
Generated with Higgsfield GPT Image — 16:9
Introduction
On August 1, 2024, the EU AI Act entered into force. By February 2025, the rules governing general-purpose AI models (GPAI) were live. As of August 2026 — the full enforcement deadline — any organization deploying high-risk AI systems inside the European Union must demonstrate documented compliance or face fines of up to €30 million, or 6% of global annual turnover.
That deadline is no longer theoretical. It is this year.
Meanwhile, in the United States, NIST released version 1.0 of its AI Risk Management Framework in January 2023, and federal agencies began mandating alignment with it for government contractors. ISO 42001, the international standard for AI management systems, published in December 2023. Boards of directors at Fortune 500 companies are now asking CTOs to explain their AI governance posture — not as a compliance exercise, but as a material risk disclosure.
For most engineering teams, this has arrived faster than expected. Three years ago, "AI governance" sounded like something legal and compliance departments handled after the fact. Today, it is a pre-deployment gate, a procurement requirement, and in some sectors a legal prerequisite to operating at all.
The uncomfortable truth is that the frameworks are complex, often written by lawyers for lawyers, and translate poorly into engineering terms. Most developer guides to AI compliance are either too high-level to be actionable ("document your data pipelines!") or too narrow in scope to address the real scope of what the EU AI Act requires. Engineers implementing RAG pipelines, fine-tuned classifiers, or agentic systems need concrete answers: Does this trigger high-risk classification? What do I actually need to build? What documentation is required before we ship?
This guide answers those questions directly. It covers what the major regulatory frameworks require, how to classify your systems correctly, what you must implement for high-risk systems, and how to integrate compliance into your engineering workflow without making it a bureaucratic nightmare.
The Regulatory Landscape
Four frameworks dominate the conversation in 2026, and while they overlap significantly, each has a distinct scope and jurisdiction. Understanding what each requires — and how they interact — is the foundation of any practical compliance strategy.
EU AI Act: Risk-Tiered Regulation
The EU AI Act is the world's first comprehensive horizontal AI regulation. It applies not just to EU companies, but to any company deploying AI systems whose outputs are used in the EU — which in practice means most large technology companies globally.
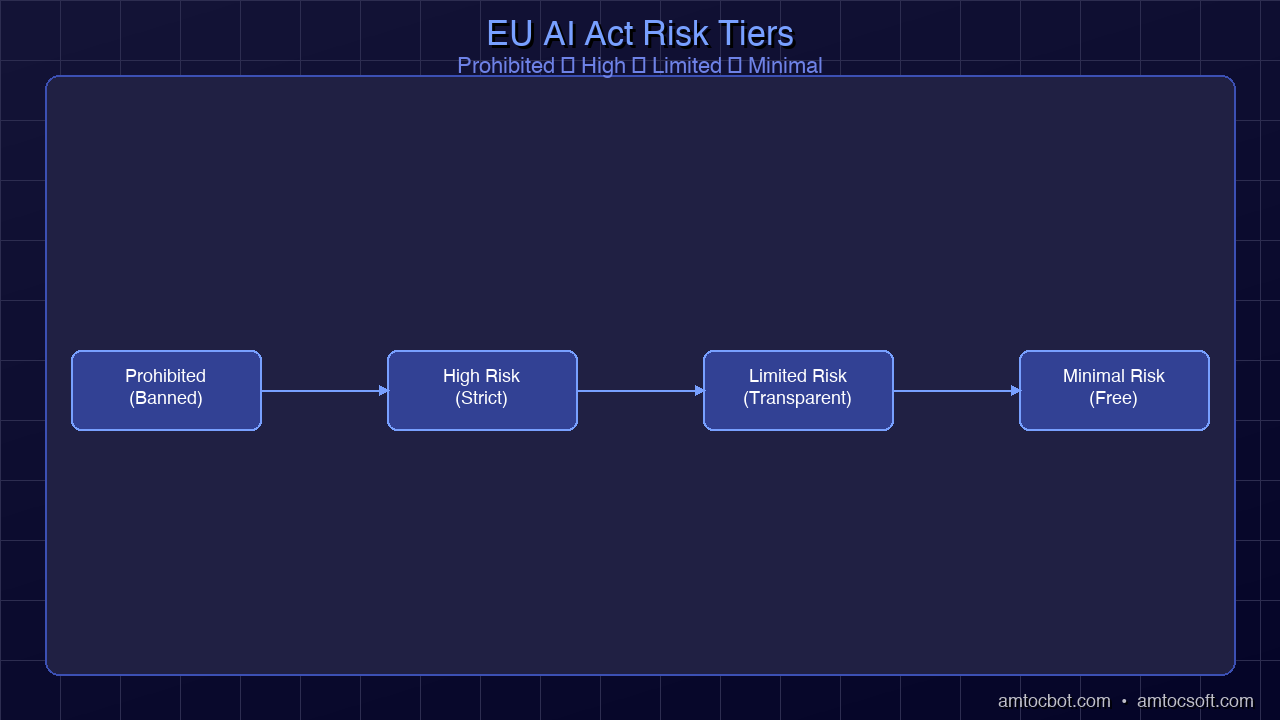
The Act organizes AI systems into four risk tiers:
Unacceptable Risk (Prohibited): These systems are banned outright. The list includes social scoring systems operated by public authorities, real-time remote biometric identification in public spaces (with narrow law enforcement exceptions), AI systems that exploit vulnerable groups, and subliminal manipulation techniques. These prohibitions took effect in February 2025.
