
Introduction
Every sufficiently large distributed system eventually confronts the same fundamental tension: services need to communicate, but tight coupling between services makes the whole system fragile. When Service A directly calls Service B, and Service B calls Service C, you have built a chain. If any link in that chain is slow, unavailable, or returns an unexpected error, the failure propagates upstream. A slow payment processor causes your checkout service to time out. A slow checkout service causes your shopping cart to block. Now your entire application is degraded because of a single slow downstream dependency.
Event-driven architecture is the answer to this tension. Instead of Service A calling Service B directly, Service A emits an event — "OrderPlaced," "UserRegistered," "PaymentReceived" — onto a message bus. Service B, C, and D each consume events they care about and process them independently. Service A does not wait for the others. It does not care how many consumers exist, or whether they are online at the moment of publication. It just emits the event and moves on.
This decoupling changes the failure model of your system fundamentally. A slow consumer does not slow the producer. A temporarily unavailable consumer catches up from the message log when it comes back online. New consumers can be added without any changes to producers. The system becomes resilient, composable, and independently scalable.
In 2026, the two dominant technologies for building event-driven systems are Apache Kafka and RabbitMQ, and they solve fundamentally different versions of the problem. Understanding the distinction — message queuing vs event streaming — is the foundation for choosing correctly. We will also briefly cover Apache Pulsar, which occupies interesting territory between the two.
This post gives you the mental model, the architecture patterns, and the code to build production-ready event-driven systems.
The Problem: Tight Coupling and Synchronous Systems
To understand why event-driven architecture matters, consider a typical synchronous microservices architecture for an e-commerce checkout flow:
The total checkout latency is the sum of every downstream call: 150ms + 800ms + 300ms + 2000ms = 3.25 seconds, plus your own processing time. If Analytics is down or slow — something fundamentally non-critical to the checkout — your users experience a degraded checkout. If EmailService is temporarily overloaded, orders stop completing.
This is the synchronous coupling problem. The solutions:
- Async calls with circuit breakers — fire-and-forget for non-critical services, but now you have no confirmation. Did the email send? Did Analytics record the event?
- Event-driven decoupling — OrderService emits one "OrderCompleted" event and is done. Every other service processes it asynchronously, in their own time, without coupling the checkout latency to their performance.
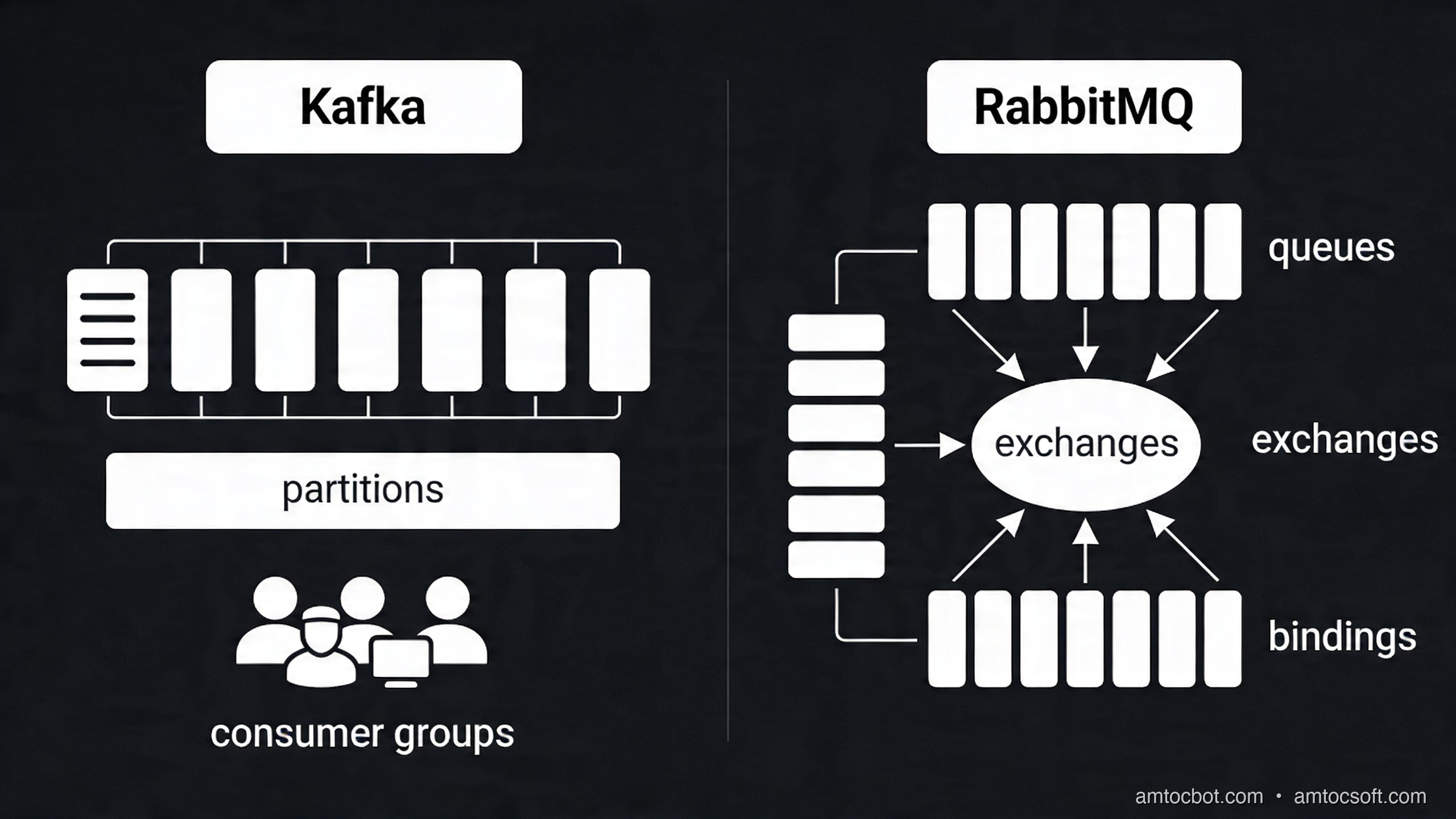
How It Works: Message Queues vs Event Streaming
