
The first time I handed a tricky competitive programming problem to GPT-4, it confidently produced a solution that failed on the second test case. I tweaked the prompt, added "think step by step," and got the same broken logic presented with more elaborate justification. It wasn't that the model was dumb — it was that standard next-token prediction has a hard ceiling on reasoning depth.
Then I tried the same problem on o3 in early 2026. It spent 47 seconds "thinking" before outputting anything. The solution was correct. What happened in those 47 seconds is the story of reasoning models.
The Ceiling Standard LLMs Hit
Before diving into reasoning models, it helps to understand exactly where vanilla LLMs fall short.
A standard transformer generates one token at a time, left to right, with no ability to revise earlier decisions. That architecture is remarkably powerful for pattern matching, code completion, and summarisation. But multi-step logical deduction — the kind that requires holding intermediate conclusions, checking consistency, and backtracking — doesn't map cleanly onto a single forward pass.
Chain-of-thought prompting ("think step by step") improves results because it forces the model to externalise intermediate reasoning into the context window. Each step can condition the next. But the model is still constrained: it can't revise a step it already emitted, and it has no mechanism for exploring alternative reasoning branches.
The result is a model that looks like it's reasoning but is really completing a pattern of reasoning-shaped text. For easy problems, the distinction doesn't matter. For hard ones — complex math, multi-constraint planning, adversarial code review — it does.
What Reasoning Models Do Differently
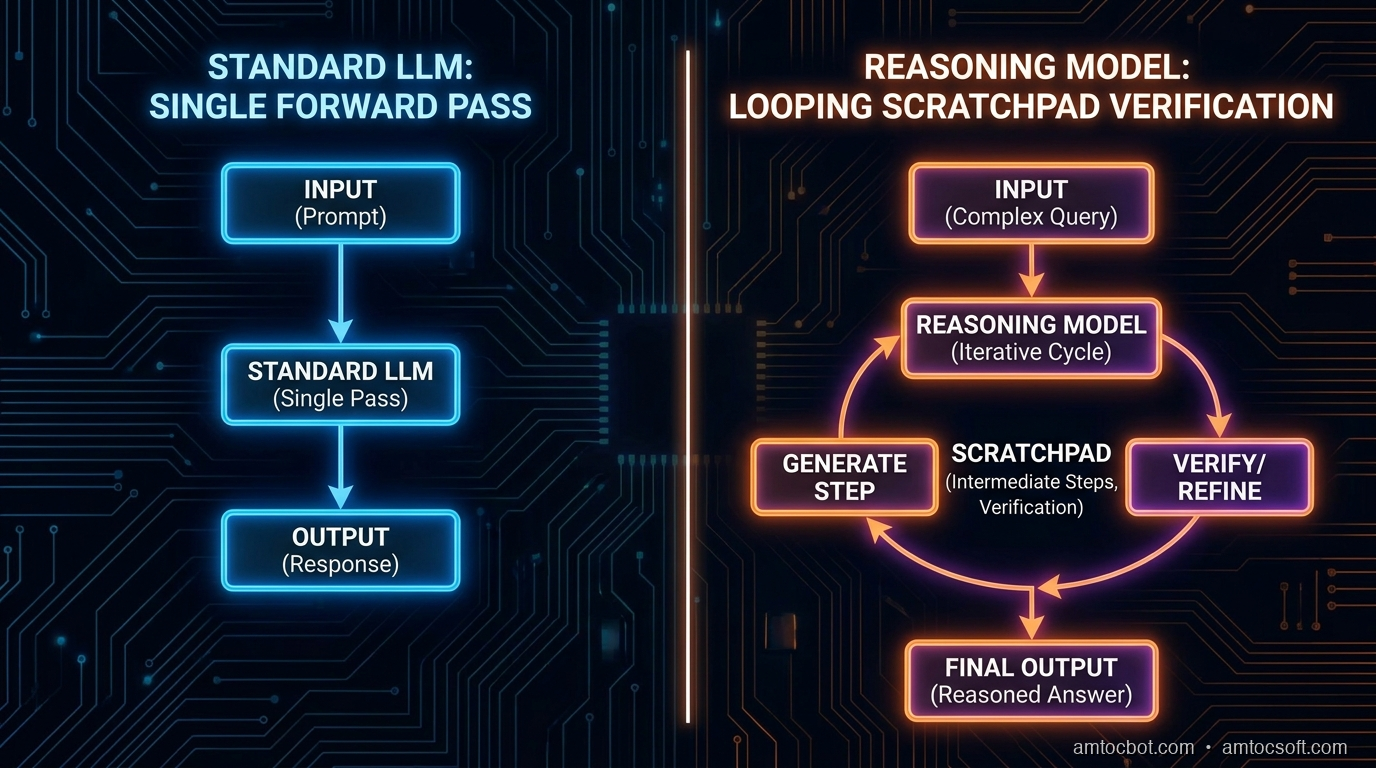
Reasoning models like OpenAI's o1/o3, DeepSeek R1, and Claude's extended thinking mode all share a common idea: give the model compute budget at inference time to generate and evaluate intermediate reasoning steps before producing a final answer.