High Risk: The category that will consume most engineering compliance effort. High-risk AI systems are permitted but subject to extensive pre-market requirements. The full list lives in Annex III of the Act and covers eight domains: biometric identification and categorization, critical infrastructure management, educational access and assessment, employment and worker management, access to essential private and public services, law enforcement, migration and border control, and administration of justice. High-risk rules fully apply as of August 2026.
Limited Risk: Primarily transparency obligations. AI systems interacting with humans (chatbots, virtual assistants) must disclose that they are AI. Deepfake generators must label output. These are relatively lightweight requirements.
Minimal Risk: Spam filters, AI-enabled video games, recommendation systems — no mandatory requirements, though the Act encourages following voluntary codes of conduct.
General Purpose AI Models (GPAI): A separate tier added to address foundation models. GPAI providers with over 10^25 FLOPs training compute face additional systemic risk requirements. All GPAI providers must publish technical documentation and a summary of training data. These rules took effect in August 2025.
Key enforcement dates to internalize:
- August 2024: Act enters into force
- February 2025: Prohibited systems rules apply; GPAI rules apply
- August 2026: High-risk system requirements fully apply (this is now)
- August 2027: High-risk systems already on the market before August 2026 get a grace period extension in some categories
NIST AI RMF: The US Standard
The National Institute of Standards and Technology AI Risk Management Framework (NIST AI RMF) is voluntary at the federal level but has become a de facto standard for US government contractors, financial institutions, and healthcare organizations. Unlike the EU AI Act, it is not sector-specific — it is a process framework.
The RMF organizes AI risk management into four functions: GOVERN, MAP, MEASURE, and MANAGE. We cover implementation of these in the NIST section below.
ISO 42001: AI Management Systems
Published December 2023, ISO 42001 is to AI what ISO 27001 is to information security: an auditable management system standard. Organizations can pursue certification, which increasingly appears as a procurement requirement in enterprise contracts. ISO 42001 aligns closely with both the EU AI Act and NIST RMF in its requirements for documented policies, roles, and continuous improvement processes.
US Executive Orders and Sector Rules
Executive Order 14110 (October 2023) directed federal agencies to establish standards for AI safety and security, including mandatory red-teaming for dual-use AI systems and reporting requirements for frontier model training runs. The AI Safety Institute within NIST coordinates this work. Sector-specific rules have followed: the FDA has published guidance on AI/ML-based software as a medical device; banking regulators have issued guidance on model risk management that explicitly covers AI. If your system operates in a regulated sector, expect sector rules to layer on top of the horizontal frameworks.
SOC 2 and AI
Auditors conducting SOC 2 Type II reviews are now explicitly asking about AI governance as part of the common criteria. Trust service criteria CC6 (logical and physical access controls) and CC7 (system operations) now include questions about AI-generated decisions and their oversight mechanisms. If your product is AI-powered and you hold SOC 2 certification, expect your next renewal to include questions about model risk, training data governance, and human override mechanisms.
