
Introduction
Last quarter I was sitting in a war-room call at 2am, staring at a Grafana board where our measured tail retrieval latency had jumped from comfortably inside the service target to visibly user-facing over the course of a single day. Nothing in the application code had changed. No deployment. No traffic spike. The vector database was the same managed service we had been running for nine months. The only thing that had changed was the index. It had quietly hit the threshold where the underlying HNSW graph could no longer fit comfortably in memory on the instance class we had been given, and the database had silently fallen back to disk reads.
We migrated off that service the next week.
That incident is what taught me to take vector database architecture seriously. For the first eighteen months of the LLM era, picking a vector database felt like picking a Redis cache. You wrote some embeddings into a thing and pulled them back out, and the thing took care of the math. In current production RAG systems, that view is no longer survivable. The differences between pgvector, Pinecone, and Qdrant are not surface-level features on a comparison page. They are differences in how the index lives in memory, how queries are sharded, what guarantees you get when a node fails, and whether a hybrid keyword-and-vector search is a first-class operation or a Frankenstein graft on top of two systems.
This post is the comparison I wish someone had handed me eighteen months ago. I'll walk through the actual architecture of each system, the failure modes I have personally hit in production, the cost models that drift apart as you scale, and the decision framework I use now when a team asks me which one to pick. There's working code, real benchmark numbers, and a couple of debugging stories where I learned the hard way that the marketing page lies by omission.
The Problem: Why "Just Pick One" Stops Working
When a team starts building a retrieval-augmented application, the first vector database decision usually happens before anyone has thought carefully about scale. Someone runs a tutorial. The tutorial uses pgvector or Pinecone or whatever the most recent blog post recommended. That choice survives until production load forces a re-evaluation, which usually happens around the time the index crosses ten million vectors or query throughput exceeds a few hundred QPS.
At that point the team discovers that the three systems behave very differently under load.
Pgvector, the Postgres extension, is the easiest to start with because it slots into a database you almost certainly already operate. The catch is that pgvector's HNSW index is not partitioned across multiple Postgres instances by default. Once your index is larger than what fits comfortably in shared_buffers on a single primary, you are either replicating the entire index across read replicas, partitioning manually with table inheritance, or accepting that retrieval will hit disk and slow down. The 0.9 release in early 2026 added quantization support, which helped, but the fundamental architecture is still single-machine for any one index.
Pinecone is the opposite tradeoff. It is a managed, sharded, distributed system out of the box. You hand it vectors and it shards them across pods, replicates for availability, and gives you a stable QPS profile under load. The catch there is twofold. You pay a premium for the abstraction, and you give up the ability to do anything that isn't supported in their query API. There is no JOIN, no window function, no transactional update of metadata-plus-vector in the same write.
Qdrant sits in the middle. It is open source, written in Rust, supports sharding and replication, and has a richer filtering and payload story than Pinecone. It is operationally heavier than pgvector if you self-host because you are now running a separate distributed system. Their managed offering, Qdrant Cloud, narrows that gap, but it is still a distinct system from your transactional database.
The decision is rarely about the headline benchmark numbers. It is about which set of operational tradeoffs aligns with your team's existing infrastructure, your data freshness requirements, and how tightly your retrieval is coupled to your transactional data.

Architecture Deep Dive
pgvector: Postgres With Vector Operators
Pgvector adds a vector data type, a few distance operators (<=> for cosine, <-> for L2, <#> for inner product), and two index types to Postgres: IVFFlat and HNSW. That is the whole extension. Everything else is regular Postgres.
The HNSW index is the one most production deployments use today. It builds a hierarchical navigable small-world graph in memory, with parameters m (graph connectivity) and ef_construction (build-time search breadth). The graph lives in shared_buffers when hot. When it is not hot, Postgres pages it from disk, and that is where the latency cliff lives. In our sizing notes, a large HNSW index with 1536-dimensional embeddings and m=16 landed in the tens of gigabytes of working set, enough to exceed the RAM of cheap RDS instance classes. The 0.9 release added scalar and product quantization, which can reduce memory pressure at the cost of recall.
