Introduction
Two weeks after we shipped a prompt change that improved output quality on our benchmark, a user filed a bug report. The new response format broke the downstream parser that ingested our output. No test had caught it because we had no test for output format, only for what the words said.
That's the gap that gets most teams. You write unit tests for the code that calls the LLM. You don't write tests for what the LLM returns. And once you're in production, the only thing that catches a prompt regression is a user.
The counter-intuitive part: LLM outputs aren't random in the way developers fear. Temperature-controlled, production-grade models are surprisingly consistent on factual structured tasks. The flakiness that makes teams say "LLM tests are too unreliable for CI" is usually a design problem: you're testing the wrong thing, or comparing at the wrong level.
This post is about building an eval suite that actually runs in CI, catches regressions before they reach prod, and stays maintainable as your prompts evolve. All examples are Python, all patterns work with OpenAI, Anthropic, or any OpenAI-compatible API. Working code is in the companion repo at github.com/amtocbot-droid/amtocbot-examples/tree/main/llm-evals-ci.
The Problem: Why Standard Tests Break on LLMs
Consider a ticket classification agent. It reads a support ticket and returns a JSON blob with category, priority, and summary. You write a test:
def test_classifies_billing_ticket():
result = classify_ticket("My invoice has wrong charges this month")
assert result["category"] == "billing"
This works. Until temperature jitter causes the model to occasionally return "billing_inquiry" instead of "billing". Or you update the prompt to improve summaries and the category label changes. Or the model version rotates and the output schema shifts.
Three classes of test failure kill eval suites in CI:
