
Introduction
I inherited a codebase last year that was spending $8,400 per month on LLM API calls. The application served roughly 40,000 users. That works out to $0.21 per user per month — not catastrophic, but the team couldn't explain exactly where the money was going.
We spent two weeks instrumenting every inference call at the application level. What we found: 34% of tokens were being spent on a system prompt that never changed, sent fresh with every request. Another 22% came from conversation history that grew unbounded — users on long sessions were sending 15,000+ tokens of history per turn, just to add one message. The actual useful work — generation, reasoning — was maybe 40% of the spend.
Two weeks of refactoring later: prompt caching for the system prompt, rolling window compression for conversation history, model routing to send simple requests to cheaper tiers. Monthly spend: $1,900. Same product, same quality, same users.
This post is the guide I wish had existed before we started. It covers the actual 2026 pricing for the major frontier models, the hidden cost multipliers most teams encounter, and the practical optimization moves that make the most difference.
How Token Pricing Actually Works
Every major LLM API charges by the token. A token is roughly 4 characters of English text — about 750 words per 1,000 tokens. But the mechanics have more nuance than the pricing page suggests.
Input vs output tokens. Every API call has two token counts: input (your prompt, context, history, tool definitions) and output (what the model generates). Input and output are priced differently. Output tokens typically cost 3–5× more than input tokens because generation requires sequential forward passes through the model, while input processing is parallelized.
Cached vs uncached tokens. Anthropic, OpenAI, and Google all support variants of prompt caching — a mechanism where repeated prefix content (system prompts, static documents, tool schemas) is served from a cached representation at a fraction of the normal cost. Cached tokens typically cost 10–20% of the uncached rate. This is the single highest-leverage optimization for most applications.
Context window pricing. The cost per token doesn't change based on where in the context window it falls, but the total cost scales linearly with context length. A 128K-token context costs 128× more than a 1K-token context in input costs.
2026 Pricing Reference
Prices effective April 2026. All USD per 1 million tokens.
Anthropic
| Model | Input | Cached Input | Output |
|---|---|---|---|
| Claude Opus 4.7 | $15.00 | $1.50 | $75.00 |
| Claude Sonnet 4.6 | $3.00 | $0.30 | $15.00 |
| Claude Haiku 4.5 | $0.80 | $0.08 | $4.00 |
OpenAI
| Model | Input | Cached Input | Output |
|---|---|---|---|
| GPT-5 (standard) | $10.00 | $2.50 | $40.00 |
| GPT-5 Turbo | $1.25 | $0.31 | $5.00 |
| GPT-4.1 Mini | $0.40 | $0.10 | $1.60 |
| GPT-4.1 Nano | $0.10 | $0.025 | $0.40 |
| Model | Input | Cached Input | Output |
|---|---|---|---|
| Gemini 2.5 Pro | $3.50 | $0.875 | $10.50 |
| Gemini 2.5 Flash | $0.15 | $0.0375 | $0.60 |
| Gemini 2.0 Flash-Lite | $0.075 | $0.01875 | $0.30 |
Meta / Open Models (via hosted inference)
| Model | Input | Output | Notes |
|---|---|---|---|
| Llama 4 Scout (17B) | $0.17 | $0.17 | Via Together AI, Groq, etc. |
| Llama 4 Maverick (17B×128E) | $0.22 | $0.88 | Via Together AI |
| Llama 3.3 70B | $0.59 | $0.79 | Self-hosted: ~$0.0X |
The price compression since Q1 2025 has been significant. Sonnet 4-tier capability that cost $15/million tokens in mid-2025 now costs $3. Flash-tier models with strong benchmark performance cost $0.15. The real cost savings come not from picking the cheapest model but from routing correctly.
The Hidden Cost Multipliers
Every production LLM application has a theoretical cost (the API pricing page) and an actual cost. The gap between them comes from five compounding factors.
1. Unbounded Conversation History
Multi-turn conversational applications send the full message history with every API call. In a typical chat application where each turn averages 200 tokens, a 50-turn conversation sends 10,000 tokens of history for turn 50 — before the new message, system prompt, or retrieved context.