The terms "message queue" and "event streaming" are often used interchangeably, but they describe fundamentally different paradigms.
Message Queue Model (RabbitMQ)
In a message queue, a message is a task to be done. When a consumer processes a message, it is acknowledged and deleted from the queue. The queue is a work distribution mechanism: here is a list of jobs, workers pick them up and mark them done.
Key properties:
- Messages are consumed once — once processed and acknowledged, they are gone
- Multiple consumers on the same queue compete for messages (work queue pattern)
- The broker is responsible for routing, filtering, and delivering messages
- Push-based: the broker actively delivers messages to consumers
- Designed for task distribution, RPC, and workflows with complex routing logic
Event Stream Model (Kafka)
In an event stream, an event is a record of something that happened. When a consumer reads an event, it is not deleted — the event remains in the log indefinitely (subject to retention policy). Different consumer groups each get their own independent cursor (offset) into the log, allowing multiple independent consumers to read the same events.
Key properties:
- Events are retained and replayable — consumers can reread history
- Multiple consumer groups read the same events independently — no competition
- The broker is a dumb log — it stores events in order, consumers control their position
- Pull-based: consumers poll the broker for new events
- Designed for high-throughput event streaming, audit logs, and event sourcing
The Decision in One Sentence
Use RabbitMQ when you have tasks to distribute among workers. Use Kafka when you have events that multiple independent systems need to know about.
Kafka Deep Dive: Topics, Partitions, and Consumer Groups
Apache Kafka organizes data into topics — named, append-only logs. Each topic is divided into partitions — shards that enable parallel processing. Events within a partition are ordered and immutable. Events across partitions have no ordering guarantee.
Partitioning and Ordering
The partition key determines which partition an event lands in. Kafka guarantees ordering within a partition. If you partition by user_id, all events for a given user arrive in order to the same consumer, enabling correct event processing (e.g., "apply these account transactions in sequence"). If you need global ordering across all events, you need a single partition — which caps your throughput at what one consumer can handle.
Producer Code (Python with confluent-kafka)
from confluent_kafka import Producer
import json
import logging
from datetime import datetime, timezone
logger = logging.getLogger(__name__)
class OrderEventProducer:
"""
Produces order lifecycle events to the 'order-events' Kafka topic.
Uses confluent-kafka, which wraps the high-performance librdkafka C library.
This is the recommended Kafka client for Python in production — it handles
batching, compression, and retry logic automatically.