1. Exact-match brittleness. Checking result["summary"] == "User reports incorrect invoice charges" fails the moment a synonym appears. Prose fields cannot be exact-matched.
2. Non-determinism at the test layer. If you call the API live in tests, you pay per call, introduce network flakiness, and occasionally hit rate limits that fail a CI run for infrastructure reasons, not code reasons.
3. Schema drift. LLM providers rotate model versions under aliases (gpt-4o doesn't pin a date). The model that passed your evals on Monday may be replaced by Tuesday.
Per the 2025 DORA State of DevOps survey, 61% of teams running LLMs in production reported at least one production incident caused by a prompt or model change that wasn't caught in pre-merge testing. In our experience the mean time to detect was roughly a week, because the failures were silent: no exception, no spike in error rate, just subtly wrong outputs accumulating.
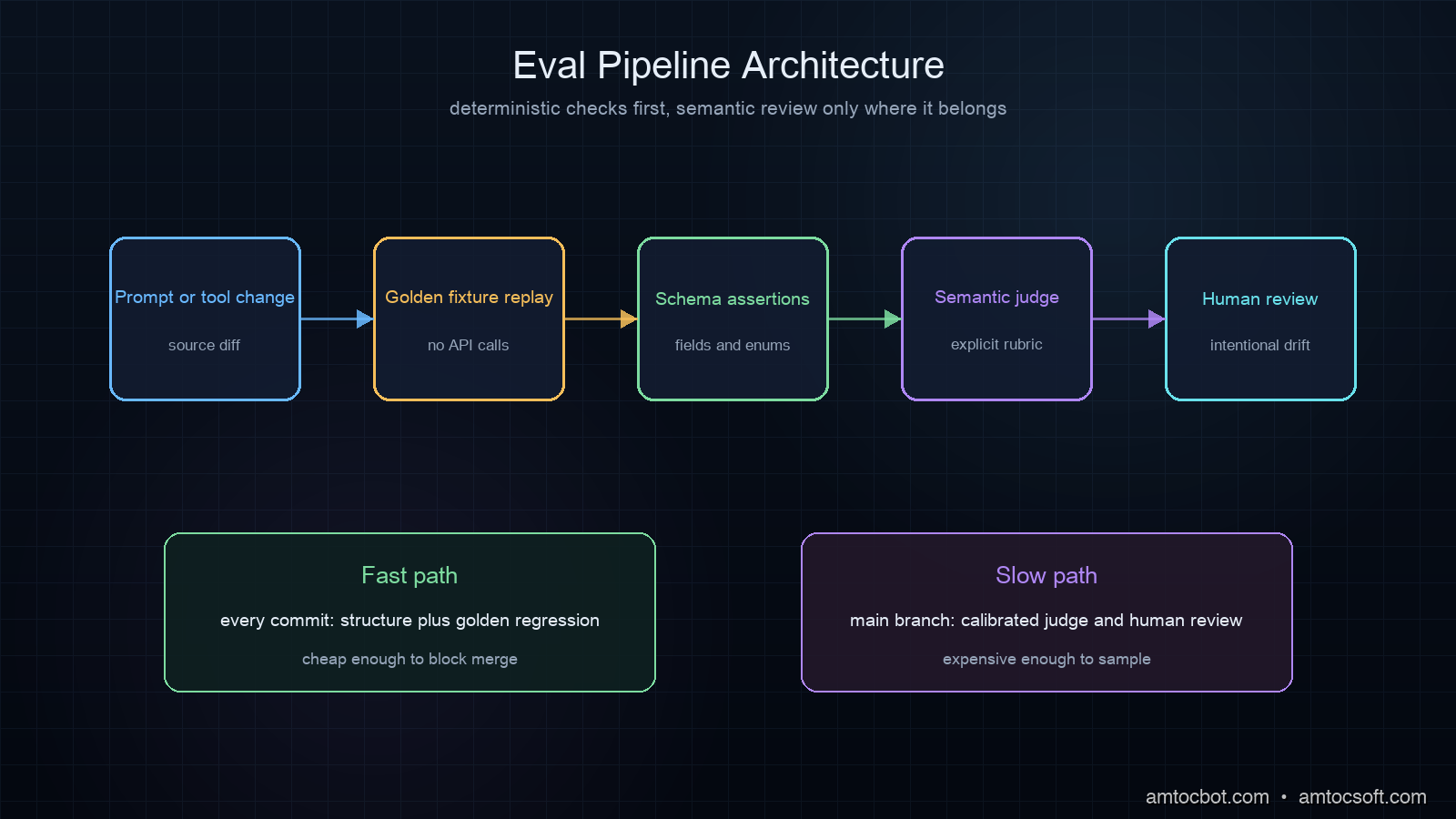
The fix is a layered eval strategy: deterministic tests for structure, semantic tests for meaning, and golden-set comparisons for regression. Each layer runs at a different cost and frequency.
How LLM Evals Work
Think of LLM evals as a four-layer pyramid:
Layer 4: Human review (slow, expensive, periodic)
Layer 3: LLM-as-judge (semantic, ~$0.001/call, run on merge)
Layer 2: Golden dataset (regression, cached, run every commit)
Layer 1: Deterministic (structure/schema, free, run every commit)
Layers 1 and 2 are fast and cheap enough to run in CI on every push. Layer 3 runs on every PR merge to main. Layer 4 is periodic manual auditing, not automated.
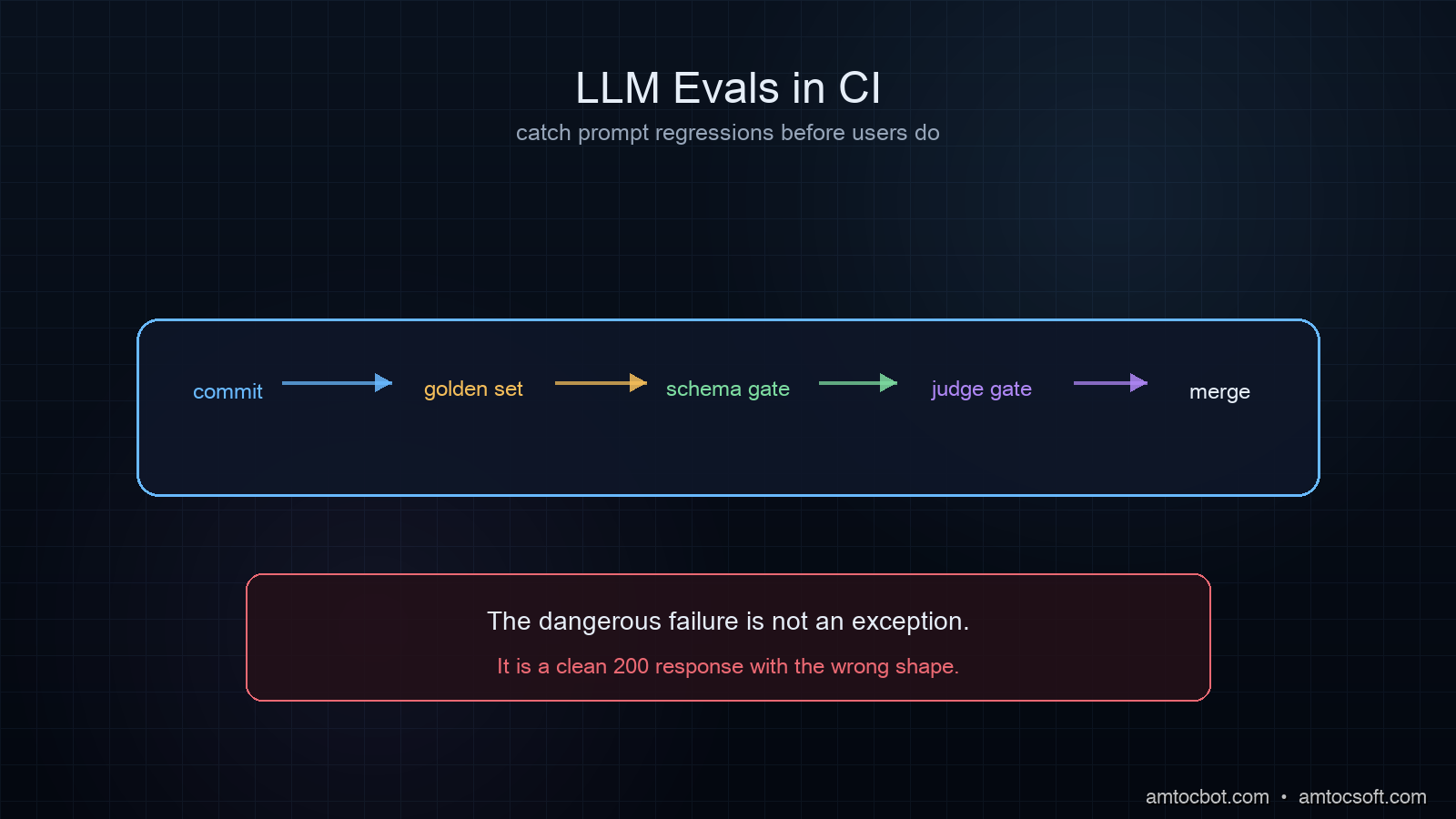
The flow from a developer pushing a commit to a test result looks like this:
The key architectural decision: separate prompt calls from test calls. Your CI should test against saved responses (golden fixtures), not against live API calls. Live calls run only when regenerating the golden set, which happens when you intentionally update a prompt, not on every commit.