The implementation details differ, but the pattern is consistent:
- The model generates a "scratchpad" — internal reasoning tokens that are not directly shown in the final answer
- It uses those tokens to explore multiple approaches, check work, and catch contradictions
- The final answer is conditioned on the full reasoning trace
This is sometimes called inference-time compute scaling — spending more compute during inference rather than purely during training.
OpenAI o3
o3 was the most significant reasoning-model release of early 2026. OpenAI haven't published full technical details, but from benchmarks and the o1 paper, we know:
- It was trained with reinforcement learning on verifiable outcomes (math proofs, code tests, logic puzzles) rather than supervised next-token prediction
- It uses a "think" budget that can be set low (fast, cheaper) or high (slower, more thorough)
- On ARC-AGI 2, o3 (high compute) achieved 87.5% — up from GPT-4o's 5% on the same benchmark
The practical implication: on a hard coding problem, o3 with high budget will outperform o3 with low budget. Reasoning ability is partially a function of how many tokens the model gets to think with. That's a fundamentally new tradeoff in LLM deployment.
DeepSeek R1
DeepSeek R1, released in January 2025, was the open-source reasoning model that forced the industry to take inference-time compute seriously. Critically, DeepSeek published their training recipe.
They trained R1 using GRPO (Group Relative Policy Optimisation), a variant of PPO that evaluates a group of completions against each other rather than a fixed reward model. The reward signals were:
- Format reward: does the output follow <think>...</think><answer>...</answer> structure?
- Accuracy reward: is the final answer correct (verifiable for math/code)?
No human feedback. No human-written chain-of-thought examples in the initial training. The model learned to reason by trial and error against verifiable outcomes.
The result: R1-Zero (the base RL-trained model) spontaneously developed behaviours like self-correction — pausing mid-reasoning with phrases like "Wait, I made an error..." and revising its approach. The researchers didn't program this in. It emerged from the RL process.
Claude's Extended Thinking
Anthropic's Claude 3.7 Sonnet (February 2026) and later Claude 4 introduced extended thinking: a configurable mode where the model generates a visible chain-of-thought scratchpad before its final response.
Unlike o3's opaque thinking process, Claude's extended thinking is shown to the user by default (with an option to hide it). This is both a design choice and a transparency statement — you can audit the reasoning, not just trust the answer.
Extended thinking is enabled via the API by setting thinking: {type: "enabled", budget_tokens: N}. Claude will spend up to N tokens on its scratchpad before outputting the final answer.
import anthropic
client = anthropic.Anthropic()
response = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=16000,
thinking={
"type": "enabled",
"budget_tokens": 10000 # up to 10k tokens for internal reasoning
},
messages=[{
"role": "user",
"content": "A 10×10 grid has all cells initially white. You flip all cells in row 3, then all cells in column 7, then all cells in any row that has an odd number of black cells. How many black cells remain?"