Generated with Higgsfield GPT Image — 16:9
What Makes a System "High Risk"?
This is the classification question most engineering teams get wrong, and the consequences of misclassification run in both directions. Over-classify and you build expensive compliance infrastructure for systems that don't require it. Under-classify and you ship a non-compliant high-risk system.
The EU AI Act's Annex III defines high-risk AI through eight use-case categories. The key insight is that classification is based on use case and context of deployment, not on the underlying technology. A large language model is not inherently high-risk. That same LLM used to generate resume screening decisions for a Fortune 500 company's hiring process is high-risk.
The eight Annex III categories are:
- Biometric identification and categorization: Real-time or post-hoc identification of natural persons from biometric data. Note that emotion recognition systems fall here.
- Critical infrastructure: AI managing or operating road traffic, water, gas, electricity, heating, internet infrastructure.
- Education and vocational training: Systems determining access to educational institutions, grading, or evaluating students.
- Employment and worker management: CV screening, hiring decision support, task allocation, performance monitoring, promotion decisions.
- Essential private and public services: Credit scoring, insurance risk assessment, benefits eligibility assessment, emergency services dispatch.
- Law enforcement: Risk assessment for criminal recidivism, polygraph equivalents, evidence evaluation, profiling.
- Migration, asylum, border control: Risk assessment, document examination, application examination.
- Administration of justice: AI assisting courts in legal research, fact-finding, or decision-making.
Common classification mistakes developers make:
Mistake 1: Treating "decision support" as lower risk than "automated decision." The Act does not make this distinction. A system that generates a recommended credit score for a human loan officer to review is high-risk under category 5, the same as a system that automatically approves or denies loans.
Mistake 2: Misreading "biometric" to mean only faces. Biometric data includes gait analysis, voice patterns, behavioral patterns, and physiological measurements. A workplace productivity monitoring tool that tracks typing patterns to flag underperformance hits both category 1 (biometric) and category 4 (employment management).
Mistake 3: Assuming B2B products are out of scope. If your B2B product is used by customers to make high-risk decisions, your product is high-risk. You cannot pass the compliance burden to your customers by putting it in a contract. You are the provider; the requirements apply to you.
Mistake 4: Ignoring the GPAI interaction layer. If your product wraps a GPAI provider and uses it to make high-risk decisions, both the GPAI provider and your system have obligations. You need to understand what your provider's documentation covers and what gaps you need to fill.
What Developers Must Actually Implement
For high-risk systems, Articles 9 through 15 of the EU AI Act define mandatory technical and organizational measures. Here is a concrete breakdown of each requirement and what it means in practice.
1. Risk Management System (Article 9)
You must establish, implement, document, and maintain a risk management system throughout the AI system's entire lifecycle. This is not a one-time risk assessment before launch — it is a continuous process.
In practice: Create a living risk register for your AI system. Document identified risks, their likelihood and severity, the controls you have implemented, and how you verify those controls are working. This needs to be version-controlled and updated with every significant model change, data drift event, or production incident.
2. Data Governance and Management (Article 10)
Training, validation, and test datasets must meet quality criteria relevant to the intended purpose. You must document:
- Data origin, collection method, and preparation steps
- Bias examination and mitigation measures
- How datasets meet the stated use case requirements
- Data handling practices for personal data
In practice: Implement model cards and dataset cards. Run bias evaluations before each model version release. Log training data lineage. For systems using personal data, ensure you have a documented lawful basis and Data Protection Impact Assessment (DPIA).
