
Introduction
Deploying software used to feel like jumping off a cliff. You merged a branch, pressed deploy, held your breath, and watched error rates either stay flat or spike into the red. If something went wrong, the options were grim: roll back the entire release, hotfix under pressure, or scramble to isolate the bad code while half your user base hit a broken experience.
Feature flags change this equation entirely. Instead of treating deployment as a single, irreversible moment, flags decouple the act of shipping code from the act of releasing features. You can deploy to production continuously — every day, multiple times a day — while individual features remain hidden behind a flag, visible only to the users or environments you choose.
This is the foundation of progressive delivery: the practice of gradually exposing new features to increasing segments of your audience, with the ability to halt, revert, or adjust at any point. It is one of the most powerful patterns in modern software engineering, and in 2026 it has become an expectation rather than a luxury at companies of any serious scale.
This post goes deep on how feature flags actually work: the evaluation model, the different flag types, how to implement percentage rollouts and user targeting in Node.js and TypeScript, how to choose between self-hosted solutions like Unleash and Flagsmith versus SaaS platforms like LaunchDarkly and Statsig, and how to manage the technical debt that stale flags inevitably accumulate. By the end, you will have enough to build a production-grade flag system from scratch or evaluate which managed solution is the right fit for your team.
The Problem: Deployment Is Not the Same as Release
Most engineering teams have felt the pain of big-bang releases. A feature takes three weeks to build, lives on a long-lived branch, and gets merged the day before launch. The diff is enormous. Review is surface-level because the deadline is imminent. Testing is rushed. And then it ships to 100% of users simultaneously.
If the feature causes a performance regression, all users experience it. If there is a logic bug that only manifests at scale, you discover it in production on the worst possible day. If business requirements change mid-sprint, half the code is already shipped and the other half is in flight — untangling it is miserable.
The same problem appears at a subtler level with database migrations, API versioning, and infrastructure changes. You want to test a new query plan against real production traffic, but only a fraction of it. You want to gradually shift users from a legacy payment processor to a new one. You want to run an A/B test on a checkout flow without spinning up a separate experiment platform.
