a physics-based degradation model.
Step 1: Instrument the Asset
For a motor, you'd collect at minimum: RPM, current draw (amps), bearing temperature, and vibration (in G-forces). Using a Raspberry Pi with an INA219 current sensor and an ADXL345 accelerometer:
import time
import board
import adafruit_adxl34x
import adafruit_ina219
from influxdb_client import InfluxDBClient, Point
from influxdb_client.client.write_api import SYNCHRONOUS
# Sensor setup
i2c = board.I2C()
accelerometer = adafruit_adxl34x.ADXL345(i2c)
current_sensor = adafruit_ina219.INA219(i2c)
# InfluxDB connection
client = InfluxDBClient(url="http://localhost:8086", token="YOUR_TOKEN", org="factory")
write_api = client.write_api(write_options=SYNCHRONOUS)
ASSET_ID = "motor-line4-001"
def collect_and_write():
ax, ay, az = accelerometer.acceleration
vibration_g = (ax**2 + ay**2 + az**2) ** 0.5
point = (
Point("motor_telemetry")
.tag("asset_id", ASSET_ID)
.field("vibration_g", vibration_g)
.field("current_amps", current_sensor.current / 1000)
.field("bus_voltage", current_sensor.bus_voltage)
)
write_api.write(bucket="factory_data", record=point)
while True:
collect_and_write()
time.sleep(1) # 1Hz sampling rate
Step 2: Build the Degradation Model
Real industrial systems degrade according to known physics. For a bearing, the RMS vibration increases as the bearing wears. You can model this with a simple exponential degradation curve calibrated on historical data:
import numpy as np
from dataclasses import dataclass
from datetime import datetime, timedelta
@dataclass
class MotorTwin:
asset_id: str
baseline_vibration: float # G-force at time of commissioning
degradation_rate: float # empirically calibrated per asset type
commission_date: datetime
def predict_vibration(self, at_time: datetime) -> float:
"""Predict vibration level at a given point in time."""
days_running = (at_time - self.commission_date).days
return self.baseline_vibration * np.exp(self.degradation_rate * days_running)
def time_to_threshold(self, threshold_g: float) -> timedelta:
"""Calculate when vibration will exceed the alarm threshold."""
if self.predict_vibration(datetime.now()) >= threshold_g:
return timedelta(0) # already exceeded
days = np.log(threshold_g / self.baseline_vibration) / self.degradation_rate
return timedelta(days=int(days))
def health_score(self) -> float:
"""0.0 = failed, 1.0 = like new"""
current = self.predict_vibration(datetime.now())
failure_threshold = self.baseline_vibration * 10 # 10x baseline = failure
