
Introduction
The first MCP failure that changed my mind about agent security was not dramatic. Nothing crashed. No alert fired. An internal assistant had a read-only database tool, and the tool was on the approved list. During a support investigation, the agent called it with a query broad enough to pull customer records from regions outside the ticket's scope. The server did exactly what its schema allowed. The model did exactly what its prompt requested. The policy failure lived in the quiet gap between those two facts.
I had reviewed the server package, checked the tool names, and verified that the connection used authentication. I had not asked the harder runtime question: should this agent, acting for this user, be allowed to invoke this tool with these arguments at this moment?
That question matters more after Trend Micro's May 2026 research sweep of 19,000 open-source MCP repositories. Trend Micro sampled 2,287 agent-flagged candidates, manually confirmed 93 exploitable cases, and estimated a point prevalence near 4.1 percent across the corpus (Trend Micro). A separate Trend Micro analysis of more than 19,000 MCP server source trees reported that 48 percent recommended secrets in .env files or plaintext JSON configuration (Trend Micro).
Those numbers do not mean every MCP server is unsafe. They mean installation-time trust is not enough. A signed package can still expose an over-broad tool. An authenticated server can still accept dangerous arguments. A clean schema can still return poisoned context. Runtime governance is the missing layer between an agent's intent and a tool server's execution.
This guide builds that layer. The implementation is deliberately small: an allowlist, argument policy, scoped identity, response inspection, circuit breaker, approval boundary, and append-only audit trail. The point is not to invent a new protocol. The point is to put a deterministic control plane around the protocol you already use.
The Problem: MCP Standardizes Execution, Not Your Risk Appetite
MCP solves a valuable interoperability problem. A client discovers tools from a server, the model chooses a tool, the client serializes a request, and the server executes it. That common path is why MCP adoption moved quickly across coding agents, databases, file systems, and third-party services.
The protocol does not decide whether your production policy allows a particular action. Microsoft's April 2026 runtime-governance write-up states the gap plainly: MCP standardizes the execution surface without defining a built-in policy checkpoint before execution (Microsoft for Developers). The same article reports an internal red-team evaluation where prompt-only safety instructions produced a 26.67 percent policy-violation rate across its benchmark. Instructions help, but they are not an authorization system.
The OWASP MCP Top 10 makes the failure modes concrete (OWASP):
| Risk | Production symptom | Runtime control |
|---|---|---|
| Token exposure | A tool receives or logs credentials it never needed | Inject scoped credentials at execution time; redact logs |
| Scope creep | A convenience tool gradually acquires administrative verbs | Bind identity, tool, action, and resource scope |
| Tool poisoning | A description or response carries adversarial instructions | Scan definitions and inspect responses before model reuse |
| Command injection | Untrusted text lands in shell, SQL, or API arguments | Parse structured arguments; deny unsafe shapes |
| Missing telemetry | Nobody can reconstruct why a sensitive call ran | Emit immutable, correlated decision records |
| Shadow servers | A developer adds an unreviewed endpoint | Registry allowlist plus server identity verification |
Supply-chain controls still matter. Verify manifests, pin versions, review dependencies, and scan packages. Blog 249 covered that boundary. Runtime governance solves the next problem: what happens after a trusted server is connected and a real agent starts calling it.
