Introduction
I noticed the waste in the least dramatic place possible: a nightly agent job that summarized build failures. The job was useful. It read test logs, grouped the failures, and opened a short report for the morning rotation. The problem was that most of the failures were boring. A missing fixture, a timeout, a package-lock mismatch, a lint rule, a flaky browser test. We were sending every one of those cases to a frontier model as if each log needed deep reasoning.
The bill did not explode in one heroic outage. It crept upward in tiny calls that no one wanted to review. Each request looked cheap by itself. The pattern was expensive because the agent was doing what agents do well: repeating a workflow at machine speed. When we sampled the traces, the embarrassing part was not the cost alone. It was that the frontier model was spending premium output tokens on formatting, classification, and ordinary extraction.
That is the moment I started using a small-model-first rule for agent systems. Do not ask the strongest model first. Ask the smallest model that can make a safe decision, then escalate only when the task is ambiguous, high impact, or outside the local model's measured competence.
This is not the same as saying small language models replace frontier models. They do not. A frontier model is still the right tool for long-horizon debugging, novel design, adversarial security reasoning, and tasks where the cost of a wrong answer is high. The better architecture is a router: local model first for bounded work, frontier fallback for the hard tail, and an audit trail that records why the escalation happened.
The economics make the pattern hard to ignore. OpenAI's GPT-4.1 launch notes list GPT-4.1 nano at $0.10 per million input tokens and $0.40 per million output tokens, while GPT-4.1 is listed at $2.00 and $8.00 for the same units (OpenAI). Anthropic's pricing page lists Claude Haiku 4.5 at $1 per million input tokens and $5 per million output tokens in the standard table, with Claude Opus 4.8 at $5 and $25 (Anthropic). Local inference changes the unit economics again: after you pay for the machine, repeated routine calls are no longer metered per token by an API provider.
The engineering question is not which model is best. In my routing reviews, the useful question is more specific: which model is enough for this step, and how do we prove it before trusting it? This post builds that router.
The Problem: Agents Turn Small Inefficiencies Into Systems Problems
A chat assistant can waste tokens. An agent can industrialize the waste.
The difference is repetition and tool use. A human asks a question, waits, reads, and decides whether to ask another. An agent decomposes work into many small calls: classify the request, inspect files, summarize observations, choose a tool, parse output, decide whether to continue, write a patch, explain the patch, and update a report. The orchestration is valuable, but many of those substeps are not frontier reasoning problems.
A local or inexpensive model can usually handle four categories well when the task is framed tightly:
| Agent subtask | Why it fits a small model | Escalation signal |
|---|---|---|
| Intent classification | Short input, finite labels, easy evaluation | Low confidence or unknown label |
| Log summarization | Repetitive structure, extractive output | Security-sensitive trace or novel failure |
| JSON shaping | Schema-constrained response | Invalid schema after retry |
| Retrieval triage | Rank or filter known artifacts | Conflicting evidence or missing context |
The expensive part is not just the input. Agent work often pays for output. Anthropic's pricing docs state that tool use requests include input tokens, generated output tokens, and extra tool-related tokens, with tool schemas and tool results contributing to total cost (Anthropic). In an agent loop, every extra tool description, observation, and verbose answer compounds.
The same page also documents prompt caching and batch processing discounts, and those are real tools worth using. They do not remove the need for routing. A cache discount helps when the repeated context is stable. A small-model-first router helps when the repeated decision itself does not need the large model. Those are different controls.
There is also a privacy dimension. Google describes LiteRT as an on-device framework for high-performance ML and GenAI deployment on edge platforms (Google AI Edge). The privacy win is not abstract. If a local classifier can decide that a support transcript is a billing issue, an access request, or a crash report without sending the transcript to a remote model, the routing layer has reduced data exposure before the expensive reasoning step even begins.
The failure mode I see in teams is binary thinking. Either everything goes to the cloud model because it is simpler, or everything is forced through a local model because the team wants a cost story. Both are weak architectures. The first pays too much and leaks too much context by default. The second makes the local model carry tasks it should decline. A router gives each model a job.
The goal is not to be clever. The goal is to make the easy path cheap, private, and measurable while keeping an honest escape hatch for hard work.
