
Generated with Higgsfield GPT Image — 16:9
Introduction
Somewhere in your organization, there is a developer waiting on a Jira ticket to get a staging environment. Someone else is copying a service skeleton from a four-year-old repository and manually updating all the CI references. A third person just spent two hours debugging why their Kubernetes deployment failed, only to discover a resource quota was never set on the namespace.
This is not a people problem. It is a platform problem.
Internal Developer Platforms (IDPs) exist to solve exactly these friction points. But in 2026, the market is crowded, the tradeoffs are real, and the cost of choosing wrong is measured in years — not weeks. Companies that bet on Backstage three years ago are now maintaining massive plugin catalogs and struggling to hire React engineers for internal tooling. Companies that chose simpler commercial platforms complain about vendor lock-in and limited extensibility.
This post is a practical guide to the IDP decision. We will cover what is actually inside these platforms, dissect the leading tools in detail, and give you a concrete framework for choosing between building and buying. If you are a platform engineer, engineering manager, or architect evaluating IDPs in 2026, this is the post you need to read before you commit.
The IDP Landscape in 2026
The Internal Developer Platform market has consolidated significantly since 2022. Early fragmentation — dozens of point solutions for catalog, scaffolding, environment provisioning, and scorecards — has given way to a handful of comprehensive platforms that each take a distinct architectural stance.
Backstage remains the dominant open-source option. Created by Spotify, adopted by the CNCF, and now with over 28,000 GitHub stars and 2,700+ production deployments, it has become the de facto industry vocabulary for IDPs. But Backstage's success has also revealed its limitations as organizations scale.
Port has emerged as the fastest-growing commercial alternative. Its API-first catalog model, no-code blueprint system, and self-service action engine have attracted companies that want value within weeks rather than months. Port closed a Series B in 2024 and has been doubling year-over-year since 2022.
Humanitec targets enterprises that want a Platform Orchestrator — an API layer that sits between developer intent and infrastructure execution. Mercedes-Benz, TIER Mobility, and other large enterprises have adopted it as the backbone of their platform.
Cortex and OpsLevel occupy a specific niche: catalog and engineering excellence scoring. They are less about self-service provisioning and more about visibility, accountability, and quality enforcement.
Configure8 is an emerging player focused on making catalog data actionable via deep integrations with existing engineering tools.
The market is moving toward composability: rather than one monolithic IDP, organizations are assembling best-of-breed components around a central catalog. But the complexity of composing and maintaining that stack has renewed interest in consolidated commercial platforms.
Backstage Deep Dive
Backstage is the right choice for many organizations — but it demands respect. Its architecture is sophisticated, its plugin ecosystem is both its greatest strength and its greatest liability, and the maintenance burden can surprise teams that underestimate it.
How Backstage Works
Backstage has three core pillars:
1. Software Catalog — The catalog ingests catalog-info.yaml files from your repositories, Kubernetes clusters, CI systems, and other integrations. It models your technical ecosystem as entities: Components (services, libraries, websites), APIs, Resources (databases, S3 buckets), Systems (logical groupings), and Domains (business units).
2. TechDocs — Backstage includes a documentation system that reads docs/ directories from your repositories and renders them as searchable HTML inside the portal. Developers write Markdown; the platform handles discovery and search.
3. Software Templates (Scaffolder) — The scaffolder lets platform teams define parameterized templates that create GitHub repositories, open PRs, provision infrastructure, and register catalog entries — all from a self-service form in the Backstage UI.
