
Generated with Higgsfield GPT Image — 16:9
Introduction
The 2025 Verizon Data Breach Investigations Report landed with a statistic that should unsettle every engineering team: 98% of breaches involve a human element. Not a misconfigured firewall. Not an unpatched library. A human — someone who clicked the wrong link, approved the wrong request, or typed a secret into the wrong field.
That number has held steady for years. And yet, the typical organizational response to security incidents is to add another tool to the CI/CD pipeline.
Tools matter. But they are not the bottleneck. The bottleneck is culture.
In 2026, most engineering organizations have nominally adopted "DevSecOps." They have Dependabot configured. They run container scans in GitHub Actions. They have a SAST tool that fails the build when it detects certain patterns. And they still get breached — because the culture around security hasn't changed. Developers still think of security as something AppSec does after the PR is merged. Security teams still think of developers as the source of problems rather than the first line of defense. And everyone treats the annual security training as a mandatory checkbox before they can get back to shipping.
This post is about closing that gap. We will cover what DevSecOps actually means when implemented with cultural intent rather than as a tool procurement exercise, what "shifting left" looks like in a real developer workflow with concrete tooling configurations, and — critically — how attackers actually bypass all of your technical controls by targeting the humans in your organization.
By the end, you should have a concrete starting point for building a security culture that makes your technical controls more effective, not less. This is the fourth post in our AI Security series; you may also want to read AI-Powered Cybersecurity (061), Deepfake Phishing and AI Attacks (062), and AI Compliance for Developers (063).
What DevSecOps Actually Means
DevSecOps was coined to make a simple argument: security belongs in the development and operations lifecycle, not outside it. The original premise was sound. The implementation has mostly been terrible.
The buzzword version of DevSecOps looks like this: a security team attends a DevOps conference, comes back with a list of tools, integrates them into the CI/CD pipeline, and declares victory. Developers are now blocked from merging unless their code passes a suite of security gates they did not design, do not understand, and cannot fix without asking AppSec. AppSec, overwhelmed by false positives, either turns down the sensitivity or becomes a perpetual review bottleneck. The result is friction without security.
The actual version of DevSecOps looks different in three critical ways.
Security is a shared responsibility, not a gate. In mature organizations, security is not something that happens to developers at the end of a pull request. It is something developers participate in actively, from the design phase onward. This means security requirements appear in tickets before a line of code is written. It means threat modeling is a design exercise, not an afterthought. It means developers know how to read a SAST finding, distinguish a true positive from a false positive, and remediate the underlying issue — not just suppress the warning.
Developers are the first line of defense. This is not rhetorical. The developer is the only person in the organization who touches the code before it ships. By the time AppSec reviews it, the cost of fixing a vulnerability has already multiplied. IBM's Systems Sciences Institute put the ratio at roughly 100:1 between finding a defect in production versus in design. Treating developers as security agents — rather than security liabilities — is the highest-leverage intervention available to any security program.
Blameless postmortems apply to security incidents. Engineering organizations that have embraced Site Reliability Engineering principles understand blameless postmortems: when something goes wrong, the goal is to understand why the system allowed it to happen, not to assign fault to an individual. This principle applies with equal force to security incidents. When a developer accidentally commits a secret to a public repository, the question is not "why did this developer do something irresponsible?" The question is: "Why does our system allow secrets to be committed? Why did no pre-commit hook catch it? Why did no CI gate flag it?" Blame drives security failures underground. Blameless culture surfaces them so they can be fixed.
Security champions programs. A security champions program designates one developer per team — typically a mid-to-senior engineer with interest in security — as a liaison between the development team and the AppSec function. Champions attend security briefings, participate in threat modeling, and serve as the first point of contact when teammates have security questions. They are not responsible for making all security decisions; they are responsible for making security accessible and removing the friction of "I need to file a ticket with AppSec to ask a basic question." Research from SANS consistently shows that organizations with active security champions programs detect vulnerabilities earlier and resolve them faster.