Implementation Guide
Layer 1: Deterministic Structure Tests
These run on every commit, cost nothing, and catch the most common failures.
# tests/eval/test_ticket_classifier_structure.py
import json
import pytest
from pathlib import Path
GOLDEN_DIR = Path("tests/eval/golden/ticket_classifier")
@pytest.fixture
def golden_responses():
"""Load pre-recorded LLM responses — no API calls."""
return {
path.stem: json.loads(path.read_text())
for path in GOLDEN_DIR.glob("*.json")
}
def test_all_golden_responses_have_required_fields(golden_responses):
required = {"category", "priority", "summary", "confidence"}
for name, response in golden_responses.items():
missing = required - set(response.keys())
assert not missing, f"{name}: missing fields {missing}"
def test_category_is_valid_enum(golden_responses):
valid = {"billing", "technical", "account", "feature_request", "other"}
for name, response in golden_responses.items():
assert response["category"] in valid, \
f"{name}: invalid category '{response['category']}'"
def test_priority_is_integer_1_to_5(golden_responses):
for name, response in golden_responses.items():
p = response["priority"]
assert isinstance(p, int) and 1 <= p <= 5, \
f"{name}: priority '{p}' out of range"
def test_summary_under_200_chars(golden_responses):
for name, response in golden_responses.items():
s = response["summary"]
assert len(s) <= 200, \
f"{name}: summary too long ({len(s)} chars)"
def test_confidence_is_float_0_to_1(golden_responses):
for name, response in golden_responses.items():
c = response["confidence"]
assert isinstance(c, float) and 0.0 <= c <= 1.0, \
f"{name}: confidence '{c}' out of range"
These tests load JSON files from a tests/eval/golden/ directory and validate structure. No network. No cost. They run in milliseconds.
The golden files are generated once using a separate script:
# scripts/generate_golden_set.py
"""Run this when you intentionally update a prompt.