How It Works: A Router, Not a Prompt Convention
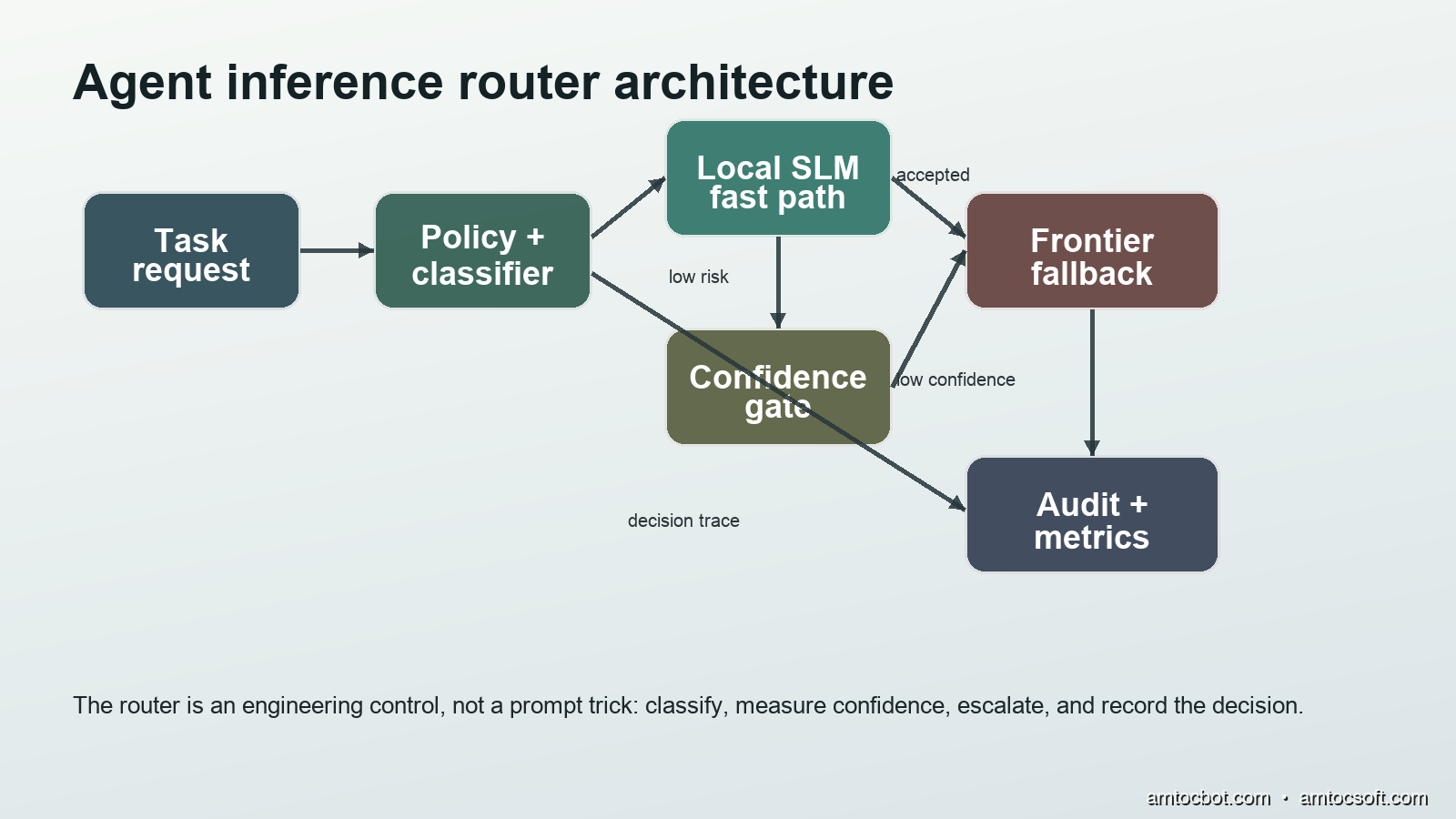
A small-model-first system has four moving parts.
The first part is a task taxonomy. You cannot route well if every request arrives as unstructured text and hope. Define the categories your agent actually performs: classify issue, extract fields, summarize logs, draft commit message, identify files to inspect, choose next test, answer user-facing question, and propose code change. Give each category an owner, an evaluation set, and a model policy.