Generated with Higgsfield GPT Image — 16:9
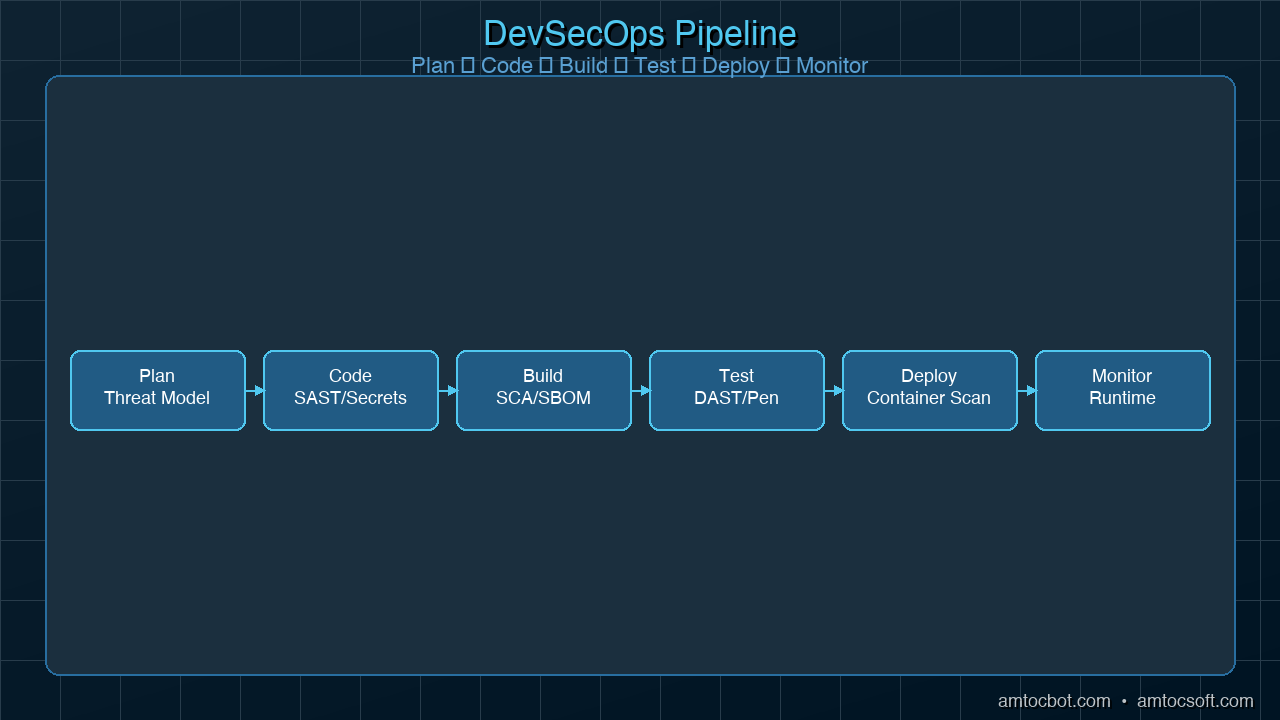
The following diagram shows how security integrates across each phase of the software development lifecycle, rather than sitting as a gate at the end:
The cycle is continuous, not linear. Every monitoring finding feeds back into the planning phase, tightening controls in response to what attackers are actually attempting.
Shifting Left: Security in the Developer Workflow
"Shift left" means moving security activities earlier in the development process — toward the left side of the timeline where changes are cheap rather than toward the right side where they are expensive. In practice, it means four concrete things: pre-commit hooks, CI/CD gates, IDE integration, and threat modeling in design.
Pre-Commit Hooks: Your First Automated Gate
Pre-commit hooks run before a commit is finalized on the developer's machine. They are the fastest possible feedback loop — the developer learns about a problem before it ever reaches a remote repository. The two most important categories to enforce at commit time are secrets detection and lightweight static analysis.