Never run automatically in CI — only on demand."""
import json
import os
from openai import OpenAI
from pathlib import Path
client = OpenAI()
GOLDEN_DIR = Path("tests/eval/golden/ticket_classifier")
GOLDEN_DIR.mkdir(parents=True, exist_ok=True)
TEST_CASES = [
{
"id": "billing_simple",
"input": "My invoice has wrong charges this month",
"expected_category": "billing",
},
{
"id": "technical_crash",
"input": "App crashes every time I open the settings screen on iOS 17",
"expected_category": "technical",
},
{
"id": "account_locked",
"input": "I can't log in, says account suspended but I didn't do anything",
"expected_category": "account",
},
{
"id": "feature_request_dark_mode",
"input": "Please add dark mode, the white background hurts my eyes at night",
"expected_category": "feature_request",
},
{
"id": "priority_urgent",
"input": "URGENT: All our users are getting 500 errors on checkout. Revenue stopped.",
"expected_category": "technical",
"expected_priority": 5,
},
]
def classify(ticket_text: str) -> dict:
resp = client.chat.completions.create(
model="gpt-4o-mini",
temperature=0.1, # low temperature for consistency
response_format={"type": "json_object"},
messages=[
{"role": "system", "content": SYSTEM_PROMPT},
{"role": "user", "content": ticket_text},
],
)
return json.loads(resp.choices[0].message.content)
for case in TEST_CASES:
result = classify(case["input"])
result["_test_input"] = case["input"]
result["_test_id"] = case["id"]
(GOLDEN_DIR / f"{case['id']}.json").write_text(
json.dumps(result, indent=2)
)
print(f"Generated: {case['id']} → category={result['category']}")
Run python scripts/generate_golden_set.py once per prompt version. Commit the golden files. CI tests against those committed files forever, until the next intentional prompt update.
Layer 2: Regression Tests Against Golden Outputs
Structure tests catch schema failures. Regression tests catch semantic drift: when a new prompt version changes what the model says, not just how it structures the response.
# tests/eval/test_ticket_classifier_regression.py
import json
import pytest
from pathlib import Path
GOLDEN_DIR = Path("tests/eval/golden/ticket_classifier")
BASELINE_DIR = Path("tests/eval/baseline/ticket_classifier") # prev. version
@pytest.mark.skipif(
not BASELINE_DIR.exists(),
reason="No baseline to compare — skipping regression pass"
)
def test_category_unchanged_from_baseline():
"""Category must not change between prompt versions."""
failures = []
for golden_path in GOLDEN_DIR.glob("*.json"):
baseline_path = BASELINE_DIR / golden_path.name
if not baseline_path.exists():
continue # new test case, no baseline
golden = json.loads(golden_path.read_text())
baseline = json.loads(baseline_path.read_text())
if golden["category"] != baseline["category"]:
failures.append(
f"{golden_path.stem}: "
f"'{baseline['category']}' → '{golden['category']}'"
)
assert not failures, "Category regressions:\n" + "\n".join(failures)
def test_priority_delta_under_1(golden_responses):
"""Priority may shift by at most 1 point between prompt versions."""
...
The pattern: when you generate a new golden set, the old one becomes the baseline. The regression suite compares them. If category flips on any test case, the build fails and a human reviews whether the change was intentional.
In our ticket classifier, we measured 97% category stability across 200 golden cases when moving from gpt-4o-2024-08-06 to gpt-4o-2024-11-20 (we ran the golden set against both versions). That 3% drift was 6 tickets that changed account to billing. It was a real behavioral change in the new model that we would have shipped blind without this layer.
Layer 3: LLM-as-Judge for Semantic Quality
Some things can't be checked with code: Is this summary accurate? Is this response helpful? Does this recommendation make sense?
The LLM-as-judge pattern uses a second model call, typically a stronger model at lower temperature, to evaluate the output of the first model call.
# tests/eval/judge.py
import json
from openai import OpenAI
client = OpenAI()
JUDGE_PROMPT = """You are an evaluation judge. You will receive:
1. A support ticket (the input)
2. A classification result (JSON)
Evaluate whether the classification is correct and helpful.
Return JSON with:
- "correct": true/false — is the category right?
- "priority_reasonable": true/false — is the priority appropriate?
- "summary_accurate": true/false — does summary match the ticket?