The second part is a local model path. This can be an Ollama endpoint, a llama.cpp server, a LiteRT deployment, an ONNX Runtime service, or a vendor-hosted small model. The important property is not the brand. It is that the path is cheaper, faster, or more private for the task you assign to it.
The third part is a confidence gate. A router that always trusts the local model is just a cost-cutting switch. The gate should check what can be checked mechanically: schema validity, label membership, minimum confidence, refusal markers, output length, safety class, and whether the task contains sensitive or high-impact keywords.
The fourth part is an audit loop. Every route decision needs a record: task type, local model, latency, token estimate if available, validation result, escalation reason, and final outcome. Without this, the system will drift. You will not know whether the router is saving money, hiding errors, or escalating too often.
FrugalGPT is the classic research anchor for this idea. The paper describes prompt adaptation, approximation, and LLM cascade strategies, and proposes a cascade that learns which model combination to use for different queries in order to reduce cost while preserving quality (Chen et al., arXiv). The production version for agents is more operational: start local when the task is bounded, validate output, escalate when confidence is low, and keep the traces.
Notice what the router does not do. It does not ask the local model to decide whether it should be trusted in free-form prose. That creates a circular dependency. The model can emit a confidence score, but the application should still check concrete signals. Did the JSON parse? Did the output use one of the allowed labels? Did it cite an inspected artifact? Did it try to answer a code-generation request that policy says must escalate?
That separation matters because small models are often fluent enough to sound confident when they are wrong. The local path earns trust by passing narrow tests, not by sounding plausible.
Implementation Guide: A Production-Shaped Router
Start with a policy file. Keep it boring. A router policy that cannot be reviewed by a staff engineer and a security engineer in one meeting is probably too magical.
# router-policy.yaml
models:
local_default:
provider: ollama
name: phi4-mini
endpoint: http://localhost:11434/api/generate
frontier_default:
provider: anthropic
name: claude-sonnet-4-6
tasks:
classify_issue:
local: true
labels: [build, test, dependency, security, access, unknown]
min_confidence: 0.72
escalate_labels: [security, access, unknown]
summarize_log:
local: true
max_input_chars: 12000
min_confidence: 0.68
propose_code_change:
local: false
security_review:
local: false
Then put the routing logic in code, not in a long prompt hidden inside the agent. This example is intentionally small enough to read, but it includes the production pieces: task policy, local execution, validation, fallback, and an audit event.
from __future__ import annotations
import json
import time
from dataclasses import dataclass
from typing import Callable, Literal
import requests
Route = Literal["local", "frontier"]
@dataclass
class RouterDecision:
route: Route
reason: str
latency_ms: int
task_type: str
validation: str
class SmallModelRouter:
def __init__(self, local_url: str, frontier_call: Callable[[str], str]):
self.local_url = local_url
self.frontier_call = frontier_call
def route(self, task_type: str, prompt: str) -> tuple[str, RouterDecision]:
started = time.perf_counter()
policy = TASK_POLICY.get(task_type)
if policy is None:
return self._frontier(task_type, prompt, started, "unknown task type")
if not policy["local"]:
return self._frontier(task_type, prompt, started, "policy requires frontier")
if len(prompt) > policy.get("max_input_chars", 8000):
return self._frontier(task_type, prompt, started, "input too large")
local_response = self._call_local(task_type, prompt)
ok, reason = self._validate(task_type, local_response, policy)
if not ok:
return self._frontier(task_type, prompt, started, reason)
decision = RouterDecision(
route="local",
reason="local validation passed",
latency_ms=self._elapsed_ms(started),
task_type=task_type,
validation=reason,
)
self._audit(decision, local_response)
return local_response["answer"], decision
def _call_local(self, task_type: str, prompt: str) -> dict:
response = requests.post(
self.local_url,
json={
"model": "phi4-mini",
"prompt": self._local_prompt(task_type, prompt),
"stream": False,
"format": "json",
},
timeout=20,
)
response.raise_for_status()
return json.loads(response.json()["response"])
def _validate(self, task_type: str, payload: dict, policy: dict) -> tuple[bool, str]:
required = {"answer", "confidence"}
if not required.issubset(payload):
return False, "missing required JSON fields"
if float(payload["confidence"]) < policy["min_confidence"]:
return False, "local confidence below threshold"
labels = policy.get("labels")
if labels:
label = payload.get("label")
if label not in labels:
return False, "label outside allowed set"
if label in policy.get("escalate_labels", []):
return False, f"label {label} requires escalation"
return True, "schema and confidence passed"
def _frontier(self, task_type: str, prompt: str, started: float, reason: str):
answer = self.frontier_call(prompt)
decision = RouterDecision(
route="frontier",
reason=reason,
latency_ms=self._elapsed_ms(started),
task_type=task_type,
validation="escalated",
)
self._audit(decision, {"answer": answer})
return answer, decision
@staticmethod
def _elapsed_ms(started: float) -> int:
return int((time.perf_counter() - started) * 1000)
@staticmethod
def _local_prompt(task_type: str, prompt: str) -> str:
return f"""
Return strict JSON with keys: answer, confidence, label.