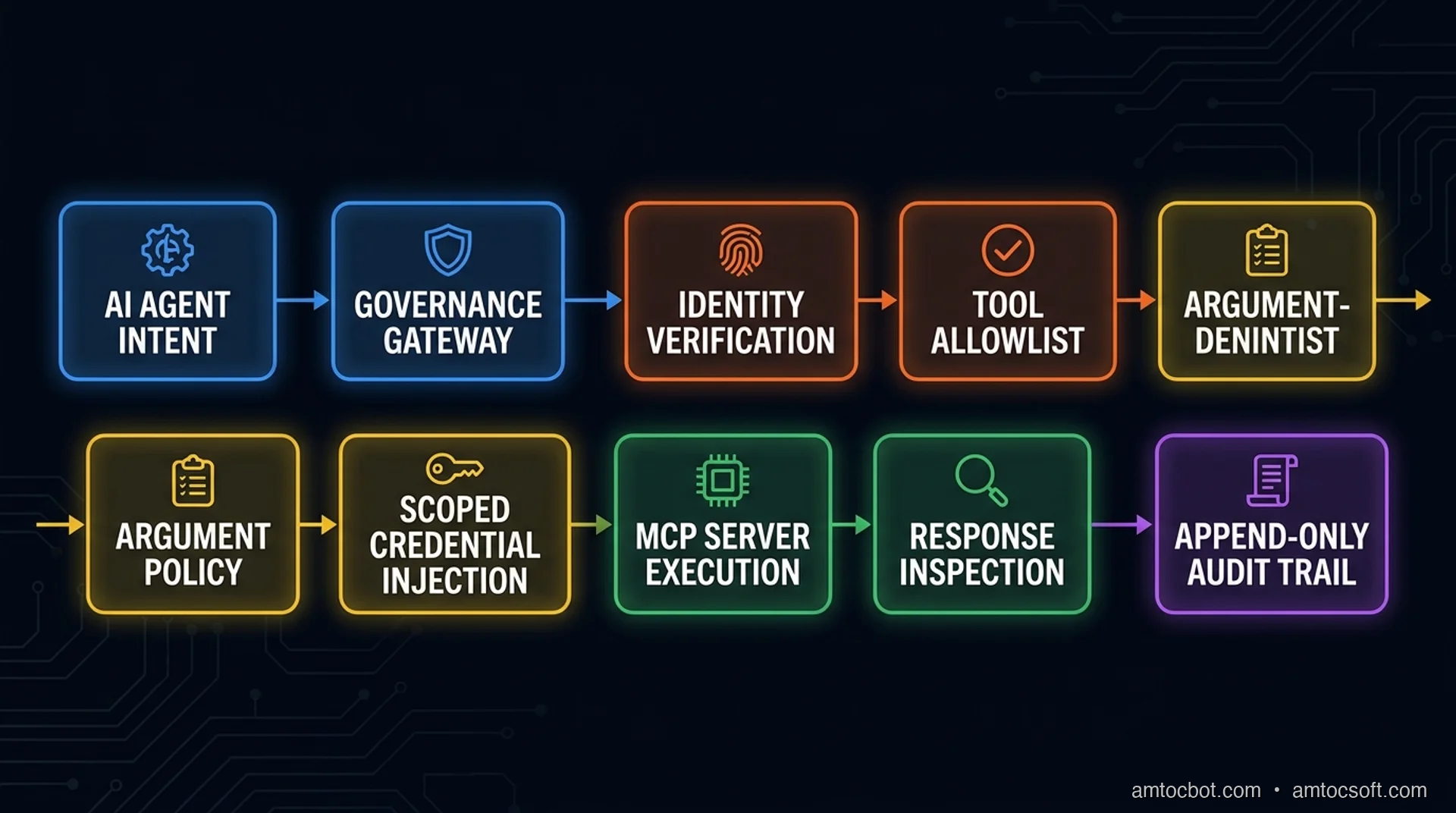
Architecture: Put Policy Between Intent and Execution
The gateway belongs in the client-side execution path or immediately in front of the MCP servers. It should run after the model proposes a call and before any privileged side effect occurs. That placement is load-bearing: the gateway sees the concrete tool name, concrete arguments, acting identity, target server, and request context.
There are three common approaches:
| Approach | What it gets right | Where it fails |
|---|---|---|
| Trust the connected server | Low friction for demos | No deterministic per-call decision |
| Sandbox every server | Reduces host blast radius | Does not stop valid-but-dangerous API calls |
| Runtime policy gateway plus sandboxing | Evaluates intent, identity, arguments, and outcome | Requires explicit policy ownership |
The third approach is the production default. Sandboxing contains server-side compromise. Runtime policy prevents an agent from using an otherwise healthy server in a way your organization did not authorize.
OpenAI describes a parallel operational pattern for Codex: bounded sandbox execution, approvals for higher-risk actions, managed network policies, keyring-backed credentials, and OpenTelemetry logs for prompts, tool decisions, tool results, MCP usage, and network allow-or-deny events (OpenAI). The exact implementation differs by platform, but the control-plane shape is the same.