"""
def __init__(self, bootstrap_servers: str):
self._producer = Producer({
'bootstrap.servers': bootstrap_servers,
# Acknowledge after all in-sync replicas have written the message.
# 'all' is the safest setting — prevents data loss on broker failure.
# '1' = just leader ack (faster, slightly higher risk of data loss)
'acks': 'all',
# Retry transient failures up to 3 times before raising an error
'retries': 3,
'retry.backoff.ms': 100,
# Idempotent producer: prevents duplicate messages on retry
# Requires acks='all' and retries > 0
'enable.idempotence': True,
# Compression reduces network and storage cost significantly
# lz4 is fast to compress/decompress; snappy is also popular
'compression.type': 'lz4',
# Batching: collect up to 16KB before sending, or wait up to 5ms
# Higher batch.size + linger.ms = better throughput, slightly higher latency
'batch.size': 16384,
'linger.ms': 5,
})
def publish_order_placed(self, order_id: str, user_id: str, total: float, items: list):
"""Publish an OrderPlaced event."""
event = {
'event_type': 'OrderPlaced',
'order_id': order_id,
'user_id': user_id,
'total': total,
'items': items,
'timestamp': datetime.now(timezone.utc).isoformat(),
'version': '1.0',
}
self._publish(
topic='order-events',
key=user_id, # Partition by user_id for per-user ordering
value=event,
)
def publish_order_completed(self, order_id: str, user_id: str):
"""Publish an OrderCompleted event."""
event = {
'event_type': 'OrderCompleted',
'order_id': order_id,
'user_id': user_id,
'timestamp': datetime.now(timezone.utc).isoformat(),
'version': '1.0',
}
self._publish(topic='order-events', key=user_id, value=event)
def _publish(self, topic: str, key: str, value: dict):
"""
Internal publish method with delivery confirmation callback.
The produce() call is non-blocking — it enqueues the message locally.
poll() flushes the delivery callback queue.
"""
def delivery_callback(err, msg):
if err:
logger.error(
'Message delivery failed: topic=%s key=%s error=%s',
topic, key, err
)
else:
logger.debug(
'Message delivered: topic=%s partition=%d offset=%d',
msg.topic(), msg.partition(), msg.offset()
)
self._producer.produce(
topic=topic,
key=key.encode('utf-8'),
value=json.dumps(value).encode('utf-8'),
callback=delivery_callback,
)
# poll() triggers delivery callbacks — call frequently to avoid buffer buildup
self._producer.poll(0)
def flush(self, timeout_seconds: float = 10.0):
"""
Wait for all outstanding messages to be delivered.
Call before application shutdown or in batch scenarios.
"""
remaining = self._producer.flush(timeout=timeout_seconds)
if remaining > 0:
logger.warning('%d messages were not delivered within timeout', remaining)
def __del__(self):
self.flush()
Consumer Code (Python with confluent-kafka)
from confluent_kafka import Consumer, KafkaError, KafkaException
import json
import logging
import signal
import sys
logger = logging.getLogger(__name__)
class OrderEventConsumer:
"""
Consumes order events and dispatches them to handlers.
Key design decisions:
1. Manual offset commit after successful processing (at-least-once delivery)
2. Graceful shutdown on SIGTERM/SIGINT
3. Dead letter queue for messages that fail after max retries
"""
def __init__(
self,
bootstrap_servers: str,
group_id: str,
topics: list[str],
max_retries: int = 3,
dlq_topic: str = 'order-events-dlq',
):
self._consumer = Consumer({
'bootstrap.servers': bootstrap_servers,
'group.id': group_id,
# Start from the beginning of the topic if this group has no committed offset.
# Use 'latest' for consumers that only care about new messages.
'auto.offset.reset': 'earliest',
# Disable auto-commit — we commit manually after successful processing
# to guarantee at-least-once delivery semantics.
'enable.auto.commit': False,
# Session timeout: if the consumer doesn't send a heartbeat within this
# window, the broker considers it dead and triggers a rebalance.
'session.timeout.ms': 30000,
'heartbeat.interval.ms': 10000,
# Maximum records returned in a single poll()
'max.poll.records': 100,
})
self._consumer.subscribe(topics)
self._topics = topics
self._max_retries = max_retries
self._dlq_producer = Producer({'bootstrap.servers': bootstrap_servers})
self._dlq_topic = dlq_topic
self._running = True
# Handle graceful shutdown on SIGTERM/SIGINT
signal.signal(signal.SIGTERM, self._shutdown)
signal.signal(signal.SIGINT, self._shutdown)
def _shutdown(self, signum, frame):
logger.info('Shutdown signal received, stopping consumer...')