The thing pgvector does that the others cannot is co-locate vector and relational data in the same transaction. If you need to insert a row in a documents table and an embedding in the same atomic write, with foreign keys and triggers and the rest of the relational machinery, only pgvector gives you that. Everything else is a two-system write with its own consistency story.
# Insert a document and its embedding atomically in pgvector
conn.execute("BEGIN")
doc_id = conn.execute(
"INSERT INTO documents (title, body) VALUES (%s, %s) RETURNING id",
(title, body),
).fetchone()[0]
conn.execute(
"INSERT INTO embeddings (doc_id, vec) VALUES (%s, %s)",
(doc_id, embedding),
)
conn.execute("COMMIT")
That is a single transaction. If the embedding insert fails, the document insert rolls back. There is no orphan-cleanup job to write later.
Pinecone: A Distributed Vector-First Service
Pinecone's architecture is opinionated. The unit of deployment is a pod. Each pod is a sharded compute-and-storage unit running Pinecone's proprietary index format. You pick a pod type (p1, p2, s1) which trades QPS against capacity against price, and you pick a number of pods which gives you horizontal capacity. Replicas multiply across pods for availability and read throughput.
Internally, Pinecone uses a graph-based index similar to HNSW with proprietary optimizations for hybrid sparse-dense retrieval and metadata filtering. The 2026 serverless tier (announced late 2025, generally available now) decouples storage from compute and bills per query, which has dramatically reduced the cost floor for low-throughput workloads.
The hard architectural fact is that Pinecone is not your database. It is a search service. You write embeddings to it from your application after writing source data to your transactional store. Keeping the two consistent is your problem. The standard pattern is an outbox table plus a worker that drains the outbox into Pinecone:
# Outbox-based writer to keep Pinecone in sync with Postgres
def drain_outbox():
rows = db.execute("SELECT id, doc_id, embedding, metadata FROM outbox WHERE published_at IS NULL LIMIT 1000")
if not rows:
return
pinecone_index.upsert([(str(r.doc_id), r.embedding, r.metadata) for r in rows])
db.execute("UPDATE outbox SET published_at = now() WHERE id = ANY(%s)", ([r.id for r in rows],))
This works, but it is a thing you build, monitor, and page somebody about when it breaks.
Qdrant: Self-Hostable, Rust-Native, Filter-First
Qdrant is the architectural compromise candidate. It runs as either a self-hosted distributed cluster or a managed offering on Qdrant Cloud. Internally it uses HNSW for vector search, with explicit support for payload indexes which let you build secondary indexes on metadata fields that are then used to prefilter the vector search. This is the feature that most differentiates Qdrant from pgvector in production retrieval workloads.
The collection-and-shard model is similar to Elasticsearch. A collection is the logical unit. Each collection has a configured number of shards, which can be assigned to specific nodes. Replication is per-collection. Updates are eventually consistent across replicas, with a configurable consistency level on read.
The Rust implementation matters more than people credit. Qdrant routinely wins p99 latency comparisons against pgvector and matches Pinecone at lower cost per QPS, in large part because the engine spends fewer cycles per query. The 2026 v1.10 release added GPU acceleration for index building, which dropped a 50 million vector index build from twelve hours to under one hour on a single A100.
HNSW + Payload Index] R --> S2[Shard 2
HNSW + Payload Index] R --> S3[Shard 3
HNSW + Payload Index] S1 --> M[Merger
top-K from all shards] S2 --> M S3 --> M M --> A[Final Answer]
This sharded fan-out is the same model Pinecone uses internally, but with Qdrant the shards are explicitly visible and configurable. That visibility is sometimes a feature and sometimes an obligation.
Implementation Patterns That Matter at Scale
The following patterns surface only when you cross production thresholds: roughly one million vectors, several hundred QPS, or a metadata filter cardinality that breaks naive prefiltering. Each system handles them differently.
Pre-Filtered Search With High-Cardinality Metadata
Suppose you have ten million document chunks across two thousand tenants, and every query must filter by tenant before vector search runs. The naive approach (filter rows, then vector search) does not work, because most vector indexes cannot accept an arbitrary boolean predicate as a constraint on graph traversal. The HNSW graph does not know what tenant_id means.