Implementation: A Small Deterministic Gateway
The gateway below is intentionally ordinary Python. The policy data is explicit. The decision result is structured. Every request receives a correlation ID. A sensitive tool can require approval even if it appears on the allowlist.
from __future__ import annotations
from dataclasses import asdict, dataclass
from hashlib import sha256
from json import dumps
from time import time
from typing import Any
from uuid import uuid4
@dataclass(frozen=True)
class ToolCall:
server: str
tool: str
args: dict[str, Any]
actor: str
approved: bool = False
@dataclass(frozen=True)
class Decision:
allowed: bool
reason: str
request_id: str
POLICY = {
"inventory-mcp": {
"inventory.lookup": {"effect": "read"},
"inventory.adjust": {"effect": "write", "approval": True},
},
"support-mcp": {
"ticket.get": {"effect": "read"},
},
}
def stable_hash(value: Any) -> str:
return sha256(dumps(value, sort_keys=True).encode()).hexdigest()[:16]
def validate_args(call: ToolCall) -> str | None:
if call.tool == "inventory.lookup":
region = call.args.get("region")
if region not in {"us-east", "us-west"}:
return "region must be explicitly scoped"
if int(call.args.get("limit", 0)) > 100:
return "limit exceeds read policy"
if call.tool == "inventory.adjust":
delta = int(call.args.get("delta", 0))
if abs(delta) > 10:
return "inventory delta exceeds approval envelope"
return None
def decide(call: ToolCall) -> Decision:
request_id = str(uuid4())
server = POLICY.get(call.server)
if not server:
return Decision(False, "server is not registered", request_id)
rule = server.get(call.tool)
if not rule:
return Decision(False, "tool is not allowed", request_id)
if rule.get("approval") and not call.approved:
return Decision(False, "human approval required", request_id)
if reason := validate_args(call):
return Decision(False, reason, request_id)
return Decision(True, "policy passed", request_id)
def audit(call: ToolCall, decision: Decision) -> None:
record = {
"ts": round(time(), 3),
"request_id": decision.request_id,
"actor": call.actor,
"server": call.server,
"tool": call.tool,
"args_hash": stable_hash(call.args),
"allowed": decision.allowed,
"reason": decision.reason,
}
print(dumps(record, sort_keys=True))
def govern(call: ToolCall) -> Decision:
decision = decide(call)
audit(call, decision)
return decision
Run three calls through the policy:
calls = [
ToolCall("inventory-mcp", "inventory.lookup",
{"region": "us-east", "limit": 25}, "agent:triage"),
ToolCall("inventory-mcp", "inventory.lookup",
{"region": "*", "limit": 10000}, "agent:triage"),
ToolCall("inventory-mcp", "inventory.adjust",
{"sku": "A-17", "delta": -2}, "agent:triage"),
]
for call in calls:
result = govern(call)
print(result.allowed, result.reason)
The output is predictable:
{"actor":"agent:triage","allowed":true,"reason":"policy passed","server":"inventory-mcp","tool":"inventory.lookup",...}
True policy passed
{"actor":"agent:triage","allowed":false,"reason":"region must be explicitly scoped","server":"inventory-mcp","tool":"inventory.lookup",...}
False region must be explicitly scoped
{"actor":"agent:triage","allowed":false,"reason":"human approval required","server":"inventory-mcp","tool":"inventory.adjust",...}
False human approval required
The gateway does not ask the model whether the call is safe. It asks deterministic code. This matters because a model can explain a dangerous call convincingly. Policy code should remain boring enough that an on-call engineer can understand it under pressure.
The Gotcha: An Allowlisted Tool Can Still Be Dangerous
The incident from the introduction survived our first fix. We created an allowlist, registered the server, and permitted only customer.search. The next test still pulled too much data.
The tool was read-only, but its arguments were broad:
{
"tool": "customer.search",
"arguments": {
"region": "*",
"fields": ["name", "email", "billing_address", "support_notes"],
"limit": 50000
}
}
That request did not violate a tool-name allowlist. It violated the policy we had failed to encode: support agents should see one ticket's customer record, a narrow field projection, and a bounded row count. We had authorized the verb while ignoring the object.