self._running = False
def _send_to_dlq(self, msg, error_reason: str, attempt: int):
"""Send a failed message to the dead letter queue with error metadata."""
dlq_payload = {
'original_topic': msg.topic(),
'original_partition': msg.partition(),
'original_offset': msg.offset(),
'original_key': msg.key().decode('utf-8') if msg.key() else None,
'original_value': msg.value().decode('utf-8') if msg.value() else None,
'error_reason': error_reason,
'failed_at': attempt,
}
self._dlq_producer.produce(
topic=self._dlq_topic,
value=json.dumps(dlq_payload).encode('utf-8'),
)
self._dlq_producer.poll(0)
logger.warning('Message sent to DLQ: %s', error_reason)
def run(self, handler):
"""
Main consume loop. Calls handler(event_dict) for each message.
Commits offset only after successful handling.
Sends to DLQ after max_retries failures.
"""
logger.info('Starting consumer for topics: %s, group: %s', self._topics, self._consumer)
try:
while self._running:
# poll() blocks for up to 1 second waiting for messages
msg = self._consumer.poll(timeout=1.0)
if msg is None:
continue # No message within timeout — loop again
if msg.error():
if msg.error().code() == KafkaError._PARTITION_EOF:
# Reached end of partition — not an error, just informational
logger.debug('Reached partition EOF: %s [%d]', msg.topic(), msg.partition())
else:
raise KafkaException(msg.error())
continue
# Deserialize the event
try:
event = json.loads(msg.value().decode('utf-8'))
except json.JSONDecodeError as e:
logger.error('Failed to decode message: %s', e)
self._send_to_dlq(msg, f'JSON decode error: {e}', attempt=0)
self._consumer.commit(message=msg)
continue
# Process with retry logic
last_error = None
for attempt in range(self._max_retries + 1):
try:
handler(event)
last_error = None
break
except Exception as e:
last_error = e
if attempt < self._max_retries:
logger.warning(
'Handler failed (attempt %d/%d): %s',
attempt + 1, self._max_retries, e
)
# Exponential backoff between retries (basic implementation)
import time
time.sleep(min(2 ** attempt * 0.1, 5.0))
if last_error:
# All retries exhausted — send to DLQ
self._send_to_dlq(msg, str(last_error), attempt=self._max_retries)
# Commit offset after processing (whether succeeded or sent to DLQ)
# This ensures we never reprocess unless intentionally replaying from DLQ
self._consumer.commit(message=msg)
finally:
logger.info('Closing consumer...')
self._consumer.close()
# Example handler function
def handle_order_event(event: dict):
"""Route order events to the appropriate handler."""
event_type = event.get('event_type')
if event_type == 'OrderPlaced':
# Send confirmation email
logger.info('Sending confirmation email for order %s', event['order_id'])
# email_service.send_order_confirmation(event['user_id'], event['order_id'])
elif event_type == 'OrderCompleted':
# Track in analytics
logger.info('Recording order completion in analytics: %s', event['order_id'])
# analytics.track('order_completed', event)
else:
logger.warning('Unknown event type: %s', event_type)
# Usage
if __name__ == '__main__':
consumer = OrderEventConsumer(
bootstrap_servers='kafka-broker-1:9092,kafka-broker-2:9092',
group_id='email-service-consumers',
topics=['order-events'],
dlq_topic='order-events-dlq',
)
consumer.run(handle_order_event)
RabbitMQ Deep Dive: Exchanges, Queues, and Routing
RabbitMQ uses a richer routing model than Kafka. Producers publish messages to exchanges, not directly to queues. Exchanges route messages to queues based on routing keys and bindings. This gives you flexible fan-out, topic-based filtering, and direct routing — all configurable without code changes.
Exchange Types
| Exchange Type | Routing Behavior | Use Case |
|---|---|---|
| Direct | Route by exact routing key match | Task distribution to specific queues |
| Fanout | Broadcast to all bound queues | Notifications to multiple services |
| Topic | Route by pattern matching (order.*, *.created) |
Flexible event routing with wildcards |
| Headers | Route by message header attributes | Complex routing without key-based patterns |
RabbitMQ Producer and Consumer (Python with pika)
import pika
import json
import logging
from datetime import datetime, timezone
from typing import Callable
logger = logging.getLogger(__name__)
class RabbitMQEventBus:
"""
Simple event bus built on RabbitMQ using a topic exchange.