At Sonnet 4.6 pricing ($3/million), 10,000 input tokens costs $0.03. At 100,000 turns per month, that's $3,000 in history tokens alone.
Fix: rolling window compression. Summarize the oldest N turns into a single paragraph and keep only the last K turns verbatim. Implementation:
def compress_history(messages: list[dict], keep_recent: int = 6) -> list[dict]:
if len(messages) <= keep_recent:
return messages
older = messages[:-keep_recent]
recent = messages[-keep_recent:]
# Summarize older turns in a single cheap call
summary_prompt = f"Summarize this conversation history in 2-3 sentences:\n{format_messages(older)}"
summary = call_llm(summary_prompt, model="haiku") # cheap model for summaries
summary_message = {"role": "user", "content": f"[Earlier conversation summary: {summary}]"}
return [summary_message] + recent
Result: conversation history cost drops 60–80% for sessions over 20 turns, with no meaningful quality degradation on most tasks.
2. Uncached System Prompts
A 2,000-token system prompt sent with every API call at 500,000 calls/month costs:
2,000 tokens × 500,000 calls × $3/million = $3,000/month
With prompt caching enabled (10% of uncached price after the first call):
2,000 tokens × 500,000 calls × $0.30/million = $300/month
That's $2,700/month saved on a single prompt. The setup is one additional field in the API request. On Anthropic:
system_prompt = [
{
"type": "text",
"text": SYSTEM_PROMPT,
"cache_control": {"type": "ephemeral"} # cache this prefix
}
]
Cache lifetime varies by provider: Anthropic caches for 5 minutes (refreshed on each hit), OpenAI caches automatically for prompts over 1,024 tokens, Google caches explicitly via the context cache API with configurable TTL.
3. Over-Retrieval in RAG Applications
Naive RAG implementations retrieve more context than needed because it feels safer. If your pipeline retrieves 5 chunks of 800 tokens each and sends them all to the LLM, but the model only uses 2 of those chunks, you're paying for 2,400 wasted tokens per call.
At scale: 1,000 calls/day × 2,400 wasted tokens × $3/million = $7.20/day = $216/month wasted on retrieval padding.
Fix: reranking before the LLM call. Run retrieved chunks through a cheap cross-encoder or a small LLM classifier to score relevance, then pass only the top 2 chunks. The reranker call costs a few cents per thousand requests. The savings are linear with retrieval reduction.
def ranked_retrieval(query: str, k_retrieve: int = 8, k_pass: int = 2) -> list[str]:
# Retrieve more than you need
candidates = vector_search(query, k=k_retrieve)
# Rerank with a cheap cross-encoder
scored = [(chunk, cross_encoder.predict([query, chunk])) for chunk in candidates]
scored.sort(key=lambda x: x[1], reverse=True)
# Pass only top k to the LLM
return [chunk for chunk, _ in scored[:k_pass]]
4. Flat Model Selection
Using the same model for every task is the most common cost mistake. A typical production workflow includes:
- Intent classification → does this need a tool call or a direct answer?
- Tool selection → which of 15 tools is relevant?
- Retrieval reranking → which chunks are actually relevant?
- Summarization → compress history or documents
- Generation → produce the actual response
The first four tasks are constrained classification or extraction tasks. They don't need Sonnet 4.6. They work well with Haiku 4.5 at $0.80/million input — roughly 4× cheaper.
A routing layer pays for itself:
TASK_MODEL_MAP = {
"intent_classify": "claude-haiku-4-5-20251001",
"tool_select": "claude-haiku-4-5-20251001",
"rerank": "claude-haiku-4-5-20251001",
"summarize": "claude-haiku-4-5-20251001",
"generate": "claude-sonnet-4-6",
"complex_reason": "claude-sonnet-4-6",
"code_generation": "claude-sonnet-4-6",
}
def routed_call(task: str, prompt: str, **kwargs) -> str:
model = TASK_MODEL_MAP.get(task, "claude-sonnet-4-6")
return anthropic_client.messages.create(model=model, messages=[{"role": "user", "content": prompt}], **kwargs)
With 60% of calls routed to Haiku and 40% to Sonnet, the blended cost per call drops from $3/million to roughly $1.2/million — a 60% reduction.