return max(0.0, 1.0 - (current - self.baseline_vibration) / (failure_threshold - self.baseline_vibration))
# Example usage
twin = MotorTwin(
asset_id="motor-line4-001",
baseline_vibration=0.12, # G at commissioning
degradation_rate=0.003, # calibrated from fleet data
commission_date=datetime(2025, 1, 15)
)
print(f"Current health score: {twin.health_score():.2%}")
print(f"Days until 0.5G alarm: {twin.time_to_threshold(0.5).days} days")
Step 3: Continuously Sync with Real Data
The model above is purely physics-based. To make it a true digital twin, you sync it with actual observed data and use the divergence between prediction and observation as a signal:
from influxdb_client import InfluxDBClient
def get_latest_vibration(asset_id: str) -> float:
query = f'''
from(bucket: "factory_data")
|> range(start: -5m)
|> filter(fn: (r) => r["asset_id"] == "{asset_id}")
|> filter(fn: (r) => r["_field"] == "vibration_g")
|> last()
'''
result = query_api.query(query)
for table in result:
for record in table.records:
return record.get_value()
return None
def sync_and_alert(twin: MotorTwin, alarm_threshold: float = 0.5):
observed = get_latest_vibration(twin.asset_id)
predicted = twin.predict_vibration(datetime.now())
divergence = abs(observed - predicted) / predicted
if divergence > 0.20: # >20% divergence from model
print(f"WARNING: {twin.asset_id} diverging from model ({divergence:.0%})")
# Recalibrate degradation_rate using observed data
# (Kalman filter or simple EMA update in practice)
if observed > alarm_threshold:
trigger_maintenance_ticket(twin.asset_id, observed)
print(f"ALERT: {twin.asset_id} vibration {observed:.3f}G exceeds threshold")
Comparison & Tradeoffs
Not every "digital twin" implementation is the same. Here's a realistic breakdown of the approaches:
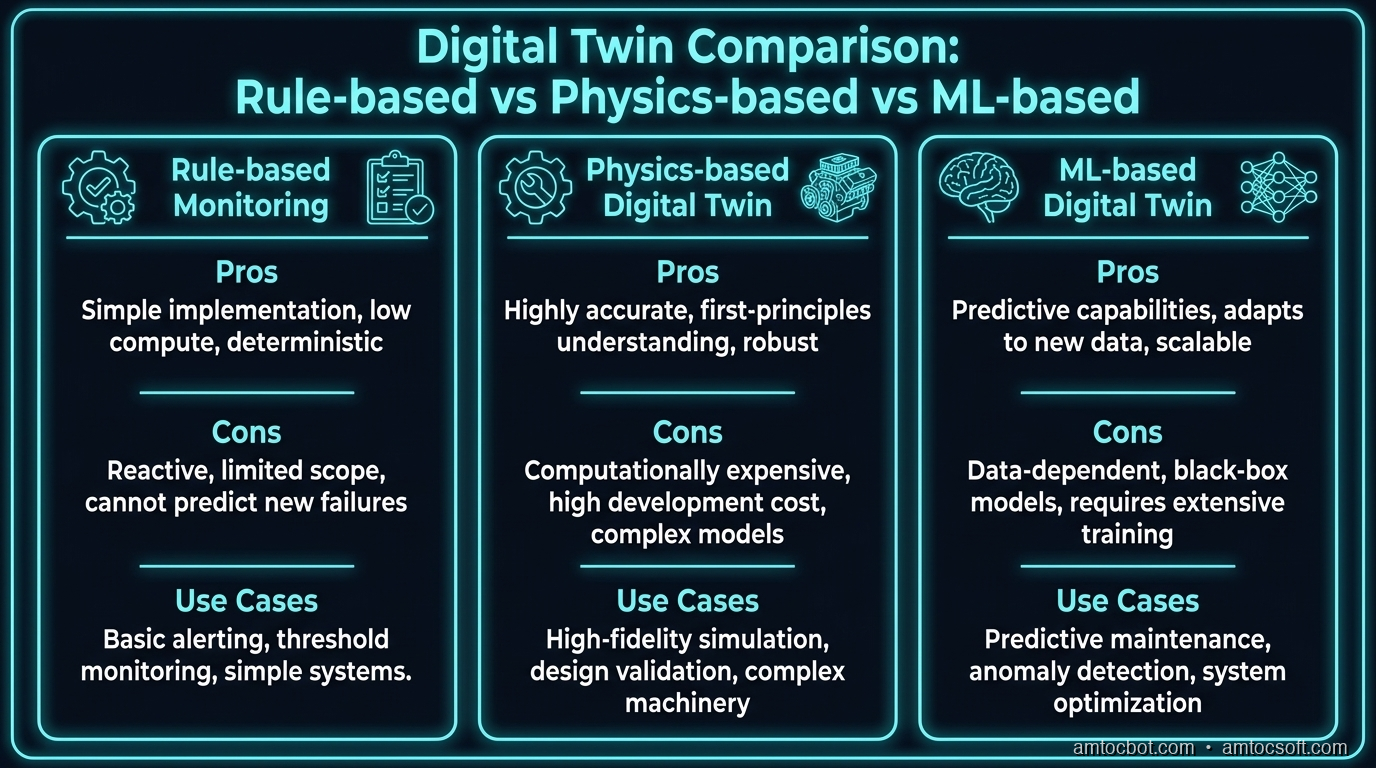
| Approach | Setup Cost | Accuracy | Generalization | Best For |
|---|---|---|---|---|
| Rule-based monitoring | Low | Moderate | Poor | Simple threshold alarms |
| Physics-based twin | High | High (known physics) | Good for asset type | Industrial equipment with known models |
| ML-based behavioral twin | Medium | High (data-dependent) | Excellent | Complex systems, unknown dynamics |
| Hybrid (physics + ML) | High | Highest | Best | Mission-critical systems |
The hybrid approach dominates serious deployments. Physics models capture what we know about how a motor or building should behave. ML fills in the gaps — the nonlinear relationships, the effects of environmental factors, the cross-asset interactions that physics models don't capture cleanly.