Routing key convention: <domain>.<entity>.<event>
Examples: orders.order.placed, orders.order.completed, users.user.registered
Consumers bind queues with wildcards:
- 'orders.*.*' = all order events
- '*.*.placed' = all 'placed' events across all domains
- 'orders.order.#' = all order entity events (# matches zero or more words)
"""
EXCHANGE_NAME = 'amtocsoft.events'
EXCHANGE_TYPE = 'topic'
def __init__(self, amqp_url: str):
self._url = amqp_url
self._connection = None
self._channel = None
def connect(self):
"""Establish connection and declare the exchange."""
params = pika.URLParameters(self._url)
# Enable heartbeats to detect dead connections
params.heartbeat = 60
params.blocked_connection_timeout = 300
self._connection = pika.BlockingConnection(params)
self._channel = self._connection.channel()
# Declare the topic exchange — durable means it survives broker restart
self._channel.exchange_declare(
exchange=self.EXCHANGE_NAME,
exchange_type=self.EXCHANGE_TYPE,
durable=True,
)
logger.info('Connected to RabbitMQ and declared exchange: %s', self.EXCHANGE_NAME)
def publish(self, routing_key: str, event_data: dict):
"""
Publish an event to the topic exchange.
routing_key: dot-separated path, e.g. 'orders.order.placed'
event_data: dict that will be JSON-serialized
"""
body = json.dumps({
**event_data,
'routing_key': routing_key,
'timestamp': datetime.now(timezone.utc).isoformat(),
}).encode('utf-8')
self._channel.basic_publish(
exchange=self.EXCHANGE_NAME,
routing_key=routing_key,
body=body,
properties=pika.BasicProperties(
delivery_mode=pika.DeliveryMode.Persistent, # Survive broker restart
content_type='application/json',
content_encoding='utf-8',
),
)
logger.debug('Published event: routing_key=%s', routing_key)
def subscribe(
self,
queue_name: str,
binding_pattern: str,
handler: Callable[[dict], None],
prefetch_count: int = 10,
):
"""
Subscribe to events matching a routing key pattern.
queue_name: unique name for this consumer's queue (persistent)
binding_pattern: topic pattern, e.g. 'orders.*.*' or '*.*.placed'
handler: function called for each message
prefetch_count: max unacknowledged messages (backpressure control)
"""
# Declare a durable queue — survives broker restart
result = self._channel.queue_declare(
queue=queue_name,
durable=True,
arguments={
# Dead letter exchange: failed messages go here
'x-dead-letter-exchange': f'{self.EXCHANGE_NAME}.dlx',
# After 5 failed deliveries, message goes to DLQ
'x-dead-letter-routing-key': queue_name,
# Messages expire after 7 days if not consumed
'x-message-ttl': 7 * 24 * 60 * 60 * 1000,
}
)
# Bind queue to exchange with the routing key pattern
self._channel.queue_bind(
exchange=self.EXCHANGE_NAME,
queue=queue_name,
routing_key=binding_pattern,
)
# Prefetch: don't deliver more than N messages before receiving acks
# Prevents one slow consumer from holding all messages
self._channel.basic_qos(prefetch_count=prefetch_count)
def _on_message(ch, method, properties, body):
try:
event = json.loads(body.decode('utf-8'))
handler(event)
# Acknowledge: message is done, remove from queue
ch.basic_ack(delivery_tag=method.delivery_tag)
except Exception as e:
logger.error('Handler failed for routing key %s: %s', method.routing_key, e)
# Negative acknowledge with requeue=False: send to DLQ after max retries
# (x-death header tracks retry count — check it in handler for custom logic)
ch.basic_nack(delivery_tag=method.delivery_tag, requeue=False)
self._channel.basic_consume(
queue=queue_name,
on_message_callback=_on_message,
)
logger.info(
'Subscribed: queue=%s, pattern=%s',
queue_name, binding_pattern
)
def start_consuming(self):
"""Block and process incoming messages until connection closes."""
logger.info('Starting to consume messages...')
try:
self._channel.start_consuming()
except KeyboardInterrupt:
self._channel.stop_consuming()
finally:
if self._connection and not self._connection.is_closed:
self._connection.close()
# Example usage: Email service subscribes to order events
def send_email_for_order_event(event: dict):
"""Handle order events that require email notifications."""