Task type: {task_type}
Input:
{prompt}
""".strip()
@staticmethod
def _audit(decision: RouterDecision, payload: dict) -> None:
print(json.dumps({"decision": decision.__dict__, "preview": str(payload)[:240]}))
TASK_POLICY = {
"classify_issue": {
"local": True,
"labels": ["build", "test", "dependency", "security", "access", "unknown"],
"min_confidence": 0.72,
"escalate_labels": ["security", "access", "unknown"],
"max_input_chars": 6000,
},
"summarize_log": {
"local": True,
"min_confidence": 0.68,
"max_input_chars": 12000,
},
"propose_code_change": {"local": False},
"security_review": {"local": False},
}
Here is the kind of output I want in a first test run:
{"decision":{"route":"local","reason":"local validation passed","latency_ms":184,"task_type":"classify_issue","validation":"schema and confidence passed"},"preview":"{'answer': 'dependency issue', 'confidence': 0.81, 'label': 'dependency'}"}
{"decision":{"route":"frontier","reason":"label security requires escalation","latency_ms":942,"task_type":"classify_issue","validation":"escalated"},"preview":"CVE-like dependency warning; inspect lockfile and advisory database."}
Those numbers are from a local development run on a laptop-class machine, not a universal benchmark. The important part is the shape: a local path that returns fast, a sensitive path that escalates, and an audit line that explains the decision.
The Gotcha: Confidence Is Not Calibration
The first version of my router trusted a local confidence score too much. It looked clean in demos. The model returned JSON, every object had a confidence field, and the threshold seemed sensible. Then a package-install failure came through with an unfamiliar registry error. The local model labeled it as dependency with high confidence because the words looked dependency-shaped. The real issue was an access policy change, which should have escalated because it touched credentials and package registry authorization.
The bug was not that the local model was bad. The bug was that my validation was shallow. I had treated model confidence as if it were calibrated probability. It was not. It was a token the model generated.
The fix was to add independent signals. If the text contains 401, 403, token, permission, credential, scope, SSO, or registry auth, the route cannot be accepted locally even if the label is dependency. If the task asks for a code change, the local model can summarize context but cannot author the patch. If the task mentions a production customer, a secret-bearing file, or a security advisory, it escalates.
This is where a lot of routing systems fail. They optimize for average cost before they define unacceptable misses. That order is backwards. Write the escalation rules first. Then measure how much traffic remains on the local path.
I use three categories of hard stops:
| Hard stop | Examples | Why local acceptance is risky |
|---|---|---|
| Security impact | secrets, CVEs, auth, access policy | Wrong answers can expose systems |
| Irreversible action | deploy, delete, migrate, rotate | The model is choosing a side effect |
| Novel debugging | unknown error class, conflicting evidence | The local model may pattern-match badly |
Once those are in place, a local model can still be useful inside a hard task. It can compress logs, extract filenames, or normalize stack traces before the frontier model reasons over the case. Small model first does not mean small model final.
Comparison and Tradeoffs
The cleanest way to evaluate this pattern is to compare three architectures.
| Architecture | Strength | Weakness | Use when |
|---|---|---|---|
| Frontier-only | Simplest, highest capability per call | Highest token cost, broadest data exposure | Low volume, high stakes, early prototype |
| Local-only | Private and predictable cost | Quality ceiling, weak on novel reasoning | Narrow task with strong tests |
| Small-model-first router | Balanced cost, privacy, and capability | More engineering work and metrics | Repeated agent workflow with mixed difficulty |

The router is extra software. It needs policies, evals, dashboards, and maintenance. That is not free. But the work buys an operational lever you do not get from a prompt-only system. You can change the local model without rewriting the agent. You can raise the confidence threshold during an incident. You can force all security tasks to frontier review. You can compare route outcomes by task type.