Model Card Template (YAML frontmatter):
# model-card.yaml
model_id: "credit-risk-classifier-v2.3"
model_type: "gradient_boosted_classifier"
intended_use: "Credit risk assessment for personal loan applications"
out_of_scope_use:
- "Employment screening"
- "Insurance underwriting"
- "Any use outside EU-regulated lending context"
training_data:
sources:
- name: "Internal loan performance dataset"
date_range: "2019-01-01 to 2024-12-31"
records: 2400000
geographic_scope: "EU member states"
preprocessing:
- "Missing value imputation via median (numerical) and mode (categorical)"
- "Feature scaling: standard normalization"
- "Protected attribute removal: age, gender, nationality excluded from features"
bias_evaluation:
method: "Disparate impact analysis across age cohorts and geographic regions"
last_run: "2026-03-15"
result: "DI ratio 0.87 across all protected cohorts (threshold: >0.80)"
performance:
metrics:
auc_roc: 0.847
precision_at_threshold_0_5: 0.79
recall_at_threshold_0_5: 0.81
false_positive_rate: 0.19
evaluation_dataset: "Holdout set, 2025 Q4, n=48000"
known_limitations:
- "Lower recall for applicants with < 12 months credit history"
- "Performance degrades for applications from regions with < 5000 training samples"
human_oversight:
override_mechanism: "Loan officer can override any automated decision"
override_rate_target: "< 5% of decisions escalated"
escalation_triggers:
- "Decision confidence < 0.65"
- "Applicant-requested review"
- "Edge case detection (out-of-distribution features)"
regulatory_compliance:
eu_ai_act_classification: "High Risk — Annex III, Category 5b (credit scoring)"
risk_management_version: "v1.4"
last_conformity_assessment: "2026-02-20"
dpia_reference: "DPIA-2025-CR-047"
contacts:
model_owner: "credit-risk-team@company.com"
compliance_contact: "ai-governance@company.com"
last_updated: "2026-04-01"
version: "2.3.0"
3. Technical Documentation (Article 11)
Before placing a high-risk AI system on the market, you must prepare comprehensive technical documentation demonstrating that the system meets the Act's requirements. Annex IV specifies the required contents: system description and purpose, development process, training data, monitoring plan, risk management records.
In practice: Maintain a System Card alongside your model card. The system card describes the full sociotechnical system — not just the model, but the input pipeline, deployment context, human oversight mechanisms, and feedback loops.
4. Transparency and Audit Logging (Article 13)
High-risk systems must have logging capabilities enabling post-hoc audit of their operation. Logs must cover the period during which the system was in use and must capture enough information to reconstruct any decision.
Audit Logging Pattern (Python):
import json
import hashlib
import time
from dataclasses import dataclass, asdict
from typing import Any, Optional
from datetime import datetime, timezone
import uuid
@dataclass
class AIDecisionRecord:
"""Audit log entry for high-risk AI decisions per EU AI Act Article 13."""
decision_id: str
timestamp_utc: str
system_id: str
system_version: str
request_hash: str # SHA-256 of input features (for reproducibility without storing PII)
decision_output: str # The decision rendered
confidence_score: float
model_version: str
input_feature_count: int
out_of_distribution: bool # Did OOD detector fire?
human_override: bool # Was this decision overridden?
override_reason: Optional[str]
processing_time_ms: int
session_context: dict # Business context (loan ID, operator ID, etc.)
class AIAuditLogger:
"""
Compliance-grade audit logger for high-risk AI systems.
Writes immutable, tamper-evident decision records.
Complies with EU AI Act Article 13 logging requirements.
"""
def __init__(self, system_id: str, system_version: str, storage_backend):
self.system_id = system_id
self.system_version = system_version
self.storage = storage_backend # e.g., append-only S3, BigQuery, Postgres with audit trigger
def _hash_features(self, features: dict) -> str:
"""Hash input features for reproducibility without storing PII."""
canonical = json.dumps(features, sort_keys=True, default=str)
return hashlib.sha256(canonical.encode()).hexdigest()
def log_decision(
self,
features: dict,
decision: str,
confidence: float,
model_version: str,
out_of_distribution: bool,
session_context: dict,
processing_start: float,
) -> str:
"""
Log a single AI decision. Returns decision_id for downstream tracking.
Call this for every inference that produces a consequential output.
"""
decision_id = str(uuid.uuid4())
processing_time_ms = int((time.monotonic() - processing_start) * 1000)
record = AIDecisionRecord(
decision_id=decision_id,
timestamp_utc=datetime.now(timezone.utc).isoformat(),
system_id=self.system_id,
system_version=self.system_version,
request_hash=self._hash_features(features),
decision_output=decision,
confidence_score=round(confidence, 6),
model_version=model_version,
input_feature_count=len(features),
out_of_distribution=out_of_distribution,
human_override=False, # Updated later if override occurs
override_reason=None,
processing_time_ms=processing_time_ms,
session_context=session_context,
)
self.storage.write(asdict(record))
return decision_id
def log_override(self, decision_id: str, operator_id: str, reason: str):
"""
Record that a human operator overrode an AI decision.