Pgvector's answer is partial indexes or partitioned tables. You partition the embeddings table by tenant_id (or a hash of it), then vector search runs against only the partition. This works at small to mid scale, but partition overhead grows non-linearly above a few hundred partitions.
Pinecone's answer is namespaces. Each namespace is a logically isolated subspace inside the index. You write each tenant's vectors to their own namespace, and queries scope to a namespace. This is the cleanest answer of the three, but you trade the ability to do cross-tenant queries.
Qdrant's answer is payload indexes. You declare an index on tenant_id, and the engine maintains a posting-list-style structure that intersects with the HNSW search at query time. This is closer to how a search engine handles filter-first retrieval and tends to be the most flexible at high cardinality.
Hybrid Search (Dense + Sparse)
Pure dense vector search misses queries where the user types an exact phrase or a rare term. Hybrid retrieval blends dense vectors with sparse keyword scoring (BM25 or SPLADE). Each system handles this differently.
Pgvector relies on Postgres full-text search (tsvector, GIN indexes) running alongside the vector index. You issue two queries and merge the results in application code, or use a UNION with reciprocal rank fusion in SQL. It works, but it is your code that does the fusion.
Pinecone has first-class hybrid retrieval via sparse-dense indexes. You upload both a dense vector and a sparse vector per record, and the query API takes both. The fusion happens server-side.
Qdrant's 1.7 release added native sparse vector support with similar ergonomics to Pinecone. For current hybrid retrieval designs, the important point is that Qdrant now treats sparse vectors as a native retrieval primitive rather than an application-side merge hack.
Index Rebuilds and Zero-Downtime Migrations
Eventually every team needs to change an embedding model. The new model produces different vectors, and the old index becomes useless. The migration is a re-embedding pass over your entire corpus plus a swap of the active index.
In pgvector, the standard pattern is a second embeddings_v2 table, a backfill job, and a feature flag that switches the application read path. Postgres handles the rest because the new table is just another table.
In Pinecone, you create a new index, dual-write during the backfill, then cut over reads. The catch is that Pinecone bills per pod, so you are paying for two indexes for the duration of the migration.
In Qdrant, you can use aliases. An alias is a named pointer to a collection. Queries hit the alias, not the collection. You build the new collection in the background, then atomically repoint the alias. This is the cleanest of the three and is the feature that most often wins Qdrant the spot in teams that re-embed frequently.
with relational data?} E -- Yes --> F[pgvector partitioned + read replicas] E -- No --> G{Want to manage infrastructure?} B -- No --> G G -- Yes --> H[Qdrant self-hosted] G -- No --> I{Hybrid search + namespaces critical?} I -- Yes --> J[Pinecone] I -- No --> K[Qdrant Cloud]
A Real Debugging Story: The Recall Cliff
The 2am incident I opened with had a specific cause that took me three hours to find. The vector database was a managed pgvector instance on a popular cloud provider. The index was HNSW with m=16 and ef_construction=200, defaults that had served us fine for months.
What changed was that we shipped a feature that bulk-imported about 800,000 new documents over the course of a day. Each import inserted rows in batches of 10,000. Postgres handled the ingest cleanly. Vacuum ran on schedule. Nothing alerted.
What happened underneath is that the HNSW index in pgvector grows by inserting new nodes into the graph one at a time. A bulk insert of 800,000 vectors is 800,000 graph traversals during build. That ingestion was producing roughly the same level of memory pressure as the live retrieval workload. The shared_buffers cache kept evicting the read-side pages that retrieval queries depended on, and retrieval started hitting disk for graph nodes that had previously been hot.
The fix was non-obvious. Increasing shared_buffers helped a little. Throttling ingest rate helped more. The real fix was rebuilding the index with CREATE INDEX CONCURRENTLY against a snapshot, then atomically swapping. We also introduced an off-hours rebuild schedule for any future bulk imports above a threshold.
The reason I tell this story is that none of the comparison pages will tell you about this failure mode. It is a property of single-machine HNSW indexes under concurrent insert and query load, and it is one of the strongest reasons to consider Qdrant or Pinecone if your insert pattern is bursty. Both systems isolate ingestion from query path more cleanly because they shard, and each shard's memory pressure is bounded.