Secrets detection prevents API keys, tokens, database passwords, and private keys from ever entering version control. Two leading tools are git-secrets (AWS) and detect-secrets (Yelp). The following .pre-commit-config.yaml configures both alongside semgrep for lightweight SAST:
# .pre-commit-config.yaml
repos:
# Secrets detection with detect-secrets
- repo: https://github.com/Yelp/detect-secrets
rev: v1.4.0
hooks:
- id: detect-secrets
args:
- '--baseline'
- '.secrets.baseline'
exclude: |
(?x)^(
.*\.lock$|
.*package-lock\.json$|
.*\.min\.js$
)$
# General pre-commit checks
- repo: https://github.com/pre-commit/pre-commit-hooks
rev: v4.5.0
hooks:
- id: check-merge-conflict
- id: detect-private-key
- id: check-added-large-files
args: ['--maxkb=1000']
- id: end-of-file-fixer
- id: trailing-whitespace
# Semgrep SAST — runs a targeted ruleset locally
- repo: https://github.com/returntocorp/semgrep
rev: v1.56.0
hooks:
- id: semgrep
args:
- '--config=auto'
- '--error'
- '--severity=ERROR'
# Skip low-signal rules to reduce noise
- '--exclude-rule=generic.secrets.security.detected-generic-secret.detected-generic-secret'
pass_filenames: false
Initialize the detect-secrets baseline on a new repository with:
# Create initial baseline (scan existing codebase, mark known non-secrets)
detect-secrets scan > .secrets.baseline
# Install hooks for the project
pre-commit install
# Run against all existing files (one-time audit)
pre-commit run --all-files
The baseline file is committed to the repository. When new developers clone the repo, pre-commit install wires up the hooks on their machine. The secrets baseline records which patterns in existing files are known-safe, so the hook does not flag things like example credentials in documentation.
CI/CD Gates: Defense in Depth
Pre-commit hooks can be bypassed with --no-verify. CI/CD gates cannot. The following GitHub Actions workflow runs dependency scanning with Snyk, container image scanning with Trivy, and a full semgrep scan on every pull request:
# .github/workflows/security-scan.yml
name: Security Scan
on:
pull_request:
branches: [main, develop]
push:
branches: [main]
permissions:
contents: read
security-events: write # Required for SARIF upload to GitHub Security tab
pull-requests: write # Required for PR comments
jobs:
dependency-scan:
name: Dependency Vulnerability Scan
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- name: Run Snyk to check for vulnerabilities
uses: snyk/actions/node@master
env:
SNYK_TOKEN: ${{ secrets.SNYK_TOKEN }}
with:
args: >
--severity-threshold=high
--sarif-file-output=snyk.sarif
continue-on-error: true # Don't block on first run — triage first
- name: Upload Snyk SARIF to GitHub Security
uses: github/codeql-action/upload-sarif@v3
with:
sarif_file: snyk.sarif
if: always()
container-scan:
name: Container Image Scan (Trivy)
runs-on: ubuntu-latest
needs: dependency-scan
steps:
- uses: actions/checkout@v4
- name: Build Docker image for scanning
run: docker build -t app:${{ github.sha }} .
- name: Run Trivy container scan
uses: aquasecurity/trivy-action@master
with:
image-ref: app:${{ github.sha }}
format: sarif
output: trivy-results.sarif
severity: 'CRITICAL,HIGH'
exit-code: '1' # Fail on CRITICAL/HIGH findings
ignore-unfixed: true # Skip vulns with no available fix
- name: Upload Trivy SARIF to GitHub Security
uses: github/codeql-action/upload-sarif@v3
with:
sarif_file: trivy-results.sarif
if: always()
sast-scan:
name: Static Analysis (Semgrep)
runs-on: ubuntu-latest
container:
image: semgrep/semgrep
steps:
- uses: actions/checkout@v4
- name: Run Semgrep full ruleset
run: |
semgrep \
--config=p/owasp-top-ten \
--config=p/secrets \
--config=p/supply-chain \
--sarif \
--output=semgrep.sarif \
--severity=WARNING
env:
SEMGREP_APP_TOKEN: ${{ secrets.SEMGREP_APP_TOKEN }}
- name: Upload Semgrep SARIF
uses: github/codeql-action/upload-sarif@v3
with:
sarif_file: semgrep.sarif
if: always()
- name: Comment findings on PR
uses: github/codeql-action/analyze@v3
if: github.event_name == 'pull_request'
The SARIF upload integration means findings appear natively in the GitHub Security tab and as inline PR comments. Developers see security findings in the same interface where they review code — reducing the friction of "I need to go to a separate dashboard to understand what this scan found."