Must be called whenever an override occurs for complete audit trail.
"""
override_record = {
"type": "override",
"decision_id": decision_id,
"timestamp_utc": datetime.now(timezone.utc).isoformat(),
"operator_id": operator_id,
"reason": reason,
}
self.storage.write(override_record)
def log_data_drift_event(self, drift_metrics: dict, alert_level: str):
"""
Log detected data drift events per Article 9 continuous monitoring.
"""
drift_record = {
"type": "data_drift_alert",
"timestamp_utc": datetime.now(timezone.utc).isoformat(),
"system_id": self.system_id,
"alert_level": alert_level, # "low" | "medium" | "high"
"metrics": drift_metrics,
}
self.storage.write(drift_record)
5. Human Oversight Mechanisms (Article 14)
High-risk AI systems must be designed and developed to allow effective human oversight. This means building explicit override capability, ensuring outputs are interpretable enough for a human to make a meaningful review decision, and defining escalation thresholds.
In practice: Hard requirements are an override UI available to every operator, escalation logic that triggers human review when confidence is below a threshold or when out-of-distribution inputs are detected, and documentation of what operators are trained to look for.
6. Robustness, Accuracy, and Cybersecurity (Article 15)
The system must meet declared accuracy levels consistently across its intended operating range. It must be resilient to input manipulation (adversarial attacks), errors, and inconsistencies. You must implement appropriate cybersecurity measures given the risk profile.
In practice: Adversarial robustness testing before release, data poisoning detection in training pipelines, regular accuracy re-evaluation against production data, and penetration testing of the inference API.
NIST AI RMF in Practice
The NIST AI Risk Management Framework does not prescribe specific controls — it provides a structured process for identifying and managing AI risks in context. This makes it more flexible than the EU AI Act but also more ambiguous. Here is what the four functions mean in practice.
GOVERN
GOVERN establishes the organizational foundation: policies, roles, culture, and accountability structures for AI risk management. Without GOVERN, MAP, MEASURE, and MANAGE are exercises with no anchor.
What a small team should do: assign a named AI risk owner (this can be the tech lead), document a one-page AI use policy, and establish a minimum review checklist for new AI systems before production deployment.
What an enterprise must do: establish a formal AI governance committee with representation from legal, compliance, engineering, and business; define escalation paths; maintain an inventory of all AI systems in production; publish an external AI use policy; and align AI risk criteria with enterprise risk appetite statements.
MAP
MAP establishes context, identifies stakeholders, and categorizes AI risks across three dimensions: technical risks (model failure modes, distribution shift), operational risks (process gaps, integration failures), and societal risks (bias, fairness, downstream harm).
Practical output of MAP: a risk register with each identified risk labeled by category, likelihood, severity, and current control status. This feeds directly into the EU AI Act's Article 9 risk management system requirement.
MEASURE
MEASURE defines the metrics, benchmarks, and evaluation methods that determine whether risks are at acceptable levels. This is where most teams have the most room to improve: building automated evaluation into CI pipelines rather than doing it manually before major releases.
Metrics to track for a typical high-risk classifier: accuracy, precision/recall by demographic subgroup, false positive and false negative rates, confidence calibration, out-of-distribution detection rate, and model drift indicators (PSI, KS statistic, feature drift).
MANAGE
MANAGE covers the playbooks for responding to AI risk events: incidents, performance degradation, identified bias, adversarial attacks. It also covers the processes for retiring or significantly modifying AI systems.
What distinguishes mature AI risk management: the ability to execute a model rollback in under 30 minutes, a defined SLA for bias report investigation, and documented criteria for when a change to a high-risk system triggers a new conformity assessment.