Platform Choices in 2026
| Platform | Strengths | Weaknesses | Best For |
|---|---|---|---|
| Azure Digital Twins | Strong graph model, DTDL standard, deep Azure integration | Complex to set up, Azure lock-in | Enterprise, manufacturing |
| AWS IoT TwinMaker | Tight Grafana integration, good 3D visualization | Less mature graph capabilities | AWS-native teams |
| NVIDIA Omniverse | Best-in-class 3D simulation, physics engine | GPU-heavy, expensive at scale | Robotics, autonomous vehicles |
| Eclipse Ditto | Open source, solid REST/WebSocket APIs | Requires significant self-management | Teams that want control |
| Siemens Teamcenter | Deep PLM integration | Industrial-only, expensive licensing | OEMs with existing Siemens tooling |
Real-World Case Studies
Singapore's Virtual City
Singapore's Virtual Singapore project is the most cited example at city scale. The platform maintains a 3D semantic model of the entire island — every building, road, underground utility, and tree. It isn't just geometry; each object carries semantic data (building age, occupancy, energy consumption, flood risk zone).
Use cases include: solar panel placement optimization (simulating shade patterns across 10,000 buildings simultaneously), emergency evacuation routing, and urban microclimate modeling. The city found that digital twin-informed solar placement decisions improved energy yield by 23% over expert judgment alone.
BMW's Virtual Production Line
BMW's Leipzig plant runs a full digital twin of each production line in parallel with the physical line. Before any production change — new vehicle model, retooled robot, adjusted assembly sequence — it's simulated in the twin first. The virtual commissioning process cut physical commissioning time from weeks to days. More importantly, it enabled BMW to run "impossible" tests: simulate a robot arm failure mid-production run and verify that the line's failover procedures actually work, without ever touching the real line.
Data Center Cooling Optimization
Google's DeepMind team famously applied ML to optimize data center cooling, reducing energy use by 40%. The "digital twin" in that context was an ML model trained on sensor data to predict Power Usage Effectiveness (PUE) based on thousands of variables — server loads, external temperature, cooling water flow rates, fan speeds. The model runs continuously, and its recommendations are sent back as actuation commands to the real cooling system.
Production Considerations
Deploying digital twins at scale surfaces some non-obvious challenges:
Time synchronization is critical. If sensor A timestamps its reading at T and sensor B at T+200ms, your twin sees a fake state that never existed in the physical world. Industrial deployments use PTP (Precision Time Protocol, IEEE 1588) to synchronize clocks to microsecond precision across the factory floor. For less demanding applications, NTP with careful timestamp handling in the pipeline is usually sufficient.
Model drift is inevitable. Physical systems change — components get replaced, configurations evolve, usage patterns shift. Your physics models and ML models will drift from reality unless you build continuous recalibration into the pipeline. This means monitoring prediction error (not just asset health) as a first-class metric.
Storage costs compound fast. A single sensor at 1Hz generates 86,400 readings/day. A factory with 10,000 sensors generates 864 million readings/day. Time-series databases handle compression well — InfluxDB achieves 10-40x compression for monotonically increasing sensor data — but you still need a tiering strategy: high-resolution recent data, downsampled historical data, aggregated long-term data.
Security is often the afterthought that kills projects. Industrial systems were not designed with internet connectivity in mind. OT (operational technology) networks historically air-gapped from IT networks. Digital twins require bridging that gap. Every protocol translator and data pipeline is a potential attack surface. The 2021 Oldsmar water treatment facility attack (where an attacker tried to increase sodium hydroxide to dangerous levels via remote access) is the canonical example of what's at stake.
A layered defense: network segmentation between OT and IT, mutual TLS on all data pipelines, read-only data flows from OT to IT (never write commands back through the same pipe as telemetry), and hardware-enforced data diodes for truly critical systems.
Three Debugging Scars Worth Sharing
If you're building a digital twin, you will run into these. I am giving you six months back.