IDE Plugins: Real-Time Feedback
The fastest feedback loop of all is finding a vulnerability as it is typed. Two plugins are worth standardizing across your engineering organization:
- Snyk Security (VS Code, JetBrains): Scans dependencies and code in real time. Highlights vulnerable imports with inline severity indicators and links to remediation guidance.
- Semgrep (VS Code): Runs configured rulesets as you type. Particularly useful for organization-specific rules — you can write a Semgrep rule that catches patterns unique to your codebase (e.g., "never call this deprecated internal auth function directly").
Threat Modeling in Design
The highest-leverage shift-left practice does not involve any tool. It involves adding a structured security conversation to the design phase of every significant feature.
STRIDE is the most widely used threat modeling framework for application security. For each component in a system design, it asks whether the component is exposed to: Spoofing (impersonation), Tampering (data modification), Repudiation (denying actions), Information Disclosure, Denial of Service, or Elevation of Privilege. A 30-minute STRIDE exercise on a design doc will surface more actionable security findings than a week of post-hoc scanning, because it catches architectural problems that no scanner can detect.
The following diagram shows how security gates map to each SDLC phase, moving from design-time threat modeling through to production monitoring:
STRIDE / PASTA] SR[Security Requirements
in Tickets] end subgraph Code ["Code Phase"] PC[Pre-Commit Hooks
detect-secrets, semgrep] IDE[IDE Plugins
Snyk, Semgrep] end subgraph Build ["Build / CI Phase"] SAST[SAST Gate
Semgrep + OWASP rules] SCA[SCA Gate
Snyk / Dependabot] end subgraph Test ["Test Phase"] CT[Container Scan
Trivy] DAST[DAST
OWASP ZAP] IaC[IaC Scan
Checkov / tfsec] end subgraph Release ["Release / Deploy"] SEC[Security Sign-off
Champion Review] SM[Secrets Mgmt
Vault / AWS SM] end subgraph Operate ["Operate / Monitor"] SIEM[SIEM Alerts
CloudTrail / Splunk] WAF[WAF + Bot Mgmt] end TM --> SR --> PC --> IDE --> SAST --> SCA --> CT --> DAST --> IaC --> SEC --> SM --> SIEM --> WAF style Design fill:#E8F4FD,stroke:#4A90D9 style Code fill:#EDF7ED,stroke:#5BA65B style Build fill:#EDF7ED,stroke:#5BA65B style Test fill:#FFF8E7,stroke:#E8A838 style Release fill:#FFF8E7,stroke:#E8A838 style Operate fill:#FDECEA,stroke:#D9534F
The key insight is that each gate catches a different class of problem, and the classes compound: threat modeling catches architectural flaws, pre-commit catches secrets, SAST catches code patterns, SCA catches dependency CVEs, container scanning catches OS-level vulnerabilities, and DAST catches runtime issues. No single gate is sufficient, and no combination of gates replaces a security-aware engineering culture.
The Human Layer: Social Engineering in 2026
Here is the uncomfortable reality that a perfectly configured DevSecOps pipeline cannot address: the most reliable attack vector against a well-defended organization is the person with legitimate access.
Attackers know this. The economics are brutal. Exploiting a zero-day vulnerability requires significant technical expertise, costs tens of thousands of dollars on the underground market, and works for a limited window before it is patched. Sending a convincing phishing email costs cents, requires no technical expertise, and works against organizations regardless of how mature their security tooling is.
The attack surface is not your code. It is your people.
AI-Personalized Phishing
In 2024 and 2025, we documented the emergence of AI-personalized phishing at scale — a development covered in depth in post 062 of this series. The key shift: phishing campaigns historically relied on mass distribution of identical lures, making detection via pattern matching tractable. AI-generated phishing produces individually personalized messages drawn from public LinkedIn profiles, GitHub contributions, company blog posts, and OSINT databases.
A developer who recently merged a PR to the payments service receives an email, apparently from a trusted vendor, referencing that specific work and asking them to review a new API authentication specification. The tone matches the vendor's communication style. The link leads to a convincing credential harvest page. No technical control in your CI/CD pipeline stops this.