EU AI Act vs. NIST AI RMF — Key Overlaps and Gaps:
| Requirement | EU AI Act | NIST AI RMF |
|---|---|---|
| Risk classification | Mandatory (Annex III) | Recommended (MAP function) |
| Technical documentation | Mandatory (Article 11) | Recommended (GOVERN + MAP) |
| Audit logging | Mandatory (Article 13) | Recommended (MEASURE) |
| Human oversight | Mandatory (Article 14) | Recommended (MANAGE) |
| Bias evaluation | Mandatory (Article 10) | Recommended (MEASURE) |
| Third-party assessment | Required for some categories | Not required |
| Geographic scope | EU nexus | US federal focus, global voluntary |
| Enforcement mechanism | Fines up to 6% global revenue | Contract requirements, sector rules |
| Voluntary certification | EU database registration | No certification program |

Generated with Higgsfield GPT Image — 16:9
Building Compliance Into Your SDLC
The worst approach to AI compliance is treating it as a pre-launch checklist. By the time a model is ready to deploy, it is too late to discover that your training data lacks the provenance documentation Article 10 requires. Compliance must be a property of your development process, not your deployment gate.
AI Compliance as Code:
Three concrete practices that integrate compliance into engineering workflow:
1. Automated model card generation. Instead of writing model cards manually, generate them from training metadata. Every training run should emit a structured artifact containing dataset statistics, bias evaluation results, and performance metrics. A CI job assembles these into a versioned model card. The model card is part of the artifact that gets deployed — not a document updated when someone remembers.
2. Bias test CI gates. Bias evaluation is not a one-time pre-launch exercise. It must run on every model version candidate, with a defined threshold that fails the pipeline. A disparate impact ratio below 0.80 on your primary protected attribute cohorts should be a hard gate, not a warning. The threshold should be documented in your risk management system and approved by your AI governance owner.
3. Audit log assertion tests. Every inference code path should have integration tests that verify audit log entries are written correctly. These tests should check that: a log entry is created for every decision, the entry contains all required fields, confidence score is within valid range, and override mechanisms are reachable. If your audit logging code silently fails in production, you have a compliance gap that you will only discover during an audit.
What "compliance as code" looks like in a CI pipeline:
# tests/test_ai_compliance.py
# Run as part of every model deployment CI pipeline
import pytest
import json
from pathlib import Path
from your_model_package import ModelCard, BiasEvaluator, AuditLogger
MODEL_CARD_PATH = Path("artifacts/model-card.yaml")
BIAS_THRESHOLD = 0.80 # Disparate impact ratio minimum
REQUIRED_LOG_FIELDS = [
"decision_id", "timestamp_utc", "system_id", "system_version",
"request_hash", "decision_output", "confidence_score", "model_version",
"out_of_distribution", "human_override"
]
class TestModelCardCompleteness:
def test_model_card_exists(self):
assert MODEL_CARD_PATH.exists(), "Model card must be generated before deployment"
def test_required_fields_present(self):
card = ModelCard.from_yaml(MODEL_CARD_PATH)
required = ["model_id", "intended_use", "training_data", "performance",
"human_oversight", "regulatory_compliance", "contacts"]
for field in required:
assert hasattr(card, field), f"Model card missing required field: {field}"
def test_out_of_scope_use_documented(self):
card = ModelCard.from_yaml(MODEL_CARD_PATH)
assert len(card.out_of_scope_use) > 0, "Model card must document out-of-scope uses"
class TestBiasEvaluation:
def test_disparate_impact_above_threshold(self, eval_dataset):
evaluator = BiasEvaluator()
results = evaluator.evaluate(eval_dataset)
for cohort, di_ratio in results.disparate_impact.items():
assert di_ratio >= BIAS_THRESHOLD, (
f"Bias gate FAILED: cohort '{cohort}' DI ratio {di_ratio:.3f} "
f"is below threshold {BIAS_THRESHOLD}. "
f"Investigate before merging."