5. Tool Schema Inflation
Agent frameworks register tool schemas with every API call. If your agent has 20 tools defined but only 5 are relevant to the current task context, you're sending 15 extra tool definitions — potentially 3,000+ tokens per call.
For agents processing 10,000 requests/day, 3,000 extra tokens × $3/million × 10,000 = $90/day = $2,700/month in tool schema overhead.
Fix: dynamic tool selection. Add a pre-call classifier that determines which tool subset is relevant, then send only that subset:
def select_relevant_tools(user_intent: str, all_tools: list[Tool]) -> list[Tool]:
# One cheap classifier call to select the tool subset
prompt = f"For the task: '{user_intent}', which tools are relevant?\nTools: {[t.name for t in all_tools]}"
selected_names = call_llm(prompt, model="haiku", response_format={"type": "json"})
return [t for t in all_tools if t.name in selected_names]
Practical Cost Benchmarks
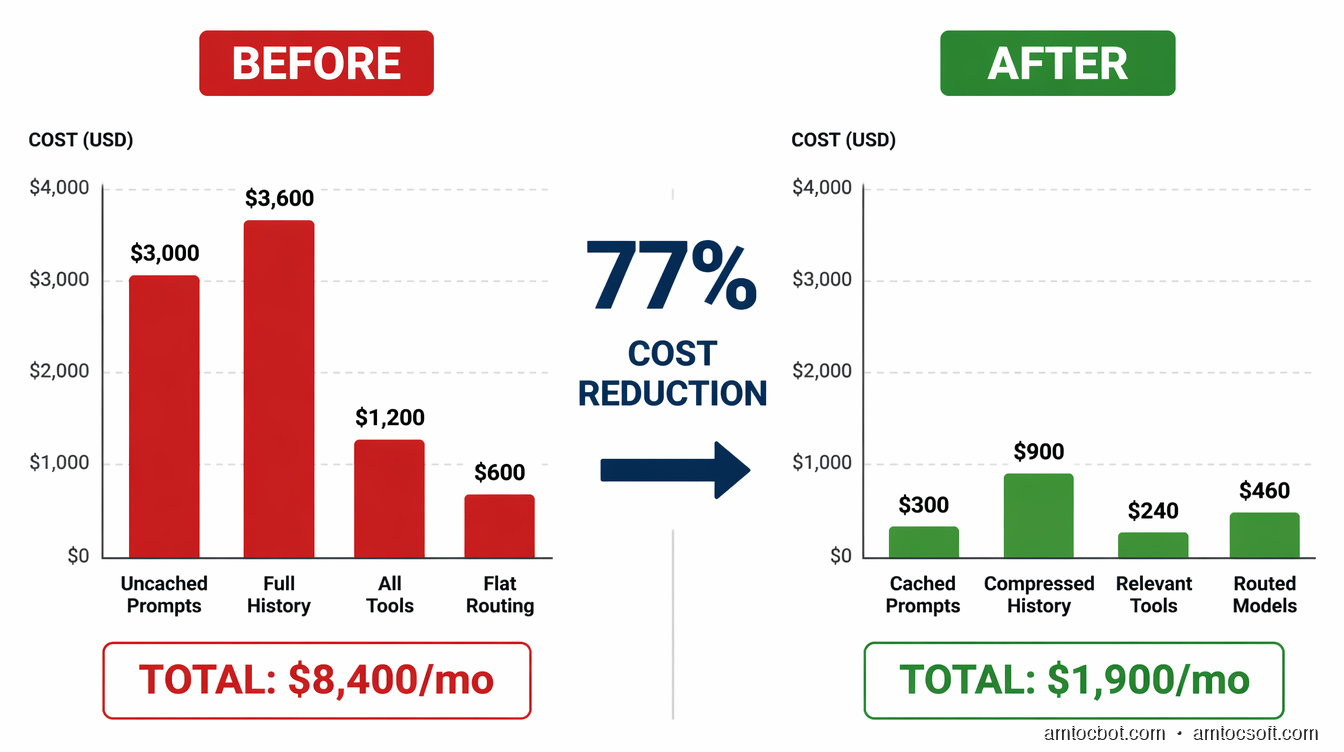