Here is a complete catalog-info.yaml showing the full range of metadata Backstage can track for a production service:
apiVersion: backstage.io/v1alpha1
kind: Component
metadata:
name: recommendation-engine
title: Recommendation Engine
description: "ML-powered product recommendation service (collaborative filtering + content-based)"
annotations:
# Source control
github.com/project-slug: "acmecorp/recommendation-engine"
# CI/CD
github.com/workflow-name: "ci-cd.yml"
# Observability
datadoghq.com/service-name: "recommendation-engine"
datadoghq.com/dashboard-url: "https://app.datadoghq.com/dashboard/rec-engine"
# Incident management
pagerduty.com/service-id: "PML123"
pagerduty.com/integration-key: "abc123xyz"
# Cost attribution
aws.amazon.com/cost-center: "ML-PLATFORM"
# Kubernetes
backstage.io/kubernetes-id: "recommendation-engine"
backstage.io/kubernetes-namespace: "ml-services"
# SLO
slo: "p99_latency<200ms, availability>99.9%"
tags:
- ml
- python
- critical-path
- tier-1
links:
- url: https://runbook.internal/recommendation-engine
title: Runbook
icon: docs
- url: https://grafana.internal/d/rec-engine
title: Grafana Dashboard
icon: dashboard
spec:
type: service
lifecycle: production
owner: group:ml-platform
system: personalization
dependsOn:
- component:user-profile-service
- component:product-catalog-service
- resource:redis-recommendations-cache
- resource:rds-ml-features-db
providesApis:
- recommendations-api
consumesApis:
- user-events-api
- product-catalog-api
Backstage Software Templates
The scaffolder is where Backstage delivers its highest developer ROI. Here is a simplified but complete scaffolder template that creates a new Go microservice:
# template.yaml — Backstage Scaffolder Template
apiVersion: scaffolder.backstage.io/v1beta3
kind: Template
metadata:
name: go-microservice-template
title: Go Microservice
description: Creates a production-ready Go microservice with CI, observability, and catalog registration
tags:
- go
- microservice
- recommended
spec:
owner: group:platform-team
type: service
parameters:
- title: Service Information
required: [name, description, owner]
properties:
name:
title: Service Name
type: string
description: Lowercase, hyphenated (e.g. 'inventory-sync')
pattern: '^[a-z][a-z0-9-]{2,48}[a-z0-9]$'
description:
title: Description
type: string
owner:
title: Owner
type: string
ui:field: OwnerPicker
ui:options:
allowedKinds: [Group]
tier:
title: Service Tier
type: string
default: tier-2
enum: [tier-1, tier-2, tier-3]
enumNames:
- 'Tier 1 (Critical Path, 99.9% SLA)'
- 'Tier 2 (Standard, 99.5% SLA)'
- 'Tier 3 (Internal, best effort)'
- title: Infrastructure Options
properties:
needsDatabase:
title: Needs PostgreSQL database?
type: boolean
default: false
needsCache:
title: Needs Redis cache?
type: boolean
default: false
initialReplicas:
title: Initial replica count
type: integer
default: 2
minimum: 1
maximum: 10
steps:
- id: fetch-skeleton
name: Fetch Go service skeleton
action: fetch:template
input:
url: ./skeleton
values:
name: ${{ parameters.name }}
description: ${{ parameters.description }}
owner: ${{ parameters.owner }}
tier: ${{ parameters.tier }}
needs_database: ${{ parameters.needsDatabase }}
needs_cache: ${{ parameters.needsCache }}
- id: publish-github
name: Create GitHub Repository
action: publish:github
input:
allowedHosts: ['github.com']
repoUrl: 'github.com?repo=${{ parameters.name }}&owner=acmecorp'
defaultBranch: main
repoVisibility: private
deleteBranchOnMerge: true
requireCodeOwnerReviews: true
- id: register-catalog
name: Register in Service Catalog
action: catalog:register
input:
repoContentsUrl: ${{ steps['publish-github'].output.repoContentsUrl }}
catalogInfoPath: /catalog-info.yaml
- id: create-datadog-dashboard
name: Create Datadog Dashboard
action: http:backstage:request
input:
method: POST
path: /api/proxy/datadog/api/v1/dashboard
body:
title: '${{ parameters.name }} Service Dashboard'
description: 'Auto-generated by platform scaffolder'
widgets: [] # Platform team maintains a default widget set
output:
links:
- title: Repository
url: ${{ steps['publish-github'].output.remoteUrl }}
- title: Open in Catalog
icon: catalog
entityRef: ${{ steps['register-catalog'].output.entityRef }}
Backstage Plugins
The plugin ecosystem is where Backstage either soars or stumbles, depending on your team's investment. Core plugins are maintained by Backstage contributors and are generally high quality. Community plugins vary enormously — some are production-grade and actively maintained, others were written by one engineer for a weekend project and have not been updated in two years.