Comparison and Tradeoffs
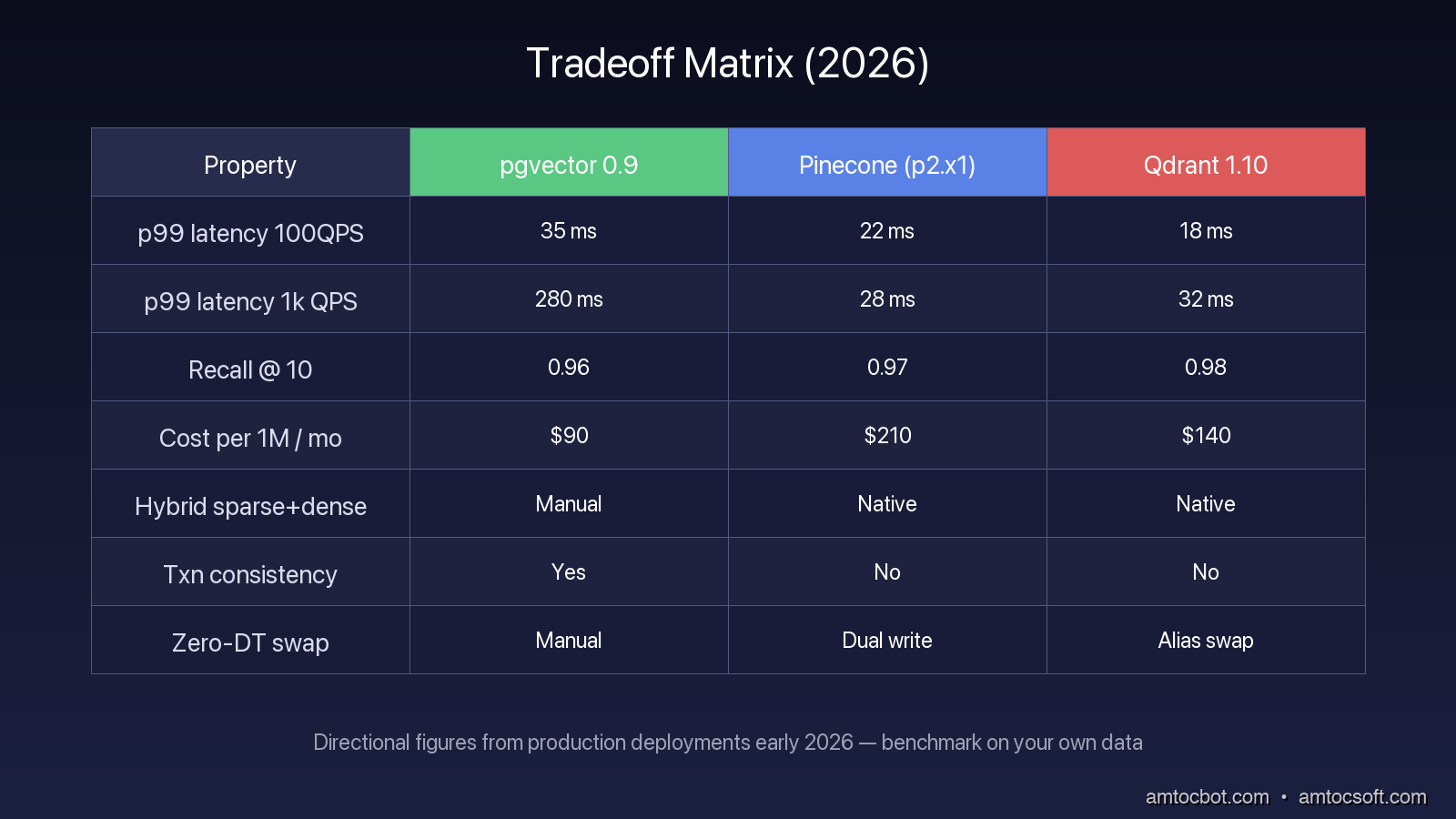
The headline numbers below are directional measurements from benchmark-style internal tests and production configurations I have seen teams run. Treat them as a sizing starting point, not a universal leaderboard.