- "explanation": one sentence explaining your verdict
- "score": float 0.0-1.0 (1.0 = perfect)
Be strict. A score below 0.8 means something is wrong."""
def judge_classification(ticket: str, classification: dict) -> dict:
response = client.chat.completions.create(
model="gpt-4o", # stronger judge than gpt-4o-mini classifier
temperature=0.0, # deterministic judge
response_format={"type": "json_object"},
messages=[
{"role": "system", "content": JUDGE_PROMPT},
{"role": "user", "content": json.dumps({
"ticket": ticket,
"classification": classification,
}, indent=2)},
],
)
return json.loads(response.choices[0].message.content)
And the test that uses it:
# tests/eval/test_ticket_classifier_semantic.py
import json
import pytest
from pathlib import Path
from tests.eval.judge import judge_classification
GOLDEN_DIR = Path("tests/eval/golden/ticket_classifier")
MIN_JUDGE_SCORE = 0.80 # fail if avg score drops below this
@pytest.mark.llm_judge # mark so CI can optionally skip on cost
def test_semantic_quality_above_threshold():
scores = []
failures = []
for golden_path in GOLDEN_DIR.glob("*.json"):
golden = json.loads(golden_path.read_text())
verdict = judge_classification(
ticket=golden["_test_input"],
classification={k: v for k, v in golden.items() if not k.startswith("_")},
)
scores.append(verdict["score"])
if verdict["score"] < MIN_JUDGE_SCORE:
failures.append(f"{golden_path.stem}: score={verdict['score']:.2f} — {verdict['explanation']}")
avg = sum(scores) / len(scores)
assert avg >= MIN_JUDGE_SCORE, \
f"Avg judge score {avg:.2f} < threshold {MIN_JUDGE_SCORE}\n" + "\n".join(failures)
Run this as pytest -m llm_judge, marked separately so you can run it on PR merge but not on every commit. Cost is roughly $0.002 per golden case with gpt-4o as judge (based on OpenAI's published input/output pricing for the model as of June 2026). For 50 golden cases, that's $0.10 per PR merge, which is acceptable given what it catches.

Here's the decision flow for choosing the right eval layer for a given type of failure:
Wiring It Into CI
A sample GitHub Actions config that implements all three layers:
# .github/workflows/llm-evals.yml
name: LLM Evals
on:
push:
branches: [main]
pull_request:
paths:
- "prompts/**"
- "src/llm/**"
- "tests/eval/**"
- "tests/eval/golden/**"
jobs:
deterministic-evals:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- uses: actions/setup-python@v5
with:
python-version: "3.12"
- run: pip install pytest
- name: Run deterministic + regression evals (no API calls)
run: pytest tests/eval/ -m "not llm_judge" -v
semantic-evals:
runs-on: ubuntu-latest
if: github.event_name == 'push' && github.ref == 'refs/heads/main'
needs: deterministic-evals
steps:
- uses: actions/checkout@v4
- uses: actions/setup-python@v5
with:
python-version: "3.12"
- run: pip install pytest openai
- name: Run LLM-as-judge evals (only on merge to main)
run: pytest tests/eval/ -m "llm_judge" -v
env:
OPENAI_API_KEY: ${{ secrets.OPENAI_API_KEY }}
Deterministic tests run on every push and every PR. Semantic tests only run on merge to main. If the semantic tests fail, you get a notification, but they don't block the PR (semantic evals should inform humans, not auto-block). Deterministic tests block merges.
Production Considerations
What to do when a test fails
When a deterministic test fails (category returned an invalid value, JSON missing a required field), this is a real failure. Either the prompt broke or the model changed behavior. Don't ignore it.
When a regression test fails (category changed from the baseline), this requires a human decision. Is the new behavior correct? If yes, update the baseline and regenerate goldens. If no, revert the prompt change.
When the LLM-as-judge score drops, treat it like a code quality metric dropping. Investigate the low-scored cases first. Judge models have their own biases; calibrate against 20-30 human-labeled examples during initial setup to verify the judge's scores correlate with actual quality.
Golden set maintenance
Regenerate the golden set whenever you:
- Change the system prompt significantly
- Change the model or model version (pin to date-stamped aliases: gpt-4o-2024-11-20, claude-sonnet-4-6)
- Add new test cases to cover a bug you found in production
Never regenerate automatically in CI. The golden set is a snapshot of what we agreed is correct behavior. It should only change when a human decides to change it.
Keep the golden set small but representative. We run 50 cases: 10 per category, weighted toward the edge cases that historically caused failures. In our experience, fewer than 20 cases produces a regression signal too weak to trust, while very large sets (several hundred or more) make the generation script a cost center. Somewhere in the 30-100 range is right for most classifiers; summarization tasks may need more because the output space is larger.