Well-maintained plugins in 2026 include: GitHub Actions (CI visibility), Kubernetes (pod status in the catalog), Datadog (metrics in the service page), ArgoCD (deployment status), Vault (secrets access), and AWS Cost Explorer (cost attribution).
The maintenance reality: a typical large Backstage installation in 2026 has 30-80 active plugins. Keeping them current with Backstage core releases requires a dedicated engineer or small team. This is not a criticism — it is a known tradeoff that teams must budget for.
Backstage hosting options have improved. You can self-host Backstage on Kubernetes (the most common approach), use managed Backstage from providers like Roadie.io or Spotify's own Backstage as a Service offering, or deploy it to Render, Railway, or a similar PaaS. Self-hosted on Kubernetes gives maximum control but requires maintaining the deployment, database (PostgreSQL), and ingress. Managed options reduce operational overhead at the cost of some customization and a monthly fee.
Port Deep Dive
Port takes the opposite philosophical stance from Backstage. Where Backstage gives you maximum flexibility at the cost of maximum complexity, Port optimizes for rapid adoption and low operational overhead.
Blueprints: Port's Core Data Model
In Port, everything is a blueprint — a schema definition for a resource type in your organization. You define the properties, relationships, and lifecycle states for each type of resource, then connect Port to your existing tools to populate it with live data.
{
"identifier": "microservice",
"title": "Microservice",
"icon": "Service",
"schema": {
"properties": {
"language": {
"type": "string",
"title": "Language",
"enum": ["Go", "Python", "TypeScript", "Java", "Rust"]
},
"tier": {
"type": "string",
"title": "Service Tier",
"enum": ["tier-1", "tier-2", "tier-3"]
},
"has_slo": {
"type": "boolean",
"title": "Has SLO Defined"
},
"p99_latency_ms": {
"type": "number",
"title": "P99 Latency (ms)"
},
"monthly_cost_usd": {
"type": "number",
"title": "Monthly Cloud Cost (USD)"
},
"on_call_team": {
"type": "string",
"title": "On-Call Team"
}
},
"required": ["language", "tier", "on_call_team"]
},
"mirrorProperties": {},
"calculationProperties": {
"health_score": {
"title": "Health Score",
"calculation": ".properties.has_slo and .properties.p99_latency_ms < 200 | if . then 100 else 50 end",
"type": "number"
}
},
"relations": {
"deployment": {
"title": "Current Deployment",
"target": "deployment",
"required": false,
"many": false
},
"owner": {
"title": "Owner Team",
"target": "team",
"required": true,
"many": false
}
}
}
Port's self-service actions let developers trigger operations — create a new service, request a database, scale a deployment — via Port's UI, and Port executes them through your existing CI/CD pipelines (GitHub Actions, GitLab CI, Jenkins) or via webhooks. No custom UI development required.