Vishing and Smishing
Voice phishing (vishing) has seen a significant resurgence, partly driven by AI voice cloning. An attacker who has harvested a target's contact information — readily available via data broker databases — can call a help desk impersonating an employee and request a password reset, citing urgency. Smishing (SMS phishing) follows the same pattern with a different channel. Multi-factor authentication mitigates some of this, but cannot stop an attacker who social engineers a help desk into bypassing MFA procedures.
Insider Threats
The insider threat is not primarily malicious employees. It is well-intentioned employees making poor decisions under pressure — sharing credentials with a colleague to "speed things up," forwarding a sensitive document to a personal email to work from home, installing an unapproved tool to solve an immediate problem. These behaviors are rational from the individual's perspective. They become security incidents when the credential is compromised, the personal email account is breached, or the unapproved tool exfiltrates data.
Vendor and Supply Chain Social Engineering
The SolarWinds attack, the 3CX supply chain attack, and numerous subsequent incidents have made clear that attackers increasingly target vendors and service providers as an indirect route into well-defended targets. Social engineering a developer at a smaller vendor with weaker security controls is often easier than attacking the target directly. From a culture perspective, this means your supply chain security posture is only as good as your third-party risk management and the security culture you require from vendors.
The trust exploitation model underlying all of these attacks is the same: attackers do not break in, they log in — using credentials, session tokens, or social authority borrowed from legitimate users. Your technical controls assume attackers are outsiders presenting invalid credentials. The human layer determines how often legitimate-seeming requests from actual attackers pass through.

Generated with Higgsfield GPT Image — 16:9
Building the Human Layer of Defense
If the human layer is the primary attack surface, then the primary defensive investment should be in developing the human layer. This is not a novel insight — the information security community has said it for decades. The consistent failure to act on it is organizational, not intellectual: security awareness is treated as a cost center, measured by completion rates rather than behavioral change, and starved of investment relative to tool procurement.
Effective human-layer defense programs share five characteristics.
Continuous Simulation Over Annual Training
Annual security awareness training has the weakest evidence base of any security investment. Employees sit through a 45-minute video, pass a multiple-choice quiz, and forget the content within 60 days. The checkbox is checked, the compliance requirement is satisfied, and the phishing click rate remains unchanged.
What works is continuous, simulated training with immediate feedback. Phishing simulation platforms (KnowBe4, Proofpoint Security Awareness, Cofense) send realistic phishing lures to employees and immediately redirect anyone who clicks to a brief training module explaining what they fell for. The critical design principle is immediacy: the training occurs at the moment of failure, when the cognitive connection between the action and the risk is strongest.
Organizations running quarterly phishing simulations typically see click rates decline from an industry-average 15-20% at baseline to under 5% within a year. The measurement is the mechanism: when employees know simulations happen, and that clicking results in a training experience rather than a reprimand, they develop a reflex of scrutiny rather than a reflex of compliance.
Security Champions: Proximity to the Team
A central AppSec team cannot scale to the needs of a large engineering organization. A security team of five cannot provide meaningful security guidance to fifty development teams. Security champions solve this through distribution: by training one security-minded developer per team and empowering them with the knowledge and authority to raise security concerns, you create a security presence in every standup, every design review, and every PR cycle.
Effective security champions programs include:
- Dedicated training time: champions attend AppSec conferences, take certifications, and participate in internal security guilds.
- Clear scope: champions are security advocates and escalation paths, not security gatekeepers. They should not be blamed when their team ships a vulnerability — their role is to raise the floor, not to be personally responsible for every decision.
- Cross-team visibility: a monthly security champions meeting creates a network where common issues can be discussed and addressed systematically rather than solved redundantly by each team in isolation.
- Recognition: champions receive visible credit in performance reviews and public acknowledgment. Security work that is invisible becomes a career penalty; making it visible makes it a career accelerator.
Blameless Reporting Culture
The single most effective way to suppress security intelligence in an organization is to punish reporters. If a developer who accidentally commits a secret to a public repository is publicly shamed or faces formal discipline, every other developer in the organization learns to hide their mistakes. Security incidents go unreported. Near-misses disappear. The organization loses its best source of information about where controls are failing.