The timestamp drift we didn't catch for three weeks. On that first HVAC project, the twin kept predicting a chiller failure that never came. The compressor vibration data looked noisy in ways the model couldn't reconcile. After three weeks of calibration attempts, we finally checked the raw sensor metadata: the Modbus gateway was buffering readings and emitting them in a burst every 15 minutes with a single timestamp applied to all of them, while the supervisory control system was logging individual timestamps at 1 Hz. Our "divergence from model" was a completely fictional signal generated by the ingestion layer averaging sensor values over a 15-minute window. The fix was a one-line change to the gateway firmware. The lesson was that timestamp metadata is load-bearing and you should assert on it at the ingestion edge, not discover it three weeks into debugging model accuracy.
Unit mismatches across vendors. A Siemens PLC reports temperature in degrees Celsius. A legacy Allen-Bradley controller reports the same sensor type in Fahrenheit. A third-party OPC-UA bridge we'd installed helpfully converted some values and not others. Our pooled telemetry had a mix of units in the same field, and the ML model trained on it happily learned a weird bimodal distribution that worked about 40% of the time. If you have more than one vendor in your OT stack, put unit validation in the stream processor and reject anything without an explicit unit tag. Make "unit is unknown" a first-class error, not a silent shrug.
The model that memorized a maintenance schedule. We trained an anomaly detector on a year of factory data. It worked beautifully for a month in production, then started firing false positives every other Tuesday. It turned out the training data included a regular planned maintenance downtime every Tuesday evening that the model had learned as "normal" behaviour — and production was now running on a different schedule. Digital-twin ML models inherit every pattern in their training data, including operational rhythms you didn't think were features. Always split train/test by calendar week, not by random sample, so the model has to generalize across schedule changes.
Conclusion
Digital twins represent a fundamental shift in how engineers relate to physical systems. The old model was: deploy, monitor, react. The new model is: model, simulate, predict, and then deploy changes to the real world with confidence.
The technology stack has matured enough that you don't need to build everything from scratch. Azure Digital Twins, AWS IoT TwinMaker, and Eclipse Ditto provide solid foundations. The real engineering challenge is in the data layer — getting clean, synchronized, consistent data from physical assets into your simulation pipeline — and in the modeling layer, choosing between physics models, ML models, and the hybrid approaches that combine both.
For developers looking to get started: pick a single asset, instrument it well, and build a minimal working twin before expanding scope. The value of a well-calibrated single-asset twin is orders of magnitude higher than a shallow twin of a hundred assets.
The cities, factories, and data centers running digital twins today aren't doing it as a curiosity. They're doing it because the alternative — operating complex physical systems based on intuition, historical rules, and post-hoc analysis — leaves enormous value on the table.
Want to go deeper? The next post in this series covers Web3's practical enterprise use cases — where distributed ledgers actually make sense in 2026, and where they remain hype.
Have you built or worked with digital twins in production? Share your architecture challenges in the comments — the hardest parts are almost always in the data pipeline, not the simulation.
Sources
- Microsoft — Azure Digital Twins documentation (DTDL schema, graph model, ingress/egress patterns)
- AWS — IoT TwinMaker concepts (entity model, scene composition, data connector architecture)
- NVIDIA — Omniverse for Digital Twins (physics-based simulation and OpenUSD for industrial twins)
- DeepMind — DeepMind AI reduces data center cooling bill by 40% (original 2016 case study with subsequent deployment details)
- Gartner — Forecast: Digital Twin Implementation Growth (adoption projections frequently cited in 2024/2025 analyst updates)
- CISA — Pinellas County Oldsmar water treatment incident advisory (reference OT security case)
About the Author
Toc Am
Founder of AmtocSoft. Writing practical deep-dives on AI engineering, cloud architecture, and developer tooling. Previously built backend systems at scale. Reviews every post published under this byline.
Published: 2026-04-17 · Updated: 2026-04-18 · Written with AI assistance, reviewed by Toc Am.
Get These In Your Inbox
Weekly deep-dives on AI engineering, no fluff. Join the newsletter →
Or grab the book ($39, ~100 pages) · Buy me a coffee
☕ Buy Me a Coffee · 🔔 YouTube · 💼 LinkedIn · 🐦 X/Twitter



No comments:
Post a Comment