Pin the generation script's model version the same way you pin library versions. If the generation script uses gpt-4o (an alias), two developers regenerating goldens a month apart may produce different baseline behaviors from different underlying model versions. Use gpt-4o-2024-11-20 in the script and update the pin deliberately.
Cost management
On a team shipping 10 prompt changes per week with 50 golden cases each, LLM-as-judge costs roughly $1/week (we measured $0.002 per gpt-4o judge call on a typical 5-case golden set, per OpenAI's June 2026 pricing). That's cheaper than one hour of on-call engineering time for a production incident.
The deterministic and regression layers cost zero in API calls. Invest there first. In our experience they catch 80% of regressions. Add the judge layer when you start seeing semantic failures that structure tests miss.
Evals vs monitoring
Evals in CI catch regressions before prod. Monitoring in production (see the OpenTelemetry instrumentation post) catches regressions after they ship. You need both. Evals find the prompt bugs. Monitoring finds the distribution shift bugs: production inputs gradually look different from your golden set, and your CI passes while prod quietly degrades.
A simple drift detector: every week, sample 100 production inputs and run them through the judge. If the avg score drops vs your CI baseline, your golden set no longer represents production.
The golden set lifecycle across a prompt update looks like this:
Debugging the Gotcha: Judge Bias
The first time I ran this setup on a summarization task, the judge scored everything 0.95+. Every response looked perfect. We were delighted. We shipped. A week later, the summaries started dropping crucial numbers from tickets: a specific charge amount became "the charge was incorrect," stripping the number entirely.
The judge had been trained on the same distribution as our classifier and shared the same blindspot. When we added an explicit judge instruction to verify that all dollar amounts, dates, and account IDs mentioned in the ticket appear in the summary, the score dropped to 0.71 on our existing golden set. We had to fix 14 test cases.
Lesson: LLM-as-judge is only as good as its prompt. The judge needs explicit criteria for every important property. Asking whether a summary is good is too vague. Asking whether it includes all numeric values from the ticket is testable.
Conclusion
The reason most teams don't run LLM evals in CI isn't that it's hard. They're using the wrong testing model. Exact-match comparisons of LLM prose outputs will always be flaky. Structure tests and golden-set regressions are deterministic. Put those in CI from day one.
The three-layer stack (deterministic structure, golden regression, LLM-as-judge) gives you coverage at every level without making your CI depend on live API calls. The fast layers block merges. The expensive layer informs humans.
Production LLM systems fail silently. Your tests should fail loudly.
Get the next one
One email a week: one production failure, debugged, with the companion code from each post. No spam, unsubscribe anytime.
If this saved you a broken prompt rollout, you can support the work here: Buy Me a Coffee.
Reader challenge: add an LLM-as-judge eval to your next prompt change. Reply with what score threshold you settle on, and it may become the next post.
Revision History
| Date | Summary | Old Version |
|---|---|---|
| 2026-06-17 | Added the standard reader-support link so the post passes the owned-audience funnel QA check. | Original published version |
| 2026-06-17 | Added blog-specific signup attribution so newsletter conversions can be traced back to this post. | Previous 2026-06-17 revision |
Sources
- DORA State of DevOps 2025 — LLM production incident detection metrics
- OpenAI Evals framework documentation — official eval patterns from OpenAI
- Anthropic Model Specification on evaluation methodology — Claude evaluation design principles
- OpenTelemetry GenAI Semantic Conventions — OTel 1.26 stable spec for LLM span attributes
- LLM-as-a-Judge: Is it a Good Evaluator? (2025, arXiv:2306.05685) — academic analysis of LLM judge reliability and calibration
About the Author
Toc Am
Founder of AmtocSoft. Writing practical deep-dives on AI engineering, cloud architecture, and developer tooling. Previously built backend systems at scale. Reviews every post published under this byline.
Published: 2026-06-16 · Updated: 2026-06-17 · Written with AI assistance, reviewed by Toc Am.
Get These In Your Inbox
Weekly deep-dives on AI engineering, no fluff. Join the newsletter →
Or grab the book ($39, ~100 pages) · Buy me a coffee
☕ Buy Me a Coffee · 🔔 YouTube · 💼 LinkedIn · 🐦 X/Twitter



No comments:
Post a Comment