Feature flags solve all of these scenarios with a single, consistent abstraction: a named conditional that controls whether a code path is active.
if (flagClient.isEnabled('new-checkout-flow', userContext)) {
return newCheckout(cart);
}
return legacyCheckout(cart);
That single conditional is doing enormous work. It lets you:
- Deploy the new checkout to production without any users seeing it (flag is off globally)
- Enable it for internal employees first to catch obvious bugs
- Roll it to 5% of users, then 20%, then 50%, monitoring metrics at each stage
- Kill the feature instantly if error rates climb, with no deployment required
- Permanently remove the flag and the old code path once confidence is established
This is the model. The rest of this post is about doing it well.
How Feature Flags Work
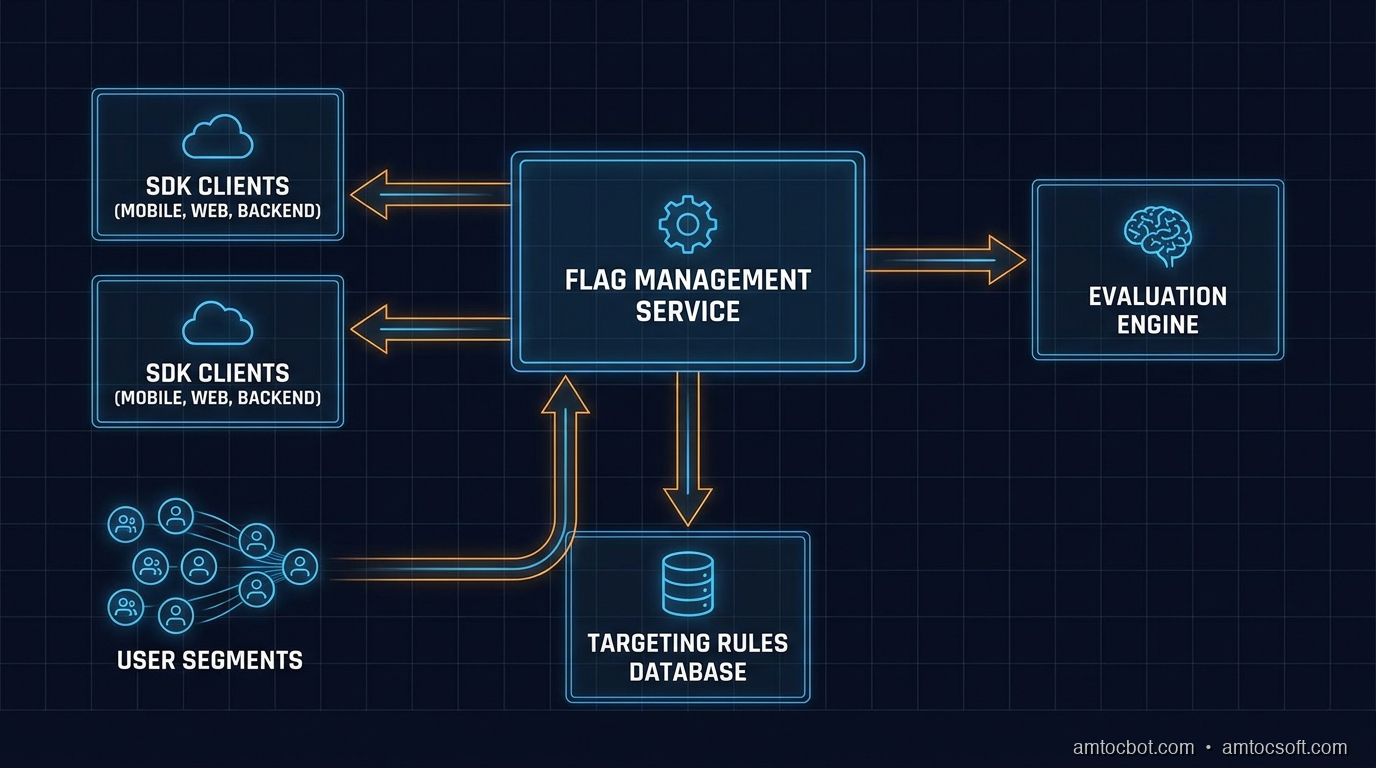
Flag Types
Not all flags are the same. The two primary categories are boolean flags and multivariate flags.
Boolean flags are the simplest form: a feature is either on or off. They are appropriate for kill switches, gradual rollouts, and simple A/B tests. The evaluation result is true or false.
Multivariate flags return one of N values, where N is greater than two. The value can be a string, a number, a JSON object, or an enumeration. Common uses include:
- String variants:
'control','variant-a','variant-b'— for multi-arm experiments - Number variants: returning a timeout value (500, 1000, 2000 ms) to test performance thresholds
- JSON variants: returning an entire configuration object, so a single flag controls multiple related settings simultaneously
// Boolean flag
const showNewDashboard = flagClient.getBoolVariation('new-dashboard', context, false);
// String multivariate flag
const checkoutVariant = flagClient.getStringVariation('checkout-flow', context, 'control');
// Returns 'control' | 'single-page' | 'multi-step' | 'guided'
// Number multivariate flag
const timeoutMs = flagClient.getNumberVariation('api-timeout-ms', context, 3000);
// JSON multivariate flag
const searchConfig = flagClient.getJsonVariation('search-config', context, defaultConfig);
// Returns { algorithm: 'bm25', maxResults: 10, enableFuzzy: false }
Multivariate flags are especially powerful because they remove the need for a proliferation of related boolean flags. Instead of use-new-search, enable-fuzzy-search, increase-result-count, you have one search-config flag that returns a coherent configuration object.
The Evaluation Model
Feature flag evaluation is where the real power lives. A flag is not just a stored boolean value — it is a set of rules evaluated against a user context object at runtime.