Blameless reporting means: when someone reports a security incident — whether they caused it or discovered it — the response is "thank you for telling us, let's fix it and understand how to prevent it" rather than "who is responsible for this?" This requires active modeling from leadership. The first time a VP handles a security incident blamefully, the message is set for the entire organization regardless of what the policy document says.
Practical mechanisms:
- Anonymous reporting channels (separate from standard incident tickets) for reporting concerns without fear of identification.
- Explicit "bug bounty" framing for internal reports: celebrate the person who found the credential in the log file before an attacker did.
- Post-incident communications that focus on systemic causes, not individual failures.
Clear Escalation Paths
One reason security incidents go unreported is that employees do not know who to tell or fear that reporting will expose them to undefined consequences. A clear, publicized escalation path removes both barriers.
The path should be: employee → security champion → AppSec team → CISO or security leadership, with defined response time SLAs at each level and explicit protection for reporters. Every employee should be able to answer "who do I tell if I think something is wrong?" without having to think about it.
Tabletop Exercises
Tabletop exercises simulate security incidents in a discussion format. The security team presents a scenario ("we have received an alert that a developer's credentials are being used from two geographically distant locations simultaneously — walk us through your response"), and the relevant teams work through their response in real time.
Tabletops surface gaps that documentation reviews miss: the escalation path that worked in theory turns out to require a person who is on vacation; the incident response runbook assumes a tool that has been decommissioned; the communication plan has no provision for an incident that occurs outside business hours. These gaps are cheap to find in a tabletop and expensive to discover during an actual incident.
The following diagram shows the security champion network and how information and authority flow between the organization's security layers:
Strategy, Risk Decisions, Escalations"] AppSec["AppSec Team
Tooling, Standards, Incident Response, Training"] subgraph eng1 ["Team 1 — Platform"] C1["Security Champion
(Senior Dev)"] D1A["Developer"] D1B["Developer"] D1C["Developer"] end subgraph eng2 ["Team 2 — Payments"] C2["Security Champion
(Senior Dev)"] D2A["Developer"] D2B["Developer"] end subgraph eng3 ["Team 3 — Mobile"] C3["Security Champion
(Senior Dev)"] D3A["Developer"] D3B["Developer"] D3C["Developer"] end subgraph eng4 ["Team 4 — Data"] C4["Security Champion
(Mid Dev)"] D4A["Developer"] D4B["Developer"] end CISO <--> AppSec AppSec <--> C1 AppSec <--> C2 AppSec <--> C3 AppSec <--> C4 C1 <--> D1A C1 <--> D1B C1 <--> D1C C2 <--> D2A C2 <--> D2B C3 <--> D3A C3 <--> D3B C3 <--> D3C C4 <--> D4A C4 <--> D4B style CISO fill:#D9534F,color:#fff style AppSec fill:#E8A838,color:#fff style C1 fill:#5BA65B,color:#fff style C2 fill:#5BA65B,color:#fff style C3 fill:#5BA65B,color:#fff style C4 fill:#5BA65B,color:#fff
The champion layer is the critical translation layer. Without it, AppSec communicates to developers primarily through automated blocking mechanisms — scan failures, policy gates, rejected PRs — which creates adversarial dynamics. With it, security guidance travels through trusted colleagues who speak the same technical language and share the same delivery pressures.
Measuring Security Culture
Security culture is not a soft concept. It is measurable, and measuring it is essential to improving it. Without measurement, security programs drift toward activity metrics (how many trainings delivered, how many tools deployed) that say nothing about whether the culture is actually more secure.
The metrics that matter fall into two categories: lagging indicators that tell you how your controls performed, and leading indicators that tell you how your culture is evolving.
Lagging Indicators
Mean Time to Detect (MTTD): The average time between when a security incident begins and when it is detected by your organization. Industry median for breach detection in 2025 was 197 days (IBM Cost of a Data Breach Report). Every day in that number is an attacker with undetected access. A declining MTTD is a signal that your monitoring and reporting culture is improving.
Mean Time to Respond (MTTR): From detection to containment. This measures the operational efficiency of your incident response, and reflects whether your escalation paths, runbooks, and team training are working.