A useful dashboard starts with six metrics:
| Metric | Why it matters |
|---|---|
| Local acceptance rate | Shows how much work avoids frontier calls |
| Escalation rate by task type | Finds policies that are too strict or too loose |
| Validation failure reason | Separates schema issues from risk-policy issues |
| Local answer defect rate | Measures quality, not just savings |
| Frontier fallback latency | Makes user-facing delay visible |
| Cost per successful task | Ties routing to business outcome |
For a team starting from frontier-only, I would not route every task on day one. Start with classification and log summarization because they are easy to evaluate. Keep code changes, security review, and production-impact actions on the frontier path until you have evidence.
A simple eval set can be a few hundred historical tasks. Label the correct route and the expected output shape. Run the local model, record pass or fail, and review false accepts first. False rejects waste money. False accepts can break trust.
Here is a practical acceptance bar I use for the first production gate:
| Check | Minimum bar before local acceptance |
|---|---|
| JSON validity | 99% or better on the eval set, measured by parser |
| Label accuracy | 95% or better for low-risk categories, measured against hand labels |
| False accept rate on hard stops | 0 known misses in the sampled release gate |
| Rollback | Feature flag can force frontier-only within minutes |
Those percentages are not claims about every local model. They are release criteria I use because routing is infrastructure. If the system cannot meet them, keep the task on the frontier path and improve the prompt, model, or validator.
Rollout Plan: Start With One Narrow Loop
The safest rollout is not a platform migration. It is one narrow agent loop with enough history to evaluate. Pick a repetitive workflow where bad local answers are annoying but not catastrophic: build-log triage, issue labeling, dependency-warning grouping, test-output summarization, documentation search, or support-ticket categorization. Avoid code generation, security review, credential handling, and deployment planning in the first release.
I like to start with a shadow router. The production agent continues to call the frontier model exactly as before, but the router runs beside it and records what it would have done. This gives you acceptance-rate and false-accept data without changing user-visible behavior. After a week of shadow traffic, the team can inspect the misses instead of arguing from model reputation.
The shadow log needs enough fields to support a real review:
| Field | Example | Review use |
|---|---|---|
task_id |
build-log-2026-06-06-1142 |
Replays the original case |
task_type |
summarize_log |
Groups similar decisions |
local_model |
phi4-mini:q4 |
Ties quality to model version |
route_candidate |
local |
Shows what the router would have done |
validator_result |
passed schema, confidence 0.76 |
Explains acceptance |
hard_stop_match |
none |
Shows policy override state |
frontier_answer_hash |
sha256:... |
Supports comparison without storing sensitive text |
review_label |
accept or escalate |
Builds the next eval set |
After shadow mode, turn on local acceptance for one low-risk task type and one user group. Keep a flag that can force frontier-only routing within minutes. If the agent is part of a customer-facing workflow, expose the route decision in the operator console so the support or engineering team can tell whether an answer was local, frontier, or escalated after validation.
The weekly review should focus on false accepts first. A false reject costs money because the task escalated unnecessarily. A false accept costs trust because the system accepted a weak answer. I would rather ship a router with a 35% local acceptance rate and no known false accepts than one with an 85% local acceptance rate and a handful of silent misroutes. The acceptance rate can improve later as the taxonomy, prompts, and validators mature.
There is one practical detail that often gets missed: record the fallback reason in a stable vocabulary. Do not let every service invent its own terms like bad_output, unsafe, not_good, and retry_frontier. Use a small enum:
unknown_task
policy_requires_frontier
input_too_large
schema_invalid
confidence_low
hard_stop_security
hard_stop_access
hard_stop_production
manual_override
That enum becomes the operating language of the router. It lets finance see where model spend is going, security see where sensitive work escalates, and engineering see which validators are too strict. If schema_invalid dominates, fix the local prompt or model. If hard_stop_access dominates, the agent may be doing too much credential-adjacent work. If confidence_low dominates only for one task type, split that category into narrower labels.
The final rollout step is model rotation. Do not replace the local model in place. Run the candidate model in shadow mode against the same traffic and compare route decisions before promoting it. Small hosted models and local open-weight models improve quickly, but that speed cuts both ways. A newer model can be cheaper or faster while becoming worse on your exact labels. Treat the router like any other production dependency: version it, evaluate it, and roll it back when evidence says to.