The context object is the key to targeting. It typically includes:
interface UserContext {
key: string; // stable user ID for consistent bucketing
email?: string; // for email-domain targeting
plan?: string; // 'free' | 'pro' | 'enterprise'
region?: string; // 'us-east-1' | 'eu-west-1'
betaUser?: boolean; // explicit opt-in segment
customAttributes?: Record<string, string | number | boolean>;
}
Rules are evaluated in priority order. The first rule to match determines the result. Common rule types:
- Individual targeting:
user_id IN ['user-abc123', 'user-def456']— useful for internal QA - Segment targeting:
plan == 'enterprise'— enable features for paying customers first - Percentage rollout: hash the user key into a 0–99 bucket, enable if bucket < threshold
- Default rule: the fallback that applies when no other rule matches
The percentage rollout mechanism deserves attention because it must be consistent and sticky. The same user must always land in the same bucket, regardless of when or where the evaluation happens. This is achieved by hashing the user key (not a random value):
function getBucketValue(userKey: string, flagKey: string): number {
// Include flagKey in the hash to prevent identical rollouts across flags
const input = `${flagKey}.${userKey}`;
const hash = murmur3(input); // or any fast, consistent hash
return (hash >>> 0) % 100; // 0–99
}
function isUserInRollout(userKey: string, flagKey: string, percentage: number): boolean {
return getBucketValue(userKey, flagKey) < percentage;
}
This ensures that a user who is in the 10% rollout for a flag stays in that rollout consistently, and that their rollout status for one flag is independent of their status for another.
Implementation Guide
Building a Minimal Flag Client in TypeScript
Let's build a feature flag client from scratch to understand exactly what the production SDKs are doing under the hood. This is not a production replacement — it is a learning tool and a useful starting point for teams that want to self-host without a full platform.
// types.ts
export interface FlagRule {
type: 'individual' | 'segment' | 'percentage' | 'default';
attribute?: string;
operator?: 'eq' | 'in' | 'lt' | 'gt' | 'contains';
values?: (string | number | boolean)[];
percentage?: number;
variant: string;
}
export interface FlagDefinition {
key: string;
enabled: boolean;
variants: Record<string, string | number | boolean | object>;
rules: FlagRule[];
defaultVariant: string;
}
export interface EvaluationContext {
key: string;
[attribute: string]: string | number | boolean | undefined;
}
// flag-client.ts
import { createHash } from 'crypto';
import type { FlagDefinition, EvaluationContext, FlagRule } from './types';
export class FeatureFlagClient {
private flags: Map<string, FlagDefinition> = new Map();
private cacheExpiry: number = 0;
private readonly cacheTtlMs: number;
private readonly flagsEndpoint: string;
constructor(opts: { endpoint: string; cacheTtlMs?: number }) {
this.flagsEndpoint = opts.endpoint;
this.cacheTtlMs = opts.cacheTtlMs ?? 30_000;
}
async initialize(): Promise<void> {
await this.refresh();
}
private async refresh(): Promise<void> {
const res = await fetch(this.flagsEndpoint);
if (!res.ok) throw new Error(`Flag fetch failed: ${res.status}`);
const definitions: FlagDefinition[] = await res.json();
this.flags.clear();
for (const flag of definitions) {
this.flags.set(flag.key, flag);
}
this.cacheExpiry = Date.now() + this.cacheTtlMs;
}
private async ensureFresh(): Promise<void> {
if (Date.now() > this.cacheExpiry) {
await this.refresh();
}
}
private getBucket(userKey: string, flagKey: string): number {
const input = `${flagKey}.${userKey}`;
const hash = createHash('sha256').update(input).digest();
// Use first 4 bytes as a uint32
const value = hash.readUInt32BE(0);
return value % 100;
}
private evaluateRule(rule: FlagRule, context: EvaluationContext): boolean {
if (rule.type === 'default') return true;
if (rule.type === 'percentage') {
const bucket = this.getBucket(context.key, rule.variant);
return bucket < (rule.percentage ?? 0);
}
if (rule.type === 'individual' || rule.type === 'segment') {
const attribute = rule.attribute ?? 'key';
const contextValue = context[attribute];
if (contextValue === undefined) return false;
switch (rule.operator) {
case 'eq':
return contextValue === rule.values?.[0];
case 'in':
return rule.values?.includes(contextValue as string | number | boolean) ?? false;
case 'contains':
return typeof contextValue === 'string' &&
typeof rule.values?.[0] === 'string' &&
contextValue.includes(rule.values[0]);
case 'lt':
return typeof contextValue === 'number' &&
typeof rule.values?.[0] === 'number' &&
contextValue < rule.values[0];