The repair was to validate argument semantics:
def validate_customer_search(args: dict) -> str | None:
if args.get("region") == "*":
return "wildcard region is forbidden"
if int(args.get("limit", 0)) > 25:
return "row limit exceeds support policy"
forbidden = {"billing_address", "payment_token", "internal_notes"}
requested = set(args.get("fields", []))
if requested & forbidden:
return "field projection includes restricted data"
return None
After the change, our local policy test produced:
$ python -m pytest tests/test_gateway.py -q
8 passed in 0.06s
$ python demo.py
DENY customer.search: wildcard region is forbidden
DENY customer.search: row limit exceeds support policy
ALLOW customer.search: region=us-east limit=1 fields=[name,support_notes]
The broader lesson is useful beyond MCP. Authorization is not only a mapping from identity to endpoint. Production authorization is a mapping from identity to action, resource, argument envelope, time, and approval state.
Identity and Credentials: Scope Them at the Boundary
The MCP authorization specification defines authorization for HTTP transports using OAuth 2.1 patterns (MCP specification). The MCP tutorial explains that authorization protects sensitive resources and operations exposed by MCP servers and uses standard discovery metadata for OAuth flows (MCP documentation).
Use that transport authentication, then add workload policy at the gateway:
- Bind the human user and agent identity to each request.
- Mint or retrieve the shortest-lived credential the tool needs.
- Limit audience, scopes, resources, and network origin.
- Never put raw credentials into model context.
- Redact tokens from logs while preserving a credential fingerprint for correlation.
OpenAI's Codex deployment guidance is a useful concrete example: CLI and MCP OAuth credentials are stored in the secure OS keyring, and MCP server usage can be exported as OpenTelemetry events (OpenAI). OWASP's MCP01 guidance similarly recommends short-lived, scoped credentials and secret-scanning controls (OWASP).
Response Inspection: Treat Tool Output as Untrusted Input
The request path is half the boundary. Tool output flows back into model context, where text can influence the agent's next action. OWASP describes MCP tool poisoning as an indirect prompt-injection attack where a malicious tool response lands in the context window and is treated as trusted input (OWASP).
Response inspection should be conservative:
- Reject unexpected schema shapes.
- Redact secrets before any result enters model context.
- Flag instruction-like text returned from tools that should return data.
- Cap payload size.
- Preserve a hash of the original response for forensic review.
- Separate data from instructions in the host application.
Do not promise that a regex solves prompt injection. It does not. A response scanner is a tripwire and a sanitization layer, not a proof of safety. The stronger pattern is architectural: return typed data to a host that controls how the model sees it, and require policy checks again before the next action.
Circuit Breakers and Sequence Controls
Per-call policy is necessary, but a sequence of individually valid calls can still become harmful. An agent can enumerate resources one page at a time, retry a failing write until a downstream service collapses, or combine low-risk reads into an unexpected data export.
Start with two controls:
from collections import Counter
failures: Counter[str] = Counter()
def repeated_failure(tool: str, args: dict, error: str) -> bool:
key = stable_hash({"tool": tool, "args": args, "error": error})
failures[key] += 1
return failures[key] >= 3
def breadth_exceeded(history: list[str]) -> bool:
sensitive = {name for name in history if name.startswith("admin.")}
return len(sensitive) > 4
The first stops identical retry spirals. The second catches breadth: too many distinct sensitive actions in a short window. Blog 260 covered the general circuit-breaker pattern. MCP governance gives it a specific enforcement point.
Microsoft's AGT article is candid about this boundary: the preview governs individual tool calls, while workflow-level policy for sequences is still a roadmap item (Microsoft for Developers). Treat that limitation as a design requirement in your own gateway.
Comparison and Rollout Plan
| Control | Installation time | Connection time | Every call | Every response |
|---|---|---|---|---|
| Dependency scan | Yes | No | No | No |
| Manifest signature | Yes | Yes | Optional pin check | No |
| Server identity | No | Yes | Yes | No |
| Tool allowlist | No | Yes | Yes | No |
| Argument policy | No | No | Yes | No |
| Scoped credential injection | No | No | Yes | No |
| Response inspection | No | No | No | Yes |
| Immutable audit record | No | Yes | Yes | Yes |
Roll out in four passes:
- Observe. Log server, tool, actor, argument hash, result hash, latency, and outcome. Redact secrets before storage.