A self-service action in Port that triggers a GitHub Actions workflow looks like this:
{
"identifier": "scaffold-microservice",
"title": "Scaffold New Microservice",
"icon": "Service",
"userInputs": {
"properties": {
"service_name": {
"type": "string",
"title": "Service Name",
"description": "Lowercase, hyphenated"
},
"language": {
"type": "string",
"title": "Language",
"enum": ["go", "python", "typescript"]
},
"owner_team": {
"type": "string",
"title": "Owner Team",
"blueprint": "team",
"format": "entity"
}
},
"required": ["service_name", "language", "owner_team"]
},
"invocationMethod": {
"type": "GITHUB",
"org": "acmecorp",
"repo": "platform-actions",
"workflow": "scaffold-service.yml",
"omitPayload": false,
"reportWorkflowStatus": true
},
"trigger": "CREATE",
"description": "Scaffold a new microservice with CI/CD, catalog registration, and observability"
}
Port's scorecards enable engineering excellence tracking: teams can define standards (every service must have an SLO, must have a runbook, must have fewer than 10 critical CVEs) and track compliance across the entire catalog in real time. The scorecard dashboard shows each team's compliance percentage, which services are failing which standards, and trends over time. This gamification element drives organic adoption — teams want to improve their scores, which means following the platform standards.
Humanitec: The Platform Orchestrator Model
Humanitec's approach is the most architecturally distinct of the three major players. While Backstage and Port are primarily portals — developer-facing UIs on top of your existing infrastructure — Humanitec positions itself as a Platform Orchestrator: an API layer that translates high-level developer intent into concrete infrastructure configurations.
The Score Model
Humanitec's core concept is the Score file — a simple, infrastructure-agnostic workload specification that developers write once and the orchestrator compiles to any target infrastructure (Kubernetes manifests, Helm releases, Terraform configs, ECS task definitions).
# score.yaml — developer writes this, orchestrator compiles it
apiVersion: score.dev/v1b1
metadata:
name: order-processor
containers:
order-processor:
image: acmecorp/order-processor:${IMAGE_TAG}
variables:
DATABASE_URL: ${resources.postgres.connection_string}