case 'gt':
return typeof contextValue === 'number' &&
typeof rule.values?.[0] === 'number' &&
contextValue > rule.values[0];
default:
return false;
}
}
return false;
}
async evaluate<T>(
flagKey: string,
context: EvaluationContext,
defaultValue: T
): Promise<T> {
await this.ensureFresh();
const flag = this.flags.get(flagKey);
if (!flag || !flag.enabled) return defaultValue;
for (const rule of flag.rules) {
if (this.evaluateRule(rule, context)) {
const variant = flag.variants[rule.variant];
return (variant as T) ?? defaultValue;
}
}
const defaultVariant = flag.variants[flag.defaultVariant];
return (defaultVariant as T) ?? defaultValue;
}
async getBoolVariation(
flagKey: string,
context: EvaluationContext,
defaultValue: boolean
): Promise<boolean> {
return this.evaluate<boolean>(flagKey, context, defaultValue);
}
async getStringVariation(
flagKey: string,
context: EvaluationContext,
defaultValue: string
): Promise<string> {
return this.evaluate<string>(flagKey, context, defaultValue);
}
}
Using the Client in an Express API
// app.ts
import express from 'express';
import { FeatureFlagClient } from './flag-client';
import type { EvaluationContext } from './types';
const app = express();
const flags = new FeatureFlagClient({
endpoint: 'https://flags.internal.mycompany.com/api/flags',
cacheTtlMs: 15_000,
});
// Initialize once at startup — client handles refresh internally
await flags.initialize();
app.get('/api/recommendations', async (req, res) => {
const userId = req.headers['x-user-id'] as string;
const userPlan = req.headers['x-user-plan'] as string;
const context: EvaluationContext = {
key: userId,
plan: userPlan,
region: process.env.AWS_REGION ?? 'us-east-1',
};
// Check flag — returns false if flag is undefined or user is not in rollout
const useNewRecommendationEngine = await flags.getBoolVariation(
'new-recommendation-engine',
context,
false
);
if (useNewRecommendationEngine) {
const results = await newRecommendationEngine(userId);
return res.json({ results, engine: 'v2' });
}
const results = await legacyRecommendationEngine(userId);
return res.json({ results, engine: 'v1' });
});
Kill Switch Pattern
Kill switches are boolean flags that default to true and turn a feature off when triggered. This is the opposite of a rollout flag. The naming convention matters for clarity:
// Kill switch: defaults to ON, turned OFF in an emergency
const featureKilled = await flags.getBoolVariation(
'kill-new-payment-processor',
context,
false // default: not killed
);
if (featureKilled) {
return legacyPaymentProcessor.charge(amount);
}
return newPaymentProcessor.charge(amount);
Kill switches should be pre-created for every high-risk feature before deployment. When a production incident occurs, the last thing you want to do is create a new flag, configure it, and deploy it. The flag should already exist and be toggleable in seconds.
Choosing a Rollout Strategy
Comparison and Tradeoffs
Self-Hosted vs SaaS
The build-vs-buy decision for feature flags is not trivial. Here is a practical comparison across the most relevant dimensions.

| Dimension | Unleash (self-hosted) | Flagsmith (self-hosted) | LaunchDarkly (SaaS) | Statsig (SaaS) |
|---|---|---|---|---|
| Evaluation location | SDK-side (local) | SDK-side (local) | SDK-side (local) | SDK-side + edge |
| Data residency | Full control | Full control | US/EU options | US primary |
| Pricing | Free (OSS) + Enterprise | Free (OSS) + Cloud | From $20k/yr (enterprise) | Usage-based |
| Latency | < 1ms (local eval) | < 1ms (local eval) | < 1ms (local eval) | < 1ms (local eval) |
| Analytics / experiments | Basic | Basic | Full A/B + stats | Advanced stats engine |
| Ops burden | High (DB, servers, HA) | Medium | None | None |
| Audit logs | Yes (Enterprise) | Yes | Yes | Yes |
| Edge / CDN flags | No | No | LaunchDarkly Edge | Statsig on Vercel/Cloudflare |
| Best for | Cost-sensitive, data-sovereign | Mid-size, mixed cloud | Enterprise, full experiments | Experiment-heavy products |
Choose self-hosted if:
- You have GDPR or data sovereignty requirements that prevent user data leaving your infrastructure
- You are running at a scale where SaaS per-seat or per-MAU pricing becomes expensive (> 10M MAUs)
- You have the DevOps capacity to run and maintain the service reliably
Choose SaaS if:
- You want to ship feature flag infrastructure in days, not months
- You need advanced experimentation capabilities (sequential testing, CUPED variance reduction)
- Your team is small and cannot afford the ops burden of a self-hosted system
Flag Evaluation Performance
One common concern is whether flag evaluation adds latency to request paths. The answer is: it should not, and here is why.