}]
)
# The response contains thinking blocks and text blocks
for block in response.content:
if block.type == "thinking":
print(f"[Thinking: {len(block.thinking)} chars]")
elif block.type == "text":
print(f"Answer: {block.text}")
Running this on the grid puzzle (a problem designed to require systematic tracking of state), the thinking block shows Claude explicitly constructing a 10×10 grid, applying each operation step by step, and verifying row parity before the final operation. The answer is correct. The same prompt without extended thinking produces a confidently wrong answer in roughly 1/10th the tokens.
The Training Mechanism: RLHF vs RL on Verifiable Rewards
Standard LLMs are typically trained with:
1. Supervised fine-tuning on human-written text
2. RLHF — human raters score outputs, those scores train a reward model, PPO updates the policy
Reasoning models shift step 2. Instead of human preference feedback (which is expensive and subjective), they use RL on verifiable signals:
- Code: does it pass the test suite?
- Math: does it match the ground-truth answer?
- Logic: does the conclusion follow from the premises under formal verification?
This is only possible for domains with objectively checkable answers. DeepSeek's bet was that math and code are rich enough to develop general reasoning capabilities, which transfer to other domains. The results suggest they were right — R1 generalises beyond math to multi-step planning and argument analysis.
The implication for developers: if you're building a domain where outputs are verifiable, reasoning models (or custom RL training on your verification signal) may be the right architectural path. If your domain is inherently subjective (creative writing, brand voice), standard RLHF or preference tuning remains dominant.
When to Use Reasoning Models (and When Not To)
Use reasoning models for:
Complex code generation or debugging. When the problem requires holding multiple constraints simultaneously — correctness, performance, security, API contract — reasoning models outperform standard models by a measurable margin. Aider's benchmark data shows o3 achieving 71.6% on SWE-bench Verified vs GPT-4o's 49.2% (Aider leaderboard, March 2026).
Multi-step planning. Tasks like "design a database schema that satisfies these 8 business constraints" benefit enormously from a model that can check constraint satisfaction before committing to an answer.
Mathematical and algorithmic reasoning. This is the canonical use case. AIME 2024 pass rates: o3 (high compute) scored 96.7%; GPT-4o scored 9.3%.
Don't use reasoning models for:
Latency-critical applications. A 47-second thinking time is fine for a batch job. It's a dealbreaker for a live chat interface.
Simple retrieval or classification. Using o3 to extract structured fields from a form is like hiring a neurosurgeon to change a lightbulb — technically capable, economically absurd.
Cost-sensitive high-volume workloads. o3 at high compute is approximately 25× the price of GPT-4o per output token (OpenAI pricing page, April 2026). For 10,000 requests/day, that difference is material.
A Gotcha I Hit in Production
I was building a compliance checker — a system that takes a contract clause and verifies it against 12 specific regulatory requirements. My first instinct was to use a reasoning model with high budget. The accuracy was excellent.
The problem: latency. The p99 was 68 seconds. Legal review workflows can tolerate that. But I'd also wired the results into a real-time UI that highlighted clauses as the user typed. 68-second lag is unusable.
The fix was a two-tier system:
1. Fast path (GPT-4o, 1-2 seconds): check whether the clause is likely compliant using a simpler prompt. Shows a preliminary green/yellow/red indicator.
2. Slow path (o3 medium budget, 8-12 seconds): runs in the background, confirms or overrides the fast-path indicator, surface detailed reasoning to the user in a collapsible "audit trail" panel.
This cut the perceived latency to ~1.5 seconds while keeping accuracy at the reasoning model level. The key insight: you don't have to choose one or the other. Use fast models for preliminary signals, slow models for verification.
Benchmarks Worth Trusting (and Some to Ignore)
Not all reasoning benchmarks are created equal.
Trust these:
- SWE-bench Verified: real GitHub issues, real test suites, no data contamination risk. As of April 2026: o3 71.6%, Claude Sonnet 4.6 49.0%, GPT-4o 38.2% (SWE-bench leaderboard).