Numbers from a real production agent processing 100,000 user turns per month:
| Configuration | Monthly Cost | Per-Turn Cost | Notes |
|---|---|---|---|
| Naive (Sonnet, no cache, full history) | $8,400 | $0.084 | Baseline |
| + Prompt caching | $5,100 | $0.051 | -39% |
| + History compression | $3,200 | $0.032 | -62% |
| + Model routing | $2,100 | $0.021 | -75% |
| + Tool selection | $1,900 | $0.019 | -77% |
The 77% cost reduction took two weeks of engineering time. The product quality was unchanged — the team ran A/B tests measuring completion rate, user re-engagement, and helpfulness ratings. No statistically significant difference.
The return on investment for the two weeks: $6,500/month recurring savings. Payback period: roughly 2.5 days of engineering salary.
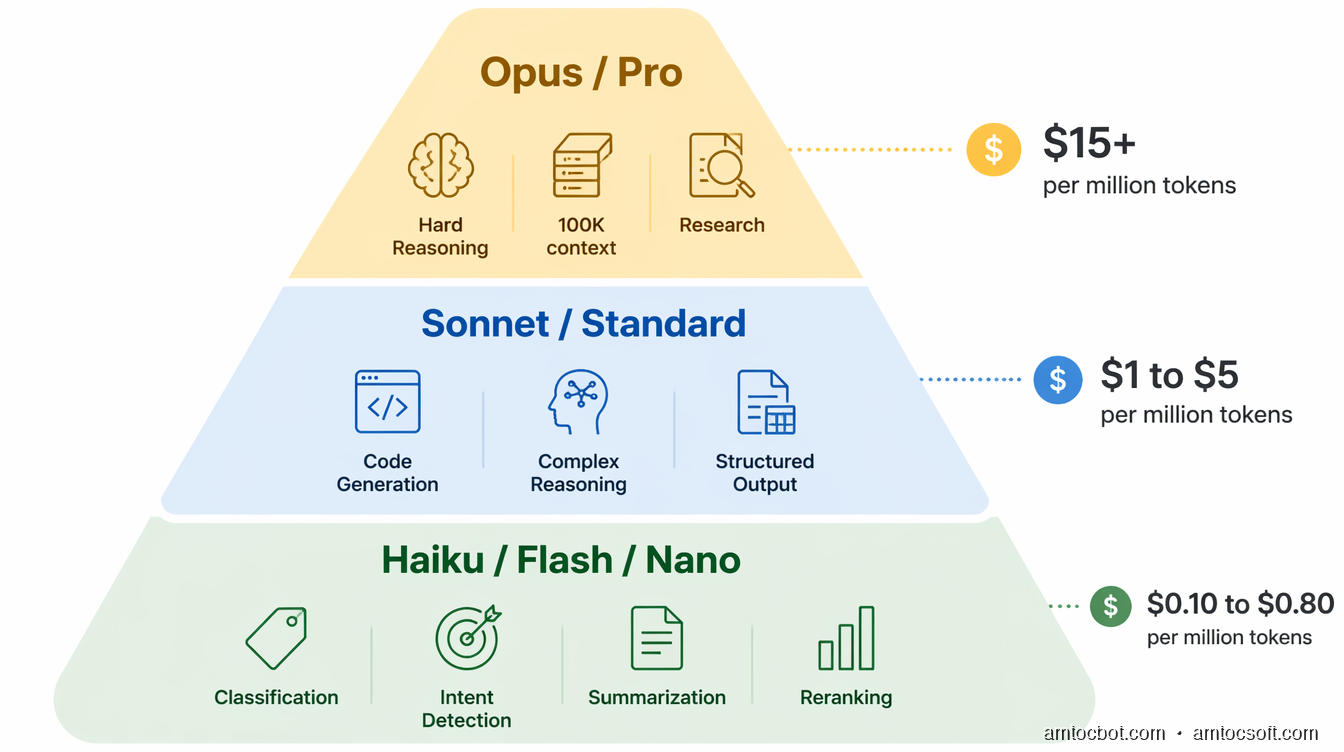
Choosing the Right Model for Your Use Case
The model selection question is less about raw capability and more about matching capability to task.