event_type = event.get('event_type')
if event_type == 'OrderPlaced':
logger.info('Sending order confirmation for %s', event.get('order_id'))
elif event_type == 'OrderShipped':
logger.info('Sending shipping notification for %s', event.get('order_id'))
if __name__ == '__main__':
bus = RabbitMQEventBus(amqp_url='amqp://user:pass@rabbitmq:5672/')
bus.connect()
# Subscribe to ALL order events using wildcard
bus.subscribe(
queue_name='email-service.order-events',
binding_pattern='orders.order.*',
handler=send_email_for_order_event,
)
# Also subscribe to user registration events
bus.subscribe(
queue_name='email-service.user-events',
binding_pattern='users.user.registered',
handler=lambda event: logger.info('Welcome email for %s', event.get('user_id')),
)
bus.start_consuming()
Delivery Semantics: At-Least-Once vs Exactly-Once
One of the most misunderstood topics in distributed messaging is delivery guarantees. There are three levels:
At-least-once is what most systems implement and what you should default to. The key implication: your consumers must be idempotent — processing the same event twice must produce the same result as processing it once.
Making consumers idempotent:
def handle_order_placed_idempotent(event: dict, db_conn):
"""
Idempotent handler: safe to call multiple times with the same event.
Uses PostgreSQL's INSERT ... ON CONFLICT DO NOTHING with event_id as unique key.
"""
event_id = event['event_id'] # Must be included by producer — a UUID
order_id = event['order_id']
with db_conn.cursor() as cur:
# The processed_events table acts as a deduplication log
cur.execute("""
INSERT INTO processed_events (event_id, processed_at)
VALUES (%s, NOW())
ON CONFLICT (event_id) DO NOTHING
""", (event_id,))
if cur.rowcount == 0:
# This event_id was already processed — skip
logger.info('Skipping duplicate event: %s', event_id)
return
# First time seeing this event — process it
cur.execute("""
INSERT INTO order_notifications (order_id, notified_at)
VALUES (%s, NOW())
ON CONFLICT (order_id) DO NOTHING
""", (order_id,))
db_conn.commit()
logger.info('Processed event %s for order %s', event_id, order_id)
Apache Pulsar: The Middle Ground
Apache Pulsar deserves a brief mention as a third option that combines elements of both Kafka and RabbitMQ. It separates the serving layer (brokers) from the storage layer (BookKeeper), enabling independent scaling of compute and storage. Key Pulsar differentiators:
- Multi-tenancy built in: namespaces with per-tenant quotas and isolation
- Geo-replication native: built-in cross-datacenter replication
- Tiered storage: automatically offloads older segments to S3/GCS
- Flexible subscription modes: exclusive (like RabbitMQ), shared (round-robin), key-shared (partitioned), failover
Pulsar is compelling for organizations running multi-region deployments or needing geo-replication without manual Kafka MirrorMaker configuration. However, its operational complexity (managing BookKeeper + Zookeeper + brokers) is higher than Kafka, which itself is already substantial.
Comparison and Tradeoffs
| Feature | Kafka | RabbitMQ | Pulsar |
|---|---|---|---|
| Model | Event log (pull) | Message queue (push) | Both |
| Ordering | Per-partition | Per-queue | Per-partition/key |
| Retention | Time/size based | Until consumed (+ TTL) | Tiered (S3 offload) |
| Throughput | Very high (millions/sec) | High (hundreds of thousands/sec) | Very high |
| Routing flexibility | Topic + partition | Exchange types + wildcards | Topic + subscription |
| Replay | Native (seek to offset) | No (message consumed = gone) | Native |
| Ops complexity | Medium (Kafka + ZK/KRaft) | Low (single binary cluster) | High (3 tiers) |
| Best for | Event streaming, audit, analytics | Task queues, RPC, workflows | Multi-region, SaaS |
When to Choose Kafka
- Multiple independent consumers need to read the same events
- You need event replay (reprocessing history with new logic)
- High throughput: millions of events per second
- Event sourcing or CQRS architectures
- Stream processing with Kafka Streams or Flink
When to Choose RabbitMQ
- Work queue pattern: N consumers competing for tasks
- Complex routing logic with topic matching and headers
- Request-reply (RPC over messaging)