)
def test_bias_evaluation_recency(self):
card = ModelCard.from_yaml(MODEL_CARD_PATH)
from datetime import datetime, timezone, timedelta
last_run = datetime.fromisoformat(card.training_data.bias_evaluation.last_run)
age_days = (datetime.now(timezone.utc) - last_run.replace(tzinfo=timezone.utc)).days
assert age_days < 30, f"Bias evaluation is {age_days} days old — must be run within 30 days of deployment"
class TestAuditLogging:
def test_decision_produces_log_entry(self, mock_storage, sample_features):
logger = AuditLogger("test-system", "v1.0", mock_storage)
decision_id = logger.log_decision(
features=sample_features,
decision="APPROVED",
confidence=0.87,
model_version="v1.0",
out_of_distribution=False,
session_context={"application_id": "test-001"},
processing_start=0.0,
)
assert decision_id is not None
assert len(mock_storage.records) == 1
def test_log_entry_has_all_required_fields(self, mock_storage, sample_features):
logger = AuditLogger("test-system", "v1.0", mock_storage)
logger.log_decision(
features=sample_features, decision="DENIED", confidence=0.61,
model_version="v1.0", out_of_distribution=True,
session_context={}, processing_start=0.0,
)
record = mock_storage.records[0]
for field in REQUIRED_LOG_FIELDS:
assert field in record, f"Audit log missing required field: {field}"
def test_override_logging_works(self, mock_storage, sample_features):
logger = AuditLogger("test-system", "v1.0", mock_storage)
decision_id = logger.log_decision(
features=sample_features, decision="DENIED", confidence=0.55,
model_version="v1.0", out_of_distribution=False,
session_context={}, processing_start=0.0,
)
logger.log_override(decision_id, "operator-007", "Customer appeal — edge case")
assert len(mock_storage.records) == 2
override = mock_storage.records[1]
assert override["type"] == "override"
assert override["decision_id"] == decision_id
The critical insight here is that compliance test failures should be treated the same as unit test failures: they block merge, they require a fix before deployment, and they are owned by the engineering team — not the compliance team. The compliance team sets the policy; the engineering team implements and verifies it in code.
Conclusion
AI compliance in 2026 is not optional, and it is no longer something you can delegate entirely to legal or compliance functions. The EU AI Act's technical requirements — risk management systems, data governance documentation, audit logging, human oversight mechanisms, robustness testing — are engineering deliverables. They require engineering ownership.
The teams that will handle this best are the ones that treat compliance as architecture: something designed in from the beginning, expressed in code, tested in CI, and continuously verified in production. The teams that will struggle are the ones waiting for a compliance checklist to appear three weeks before an audit.
There is also a competitive angle worth naming directly. Mature AI governance is increasingly a sales differentiator in enterprise markets. Procurement teams at regulated customers — banks, insurers, healthcare systems, public sector organizations — are now asking for model cards, audit logging attestation, and documented human oversight mechanisms before signing contracts. Having this infrastructure in place is not just a compliance cost; it is a trust signal that closes deals.
The frameworks — EU AI Act, NIST AI RMF, ISO 42001 — overlap significantly in their practical requirements. You do not need to build three parallel compliance programs. Build one solid one: risk-classify your systems correctly, document your training data and model behavior, implement audit logging and human override mechanisms, run bias evaluations in CI, and maintain a living risk register. That core program satisfies the lion's share of all three frameworks simultaneously.
Start with the highest-risk systems first. Classify everything in your portfolio. Fix the gaps in documentation and logging for high-risk systems before August 2026 if you haven't already. Then build the compliance-as-code infrastructure so that new systems are compliant by default, not by remediation.
The regulatory moment is here. The engineering response is to make compliance a first-class property of how you build AI systems — not a checkpoint you hit on the way out the door.
Want to go deeper? The EU AI Act full text is at eur-lex.europa.eu. The NIST AI RMF playbook is at airc.nist.gov. The AI Safety Institute's evaluation guidelines are at aisi.gov.uk.
About the Author
Toc Am
Founder of AmtocSoft. Writing practical deep-dives on AI engineering, cloud architecture, and developer tooling. Previously built backend systems at scale. Reviews every post published under this byline.
Published: 2026-04-12 · Written with AI assistance, reviewed by Toc Am.
Get These In Your Inbox
Weekly deep-dives on AI engineering, no fluff. Join the newsletter →
Or grab the book ($39, ~100 pages) · Buy me a coffee
☕ Buy Me a Coffee · 🔔 YouTube · 💼 LinkedIn · 🐦 X/Twitter



No comments:
Post a Comment