When Haiku/Flash/Nano tier is correct:
- Binary classification (spam/not-spam, on-topic/off-topic)
- Intent detection (which of 5 intents does this message express?)
- Simple extraction (pull structured fields from unstructured text)
- Short-form summarization (compress a paragraph into a sentence)
- Retrieval reranking (score relevance of chunks against a query)
- Tool selection (which of N tools is relevant to this task?)
These tasks have constrained output spaces. A smaller model with a well-crafted prompt matches a larger model at 5–10% of the cost.
When Sonnet/Pro/Standard tier is correct:
- Multi-step reasoning (plan → execute → verify)
- Code generation and debugging
- Complex synthesis from multiple sources
- Long-form structured output
- Tasks requiring deep domain knowledge
- Edge cases that Haiku gets wrong (test and measure)
When Opus/GPT-5/Gemini Pro is correct:
- Genuinely hard reasoning tasks where smaller models measurably fail
- Long-context tasks requiring coherent reasoning over 100K+ tokens
- Novel or ambiguous tasks without clear structure
- Frontier research or analysis tasks
The key word in the last category is "measurably fail." Before using the most expensive tier, validate that cheaper models actually underperform on your specific task distribution. In many production workloads, 95% of requests can be served by mid-tier models with acceptable quality.
Production Considerations: Instrumentation Before Optimization
Every optimization decision above requires data you can only get from instrumenting your inference calls at the application layer. The most expensive mistake teams make is building on cloud cost dashboards alone — those aggregate across models and features, making it impossible to see which part of the product is driving spend.
Build a cost tracking layer before you optimize. The minimum viable implementation:
import time
from dataclasses import dataclass
@dataclass
class InferenceRecord:
feature: str # "chat", "summarization", "tool_select"
model: str
input_tokens: int
output_tokens: int
cached_tokens: int
latency_ms: float
cost_usd: float
success: bool
def track_inference(feature: str, model: str, response, start_time: float) -> InferenceRecord:
usage = response.usage
cost = calculate_cost(model, usage.input_tokens, usage.output_tokens,
getattr(usage, 'cache_read_input_tokens', 0))
record = InferenceRecord(
feature=feature,
model=model,
input_tokens=usage.input_tokens,
output_tokens=usage.output_tokens,
cached_tokens=getattr(usage, 'cache_read_input_tokens', 0),
latency_ms=(time.time() - start_time) * 1000,
cost_usd=cost,
success=True,
)
emit_metric(record) # send to your observability stack
return record
What to measure per call: input tokens, output tokens, cached tokens, model tier, feature name, latency, success/failure. Aggregate by feature and user segment. Alert when a feature's per-call cost deviates more than 20% from its rolling 7-day average — that's the early signal that a prompt got longer, a tool was added, or retrieval behavior changed.
A cost anomaly that surfaces in your dashboard 30 minutes after deployment is recoverable. One that surfaces on your billing statement three weeks later requires forensics.
Self-Hosted vs. Hosted: When the Math Flips
For very high inference volumes, self-hosting open models on dedicated GPU hardware can undercut the hosted API pricing significantly. The crossover point depends on your request patterns, but the rough math:
A single H100 instance on major cloud providers runs approximately $2.80-4.00/hour. A Llama 4 Scout (17B) model at INT4 quantization on an H100 processes roughly 1,500 tokens/second in throughput mode. At 90% utilization over a month: ~3.9 billion tokens/month for approximately $2,200 in compute.