- Lower operational complexity is a priority
- Mixed task types that benefit from priority queues
Production Considerations
Kafka Operational Checklist
# Monitor consumer lag — how far behind are consumers?
kafka-consumer-groups.sh \
--bootstrap-server kafka:9092 \
--describe \
--group email-service-consumers
# Output shows: TOPIC, PARTITION, CURRENT-OFFSET, LOG-END-OFFSET, LAG
# LAG > 0 means the consumer is falling behind — investigate throughput
Key metrics to alert on:
- Consumer lag > threshold: consumers cannot keep up with production rate
- Under-replicated partitions > 0: a broker may be down or slow
- ISR (In-Sync Replicas) shrinking: replica is falling behind, risk of data loss on failure
- Request rate on leader vs. follower fetch rate: imbalance indicates hot partitions
Schema Management with Avro and Schema Registry
Without schema management, a producer deploying a breaking schema change will crash all consumers. Use Confluent Schema Registry (or AWS Glue Schema Registry) to version and validate event schemas:
from confluent_kafka.schema_registry import SchemaRegistryClient
from confluent_kafka.schema_registry.avro import AvroSerializer, AvroDeserializer
# Schema Registry enforces compatibility modes:
# BACKWARD: new schema can read data written with previous schema
# FORWARD: previous schema can read data written with new schema
# FULL: both backward and forward compatible
ORDER_SCHEMA_STR = """
{
"type": "record",
"name": "OrderPlaced",
"namespace": "com.amtocsoft.orders",
"fields": [
{"name": "order_id", "type": "string"},
{"name": "user_id", "type": "string"},
{"name": "total", "type": "double"},
{"name": "timestamp", "type": "string"},
{"name": "version", "type": "string", "default": "1.0"}
]
}
"""
RabbitMQ High Availability
Run RabbitMQ in a cluster with quorum queues (the modern replacement for mirrored queues):
# Declare a quorum queue — replicated across N nodes for HA
channel.queue_declare(
queue='critical-orders',
durable=True,
arguments={
'x-queue-type': 'quorum', # Quorum queue: Raft-based replication
# x-quorum-initial-group-size defaults to cluster size
}
)
Quorum queues use Raft consensus to ensure a message is written to a majority of nodes before acking. This prevents data loss on broker failure.
Conclusion
Event-driven architecture is not a silver bullet — it introduces operational complexity, eventual consistency, and the need for idempotent consumers. But for systems beyond a certain scale, it is the only way to achieve genuine decoupling and independent scalability.
The choice between Kafka and RabbitMQ is not about which is better — it is about which model fits your problem. Task distribution with complex routing logic? RabbitMQ. High-throughput event streaming where multiple independent consumers need the full event history? Kafka. Both? Run both — many mature systems use Kafka for the event backbone and RabbitMQ for internal task queues.
The most important thing to get right is your delivery guarantee and idempotency story. Almost every event-driven system operates at-least-once, which means your consumers will occasionally process the same event twice. Build that assumption into your design from day one, and use a deduplication table keyed on event IDs to handle it cleanly.
Building event-driven systems and have questions about Kafka vs RabbitMQ for your use case? Drop a comment below or connect on LinkedIn. Follow AmtocSoft Tech Insights for more deep-dives into distributed systems architecture.
Sources
- Apache Kafka documentation — Consumer groups, partitioning, and retention configuration reference
- RabbitMQ documentation — Exchange types (direct, topic, fanout, headers), dead-letter queues, and acknowledgement modes
- Confluent — "The Kafka Paper" (Kreps, Narkhede, Rao — 2011) — Original LinkedIn engineering paper describing the log-based messaging model
- NATS documentation — Lightweight messaging alternative referenced in the comparison section
- AWS EventBridge — Managed event bus used in the cloud-native EDA patterns
- Martin Fowler — "Event-Driven Architecture" — Taxonomy of event notification vs event-carried state transfer vs event sourcing
- CloudEvents specification — The CNCF standard event envelope format referenced in the interoperability section
About the Author
Toc Am
Founder of AmtocSoft. Writing practical deep-dives on AI engineering, cloud architecture, and developer tooling. Previously built backend systems at scale. Reviews every post published under this byline.
Published: 2026-04-14 · Written with AI assistance, reviewed by Toc Am.
Get These In Your Inbox
Weekly deep-dives on AI engineering, no fluff. Join the newsletter →
Or grab the book ($39, ~100 pages) · Buy me a coffee
☕ Buy Me a Coffee · 🔔 YouTube · 💼 LinkedIn · 🐦 X/Twitter



No comments:
Post a Comment