All production-grade feature flag SDKs (LaunchDarkly, Unleash, Flagsmith, Statsig) use a local evaluation model. The SDK downloads a snapshot of all flag rules at startup and on a polling interval (typically 30 seconds). Evaluation is then done entirely in-memory, against local data, with no network call required per evaluation.
The cost of a flag evaluation in this model is roughly:
- Hash computation: ~1 microsecond
- Rule traversal: ~5–20 microseconds for a typical ruleset
Compared to a database query (1–10ms) or an external API call (10–200ms), flag evaluation is effectively zero-cost.
The one exception is streaming-based updates. SDKs like LaunchDarkly maintain a persistent SSE connection to receive flag changes in real time (< 200ms propagation), rather than waiting for the next polling interval. This is important for kill switches where a 30-second delay is too long.
Production Considerations
Flag Lifecycle and Stale Flag Debt
Feature flags accumulate. A team that ships two features per week can have 100 flags after a year. Without discipline, these become permanent conditionals in the codebase — dead code paths that no one dares remove, flags that are always on but never cleaned up, and rules that reference segments that no longer exist.
Stale flags are a form of technical debt that compounds over time:
- Readability: Code with many flag conditionals is harder to reason about. What code path actually runs in production?
- Testing burden: Every combination of flag states is theoretically a different code path to test.
- Performance: Even with local evaluation, a ruleset with 500 flags is slower to download and parse than one with 50.
The solution is a flag lifecycle policy enforced through tooling:
// Flag definition with mandatory expiry metadata
interface FlagDefinition {
key: string;
enabled: boolean;
variants: Record<string, unknown>;
rules: FlagRule[];
defaultVariant: string;
metadata: {
createdAt: string; // ISO date
owner: string; // team or individual
expiresAt: string; // ISO date — mandatory
jiraTicket?: string; // cleanup ticket
type: 'release' | 'experiment' | 'kill-switch' | 'ops';
};
}
Recommended expiry windows:
| Flag Type | Max Lifetime |
|---|---|
| Release flag | 2 weeks after 100% rollout |
| Experiment flag | Duration of experiment + 1 week |
| Kill switch | Indefinite (but reviewed quarterly) |
| Ops flag | Indefinite (but reviewed quarterly) |
Integrate expiry checks into your CI pipeline so that a PR adding a flag without an expiry date fails the build. And track overdue flag cleanup in your sprint velocity — it is real work.
Monitoring and Observability
Flag evaluations should be emitted as metrics and structured logs:
// Instrumented evaluation wrapper
async function evaluateWithMetrics<T>(
client: FeatureFlagClient,
flagKey: string,
context: EvaluationContext,
defaultValue: T
): Promise<T> {
const start = performance.now();
let variant: string | undefined;
let error: Error | undefined;
try {
const result = await client.evaluate<T>(flagKey, context, defaultValue);
variant = JSON.stringify(result);
return result;
} catch (err) {
error = err as Error;
return defaultValue;
} finally {
const durationMs = performance.now() - start;
metrics.histogram('feature_flag.evaluation_duration_ms', durationMs, {
flag: flagKey,
});
logger.info('feature_flag.evaluated', {
flag: flagKey,
userKey: context.key,
variant,
durationMs,
error: error?.message,
});
}
}
Set up dashboards that show:
- Evaluation volume by flag (which flags are hottest?)
- Error rate per flag variant (is variant B causing more 5xx than variant A?)
- Flag propagation latency (how quickly do changes reach production SDKs?)
- Stale evaluation warnings (flags evaluated after their expiry date)
Trunk-Based Development and Feature Flags
Feature flags are the enabling technology for trunk-based development (TBD) — the practice where all developers commit directly to main at least once per day. With TBD, there are no long-lived feature branches, which eliminates the merge conflict tax and the integration risk of big-bang merges.