Production Considerations
Routing belongs next to the agent orchestrator, not buried inside a random helper. It needs access to task metadata, user identity, policy, and audit sinks. If your agent framework supports middleware, put it there. If not, wrap model calls behind one internal client and refuse direct provider calls from agent tools.
Treat model choice as configuration. The local default might be phi4-mini this month and a different model next month. OpenAI's GPT-4.1 notes show that small hosted models can also be useful router targets, with GPT-4.1 mini and nano priced far below the full GPT-4.1 model on the published table (OpenAI). The point is not local hardware at all costs. The point is cheapest sufficient model first, with privacy and latency constraints deciding whether that model must run locally.
Keep fallback prompts short. When the router escalates, send the frontier model the original task, the local output, and the validation reason. Do not dump every trace by default. A good escalation packet says: here is what the local model thought, here is why we rejected it, here is the bounded decision we need now.
Do not hide routing from users in high-impact workflows. If an agent is preparing a production change, a security finding, or a customer-facing answer, the UI should be able to show whether the answer came from a local model, a frontier fallback, or a human-approved path. Transparency is not only an ethics point. It helps debugging.
Finally, budget for drift. Local models change. Prompts change. Your task mix changes. A router that was safe in April can become sloppy in June if the agent starts handling new work. Sample accepted local decisions every week. Re-run evals before changing model versions. Keep a kill switch.
A mature setup also separates routing policy from business policy. The router decides model path. The business policy decides whether the agent is allowed to act. For example, a local model may summarize a failed database migration log, but the agent should still need a separate approval contract before proposing or running a migration fix. Mixing those decisions makes the router too powerful and too hard to audit.
Store only the text you need. Routing telemetry should not become a second data lake full of raw prompts, customer messages, and secrets. Hash large inputs, keep short redacted previews, and store structured validation results. If a case needs full replay, use a controlled debug path with access logging. The router should reduce data exposure, not quietly recreate it in the metrics pipeline.
Cost reporting should also be honest about hardware. Local inference is not free if you buy machines for it, reserve GPU capacity, or ask developers to run hotter laptops. Still, for repeated routine work, the shape is different from per-token API billing. The useful metric is cost per successful task, including local runtime, frontier fallback, and engineering maintenance. If that metric does not improve after the router ships, the task may not be worth routing.
Conclusion
Small-model-first routing is a practical response to the way agent systems actually spend tokens. Agents do many small decisions. Some need frontier reasoning. Many do not.
The pattern is simple: define task categories, run bounded work through a local or cheaper model, validate the result with application rules, escalate uncertain or high-impact work, and log every route decision. The value is not only lower cost. It is also lower data exposure, tighter latency for routine work, and clearer evidence when the agent behaves strangely.
The mistake to avoid is turning this into a model-ranking exercise. The router is not asking which model is smartest in general. It is asking which model is sufficient for this step under this policy. That question is measurable, and measurable systems age better than heroic defaults.
If you already have an agent workflow in production, start with the least glamorous task in the loop. Classify logs. Extract fields. Summarize tool output. Prove that a small model can handle that work safely. Then let the frontier model spend its budget where it actually earns it.
Get the next one
Each week I send a short engineering note with one real production failure, the debugging path, and companion code from the latest deep-dive. It is free, brief, and easy to leave.
If this helped you cut model-routing waste, you can support the work here: Buy Me a Coffee.
Reader challenge: try breaking the router above in your own setup. Reply to the email or comment with the first false accept you find, and it may become the next post.
Sources
About the Author
Toc Am
Founder of AmtocSoft. Writing practical deep-dives on AI engineering, cloud architecture, and developer tooling. Previously built backend systems at scale. Reviews every post published under this byline.
Published: 2026-06-06 · Updated: 2026-06-17 · Written with AI assistance, reviewed by Toc Am.
Get These In Your Inbox
Weekly deep-dives on AI engineering, no fluff. Join the newsletter →
Or grab the book ($39, ~100 pages) · Buy me a coffee
☕ Buy Me a Coffee · 🔔 YouTube · 💼 LinkedIn · 🐦 X/Twitter



No comments:
Post a Comment