- Deny unknown servers. Require registry membership and identity verification.
- Enforce argument envelopes. Start with destructive tools, broad reads, shell execution, cloud administration, and credential access.
- Add approval and sequence policy. Require review for writes and alert on repeated failures or suspicious action breadth.
The observe-first pass matters. A policy written without real traffic usually blocks harmless workflows and misses dangerous argument shapes. Collect enough structured traces to understand the normal envelope, then enforce it deliberately.
Production Considerations
Keep the gateway small and observable. A control plane that nobody can debug will become a bypass target the first time it slows a release.
Measure:
- Allow, deny, and approval rates by tool.
- Policy-evaluation latency.
- Repeated-failure trips.
- Response redactions.
- Shadow-server attempts.
- Scope-expansion requests.
- Audit-log delivery health.
Microsoft reports sub-millisecond policy-evaluation overhead for typical AGT rule sets in its internal microbenchmarks (Microsoft for Developers). Your numbers will depend on policy engine, network topology, and logging path, so benchmark your own gateway and alert on regressions.
Fail closed for destructive actions. For low-risk reads, choose consciously whether a telemetry outage should fail open, fail closed, or queue work. Keep emergency kill switches outside the agent's own tool surface. Store audit records in an append-only destination and include schema versions so you can reconstruct which contract governed a historical invocation.
Policy Ownership: Make the Boundary Operable
A gateway is easy to demo and surprisingly easy to neglect. The hard production question is who owns each rule after the first month. If every policy change requires a security architect, teams route around the gateway. If every application team can loosen policy silently, the gateway becomes decorative.
I use a split ownership model:
| Policy layer | Primary owner | Review requirement |
|---|---|---|
| Server registry and identity | Platform security | Security review for additions |
| Tool discovery allowlist | Platform team | Application-owner approval |
| Argument envelope | Application owner | Code review plus policy tests |
| Credential scope | Identity team | Security review for expansion |
| Human-approval triggers | Risk owner | Product and security sign-off |
| Response inspection | Platform security | Threat-model review |
| Audit retention | Compliance or SRE | Retention-policy approval |
This division matters because the application owner understands semantic risk. A platform team can recognize that inventory.adjust writes state. It may not know that a delta above ten units requires a separate warehouse workflow, or that reading support notes across regions creates a data-residency problem. The platform provides the enforcement mechanism. The application owner defines the safe envelope.
Policy changes should travel through the same path as code. Require review, preserve diffs, run contract tests, and attach a reason. An emergency override should expire automatically. If an engineer must remember to remove it on Friday afternoon, assume it will still exist Monday morning.
Keep the rule language narrow at first. A YAML file or plain Python policy table is often better than a powerful general-purpose DSL when the deployment is new. You want on-call engineers to answer three questions quickly:
- Which rule denied the call?
- What request shape would pass?
- Who can approve a temporary exception?
Complex policy engines become valuable when you need shared libraries, formal decision traces, or organization-wide reuse. Do not start there solely because the policy language looks sophisticated. Start with the smallest representation that makes dangerous actions explicit and testable.
Audit Records: Capture Enough Context Without Capturing Secrets
The audit trail is not a debug print. It is the evidence surface for incident response, compliance review, and policy tuning. OWASP's MCP08 guidance calls out the need for structured, centralized activity logging and warns that missing telemetry blocks forensic analysis (OWASP).
Each tool-call record should include:
| Field | Why it exists |
|---|---|
| Request ID and parent trace ID | Reconstruct the agent workflow |
| User, agent, and workload identity | Identify the acting principal |
| Server identity and manifest digest | Bind execution to the discovered server version |
| Tool name and schema version | Explain the invoked contract |
| Argument hash and redacted summary | Investigate shape without storing secrets |
| Policy version and decision reason | Explain why execution was allowed or blocked |
| Approval identity and expiry | Audit sensitive exceptions |
| Credential fingerprint and audience | Correlate scope without logging the token |
| Response hash and redaction count | Track output inspection |
| Duration and outcome | Tune operations and detect failure spirals |
The redacted summary deserves care. Hashing the full argument object protects raw values, but a hash alone is not enough during an incident. Store a deliberately limited structural summary: field names, row-limit bucket, resource category, region, and whether restricted fields were requested. Do not store free-form prompt text by default. Do not store bearer tokens at all. Preserve the original payload only in a tightly controlled forensic path if your risk model genuinely requires it.