REDIS_URL: ${resources.cache.connection_string}
LOG_LEVEL: info
resources:
requests:
cpu: "100m"
memory: "128Mi"
limits:
cpu: "500m"
memory: "512Mi"
livenessProbe:
httpGet:
path: /health
port: 8080
service:
ports:
http:
port: 80
targetPort: 8080
resources:
postgres:
type: postgres
class: standard
cache:
type: redis
class: standard
The platform team defines resource definitions that specify how each resource type (postgres, redis, s3) should be provisioned in each environment class (dev, staging, production). Developers never write Kubernetes YAML or Terraform — they declare what their service needs, and the orchestrator handles the rest.
Humanitec's dynamic environment configuration solves a specific pain point at scale: managing hundreds of staging and preview environments where each one needs its own resource instances with correct connection strings injected automatically.
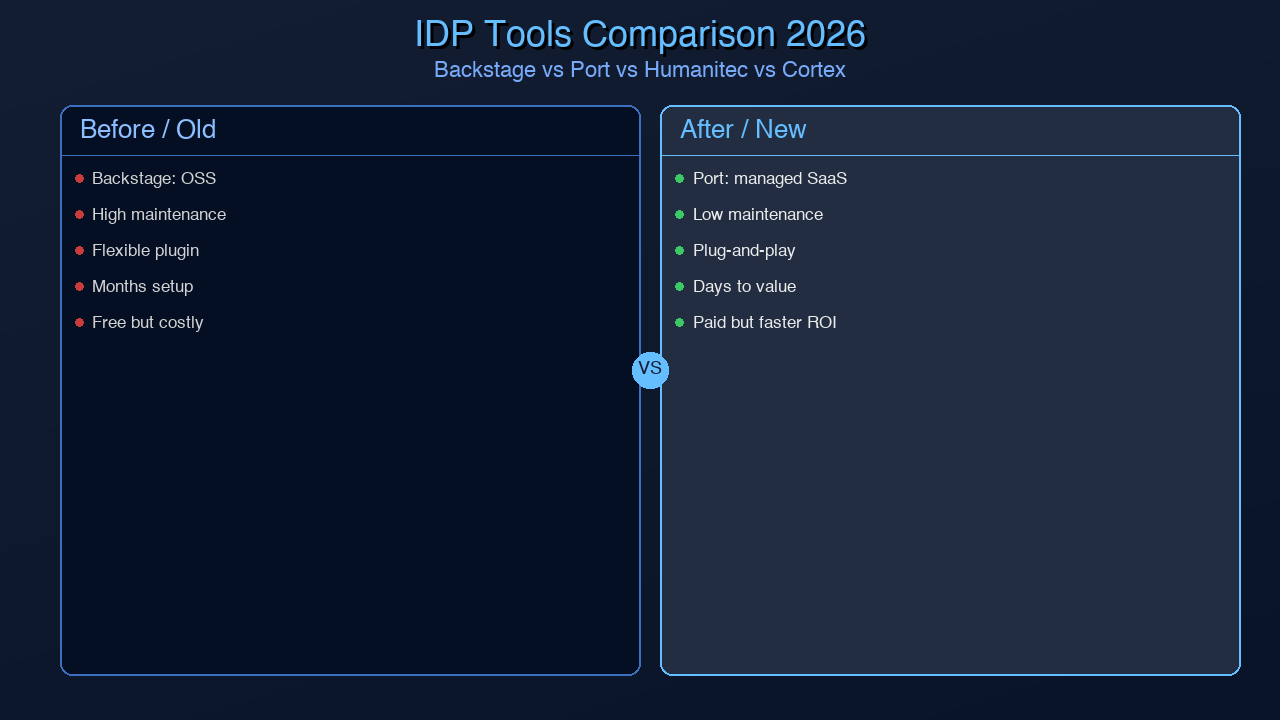
Build vs Buy Decision Framework
With the tools understood in detail, the decision framework becomes clearer. The right choice depends on five variables: team size, operational maturity, budget, customization needs, and how quickly you need to deliver value.
Generated with Higgsfield GPT Image — 16:9
Full Comparison Table
| Dimension | Backstage | Port | Humanitec | Cortex |
|---|---|---|---|---|
| Cost | Free (self-hosted) | $15-25/user/mo | Contact sales | $20-35/user/mo |
| Hosting | Self-hosted | SaaS | SaaS + self-hosted | SaaS |
| Setup Time | 2-8 weeks | 1-3 days | 1-2 weeks | 1-3 days |
| Customization | Unlimited (React) | Medium (no-code config) | High (API-first) | Low-medium |
| Scaffolding | Yes (powerful) | Yes (via actions) | Via Score/CI | Limited |
| Catalog | Excellent | Excellent | Good | Excellent |
| Scorecards | Via plugins | Built-in | Limited | Built-in (primary feature) |
| Env Provisioning | Via plugins | Via actions | Native (core feature) | No |
| Vendor Lock-in | None | Medium | Medium | Medium |
| Maintenance Burden | High | Low | Low | Low |
| Best For | Large orgs, custom needs | Fast adoption, SMB/enterprise | Dynamic environments, complex infra | Engineering quality tracking |
The Decision Tree
Self-Service in Practice
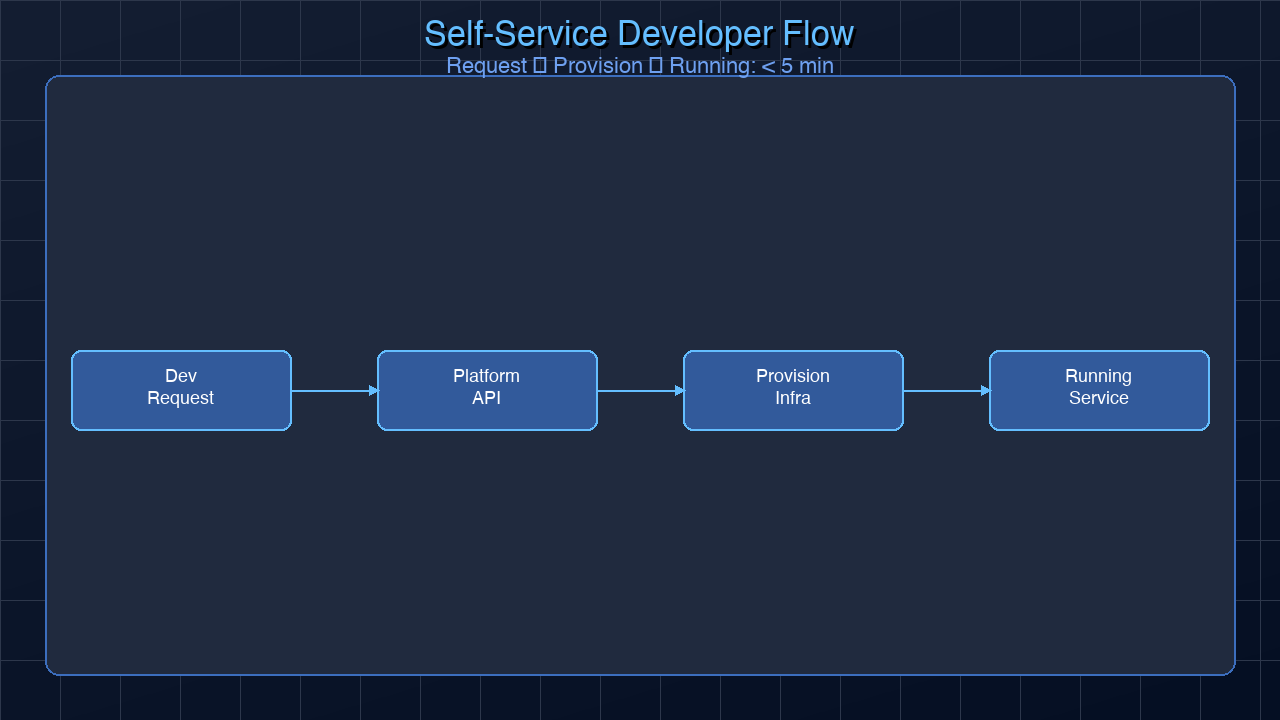