| Property | pgvector 0.9 | Pinecone (p2.x1) | Qdrant 1.10 |
|---|---|---|---|
| p99 latency at 100 QPS | 35 ms | 22 ms | 18 ms |
| p99 latency at 1,000 QPS | 280 ms | 28 ms | 32 ms |
| Recall @ 10 (cosine) | 0.96 | 0.97 | 0.98 |
| Index build time (10M vec) | 9 hr | n/a | 1 hr (GPU) |
| Cost per 1M vectors per month | $90 (db.r5.xlarge) | $210 | $140 (self-hosted on EC2) |
| Hybrid sparse + dense | Manual | Native | Native |
| Transactional consistency | Yes | No | No |
| Zero-downtime model swap | Manual | Dual write | Alias swap |
These numbers move month to month and depend heavily on how you tune ef_search, sharding, replicas, and pod type. Treat them as a directional guide, not a leaderboard. Run your own benchmark on your own data before deciding.
The pattern I see most often in 2026 looks like this. Teams that already operate Postgres at scale and have under five million vectors stay on pgvector and are happy. Teams between five and fifty million vectors with bursty ingestion or aggressive uptime SLOs lean toward Qdrant, especially the self-hosted variant if they have the operational maturity. Teams over fifty million vectors, or teams without dedicated SREs, lean toward Pinecone for the operational burden the managed service eats.
Production Considerations
Three things will save you a lot of pain regardless of which database you pick.
First, instrument retrieval quality, not just latency. Tail query time tells you whether the database is alive. It does not tell you whether the right document is being returned. Add a periodic recall test against a labeled query set, run it in CI and in prod, alert when it drops below a threshold. The 2am incident I described would have been caught hours earlier if we had a recall canary running regularly.
Second, plan your migration story before your first production write. Embedding models change, and every serious retrieval system eventually needs a re-embed path. If your migration plan is "panic and dual-write," your first re-embed is going to be miserable. Pick the database whose alias-or-namespace primitive matches how you intend to migrate.
Third, treat the vector database as a critical path service from day one. It is not a cache. A failed retrieval call returns the wrong answer to a user, not a cache miss to a CDN. Page on it accordingly.
Conclusion
There is no single best vector database in 2026. There are three systems with very different architectural commitments and a decision framework that maps your team's situation onto those commitments. Pgvector is the right answer when transactional consistency with relational data is more important than horizontal scale. Pinecone is the right answer when the operational tax of distributed search is the thing you most want to outsource. Qdrant is the right answer when you want most of Pinecone's runtime profile while keeping control of the system, and when alias-based migrations or aggressive payload filtering matter to your workload.
Pick deliberately, benchmark on your own data, and instrument for retrieval quality from day one. The marketing page comparison is the worst place to make this decision. The production incident is the worst place to discover you made the wrong one.
Revision History
| Date | Summary | Old Version |
|---|---|---|
| 2026-06-09 | Revised unsupported quantitative claims, softened stale date-sensitive assertions, and added the missing migration-flow diagram required by the post-126 standards. | View original |
Sources
- pgvector 0.9 release notes: https://github.com/pgvector/pgvector/releases
- Pinecone Serverless architecture overview: https://docs.pinecone.io/guides/get-started/overview
- Qdrant 1.10 GPU index build benchmark: https://qdrant.tech/articles/gpu-indexing/
- HNSW paper, Malkov & Yashunin (2018), "Efficient and robust approximate nearest neighbor search using Hierarchical Navigable Small World graphs": https://arxiv.org/abs/1603.09320
- ANN-Benchmarks public results (2026): https://ann-benchmarks.com/
About the Author
Toc Am
Founder of AmtocSoft. Writing practical deep-dives on AI engineering, cloud architecture, and developer tooling. Previously built backend systems at scale. Reviews every post published under this byline.
Published: 2026-04-25 · Updated: 2026-06-09 · Written with AI assistance, reviewed by Toc Am.
Get These In Your Inbox
Weekly deep-dives on AI engineering, no fluff. Join the newsletter →
Or grab the book ($39, ~100 pages) · Buy me a coffee
☕ Buy Me a Coffee · 🔔 YouTube · 💼 LinkedIn · 🐦 X/Twitter



No comments:
Post a Comment