The useful test is simple: can an incident responder distinguish a normal one-record support lookup from a wildcard export attempt without opening raw customer data? If not, improve the summary schema. If the summary itself contains customer secrets, reduce it.
OpenTelemetry is a natural transport because it keeps agent events close to the rest of your operational traces. Emit a span or structured log around the policy decision, attach the request ID to the downstream call, and alert when audit delivery fails. OpenAI's Codex deployment uses OpenTelemetry export for tool decisions, tool results, MCP usage, and network-policy events, which is the same correlation shape a production MCP gateway needs (OpenAI).
Failure Handling: Decide What Happens When the Gateway Is Sick
The gateway is now part of the critical path. Treat it like one.
There are four failures to design before rollout:
Policy service unavailable
For destructive tools, deny or queue the call. Do not bypass policy because the policy service is down. For narrow read-only tools, a cached last-known-good decision may be acceptable if the cache binds server digest, tool, identity scope, argument envelope, and a short expiry. Document that exception instead of letting it emerge during an outage.
Identity provider unavailable
Do not fall back to a shared static credential. Queue work or require the operator to retry after recovery. Static fallback credentials quietly become the most privileged path in the system because they outlive every intended boundary.
Audit sink unavailable
Buffer records locally with bounded storage and alert immediately. For destructive calls, decide whether missing durable audit delivery should halt execution. Regulated workflows often need a fail-closed rule. Low-risk reads may tolerate a bounded buffer. Either way, make the behavior explicit and test it.
Response inspector timeout
Do not pass an uninspected response into model context merely because inspection exceeded its latency budget. Return a typed failure, quarantine the payload for review, and let the agent choose a safe recovery path. The agent may retry a different source, ask for approval, or stop.
Exercise these paths in a staging environment. Disable the policy backend. Rotate the signing key. Return an oversized response. Break audit delivery. Let an agent hit the same denied call repeatedly. The first time you observe these behaviors should not be during an incident.
Testing the Boundary
Policy tests should read like security requirements. Keep a compact suite beside each policy package:
def test_wildcard_region_is_denied():
call = ToolCall(
"inventory-mcp",
"inventory.lookup",
{"region": "*", "limit": 25},
"agent:triage",
)
assert govern(call).allowed is False
def test_write_requires_approval():
call = ToolCall(
"inventory-mcp",
"inventory.adjust",
{"sku": "A-17", "delta": -2},
"agent:triage",
)
assert govern(call).reason == "human approval required"
Add adversarial fixtures for every argument parser. Test wildcard values, negative limits, empty resource IDs, encoded shell separators, oversized payloads, unexpected fields, and schema-version drift. Then test sequences: many distinct sensitive reads, repeated identical failures, approval reuse after expiry, and an agent switching servers mid-workflow.
The test suite is also a communication artifact. An application owner can review a dozen explicit examples faster than a dense policy document. When a requirement changes, update the test first, then change the rule. That keeps security policy close to the behavior engineers can observe.
Finally, replay real traces against policy updates before rollout. A deny rule that blocks an existing workflow should be visible in staging. An allow rule that unexpectedly widens access should be visible in the diff. Runtime governance works best when teams treat policy evolution as engineering work, not as a one-time security checklist.
A Practical Migration Runbook
If you already have MCP servers in production, do not attempt a single cutover where every call becomes governed overnight. The safer path is to move one tool family at a time while preserving evidence about what changed.
Start with inventory. List every MCP server your agents can reach, including developer-local servers, staging endpoints, experimental connectors, and servers configured through project files. Record owner, repository, deployment environment, transport, authentication mode, exposed tools, credential source, and whether the server can cause side effects. The shadow-server pass is usually revealing. A platform team may know about the official database connector and miss the local helper that a team added during an incident.