- ARC-AGI: abstract reasoning tasks humans solve easily but LLMs typically fail. o3 high compute: 87.5%. GPT-4o: 5.3% (ARC Prize 2025 results).
- AIME 2024: AMC/AIME competition math, hard to contaminate due to limited public solutions.
Be skeptical of:
- MMLU scores for reasoning models: MMLU is multiple-choice trivia-style. Standard LLMs have near-saturated it. A 2-point MMLU improvement tells you almost nothing about reasoning capability.
- HumanEval: widely contaminated in training data. Use SWE-bench or LiveCodeBench instead.
- Self-reported benchmarks: always check whether evals use the publicly released checkpoint or a separate "eval model" that's been specifically tuned for benchmark performance.
Production Considerations
Token budget tuning matters. Don't set the thinking budget to max and call it done. Run evals at 2k, 5k, 10k, and 20k thinking tokens. For most tasks, 5k-8k tokens captures 90% of the accuracy gain at 40% of the cost of 20k. Plot accuracy vs. budget and find your knee in the curve.
Thinking tokens aren't free but they're cheaper than output tokens. On the Anthropic API, extended thinking tokens are billed at the input token rate ($3/MTok for Sonnet 4.6), not the output rate ($15/MTok). This makes generous thinking budgets more economical than they first appear.
Cache the reasoning, not just the answer. If you're running the same reasoning task repeatedly (e.g., evaluating 1,000 contracts against the same 12 rules), the system prompt and rule list can be prompt-cached, reducing costs by ~90% for the static portion. The dynamic portion (the contract clause) still incurs full cost.
# Example: prompt caching with extended thinking
response = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=8000,
thinking={"type": "enabled", "budget_tokens": 6000},
system=[{
"type": "text",
"text": "You are a compliance checker. Check clauses against these 12 rules:\n[rules here]",
"cache_control": {"type": "ephemeral"} # Cache the static rules
}],
messages=[{
"role": "user",
"content": clause_text # Only this varies per request
}]
)
Stream thinking blocks separately. The Anthropic API and OpenAI streaming API both support streaming thinking content. Stream the thinking to the client to provide progress feedback during long reasoning sessions — users can see "still thinking..." with intermediate reasoning rather than a frozen spinner.
Conclusion
Reasoning models don't replace standard LLMs — they extend the capability ceiling for tasks that require genuine multi-step deduction. The right mental model is "when does the problem require the model to check its own work?"
For routine tasks — drafting, classification, simple code completion — standard LLMs are faster and cheaper. For complex planning, algorithmic reasoning, and constraint-heavy generation, reasoning models provide accuracy gains that are hard to achieve through prompt engineering alone.
The economics will continue to shift. Inference-time compute is improving on the same curve as training compute — meaning today's "expensive reasoning" will be next year's baseline. Building your system to route intelligently between fast and slow models now means you're positioned to upgrade automatically as the cost curves drop.
Sources
- SWE-bench Leaderboard — verified benchmark for code agents (accessed April 2026)
- ARC Prize 2025 Results — ARC-AGI 2 benchmark results including o3 high-compute score
- DeepSeek R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning — DeepSeek AI, January 2025
- Anthropic Extended Thinking Docs — Claude extended thinking API reference
- OpenAI o3 System Card — OpenAI, December 2024
- Aider LLM Leaderboard — independent coding benchmark (accessed April 2026)
About the Author
Toc Am
Founder of AmtocSoft. Writing practical deep-dives on AI engineering, cloud architecture, and developer tooling. Previously built backend systems at scale. Reviews every post published under this byline.
Published: 2026-04-20 · Written with AI assistance, reviewed by Toc Am.
Get These In Your Inbox
Weekly deep-dives on AI engineering, no fluff. Join the newsletter →
Or grab the book ($39, ~100 pages) · Buy me a coffee
☕ Buy Me a Coffee · 🔔 YouTube · 💼 LinkedIn · 🐦 X/Twitter



No comments:
Post a Comment