The pattern is straightforward: every in-flight feature is wrapped in a flag from day one. Developers commit incomplete code behind a flag that is globally disabled. The code ships to production but is invisible. Once the feature is complete and the flag is enabled, it becomes live — with full rollout control.
// Day 1 commit — feature is incomplete but ships behind a flag
async function handleSearch(query: string, userId: string): Promise<SearchResult[]> {
const context: EvaluationContext = { key: userId };
const useNewSearchEngine = await flags.getBoolVariation(
'new-search-engine', // globally off — safe to ship incomplete
context,
false
);
if (useNewSearchEngine) {
// TODO: This is a stub — full implementation in next commit
return newSearchEngine.query(query);
}
return legacySearch(query);
}
This model has a profound effect on team dynamics. Developers stop hoarding code on local branches. Code review happens in smaller, more reviewable chunks. And the main branch is always deployable, because every in-flight feature is safely dark.
Progressive Delivery Lifecycle
The Gantt diagram above represents the ideal lifecycle. Notice two things: the rollback path (kill switch) is available throughout the entire rollout period, and the cleanup phase is scheduled immediately after full release — not as an afterthought.
Conclusion
Feature flags have matured from a scrappy workaround into a first-class engineering practice. In 2026, progressive delivery is table stakes for any team that cares about deployment safety and velocity.
The key ideas to take forward:
Decouple deployment from release. Shipping code and exposing features to users are two separate events. Feature flags give you control over when the second event happens, independently of the first.
Use the right flag type for the job. Boolean flags for simple rollouts and kill switches. Multivariate flags for experiments and configuration management. Avoid proliferating multiple related booleans when a single JSON flag captures the intent more clearly.
Build with the evaluation model in mind. User context, rule priority, and consistent hashing for percentage bucketing are the core mechanics. Understand them whether you are using an SDK or rolling your own.
Pick your platform based on your constraints. Self-hosted solutions (Unleash, Flagsmith) give you data sovereignty and cost control at the price of operational overhead. SaaS solutions (LaunchDarkly, Statsig) give you speed and advanced experimentation at a cost that scales with your user base.
Treat stale flags as debt, not decoration. Every flag that outlives its purpose is a cognitive tax on every developer who reads that code path. Build expiry enforcement into your process from the start.
Combine flags with trunk-based development. The two practices amplify each other. Trunk-based development eliminates merge risk. Feature flags eliminate release risk. Together, they enable the continuous delivery culture that high-performing engineering organizations depend on.
The most important step is to start. Pick one high-risk feature that is about to ship, wrap it in a flag, and do your first percentage rollout. Watch what you can do when deployment stops being a cliff jump and becomes a dial you turn.
Next up: We will look at how Statsig's experiment platform goes beyond basic A/B testing — sequential testing, CUPED variance reduction, and multi-armed bandits for adaptive rollouts.
Sources
- LaunchDarkly — Feature Flag Best Practices — Naming conventions, lifecycle management, and rollout strategies
- Unleash — Open Source Feature Management — Self-hosted feature flag platform referenced throughout
- Flagsmith documentation — Self-hosted/SaaS alternative; remote config and segment targeting
- Statsig — Feature Gates and Experiments — Experimentation layer used in the A/B testing section
- Martin Fowler — "Feature Toggles (aka Feature Flags)" — The canonical categorisation of flag types (release, experiment, ops, permission)
- Trunk-Based Development — The complementary practice that makes short-lived feature branches work with flags
- Accelerate: The Science of Lean Software and DevOps (DORA, 2018) — The DORA research behind the claim that feature flags enable elite deployment frequency with lower change failure rates
About the Author
Toc Am
Founder of AmtocSoft. Writing practical deep-dives on AI engineering, cloud architecture, and developer tooling. Previously built backend systems at scale. Reviews every post published under this byline.
Published: 2026-04-14 · Written with AI assistance, reviewed by Toc Am.
Get These In Your Inbox
Weekly deep-dives on AI engineering, no fluff. Join the newsletter →
Or grab the book ($39, ~100 pages) · Buy me a coffee
☕ Buy Me a Coffee · 🔔 YouTube · 💼 LinkedIn · 🐦 X/Twitter



No comments:
Post a Comment