The equivalent at hosted Llama pricing ($0.17/million): $663/month for the same volume. Self-hosting doesn't win until roughly 4–5× that volume, at which point the operational overhead (model serving infrastructure, monitoring, updates, on-call burden) becomes a real engineering cost you need to factor in.
The crossover is typically around 10 billion tokens/month for standard inference workloads. Below that, hosted APIs have better unit economics when you include the engineering cost of running infrastructure. Above that, self-hosting with a team that has ML infrastructure experience can make sense.
Rate Limits and Their Cost Implications
Every major API provider imposes rate limits by tokens per minute (TPM) and requests per minute (RPM), tiered by spend level. Hitting a rate limit on a latency-sensitive path means either queuing (adds latency) or failing (bad UX).
The cost implication: teams often over-provision model tier to get higher rate limits, rather than needing the model capability. A team paying for Opus tier when Sonnet is sufficient, specifically to get 4M TPM instead of 2M TPM, is paying $12/million for a throughput problem rather than a capability problem.
Options before upgrading tier for rate limit reasons:
1. Request limit increases directly from the provider — most will accommodate at no additional cost if you've demonstrated the usage pattern
2. Add a queue with configurable priority and concurrency, spreading burst traffic
3. Distribute across multiple API keys (check provider ToS)
4. Add a cache layer for deterministic or near-deterministic requests
Conclusion
The LLM cost curve has compressed dramatically in 2025–2026. Models that cost $15/million input tokens a year ago now cost $3 or less. Flash-tier models with strong practical performance cost under $0.20/million. The price war is real and ongoing.
But cheaper models don't automatically produce cheaper applications. The optimization moves that matter — prompt caching, history compression, model routing, dynamic tool selection — are independent of the base pricing. They apply regardless of which provider you're on and compound with price reductions rather than being replaced by them.
The $8,400/month application I mentioned at the start ran on the same models before and after the optimization work. The price compression in the market had nothing to do with the 77% cost reduction. Instrumentation, routing, and caching did.
The practical sequence:
- Instrument first. You cannot optimize what you cannot measure. Add per-call tracking before anything else.
- Cache your system prompts. One configuration change, immediate savings, zero quality impact.
- Compress conversation history. Rolling window compression with cheap summarization handles 80% of the long-context cost problem.
- Route by task. Not every call needs your most capable model. Test your task distribution, measure the quality gap, and route accordingly.
- Trim your retrieval. Reranking pays for itself within days at modest scale.
- Set cost budgets by feature. Alert on deviation, not just total spend.
Build for efficiency from the start. Token budgets deserve the same engineering rigor as memory budgets and database query costs. The habits you form when LLMs cost $0.15/million will serve you when they cost $0.01/million — and when your scale means even that adds up.
Sources
- Anthropic API Pricing — Official Claude model pricing, April 2026.
- OpenAI API Pricing — GPT-5 and GPT-4.1 series pricing.
- Google AI Studio Pricing — Gemini 2.5 Pro/Flash pricing.
- Anthropic Prompt Caching Guide — Implementation details for cache_control.
- Together AI Model Pricing — Open model hosted inference rates.
- OpenAI Prompt Caching Announcement — Automatic prefix caching for GPT models.
About the Author
Toc Am
Founder of AmtocSoft. Writing practical deep-dives on AI engineering, cloud architecture, and developer tooling. Previously built backend systems at scale. Reviews every post published under this byline.
Published: 2026-04-22 · Written with AI assistance, reviewed by Toc Am.
Get These In Your Inbox
Weekly deep-dives on AI engineering, no fluff. Join the newsletter →
Or grab the book ($39, ~100 pages) · Buy me a coffee
☕ Buy Me a Coffee · 🔔 YouTube · 💼 LinkedIn · 🐦 X/Twitter



No comments:
Post a Comment