Then classify tools into four rings:
| Ring | Typical capability | Default runtime decision |
|---|---|---|
| 0 | Static documentation and public metadata | Allow with logging |
| 1 | Narrow internal reads | Allow with argument validation |
| 2 | Broad reads or bounded writes | Require stronger scope and conditional approval |
| 3 | Destructive actions, credentials, deployments, identity changes | Deny by default; explicit approval and audit required |
Do not classify only by tool name. A database query tool can move from Ring 1 to Ring 3 depending on accessible tables, row limits, export options, and credential scope. A file reader can be low risk inside a documentation folder and high risk when its root is a developer home directory. The ring belongs to the effective capability, not the marketing label.
Run the gateway in observe mode for a bounded period. During that window, every call receives the policy decision it would have received under enforcement, but the gateway does not block normal traffic. Review the would-deny records daily. Separate legitimate workflows from accidental breadth. Tighten arguments where a tool is more general than the workflow needs. Fix credentials where one token spans too many systems.
Promote enforcement in this order:
- Unknown server denial.
- Ring 3 approval requirements.
- Credential redaction and scoped injection.
- Destructive-argument denial.
- Broad-read limits.
- Response-shape validation.
- Sequence alerts and circuit breakers.
This order catches the highest-impact failures early without turning the first rollout into an organization-wide productivity outage. It also creates a useful feedback loop: every enforcement phase produces traces that improve the next phase.
Keep an exception register. Each temporary bypass should name an owner, reason, affected tool, exact widened scope, approval identity, creation time, and automatic expiration. Review active exceptions weekly. If a bypass survives repeated renewals, treat it as a missing product requirement and redesign the policy or the tool. Permanent emergency flags are policy debt with a friendly name.
Finally, rehearse revocation. Pick a test server, mark its identity as compromised, and verify that new calls stop. Revoke a credential and confirm that the gateway does not reuse a cached token. Change a schema digest and verify that the client requires revalidation. Search the audit store for the affected server digest and reconstruct the call history. A control plane is only credible if you can use it while the system is under pressure.
The migration is complete when teams can answer three questions without guesswork:
- Which MCP servers can each agent reach?
- Which calls require approval or denial, including argument boundaries?
- Can an incident responder reconstruct what happened without exposing secrets?
If any answer is unclear, keep the gateway in the rollout plan. The missing clarity is exactly the risk runtime governance is meant to remove.
Conclusion
MCP made tool integration easier. That is exactly why the governance boundary matters. Once an agent can discover and call real systems, server trust is only the starting point.
The production question is not whether the model usually behaves. It is whether every meaningful side effect passes a deterministic checkpoint that understands identity, tool, arguments, scope, approval state, recent history, and response shape.
Start with the smallest useful gateway. Deny unknown servers. Validate arguments. Mint scoped credentials at the boundary. Inspect responses before they re-enter model context. Emit audit records you can replay during an incident. Then add sequence policy as your traces expose the normal shape of real work.
That is how you turn MCP from a convenient execution surface into a governed one.
Get the next one
Each week I send a short engineering note with one production failure, the debugging path, and companion code from the latest deep-dive. It is free, brief, and easy to leave.
If this saved you a governance incident, you can support the work here: Buy Me a Coffee.
Reader challenge: try mapping the runtime governance checklist above to one MCP server you already use. Reply to the email or comment with the first missing gate you find.
Sources
- Trend Micro: Hunt Them All, an AI-Powered Vulnerability Sweep of 19,000 MCP Servers
- Trend Micro: Update on Exposed MCP Servers, The Threat Widens to the Cloud
- Microsoft for Developers: Securing MCP, A Control Plane for Agent Tool Execution
- OpenAI: Running Codex Safely at OpenAI
- OWASP MCP Top 10
- OWASP: MCP Tool Poisoning
- Model Context Protocol: Authorization Specification
- Model Context Protocol: Understanding Authorization in MCP
About the Author
Toc Am
Founder of AmtocSoft. Writing practical deep-dives on AI engineering, cloud architecture, and developer tooling. Previously built backend systems at scale. Reviews every post published under this byline.
Published: 2026-06-03 · Updated: 2026-06-17 · Written with AI assistance, reviewed by Toc Am.
Get These In Your Inbox
Weekly deep-dives on AI engineering, no fluff. Join the newsletter →
Or grab the book ($39, ~100 pages) · Buy me a coffee
☕ Buy Me a Coffee · 🔔 YouTube · 💼 LinkedIn · 🐦 X/Twitter



No comments:
Post a Comment