Theory is useful, but the real test of any IDP is the end-to-end experience for a developer who needs something. Let us walk through a complete self-service flow: a developer needs to create a new Python microservice and get it to staging.
Without an IDP (traditional path):
1. Copy an existing service repo, spend 30 minutes removing its specific logic
2. Update CI workflow references, fix the Docker build, update environment variables
3. File a Jira ticket to DevOps for a Kubernetes namespace (wait 1-3 days)
4. Set up Datadog monitoring manually
5. Add a PagerDuty service and link it to your team
6. Add the service to the internal wiki (or don't — this is how undiscoverable services happen)
Total time: 1-3 days, lots of context switching, high error risk.
With an IDP (golden path):
This is the concrete value proposition of an IDP. Four minutes versus two days. Zero Jira tickets. Zero waiting. The developer stays in flow.
Platform Maturity Model
Organizations do not build a complete IDP overnight. A useful framework for understanding where you are and where you are going is the Platform Engineering Maturity Model. It has four levels:
Most organizations evaluating IDPs for the first time are at Level 1 or early Level 2. The maturity model is useful for scoping expectations: if you are starting at Level 1, do not try to build a Level 3 platform in three months. Start with the catalog and CI templates. Earn developer trust. Then expand.
Generated with Higgsfield GPT Image — 16:9
Common Pitfalls
Platform engineering is not immune to failure modes. Understanding them in advance saves expensive lessons.
Building the platform nobody uses. This is the most common platform engineering failure. A team spends six months building an IDP and then discovers that developers are still using their old ad-hoc processes. The root cause: the platform was built without involving the developers who would use it. Platform teams that run regular developer experience interviews, track adoption metrics, and treat their users as customers avoid this trap.
Forcing the golden path. A golden path should be so good that developers choose it willingly, not because they have no alternative. When platform teams mandate their path without earning developer trust, developers route around it — using personal scripts, shadow CI pipelines, and workarounds that create more fragmentation than existed before.