Vulnerability Fix SLA Compliance: Given defined SLAs for remediating vulnerabilities by severity (e.g., critical findings fixed within 72 hours, high within 14 days), what percentage of findings are resolved within SLA? Low compliance indicates either tooling problems (too many false positives drowning real findings) or cultural problems (security remediation is deprioritized relative to feature work).
Security Debt Ratio: The ratio of open vulnerability findings to total code surface — a rough measure of whether security debt is accumulating faster than it is being repaid. An increasing ratio over time indicates the security program is losing ground even if absolute finding counts appear stable.
Leading Indicators
Phishing Click Rate Over Time: The most direct measure of security awareness program effectiveness. Track cohort-by-cohort across simulation campaigns, broken down by team and role. A declining click rate indicates the training is working. A flat or increasing rate indicates it is not.
Percentage of Teams with Active Security Champions: Coverage is a prerequisite to culture. If 60% of teams have champions and 40% do not, the 40% are operating without a security proximity layer — and incidents from those teams will reflect it.
Near-Miss Report Rate: The number of security near-misses voluntarily reported per quarter. An increasing rate is a positive signal: it means employees trust the reporting culture and believe reporting is worthwhile. A rate near zero indicates the blameless culture is not working or is not trusted.
Threat Model Coverage: What percentage of new features shipped in the last quarter included a formal threat modeling exercise? This is a measure of whether shift-left is actually happening or whether "threat modeling is a design phase activity" exists only in documentation.
OKRs for Security Culture
Security metrics translate naturally into OKRs. An example for a quarter:
Objective: Embed security into every team's development workflow.
- KR1: Pre-commit hooks deployed to 100% of repositories (currently 65%)
- KR2: Security champion coverage reaches 90% of engineering teams (currently 70%)
- KR3: Phishing click rate reduced from 12% to under 6% across Q2 simulations
- KR4: Mean time to remediate critical findings reduced from 8 days to 48 hours
OKRs at this level connect security culture investments directly to measurable outcomes, making them legible to engineering and product leadership in the same language they use for feature delivery. Security stops being "the department that blocks things" and becomes "the program that has committed to these outcomes and is tracking them publicly."
Conclusion
Security culture is a multiplier. Every technical control you deploy — pre-commit hooks, SAST gates, container scanning, MFA, WAF rules — performs better when the humans operating the system understand why those controls exist, have the skills to engage with their findings meaningfully, and feel empowered to raise concerns without fear.
The inverse is also true. No technical control is sufficient in an organization where developers suppress findings because raising them creates friction, where security is seen as an external team's responsibility rather than a shared one, and where the annual security training is something to be completed as quickly as possible before the real work resumes.
The shift that makes DevSecOps work is not buying a different tool. It is treating security as part of engineering practice rather than as a compliance overlay on top of it. That shift is harder than tool procurement. It requires leadership commitment, sustained investment in developer education, and the organizational patience to build culture over quarters rather than deploying it in a sprint.
The architecture is straightforward: automate the controls that can be automated, instrument the metrics that tell you how the culture is performing, build the champion network that distributes security knowledge across teams, and create the psychological safety that makes reporting possible. These investments compound. An organization that consistently executes them is dramatically harder to breach than one with superior tools and no culture to operate them effectively.
This post is part of our AI Security series. For the technical threat landscape, see AI-Powered Cybersecurity (061). For the social engineering attack vectors that bypass technical controls, see Deepfake Phishing and AI Attacks (062). For the regulatory environment your security program needs to satisfy, see AI Compliance for Developers (063).
Published by AmtocSoft Tech Insights — amtocsoft.blogspot.com
About the Author
Toc Am
Founder of AmtocSoft. Writing practical deep-dives on AI engineering, cloud architecture, and developer tooling. Previously built backend systems at scale. Reviews every post published under this byline.
Published: 2026-04-12 · Written with AI assistance, reviewed by Toc Am.
Get These In Your Inbox
Weekly deep-dives on AI engineering, no fluff. Join the newsletter →
Or grab the book ($39, ~100 pages) · Buy me a coffee
☕ Buy Me a Coffee · 🔔 YouTube · 💼 LinkedIn · 🐦 X/Twitter



No comments:
Post a Comment