Underestimating Backstage maintenance. Backstage core releases new versions frequently. Plugin compatibility is not guaranteed across major versions. Organizations that allocate zero ongoing engineering time for Backstage maintenance end up with installations frozen at a year-old version, missing security patches and features. Budget at least 0.5 FTE for a small installation, 1-2 FTE for a large one.
Not treating the platform as a product. The platform team that disappears after initial launch and considers the IDP "done" is setting itself up for irrelevance. Platforms require continuous iteration, deprecation of old features, onboarding support, and proactive engagement with developer feedback. The platform's product manager role — whether or not that title exists — is a full-time job.
Catalog rot. A service catalog is only valuable if it stays current. Without enforcement and automation, catalog-info.yaml files become stale within weeks of a service's architecture changing. Production IDPs address this through automated validation pipelines that fail CI if catalog metadata is missing required fields, scheduled jobs that detect orphaned catalog entries for deleted repositories, and regular catalog health reviews as part of platform team ceremonies.
Ignoring non-happy-path workflows. Golden path templates are designed for the common case: a new stateless microservice. But real engineering organizations have heterogeneous workloads: batch jobs, ML training pipelines, data streaming services, mobile backends. A platform that only supports the happy path forces teams building non-standard services to go completely off-road. Successful platform teams maintain a catalog of supported patterns and provide clear documentation for teams that need to deviate.
Measuring IDP Success
How do you know if your IDP is working? The metrics fall into three categories.
Developer adoption metrics are the most direct measure of whether the platform is delivering value. Track: percentage of new services created via the golden path (target: 80%+), percentage of teams using the catalog actively (viewed or updated a catalog entry in the last 30 days), and self-service action completion rate (did developers successfully complete self-service requests without abandoning or filing tickets?).
Developer experience scores are the qualitative complement to adoption metrics. A quarterly developer satisfaction survey with five to ten questions about infrastructure cognitive load, time spent on platform tasks, and confidence in tooling provides a trend line that reveals whether the platform is actually reducing friction.
Engineering performance metrics (DORA) measure downstream impact. As IDP adoption increases, deployment frequency should rise, lead time for changes should fall, and MTTR should improve. Platform teams that cannot demonstrate DORA improvement after six months should re-examine whether they are solving the right problems.
The platform team's internal dashboard should surface all of these metrics in one place. Ironically, the best platform teams build their own catalog entry and scorecard — treating the platform itself as a first-class service subject to the same standards they ask of everyone else.
Conclusion
The IDP market has matured enough in 2026 that the question is no longer "should we have an internal developer platform?" — it is "which approach fits our organization, and how do we avoid the two-year rebuild trap?"
Backstage is the right answer for organizations with a strong engineering culture, budget for ongoing React engineering, and a need for maximum customization. Port is the right answer for organizations that need rapid value and are comfortable with a SaaS model. Humanitec is right for enterprises with complex, dynamic environment provisioning needs. Cortex is right for organizations that need engineering excellence tracking first and everything else second.
The common thread in successful IDP implementations is treating the platform as a product. Developer experience is the product. Developer time is the metric. Adoption is the success criteria.
Whatever tool you choose, the platform team's mission is the same: make it so easy to do the right thing that developers never have to think about the infrastructure underneath. When the platform disappears into the background, it has succeeded.
Part of the Platform Engineering Deep-Dive series. Next: AI-Powered Cybersecurity.
About the Author
Toc Am
Founder of AmtocSoft. Writing practical deep-dives on AI engineering, cloud architecture, and developer tooling. Previously built backend systems at scale. Reviews every post published under this byline.
Published: 2026-04-12 · Written with AI assistance, reviewed by Toc Am.
Get These In Your Inbox
Weekly deep-dives on AI engineering, no fluff. Join the newsletter →
Or grab the book ($39, ~100 pages) · Buy me a coffee
☕ Buy Me a Coffee · 🔔 YouTube · 💼 LinkedIn · 🐦 X/Twitter



No comments:
Post a Comment